EduArt: An educational-level benchmark for evaluating art history knowledge in large language models
Pith reviewed 2026-07-03 14:45 UTC · model grok-4.3
The pith
Multimodal LLMs achieve near-ceiling scores on multiple-choice art history questions but drop sharply on open formats that require generating or correcting answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
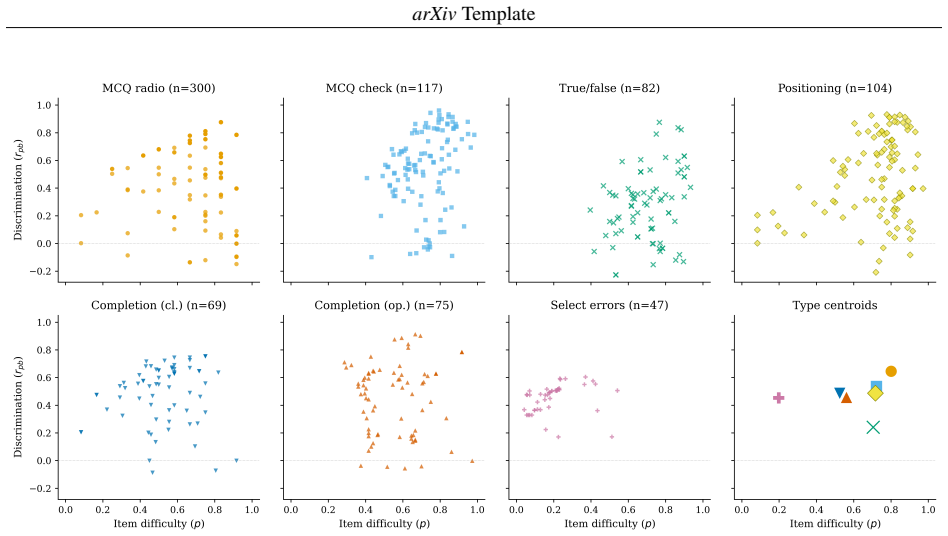
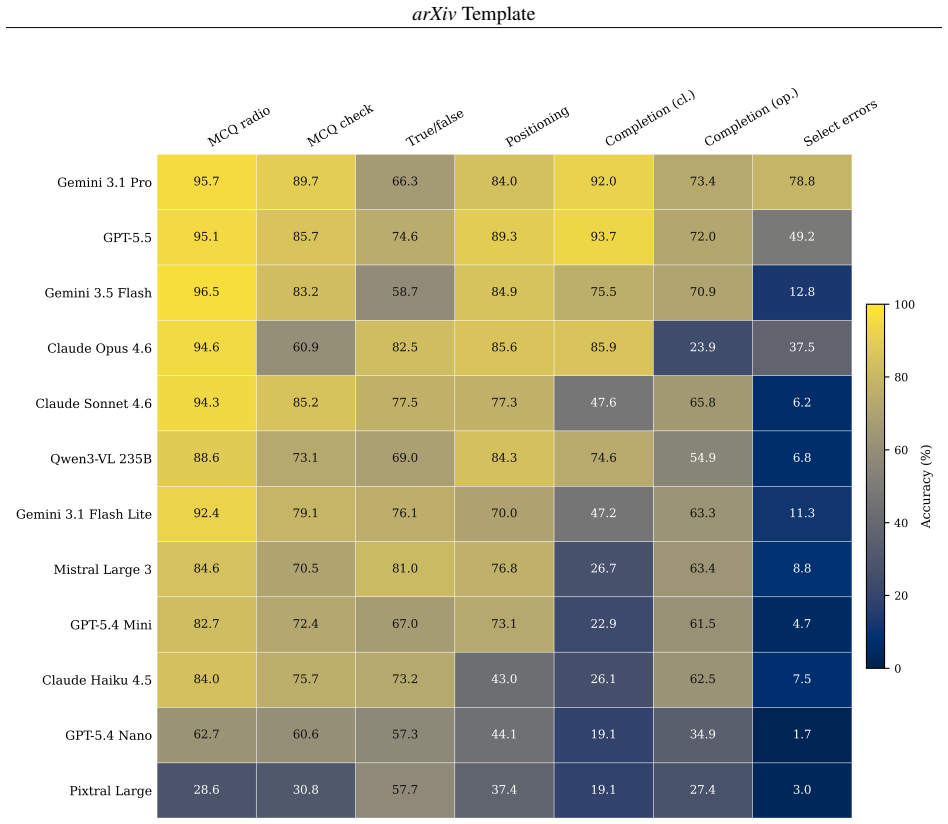
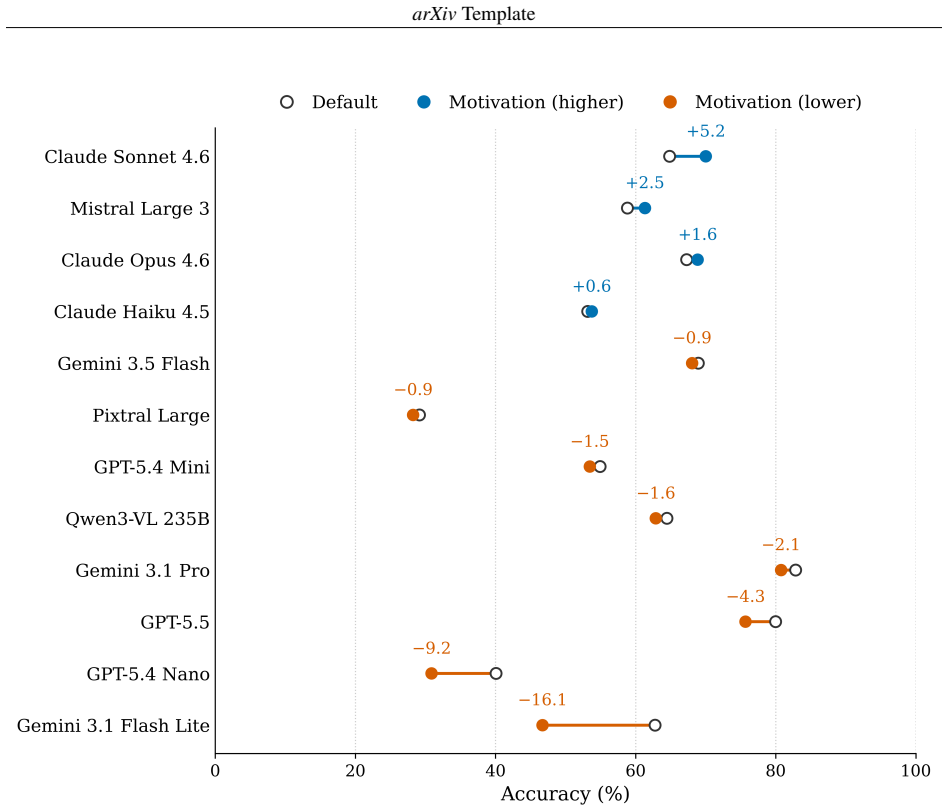
EduArt shows that art-historical knowledge and the ability to deploy it are distinct capabilities, since models exceed 94 percent accuracy on multiple choice yet fall to 23.9 percent on open completion and 6.2 percent on error identification. The motivation condition, which requires written justification, further changes accuracy in a predominantly negative and family-dependent direction. Single-format benchmarks therefore overestimate what models can reliably do when tasks demand producing and manipulating content.
What carries the argument
The EduArt benchmark, built from seven question formats spanning recognition to open production and drawn from educational exams in two languages, together with the contrast between answer-only and motivation conditions.
If this is right
- Format acts as a strong independent predictor of accuracy even after controlling for language, image presence, and model family.
- Multiple-choice accuracy saturates near ceiling for several models, so recognition formats alone cannot distinguish frontier performance.
- The motivation condition alters accuracy in a negative direction that depends on the model family.
- Mapping the full capability profile across formats is a precondition for responsible use of multimodal LLMs in art-historical scholarship.
Where Pith is reading between the lines
- The observed dissociation between recognition and deployment may appear in other knowledge domains that rely on generation rather than selection.
- Benchmarks limited to one format risk systematically overestimating model utility for any task that requires writing or revising content.
- Tracking model progress on open formats within EduArt could provide a clearer signal of improvement in deployable knowledge than aggregate scores.
Load-bearing premise
The 871 questions from Italian secondary-school exercises and US Advanced Placement Art History exams adequately represent the knowledge and visual reasoning demands of art-historical scholarship.
What would settle it
An experiment in which models that score low on EduArt's open formats are nevertheless shown to produce accurate, error-free art-historical analyses or identifications when given real scholarly source material without multiple-choice options.
