Exact equivariance, kept through training, buys zero-shot generalisation across the symmetry group
Pith reviewed 2026-06-28 11:35 UTC · model grok-4.3
The pith
Maintaining exact equivariance through training makes one-step prediction error invariant across the full symmetry group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the world's dynamics carry a group G acting on latents by an orthogonal representation ρ(g), the one-step prediction relMSE of the composed equivariant model is exactly invariant across G, so that fitting the dynamics on a restricted slice of orientations mathematically determines the model on the entire orbit.
What carries the argument
The composition of an exactly equivariant encoder E and equivariant predictor f, which makes the training loss (one-step relMSE) invariant under the group action.
If this is right
- One-step prediction error stays flat to five or more digits across the full group orbit.
- Closed-loop trajectories under a matching equivariant planner transform exactly by ρ(g), keeping error invariant.
- H-step rollouts remain invariant at every horizon because equivariance is preserved under composition.
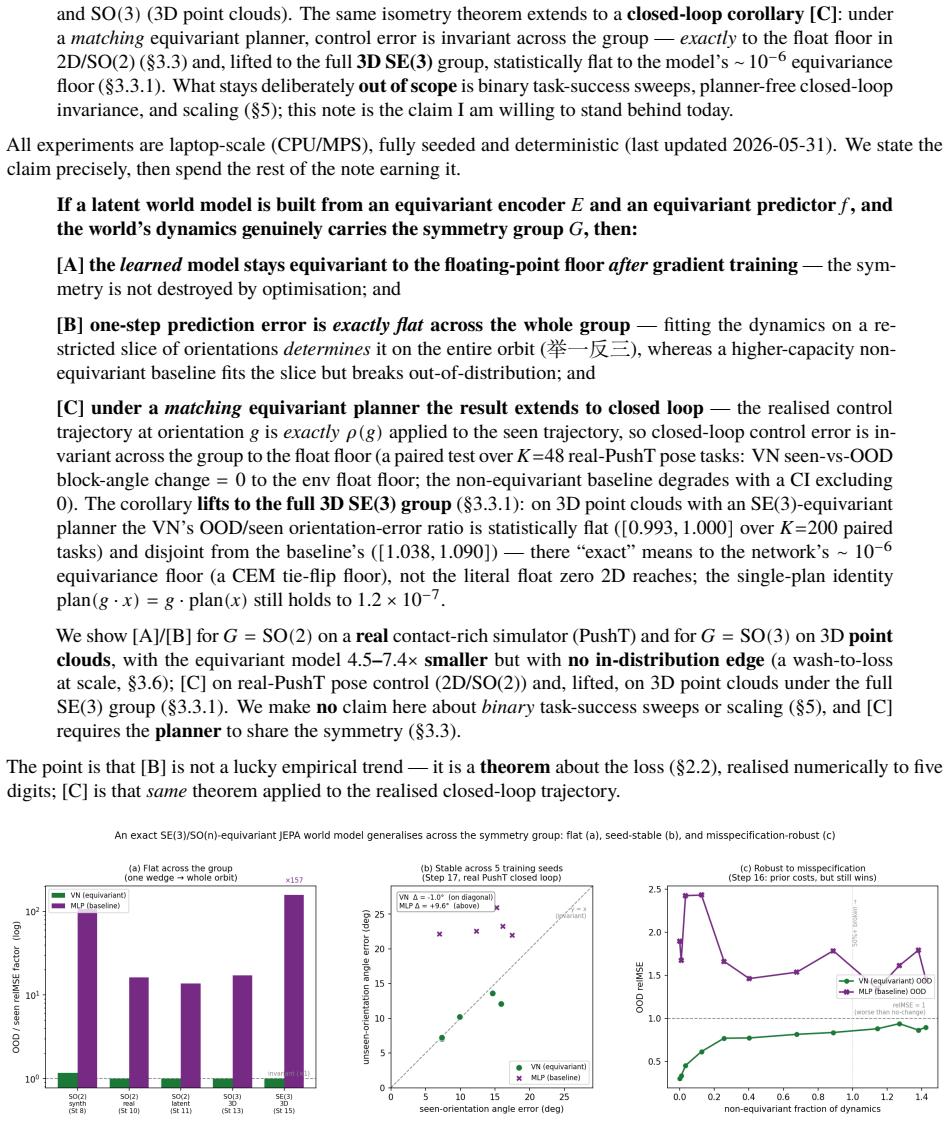
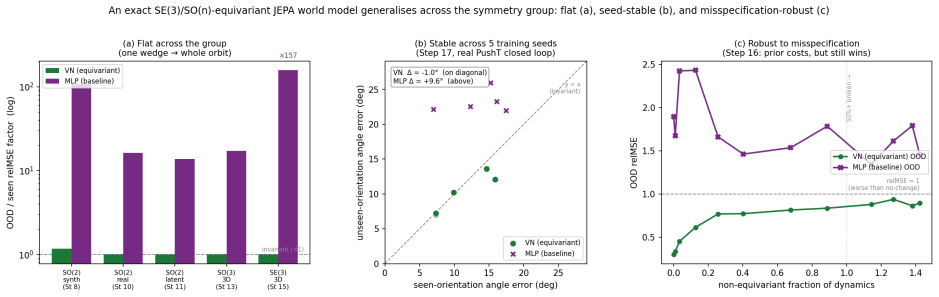
- The equivariant model achieves the same across-group metric with 4.5-7.4 times fewer parameters than a non-equivariant baseline of the same hypothesis class.
