MB-Loc: Multi-planar Bird's-eye-view Localization in outdoor LiDAR scenes
Pith reviewed 2026-06-27 18:54 UTC · model grok-4.3
The pith
MB-Loc turns 3D LiDAR localization into a set of 2D CNN regressions by slicing scans into stacked bird's-eye planes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
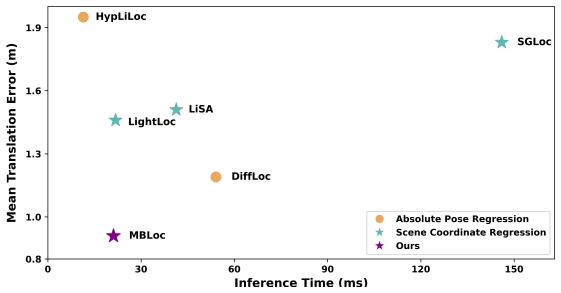
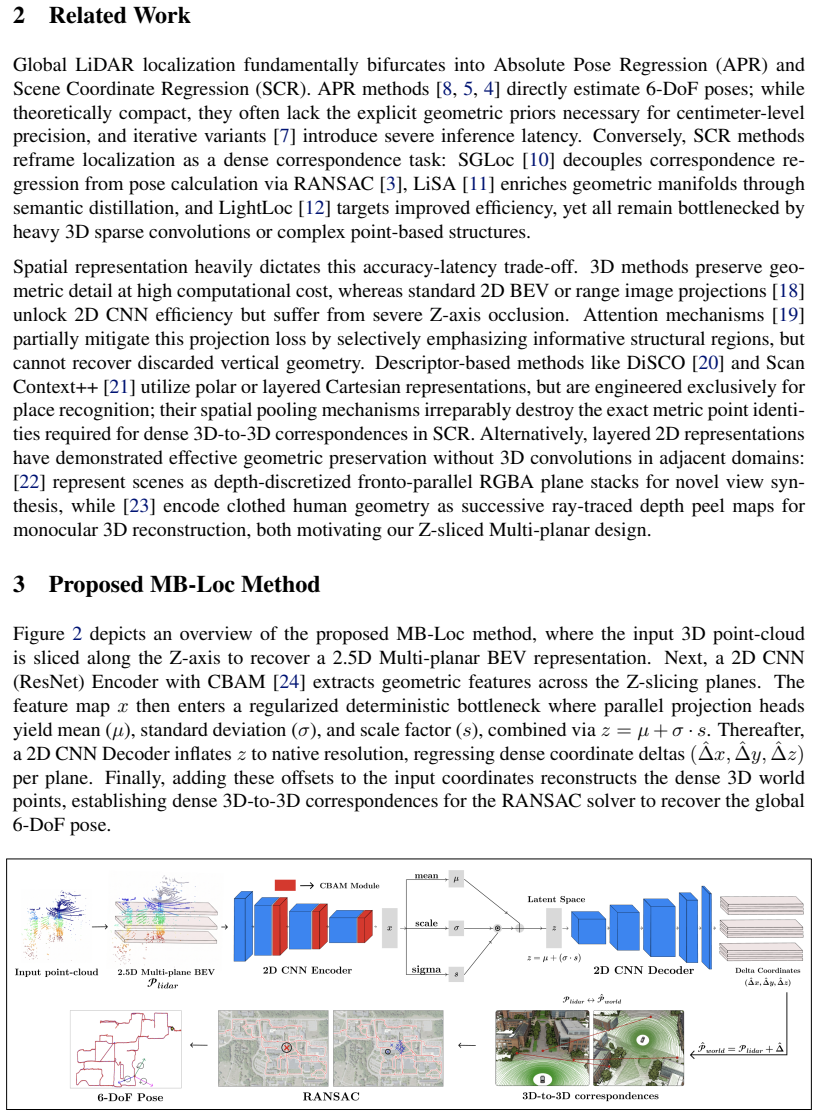
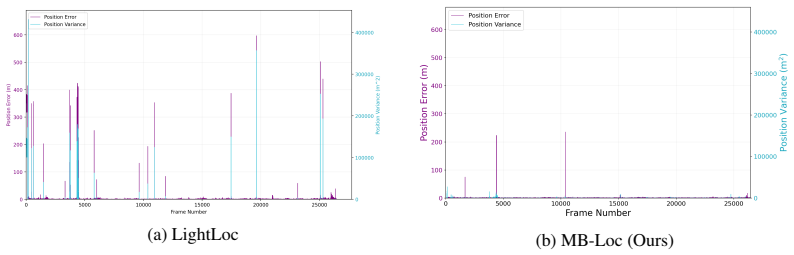
MB-Loc performs scene coordinate regression on outdoor LiDAR by projecting each scan into a multi-planar bird's-eye-view representation obtained through Z-axis slicing and signed-depth encoding into discrete 2D planes. The network uses a KL-regularized latent bottleneck to capture spatial uncertainty without added noise and receives 3D spatial augmentations before projection to acquire viewpoint-invariant features. Experiments show this yields higher accuracy than existing methods on the NCLT dataset together with real-time inference and substantially lower compute than traditional 3D scene coordinate regression networks.