Figures
read the original abstract
Large language models now score near ceiling on general benchmarks, but these aggregate measures reveal little about how models behave within single disciplines. Existing art-focused evaluations rely on synthetic questions and rarely report item-level properties. This paper introduces EduArt, an educational-level benchmark for art-historical knowledge and visual reasoning in multimodal LLMs. EduArt comprises 871 human-authored questions from Italian secondary-school exercises and US Advanced Placement Art History exams, spanning two languages and seven formats from multiple choice to in-text word placement and error identification. Twelve models from six provider families were evaluated under a default answer-only condition and a motivation condition requiring written justification, and characterized using Classical Test Theory and a logistic regression isolating the effects of format, language, image presence, and model. The benchmark showed strong psychometric properties (mean discrimination 0.514, 82.3 percent good discriminators), while multiple-choice accuracy saturated near ceiling for six models, showing recognition formats alone cannot distinguish frontier models. Format was a strong independent predictor of accuracy: models exceeding 94 percent on multiple choice fell to 23.9 percent on open completion (Claude Opus 4.6) and 6.2 percent on error identification (Claude Sonnet 4.6). The motivation condition changed accuracy in a predominantly negative, family-dependent direction. These dissociations indicate that art-historical knowledge and the ability to deploy it are distinct capabilities, and that single-format benchmarks overestimate what models can reliably do. Mapping this capability profile is a precondition for responsible use of multimodal LLMs in art-historical scholarship, where tasks demand producing and manipulating content rather than selecting from fixed options.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EduArt, a benchmark of 871 human-authored questions drawn from Italian secondary-school exercises and US AP Art History exams across seven formats (multiple choice to error identification) and two languages. Twelve multimodal LLMs from six families are evaluated in answer-only and motivation (justification) conditions. Classical Test Theory yields mean item discrimination of 0.514 with 82.3% good discriminators; logistic regression isolates effects of format, language, image presence, and model. Multiple-choice accuracy saturates near ceiling for six models, but drops sharply on open formats (e.g., 23.9% on completion for Claude Opus, 6.2% on error identification for Claude Sonnet). The motivation condition produces predominantly negative, family-dependent accuracy shifts. The authors conclude that art-historical knowledge and deployment are distinct capabilities and that single-format benchmarks overestimate reliable performance, positioning the profile as a precondition for responsible LLM use in art-historical scholarship.
Significance. If the reported dissociations and psychometric properties hold, the work supplies a concrete, multi-format evaluation that moves beyond aggregate or synthetic benchmarks in a humanities domain. Credit is due for sourcing authentic exam items rather than generated questions, for reporting item-level discrimination statistics, and for using logistic regression to quantify format as an independent predictor. These elements make the capability-profile claim falsifiable via replication on the released items. The findings could usefully inform evaluation design for other domain-specific multimodal tasks.
major comments (2)
- [Abstract] Abstract: The claim that the observed format dissociations constitute a 'precondition for responsible use of multimodal LLMs in art-historical scholarship' is load-bearing for the paper's broader significance, yet the 871 items are drawn exclusively from secondary-school exercises and AP exams that emphasize recognition, recall, and basic visual identification; the manuscript supplies no validation, mapping, or comparative data showing that drops on open completion or error identification predict performance on scholarly activities such as constructing period arguments or writing catalogue entries.
- [Abstract] Abstract (logistic regression paragraph): The statement that 'format was a strong independent predictor of accuracy' is central to the dissociation argument, but the manuscript does not report the regression specification (e.g., whether interactions between format and model family were included, the reference level for format, or coefficient magnitudes), preventing verification that the format effect remains robust after controlling for language, image presence, and model.
minor comments (1)
- [Abstract] The abstract reports concrete statistics (mean discrimination 0.514, 82.3% good discriminators) but does not indicate whether these were computed on the full 871-item set or after any filtering; a brief methods sentence would clarify reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on scope and reporting. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the observed format dissociations constitute a 'precondition for responsible use of multimodal LLMs in art-historical scholarship' is load-bearing for the paper's broader significance, yet the 871 items are drawn exclusively from secondary-school exercises and AP exams that emphasize recognition, recall, and basic visual identification; the manuscript supplies no validation, mapping, or comparative data showing that drops on open completion or error identification predict performance on scholarly activities such as constructing period arguments or writing catalogue entries.