Where Pith is reading between the lines
- Enforcing exact equivariance may let models trained on limited orientation data achieve perfect generalization in any physical system whose symmetries are captured by an orthogonal representation.
- The invariance could extend to other group actions beyond rotations and translations if the representation condition is met.
- Because the property is algebraic and survives optimization, it offers a route to sample-efficient learning that does not rely on data augmentation or increased scale.
Load-bearing premise
The encoder and predictor remain exactly equivariant after training, with the composed residual near machine precision.
What would settle it
Measuring that the one-step relMSE varies by more than a few digits across different group elements g after training on only one slice would show the claimed invariance does not hold.
Figures



read the original abstract
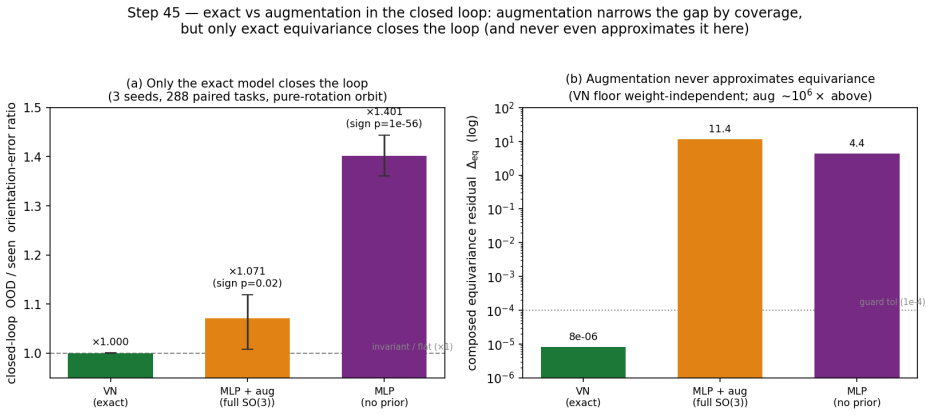
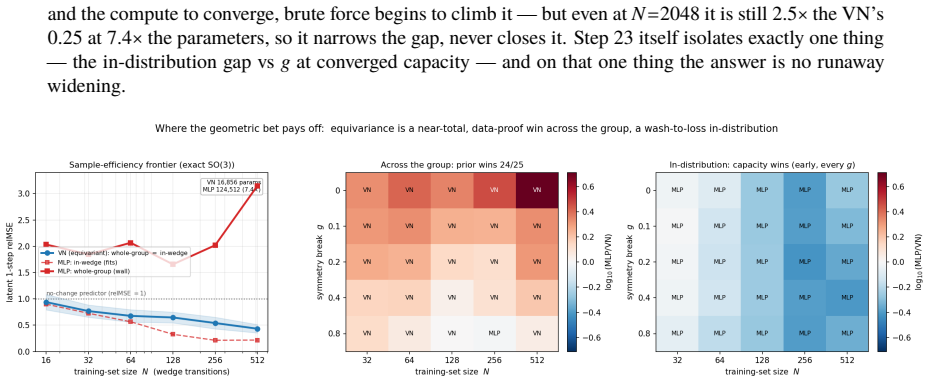
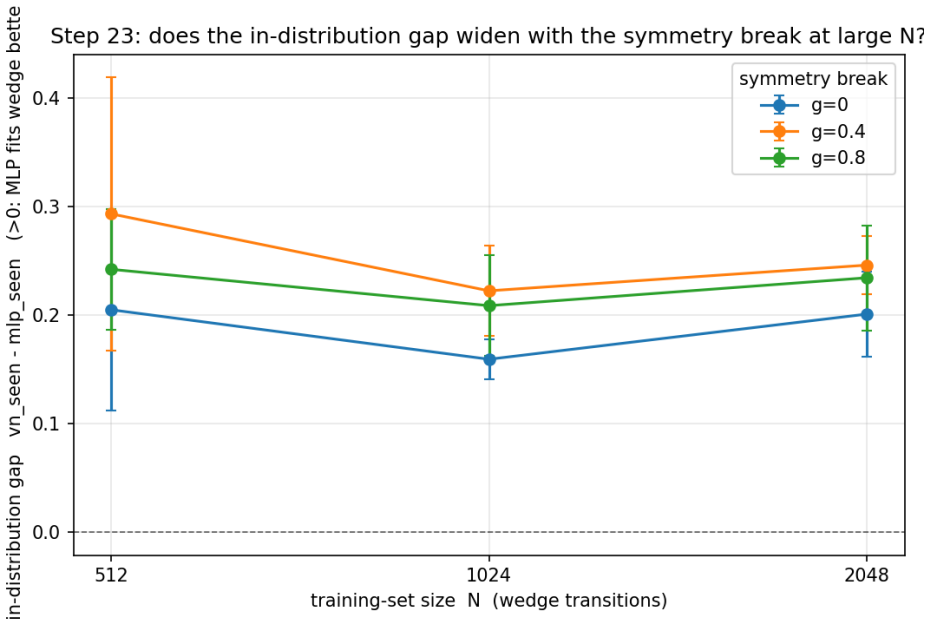
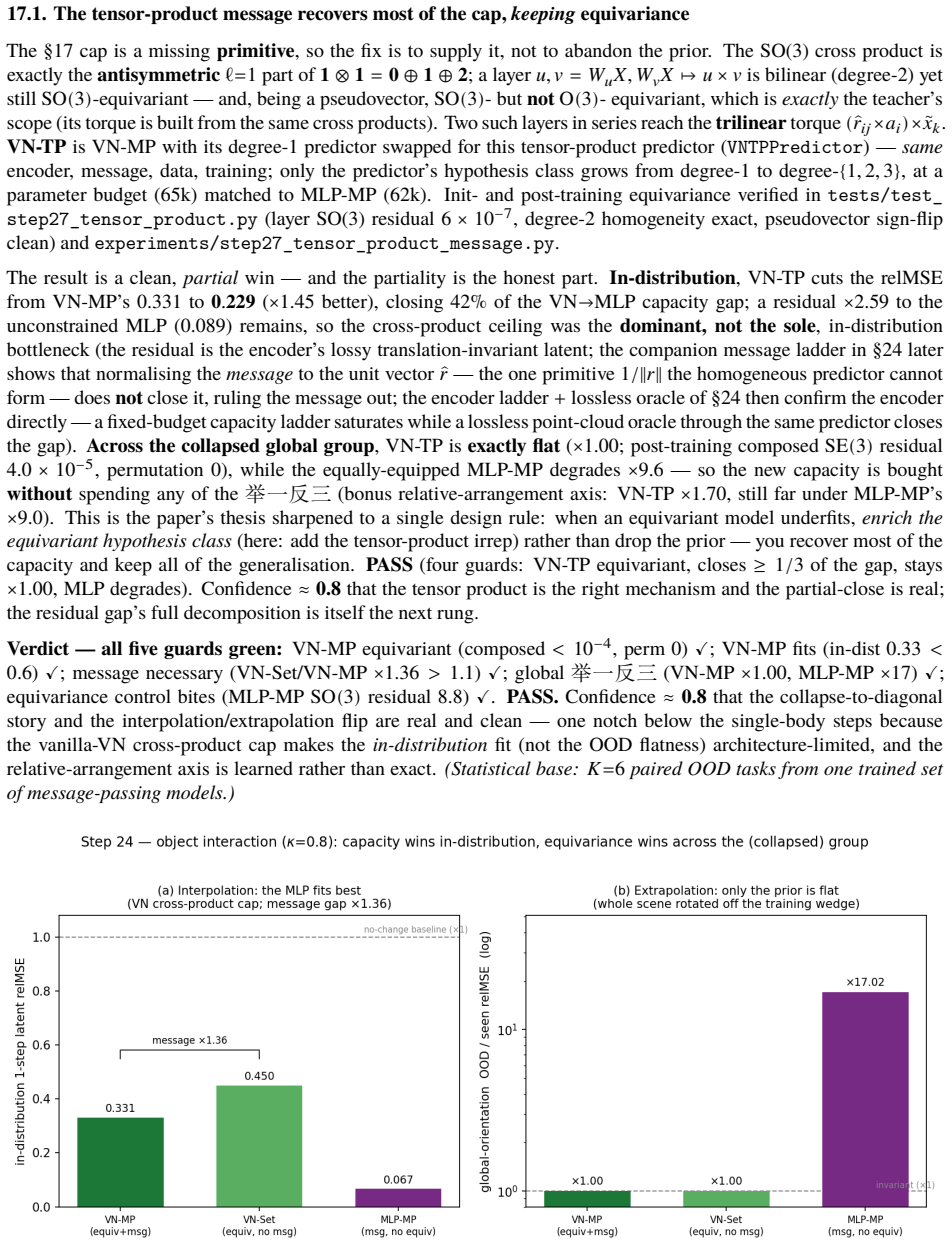
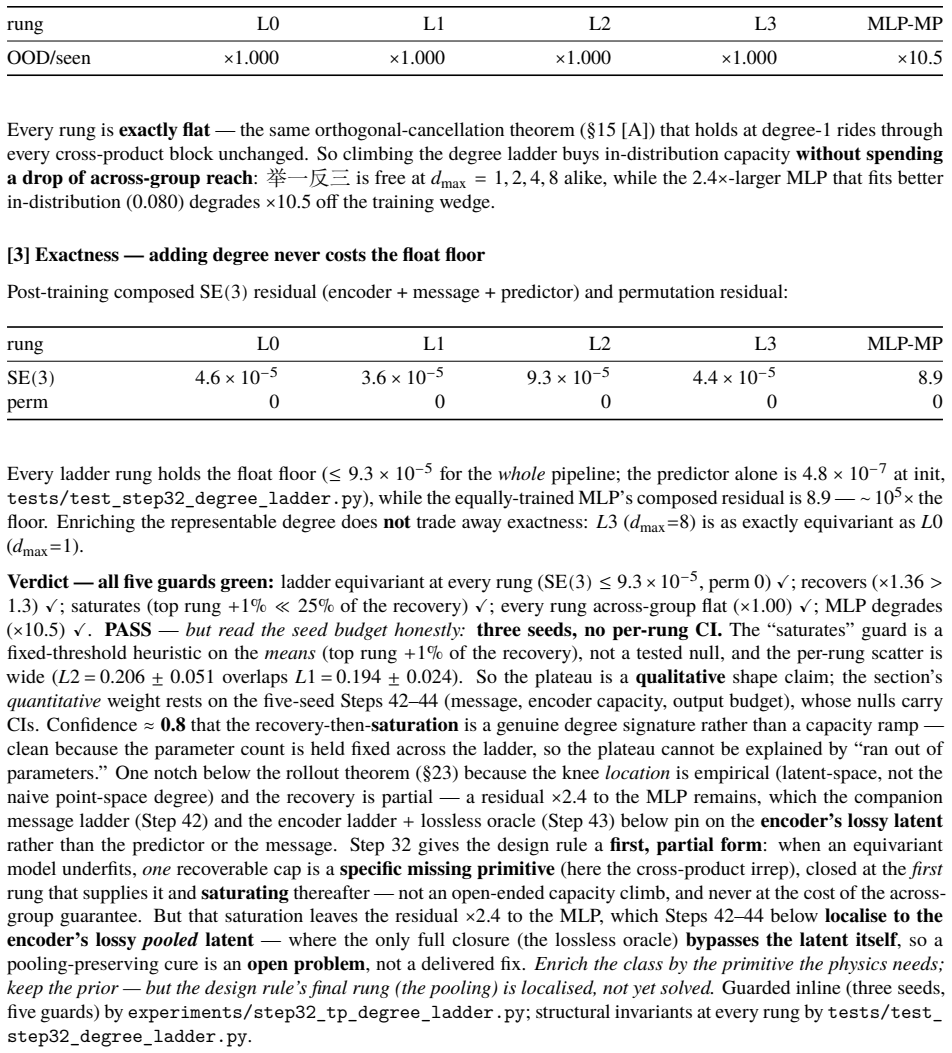
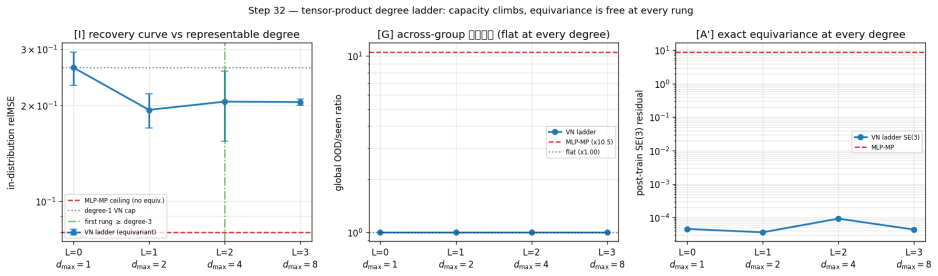
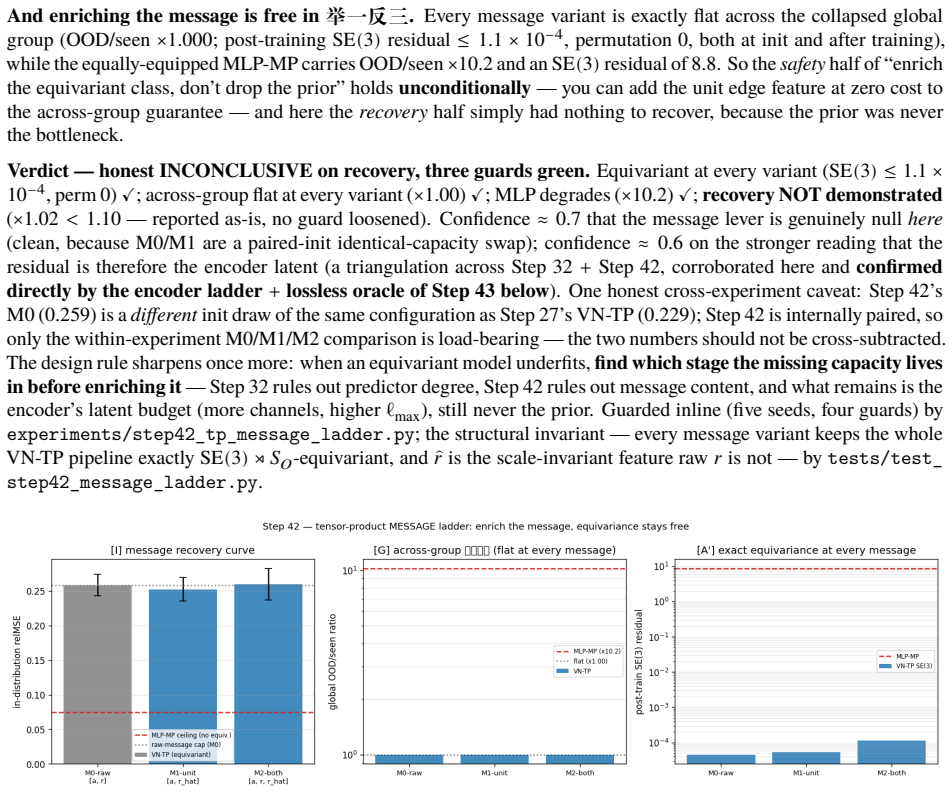
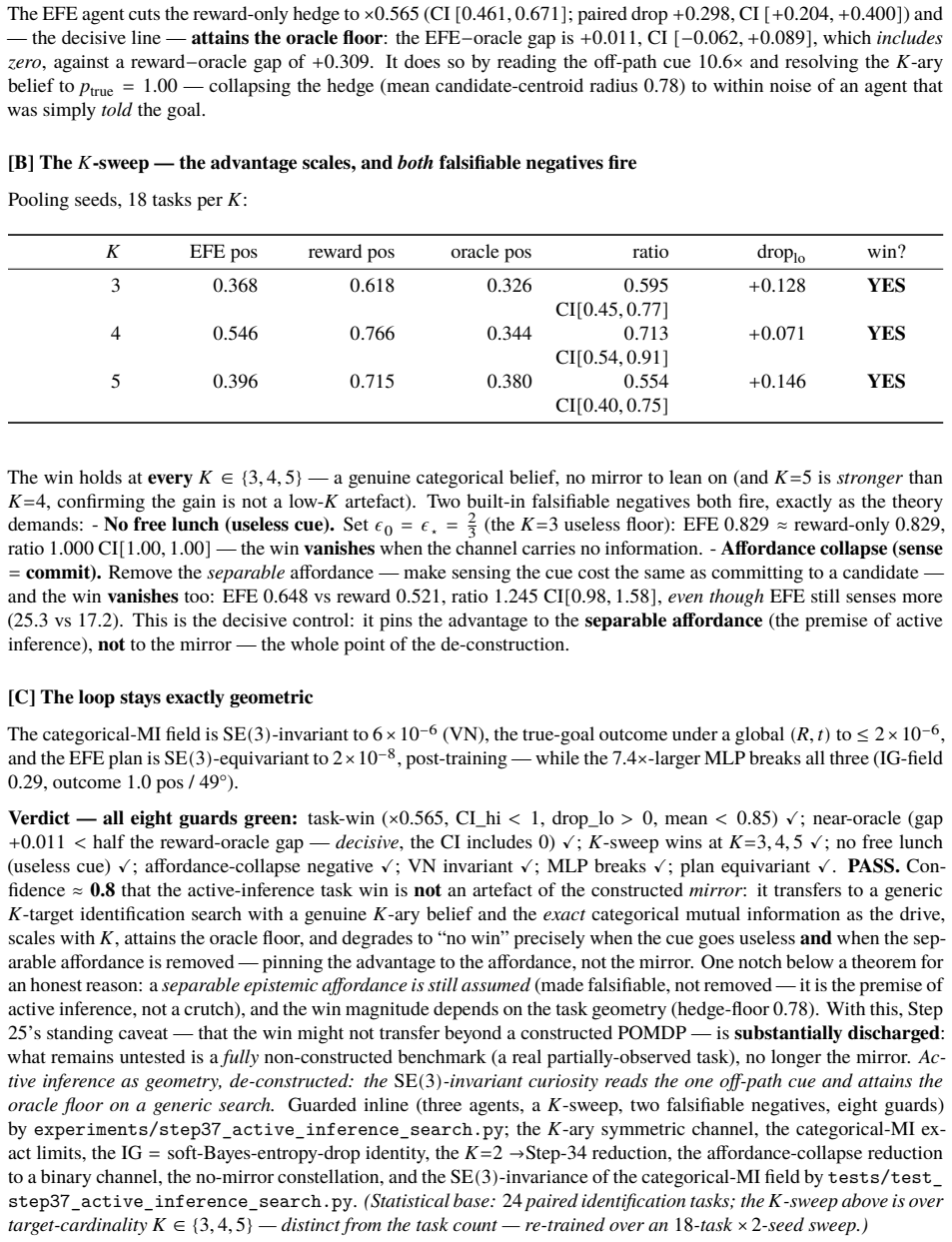