What carries the argument
The multi-planar bird's-eye-view representation created by slicing the point cloud along the Z-axis and mapping signed depths into discrete 2D planes.
If this is right
- Localization runs at real-time speeds on ordinary GPUs because only 2D convolutions are required after the initial projection.
- Accuracy remains high when the sensor viewpoint at test time differs from the training viewpoint.
- Memory and compute budgets drop sharply relative to any network that operates directly on raw 3D point clouds or voxels.
- The explicit uncertainty modeling inside the latent bottleneck reduces sensitivity to the sparse returns typical of outdoor LiDAR.
Where Pith is reading between the lines
- The same slicing-and-projection step could be reused for other 3D tasks such as semantic segmentation or object detection where real-time performance on embedded hardware is required.
- Because the representation is built from signed depths rather than raw intensities, it may combine naturally with camera images that supply complementary appearance cues.
- The rotation-invariance gained from 3D augmentations suggests the trained model could transfer across different vehicle platforms without retraining on new mounting angles.
Load-bearing premise
Slicing the point cloud along the vertical axis into discrete planes and recording signed depths is sufficient to keep every geometric detail required for accurate 3D coordinate regression.
What would settle it
A controlled test in which MB-Loc produces localization errors larger than prior 3D methods on scenes containing tall vertical objects or on trajectories whose sensor tilt exceeds the range of the 3D augmentations.
Figures

read the original abstract
Global LiDAR localization is a fundamental task for autonomous navigation systems. Recent methods perform Scene Coordinate Regression (SCR) and achieve superior accuracy over Absolute Pose Regression (APR) solutions by predicting dense 3D world coordinates. However, SCR approaches introduce two major bottlenecks: severe computational inefficiency from processing raw 3D geometries and significant performance degradation under varying sensor viewpoints. To address these limitations, we present MB-Loc, a lightweight and viewpoint-robust SCR framework. Instead of relying on heavy 3D convolutions, we project the input LiDAR scan into a 2.5D Multi-planar Bird's-Eye View (BEV) representation. By slicing the point-cloud along the Z-axis and mapping signed depths into discrete 2D planes, MB-Loc retains essential 3D geometric structures while exploiting the computational tractability of standard 2D CNNs. To handle the inherent sparsity of outdoor LiDAR, we introduce a KL-regularized latent bottleneck that explicitly models spatial uncertainty without injecting stochastic noise. Finally, to ensure rotation robustness, we apply 3D spatial augmentations prior to planar projection, forcing the network to implicitly learn viewpoint-invariant features. We perform extensive experiments on the publicly available NCLT dataset and demonstrate that our proposed method outperforms the current state-of-the-art. Operating at real-time inference speeds, MB-Loc significantly outperforms traditional 3D-SCR architectures in computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MB-Loc, a lightweight scene coordinate regression (SCR) framework for global LiDAR localization in outdoor scenes. It replaces heavy 3D convolutions with a 2.5D multi-planar bird's-eye-view (BEV) representation obtained by slicing the input point cloud along the Z-axis and mapping signed depths into discrete 2D planes, augments this with a KL-regularized latent bottleneck to handle sparsity without stochastic noise, and applies 3D spatial augmentations before projection for rotation robustness. Experiments on the NCLT dataset are reported to show that MB-Loc outperforms current state-of-the-art SCR methods while achieving real-time inference speeds and substantially lower computational cost than traditional 3D-SCR architectures.