Authors: We agree that EduArt is limited to educational-level items focused on recognition and recall, with no direct validation or mapping to advanced scholarly tasks. The abstract claim was intended to underscore that limitations on basic deployment tasks are relevant to responsible use, but we accept that this overstates the direct link. We will revise the abstract wording from 'a precondition' to 'an important step toward responsible use' and add a brief limitations note on the educational scope of the items. revision: partial
-
Referee: [Abstract] Abstract (logistic regression paragraph): The statement that 'format was a strong independent predictor of accuracy' is central to the dissociation argument, but the manuscript does not report the regression specification (e.g., whether interactions between format and model family were included, the reference level for format, or coefficient magnitudes), preventing verification that the format effect remains robust after controlling for language, image presence, and model.
Authors: The logistic regression used accuracy as the binary outcome with predictors for format (multiple-choice as reference level), language (Italian reference), image presence, and model family (one family as reference); no interactions were modeled. We will add the full specification, reference levels, and key coefficients (including format odds ratios) to the methods section in revision. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper constructs EduArt from existing Italian secondary-school and US AP exam questions, evaluates 12 models across formats using standard accuracy metrics plus Classical Test Theory and logistic regression for format/language/image effects, and reports observed dissociations. No derivation chain, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatz smuggling appear; the central claims follow directly from the collected item responses without reducing to the inputs by construction. This is a standard empirical evaluation study whose results are falsifiable against the benchmark data itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Hendrycks, Dan and Burns, Collin and Basart, Steven and Zou, Andy and Mazeika, Mantas and Song, Dawn and Steinhardt, Jacob , urldate =. Measuring Massive Multitask Language Understanding , url =. doi:10.48550/arXiv.2009.03300 , abstract =. 2009.03300 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2009
-
[2]
doi:10.52202/079017-3018 , shorttitle =
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and Li, Tianle and Ku, Max and Wang, Kai and Zhuang, Alex and Fan, Rongqi and Yue, Xiang and Chen, Wenhu , urldate =. doi:10.52202/079017-3018 , shorttitle =
-
[3]
, urldate =
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , urldate =
-
[4]
Guha, Neel and Nyarko, Julian and Ho, Daniel and Ré, Christopher and Chilton, Adam and K, Aditya and Chohlas-Wood, Alex and Peters, Austin and Waldon, Brandon and Rockmore, Daniel and Zambrano, Diego and Talisman, Dmitry and Hoque, Enam and Surani, Faiz and Fagan, Frank and Sarfaty, Galit and Dickinson, Gregory and Porat, Haggai and Hegland, Jason and Wu,...
-
[5]
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , urldate =. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , volume =. doi:10.3390/app11146421 , shorttitle =
-
[6]
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , volume =
Lu, Pan and Mishra, Swaroop and Xia, Tanglin and Qiu, Liang and Chang, Kai-Wei and Zhu, Song-Chun and Tafjord, Oyvind and Clark, Peter and Kalyan, Ashwin , urldate =. Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , volume =
-
[7]
Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Yang, Linyi and Zhu, Kaijie and Chen, Hao and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and Ye, Wei and Zhang, Yue and Chang, Yi and Yu, Philip S. and Yang, Qiang and Xie, Xing , urldate =. A Survey on Evaluation of Large Language Models , volume =. doi:10.1145/3641289 , abstract =
-
[8]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and Wei, Cong and Yu, Botao and Yuan, Ruibin and Sun, Renliang and Yin, Ming and Zheng, Boyuan and Yang, Zhenzhu and Liu, Yibo and Huang, Wenhao and Sun, Huan and Su, Yu and Chen, Wenhu , urldate =
-
[9]
Visual Instruction Tuning , volume =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , urldate =. Visual Instruction Tuning , volume =
-
[10]
Alfarano, Andrea and Venturoli, Lorenzo and del Castillo, Darío Negueruela , urldate =. 2025. doi:10.1109/ICCVW69036.2025.00761 , shorttitle =
-
[11]
Evaluating Multimodal Large Language Models for Visual Question-Answering in Italian , abstract =
Scaiella, Antonio and Margiotta, Daniele and Hromei, Claudiu Daniel and Croce, Danilo and Basili, Roberto , langid =. Evaluating Multimodal Large Language Models for Visual Question-Answering in Italian , abstract =
-
[12]
A Dataset and Baselines for Visual Question Answering on Art
-
[13]
Gema, Aryo Pradipta and Leang, Joshua Ong Jun and Hong, Giwon and Devoto, Alessio and Mancino, Alberto Carlo Maria and Saxena, Rohit and He, Xuanli and Zhao, Yu and Du, Xiaotang and Ghasemi Madani, Mohammad Reza and Barale, Claire and. Are We Done with. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Comput...