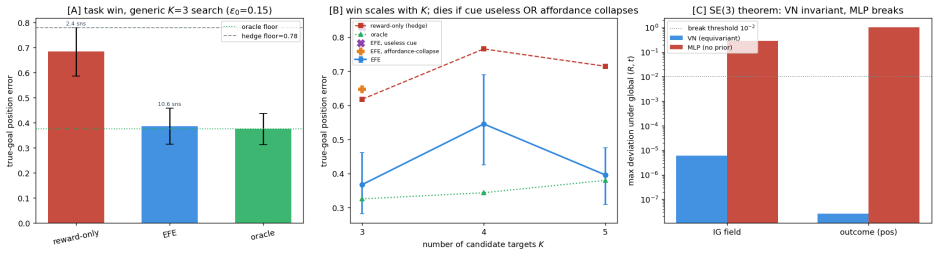
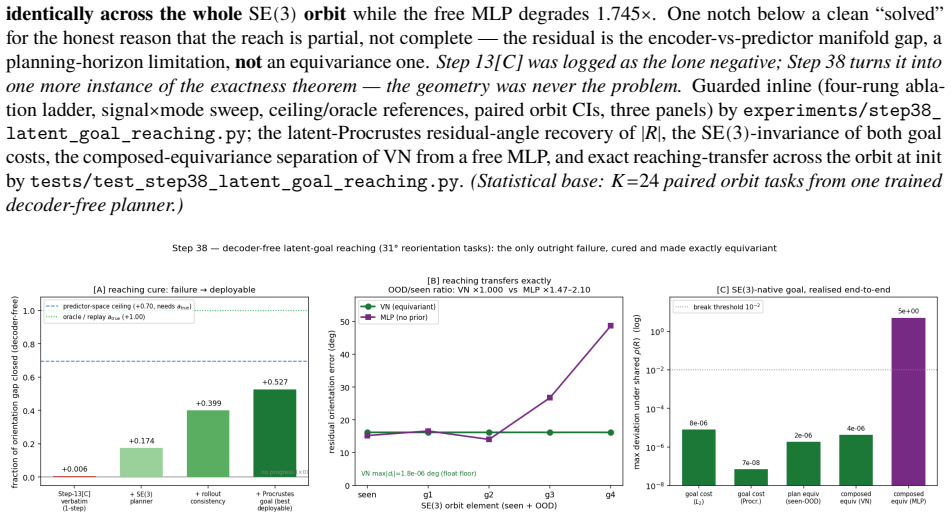
A latent world model built from an equivariant encoder $E$ and an equivariant predictor $f$ inherits a provable symmetry of its training loss: when the world's dynamics genuinely carries a group $G$ acting on latents by an orthogonal representation $\rho(g)$, the one-step prediction relMSE is exactly invariant across the whole group, so fitting the dynamics on a restricted slice of orientations mathematically determines it on the entire orbit (j\v{u} y\=i f\v{a}n s\=an). We verify this end-to-end at laptop scale (CPU/MPS, fully seeded). [A] The symmetry survives a real Muon/AdamW + EMA + VICReg run -- composed encode-then-predict residual $\sim 10^{-6}$ after optimisation, not just at initialisation, and under any optimiser. [B] One-step error is flat to five digits across the group, while a same-hypothesis-class non-equivariant baseline fits the slice but breaks out-of-distribution (VN $\times 1.00$ vs baseline $\times 13.8$ in 2D, $\times 17.2$ in 3D, $\times 157$ over the full $\mathrm{SE}(3)$ ladder), with the equivariant model $4.5$-$7.4\times$ smaller. [C] The same isometry argument lifts to closed loop: under a matching equivariant