Significance. If the reported accuracy and efficiency gains hold under full scrutiny, the work would demonstrate a practical route to viewpoint-robust, real-time LiDAR localization by leveraging standard 2D CNNs on a carefully designed multi-planar BEV input; this could reduce the computational barrier that currently limits dense SCR methods in autonomous navigation pipelines.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The central claim that 'slicing the point-cloud along the Z-axis and mapping signed depths into discrete 2D planes retains essential 3D geometric structures' is load-bearing for attributing any accuracy advantage over full 3D-SCR; yet no quantitative analysis (e.g., reconstruction error, point-density statistics per plane, or ablation on vertical surface recall) is supplied to bound the information loss that occurs for points lying between planes or on vertical façades in sparse outdoor LiDAR.
- [Abstract and experimental section] Abstract and experimental section: The assertion that MB-Loc 'outperforms the current state-of-the-art' on NCLT is presented without reference to the precise baseline implementations, training protocols, or error metrics (e.g., median translation/rotation error, success rate at fixed thresholds) used for comparison; without these details the magnitude and statistical significance of the reported gains cannot be verified.
- [§3.2] §3.2 (KL-regularized latent bottleneck): The claim that the bottleneck 'explicitly models spatial uncertainty without injecting stochastic noise' requires the explicit loss formulation and sampling procedure; the current description leaves open whether the regularization is applied only at training time or also affects deterministic inference, which directly affects the real-time efficiency claim.
minor comments (2)
- Notation for the number of planes, plane spacing, and signed-depth encoding range is introduced without a dedicated table or equation block, making reproduction difficult.
- The 3D augmentation strategy (rotation ranges, translation bounds) is described at a high level; a precise list of augmentation parameters would strengthen the reproducibility of the viewpoint-invariance claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and analyses.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that 'slicing the point-cloud along the Z-axis and mapping signed depths into discrete 2D planes retains essential 3D geometric structures' is load-bearing for attributing any accuracy advantage over full 3D-SCR; yet no quantitative analysis (e.g., reconstruction error, point-density statistics per plane, or ablation on vertical surface recall) is supplied to bound the information loss that occurs for points lying between planes or on vertical façades in sparse outdoor LiDAR.
Authors: We agree that a quantitative bound on information loss would strengthen the central claim. In the revised manuscript we will add an analysis subsection that reports point-density statistics per plane, an ablation varying the number of planes, and vertical-surface recall metrics computed on the NCLT sequences. These additions will directly address the potential loss for points between planes or on façades. revision: yes
-
Referee: [Abstract and experimental section] Abstract and experimental section: The assertion that MB-Loc 'outperforms the current state-of-the-art' on NCLT is presented without reference to the precise baseline implementations, training protocols, or error metrics (e.g., median translation/rotation error, success rate at fixed thresholds) used for comparison; without these details the magnitude and statistical significance of the reported gains cannot be verified.
Authors: We will expand the experimental section with a dedicated table and accompanying text that specifies the exact baseline implementations (including code references or re-implementation details), the training protocols (optimizer, learning-rate schedule, data splits), and the full set of error metrics (median translation/rotation error together with success rates at standard thresholds). Statistical significance tests will also be reported where appropriate. revision: yes
-
Referee: [§3.2] §3.2 (KL-regularized latent bottleneck): The claim that the bottleneck 'explicitly models spatial uncertainty without injecting stochastic noise' requires the explicit loss formulation and sampling procedure; the current description leaves open whether the regularization is applied only at training time or also affects deterministic inference, which directly affects the real-time efficiency claim.