-
[14]
Dong, Yihong and Jiang, Xue and Liu, Huanyu and Jin, Zhi and Gu, Bin and Yang, Mengfei and Li, Ge , editor =. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models , url =. Findings of the Association for Computational Linguistics:. doi:10.18653/v1/2024.findings-acl.716 , shorttitle =
-
[15]
Time Travel in
Golchin, Shahriar and Surdeanu, Mihai , urldate =. Time Travel in
-
[16]
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
White, Colin and Dooley, Samuel and Roberts, Manley and Pal, Arka and Feuer, Ben and Jain, Siddhartha and Shwartz-Ziv, Ravid and Jain, Neel and Saifullah, Khalid and Dey, Sreemanti and Shubh-Agrawal and Sandha, Sandeep Singh and Naidu, Siddartha and Hegde, Chinmay and. doi:10.48550/arXiv.2406.19314 , shorttitle =. 2406.19314 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.19314
-
[17]
From Generation to Judgment: Opportunities and Challenges of
Li, Dawei and Jiang, Bohan and Huang, Liangjie and Beigi, Alimohammad and Zhao, Chengshuai and Tan, Zhen and Bhattacharjee, Amrita and Jiang, Yuxuan and Chen, Canyu and Wu, Tianhao and Shu, Kai and Cheng, Lu and Liu, Huan , editor =. From Generation to Judgment: Opportunities and Challenges of. Proceedings of the 2025 Conference on Empirical Methods in Na...
-
[18]
Benchmarking Foundation Models with Language-Model-as-an-Examiner , volume =
Bai, Yushi and Ying, Jiahao and Cao, Yixin and Lv, Xin and He, Yuze and Wang, Xiaozhi and Yu, Jifan and Zeng, Kaisheng and Xiao, Yijia and Lyu, Haozhe and Zhang, Jiayin and Li, Juanzi and Hou, Lei , urldate =. Benchmarking Foundation Models with Language-Model-as-an-Examiner , volume =
-
[19]
and Krathwohl, David R
Anderson, Lorin W. and Krathwohl, David R. , urldate =. A taxonomy for learning, teaching, and assessing : a revision of Bloom's taxonomy of educational objectives : complete edition , isbn =
-
[20]
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , url =
-
[21]
doi:10.48550/arXiv.2303.08774 , abstract =. 2303.08774 [cs] , keywords =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[22]
Gemini and Anil, Rohan and Borgeaud, Sebastian and Alayrac, Jean-Baptiste and Yu, Jiahui and Soricut, Radu and Schalkwyk, Johan and Dai, Andrew M. and Hauth, Anja and Millican, Katie and Silver, David and Johnson, Melvin and Antonoglou, Ioannis and Schrittwieser, Julian and Glaese, Amelia and Chen, Jilin and Pitler, Emily and Lillicrap, Timothy and Lazari...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805
-
[23]
The Claude 3 Model Family: Opus, Sonnet, Haiku , url =
Anthropic , date=. The Claude 3 Model Family: Opus, Sonnet, Haiku , url =
-
[24]
Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R. and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adrià and Kluska, Agnieszka and Lewkowycz, Aitor and Agarwal, Akshat and Power, Alethea and Ray, Alex and Warstadt, Alex and Kocurek, Alexander W. and Safaya, Ali and...