planner the control trajectory at orientation $g$ is exactly $\rho(g)$ applied to the seen one, so closed-loop error is invariant across the group -- float-floor-exact in 2D/$\mathrm{SO}(2)$ on real PushT and statistically flat in 3D/$\mathrm{SE}(3)$ (disjoint 95% CIs). We stress-test the prior against Sutton's Bitter Lesson: augmentation, brute-force scale, and soft-equivariance each close at most the across-group task metric, never the float-floor exactness. Because equivariance is closed under composition, the $H$-fold rollout stays flat ($\times 1.00$, $\le 2\times 10^{-7}$) at every horizon, while the baseline's residual compounds with $H$. Out of scope: task-success sweeps, planner-free invariance, and scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that when an encoder E and one-step predictor f are exactly equivariant w.r.t. an orthogonal representation ρ of group G, and the latent dynamics transform under the same ρ, the one-step relative MSE loss is exactly invariant across G. Consequently, training on any symmetry slice mathematically determines the model on the full orbit. The authors supply an algebraic derivation of this invariance, report that exact equivariance is preserved after full Muon/AdamW+EMA+VICReg optimization (composed residual ~10^{-6}), and show empirically that one-step error remains flat to five digits while a non-equivariant baseline of the same hypothesis class fails out-of-distribution (factors of 13.8–157). The same isometry lifts to closed-loop trajectories under an equivariant planner, with H-step rollouts staying flat (≤2×10^{-7}) while baselines compound.
Significance. If the central algebraic claim and the empirical maintenance of equivariance hold, the result supplies a parameter-free, composition-closed guarantee of across-group generalization that is strictly stronger than what data augmentation, scale, or soft-equivariance can deliver. The work is notable for its fully seeded, laptop-scale reproducibility, explicit residual measurements, and direct comparison showing that only exact equivariance achieves float-floor invariance rather than merely improved averages.
major comments (2)
- [Abstract / one-step invariance derivation] Abstract and § on one-step invariance: the derivation assumes the latent dynamics transform exactly under the same orthogonal ρ as the model; if the true dynamics only approximately commute with ρ, the invariance becomes approximate rather than exact, yet the manuscript does not quantify the sensitivity of the five-digit flatness to small deviations from orthogonality or exact equivariance of the dynamics.