Authors: We will insert the explicit loss formulation (KL divergence term plus reconstruction term) and the sampling procedure into §3.2. The regularization is applied exclusively during training; inference remains fully deterministic with no stochastic sampling, thereby preserving the claimed real-time efficiency. A short paragraph clarifying this distinction will be added. revision: yes
Circularity Check
No circularity: MB-Loc is an empirical engineering proposal with independent content
full rationale
The paper introduces a multi-planar BEV slicing method, KL-regularized bottleneck, and 3D augmentations as a practical architecture for viewpoint-robust SCR, evaluated empirically on the NCLT dataset. No equations, parameters, or central claims reduce by construction to fitted inputs, self-citations, or renamed prior results; the performance and efficiency assertions rest on experimental comparisons rather than tautological derivations. The representation choice is presented as an ansatz justified by computational tractability, not imported via self-citation chains or uniqueness theorems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. B. Rusu, N. Blodow, and M. Beetz. Fast point feature histograms (fpfh) for 3d registration. In2009 IEEE International Conference on Robotics and Automation, pages 3212–3217, 2009. doi:10.1109/ROBOT.2009.5152473
-
[2]
C. Choy, J. Park, and V . Koltun. Fully convolutional geometric features. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 8957–8965, 2019. doi:10.1109/ ICCV .2019.00905
arXiv 2019
-
[3]
M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography.Commun. ACM, 24(6):381–395, June 1981. ISSN 0001-0782. doi:10.1145/358669.358692. URLhttps://doi.org/10. 1145/358669.358692
-
[4]
W. Li, Y . Yang, S. Yu, G. Hu, C. Wen, M. Cheng, and C. Wang. Diffloc: Diffusion model for outdoor lidar localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15045–15054, 2024
2024
-
[5]
S. Wang, Q. Kang, R. She, W. Wang, K. Zhao, Y . Song, and W. P. Tay. Hypliloc: Towards effective lidar pose regression with hyperbolic fusion. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 5176–5185, 2023
2023
-
[6]
S. Yu, C. Wang, Y . Lin, C. Wen, M. Cheng, and G. Hu. Stcloc: Deep lidar localization with spatio-temporal constraints.IEEE Transactions on Intelligent Transportation Systems, 24(1): 489–500, 2023. doi:10.1109/TITS.2022.3213311
-
[7]
S. Yu, X. Sun, W. Li, C. Wen, Y . Yang, B. Si, G. Hu, and C. Wang. Nidaloc: Neurobiologically inspired deep lidar localization.IEEE Transactions on Intelligent Transportation Systems, 25 (5):4278–4289, 2024
2024
-
[8]
W. Wang, B. Wang, P. Zhao, C. Chen, R. Clark, B. Yang, A. Markham, and N. Trigoni. Point- loc: Deep pose regressor for lidar point cloud localization, 2021. URLhttps://arxiv.org/ abs/2003.02392
arXiv 2021
-
[9]
S. Yu, C. Wang, C. Wen, M. Cheng, M. Liu, Z. Zhang, and X. Li. Lidar-based localization using universal encoding and memory-aware regression.Pattern Recognition, 128:108685,
-
[10]
doi:https://doi.org/10.1016/j.patcog.2022.108685
ISSN 0031-3203. doi:https://doi.org/10.1016/j.patcog.2022.108685
-
[11]
W. Li, S. Yu, C. Wang, G. Hu, S. Shen, and C. Wen. Sgloc: Scene geometry encoding for outdoor lidar localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9286–9295, 2023
2023
-
[12]
B. Yang, Z. Li, W. Li, Z. Cai, C. Wen, Y . Zang, M. Muller, and C. Wang. Lisa: Lidar localiza- tion with semantic awareness. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15271–15280, 2024. doi:10.1109/CVPR52733.2024.01446
-
[13]
W. Li, C. Liu, S. Yu, D. Liu, Y . Zhou, S. Shen, C. Wen, and C. Wang. Lightloc: Learning outdoor lidar localization at light speed. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6680–6689, 2025