-
[25]
Phan, Long and Gatti, Alice and Han, Ziwen and Li, Nathaniel and Hu, Josephina and Zhang, Hugh and Zhang, Chen Bo Calvin and Shaaban, Mohamed and Ling, John and Shi, Sean and Choi, Michael and Agrawal, Anish and Chopra, Arnav and Khoja, Adam and Kim, Ryan and Ren, Richard and Hausenloy, Jason and Zhang, Oliver and Mazeika, Mantas and Dodonov, Dmitry and N...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09962-4
-
[26]
Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter , urldate =. What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams , url =. doi:10.48550/arXiv.2009.13081 , shorttitle =. 2009.13081 [cs] , keywords =
-
[27]
Kung, Tiffany H. and Cheatham, Morgan and Medenilla, Arielle and Sillos, Czarina and Leon, Lorie De and Elepaño, Camille and Madriaga, Maria and Aggabao, Rimel and Diaz-Candido, Giezel and Maningo, James and Tseng, Victor , urldate =. Performance of. doi:10.1371/journal.pdig.0000198 , shorttitle =
-
[28]
A Dataset and Baselines for Visual Question Answering on Art , isbn =
Garcia, Noa and Ye, Chentao and Liu, Zihua and Hu, Qingtao and Otani, Mayu and Chu, Chenhui and Nakashima, Yuta and Mitamura, Teruko , editor =. A Dataset and Baselines for Visual Question Answering on Art , isbn =. Computer Vision –. doi:10.1007/978-3-030-66096-3_8 , abstract =
-
[29]
Spinaci, Gianmarco and Klic, Lukas and Colavizza, Giovanni , urldate =. Benchmarking Vision-Language and Multimodal Large Language Models in Zero-shot and Few-shot Scenarios: A study on Christian Iconography , url =. doi:10.48550/arXiv.2509.18839 , shorttitle =. 2509.18839 [cs] , keywords =
-
[30]
doi:10.1145/3590773 , shorttitle =
Becattini, Federico and Bongini, Pietro and Bulla, Luana and Bimbo, Alberto Del and Marinucci, Ludovica and Mongiovì, Misael and Presutti, Valentina , urldate =. doi:10.1145/3590773 , shorttitle =
-
[31]
doi:10.48550/arXiv.2406.05967 , shorttitle =
Romero, David and Lyu, Chenyang and Wibowo, Haryo Akbarianto and Lynn, Teresa and Hamed, Injy and Kishore, Aditya Nanda and Mandal, Aishik and Dragonetti, Alina and Abzaliev, Artem and Tonja, Atnafu Lambebo and Balcha, Bontu Fufa and Whitehouse, Chenxi and Salamea, Christian and Velasco, Dan John and Adelani, David Ifeoluwa and Meur, David Le and Villa-Cu...
-
[32]
Making the v in
Goyal, Yash and Khot, Tejas and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , urldate =. Making the v in
-
[33]
doi:10.1098/rsta.2023.0254 , abstract =
Katz, Daniel Martin and Bommarito, Michael James and Gao, Shang and Arredondo, Pablo , date =. doi:10.1098/rsta.2023.0254 , abstract =
-
[34]
and Girshick, Ross , urldate =
Johnson, Justin and Hariharan, Bharath and van der Maaten, Laurens and Fei-Fei, Li and Lawrence Zitnick, C. and Girshick, Ross , urldate =
-
[35]
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , url =
Zhou, Hongli and Huang, Hui and Zhao, Ziqing and Han, Lvyuan and Wang, Huicheng and Chen, Kehai and Yang, Muyun and Bao, Wei and Dong, Jian and Xu, Bing and Zhu, Conghui and Cao, Hailong and Zhao, Tiejun , urldate =. Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory , url =. doi:10.48550/arXiv.2505.15055 , shorttit...
-
[36]
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , urldate =. doi:10.48550/arXiv.2402.14992 , shorttitle =. 2402.14992 [cs] , note =
-
[37]
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal
Tong, Shengbang and Liu, Zhuang and Zhai, Yuexiang and Ma, Yi and. Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal
-
[38]
Xu, Weiye and Wang, Jiahao and Wang, Weiyun and Chen, Zhe and Zhou, Wengang and Yang, Aijun and Lu, Lewei and Li, Houqiang and Wang, Xiaohua and Zhu, Xizhou and Wang, Wenhai and Dai, Jifeng and Zhu, Jinguo , langid =
-
[39]
Zhang, Renrui and Jiang, Dongzhi and Zhang, Yichi and Lin, Haokun and Guo, Ziyu and Qiu, Pengshuo and Zhou, Aojun and Lu, Pan and Chang, Kai-Wei and Qiao, Yu and Gao, Peng and Li, Hongsheng , editor =. Computer Vision –. doi:10.1007/978-3-031-73242-3_10 , shorttitle =
-
[40]
From Recognition to Cognition: Visual Commonsense Reasoning , url =
Zellers, Rowan and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , urldate =. From Recognition to Cognition: Visual Commonsense Reasoning , url =
-
[41]
and Gu, Huanying and Maruf, Abdullah Al and Aung, Zeyar , urldate =
Siam, Md Kamrul and Varela, Angel and Faruk, Md Jobair Hossain and Cheng, Jerry Q. and Gu, Huanying and Maruf, Abdullah Al and Aung, Zeyar , urldate =. Benchmarking large language models on the United States medical licensing examination for clinical reasoning and medical licensing scenarios , volume =. doi:10.1038/s41598-025-31010-4 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.