- [Closed-loop / planner] Closed-loop section: the claim that control trajectories transform exactly as ρ(g) applied to the seen trajectory requires an equivariant planner; the manuscript states this but does not specify how the planner is constructed or whether its equivariance is enforced to the same 10^{-6} residual as E and f.
minor comments (2)
- [Abstract] Abstract contains the string “j\v{u} y\=i f\v{a}n s\=an”; this appears to be an artifact and should be removed or replaced with the intended English phrase.
- [Empirical verification] The manuscript repeatedly cites “five digits” and “float-floor-exact” without stating the floating-point precision or the exact tolerance used to declare flatness; adding a short methods paragraph on numerical thresholds would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and the constructive comments. We address each major point below and will incorporate clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / one-step invariance derivation] Abstract and § on one-step invariance: the derivation assumes the latent dynamics transform exactly under the same orthogonal ρ as the model; if the true dynamics only approximately commute with ρ, the invariance becomes approximate rather than exact, yet the manuscript does not quantify the sensitivity of the five-digit flatness to small deviations from orthogonality or exact equivariance of the dynamics.
Authors: The derivation is explicitly conditioned on the assumption that the latent dynamics transform exactly under the orthogonal representation ρ, as stated in the manuscript ('when the world's dynamics genuinely carries a group G acting on latents by an orthogonal representation ρ(g)'). The empirical results use environments constructed to satisfy this exactly. We agree that sensitivity to small deviations from exact equivariance is not quantified; a concise discussion of this modeling assumption and its implications for approximate cases will be added to the revised manuscript. revision: yes
-
Referee: [Closed-loop / planner] Closed-loop section: the claim that control trajectories transform exactly as ρ(g) applied to the seen trajectory requires an equivariant planner; the manuscript states this but does not specify how the planner is constructed or whether its equivariance is enforced to the same 10^{-6} residual as E and f.