2025
-
[14]
N. Carlevaris-Bianco, A. Ushani, and R. Eustice. University of michigan north campus long- term vision and lidar dataset.The International Journal of Robotics Research, 35, 12 2015. doi:10.1177/0278364915614638
-
[15]
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy. Deep variational information bottleneck,
-
[16]
URLhttps://arxiv.org/abs/1612.00410
-
[17]
N. Tishby and N. Zaslavsky. Deep learning and the information bottleneck principle, 2015. URLhttps://arxiv.org/abs/1503.02406. 19
Pith/arXiv arXiv 2015
-
[18]
Kullback and R
S. Kullback and R. A. Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
1951
-
[19]
D. P. Kingma and M. Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[20]
X. Chen, T. L ¨abe, A. Milioto, T. R ¨ohling, O. Vysotska, A. Haag, J. Behley, and C. Stach- niss. Overlapnet: Loop closing for lidar-based slam. InRobotics: Science and Systems XVI, RSS2020. Robotics: Science and Systems Foundation, 2020. doi:10.15607/rss.2020.xvi.009. URLhttp://dx.doi.org/10.15607/RSS.2020.XVI.009
-
[21]
J. Ma, J. Zhang, J. Xu, R. Ai, W. Gu, and X. Chen. Overlaptransformer: An efficient and yaw-angle-invariant transformer network for lidar-based place recognition.IEEE Robotics and Automation Letters, 7(3):6958–6965, July 2022. ISSN 2377-3774. doi:10.1109/lra.2022. 3178797. URLhttp://dx.doi.org/10.1109/LRA.2022.3178797
-
[22]
X. Xu, H. Yin, Z. Chen, Y . Li, Y . Wang, and R. Xiong. Disco: Differentiable scan context with orientation.IEEE Robotics and Automation Letters, 6(2):2791–2798, 2021. doi:10.1109/ LRA.2021.3060741
arXiv 2021
-
[23]
G. Kim, S. Choi, and A. Kim. Scan context++: Structural place recognition robust to rotation and lateral variations in urban environments.IEEE Transactions on Robotics, 38(3):1856– 1874, 2021
2021
-
[24]
Tucker and N
R. Tucker and N. Snavely. Single-view view synthesis with multiplane images. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[25]
S. S. Jinka, A. Srivastava, C. Pokhariya, A. Sharma, and P. J. Narayanan. Sharp: Shape-aware reconstruction of people in loose clothing, 2022. URLhttps://arxiv.org/abs/2205. 11948
2022
-
[26]
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon. Cbam: Convolutional block attention module,
-
[27]
URLhttps://arxiv.org/abs/1807.06521
-
[28]
W. Kabsch. A solution for the best rotation to relate two sets of vectors.Acta Crystallographica Section A, 32(5):922–923, Sept. 1976. doi:10.1107/S0567739476001873
-
[29]
Barnes, M
D. Barnes, M. Gadd, P. Murcutt, P. Newman, and I. Posner. The oxford radar robotcar dataset: A radar extension to the oxford robotcar dataset. In2020 IEEE international conference on robotics and automation (ICRA), pages 6433–6438. IEEE, 2020
2020
-
[30]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[31]
M. A. Uy and G. H. Lee. Pointnetvlad: Deep point cloud based retrieval for large-scale place recognition. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[32]
Wang and J
Y . Wang and J. M. Solomon. Deep closest point: Learning representations for point cloud registration. InProceedings of the IEEE/CVF international conference on computer vision, pages 3523–3532, 2019
2019
-
[33]
A. Kumar, P. Sattigeri, and A. Balakrishnan. Variational inference of disentangled latent con- cepts from unlabeled observations.arXiv preprint arXiv:1711.00848, 2017
Pith/arXiv arXiv 2017
-
[34]
H. Tang, Z. Liu, S. Zhao, Y . Lin, J. Lin, H. Wang, and S. Han. Searching efficient 3d architec- tures with sparse point-voxel convolution. InEuropean conference on computer vision, pages 685–702. Springer, 2020. 20
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.