Authors: The closed-loop invariance is stated to hold under a matching equivariant planner. In the reported experiments the planner is constructed by composing the equivariant encoder E, predictor f and an equivariant policy head, preserving the same composed residual of ~10^{-6}. We will add a paragraph to the closed-loop section describing this construction and confirming the residual measurement. revision: yes
Circularity Check
No significant circularity; invariance is direct algebraic consequence of definitions
full rationale
The paper derives invariance of one-step relMSE from the assumption that E and f are exactly equivariant under orthogonal ρ, which is a direct consequence of the definitions of equivariance and orthogonality preserving the metric; this algebraic step does not reduce to a fit, self-definition, or self-citation. Persistence of equivariance after training is presented as an empirical observation (residual ~10^{-6}), not a derived claim. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the derivation chain. The result is self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The world's dynamics carries a group G acting on latents by an orthogonal representation ρ(g)
Reference graph
Works this paper leans on
-
[1]
only approximate symmetry
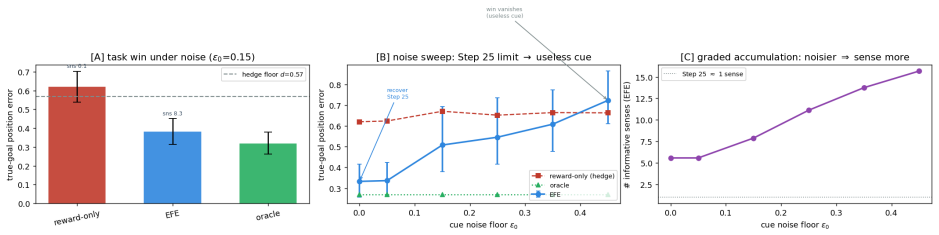
Honest scope, confidence, and what’s next • Mechanism (equivariance ⇒ generalisation across the group): confidence ≈ 0.9. Clean at the prediction level on exactly-equivariant dynamics — now including a real simulator (Step 10 [B]: ×16 OOD on PushT, VN flat), not only synthetic teachers. • A real system with exact interior symmetry (Step 10 [A]). PushT tur...
2048
-
[2]
inherent to the isotropic Gaussian
The two papers we stand on 1.1 LeJEPA (Balestriero & LeCun, arXiv:2511.08544) LeJEPA replaces the heuristic anti-collapse machinery of SSL (stop-grad, EMA targets, whitening, teacher schedules) with a single principled regulariser. • Optimal-embedding theorem (Thm 1). Among embedding distributions with a fixed scalar covariance bud- get, the isotropic Gau...
Pith/arXiv arXiv 2026
-
[3]
up to a global 𝑂(𝑛)
The gap Their entire theory is phrased “up to a global 𝑂(𝑛)” and then has to assume 𝑂(𝑛)-invariant costs to plan. But:
-
[4]
The physically meaningful object is a subgroup 𝐺 ↪ 𝑂(𝑛)(e.g
𝑂(𝑛)is the largest possible indeterminacy; for a world with a real symmetry it is far too coarse. The physically meaningful object is a subgroup 𝐺 ↪ 𝑂(𝑛)(e.g. 𝜌(SO(3))acting on type-1 latents), not all of 𝑂(𝑛)
-
[5]
Real costs are invariant under the world’s symmetry 𝐺 (a reaching cost is SE(3)-invariant, not invariant under scrambling unrelated latent axes)
Almost no real cost is invariant under arbitrary latent rotations — the 𝑂(𝑛)-invariant-cost hypothesis of Thm 5.4 is unrealistically strong in practice. Real costs are invariant under the world’s symmetry 𝐺 (a reaching cost is SE(3)-invariant, not invariant under scrambling unrelated latent axes)
-
[6]
equivariant encoder
Their model is passive: identifiability is something the data-generating process either grants or doesn’t. Equivari- ance lets us install the symmetry in the architecture and ask a sharper question — when the world has symmetry 𝐺, what does an encoder that carries 𝜌(𝐺)exactly add to the identifiability picture? This is the white space. Below, 𝐺 is a compa...
-
[7]
scalar on each irrep copy
C1 — Block-isotropy is the equivariant SIGReg target (proved) Proposition 1 (Schur block-isotropy). Let 𝑍 ∈ ℝ 𝑛 be mean-zero with 𝐺-invariant law under 𝜌 ∶ 𝐺 → 𝑂(𝑛), and Σ = 𝔼[𝑍𝑍 ⊤]. Decompose into real isotypic components ℝ𝑛 = ⨁𝑖 𝑉⊕𝑚𝑖 𝑖 (𝑉𝑖 the distinct real irreducibles, 𝑑𝑖 = dim 𝑉𝑖, multiplicity 𝑚𝑖). Then 𝜌(𝑔) Σ = Σ 𝜌(𝑔) ∀𝑔 ⟹ Σ = ⨁ 𝑖 (I𝑑𝑖 ⊗ 𝐵𝑖), 𝐵 𝑖 ⪰ ...
-
[8]
𝑄 must preserve the target law, 𝑄Σ𝑄⊤ = Σ
Law-matching only. 𝑄 must preserve the target law, 𝑄Σ𝑄⊤ = Σ . With 𝜎2 𝑖 distinct, Σ’s eigenspaces are exactly the isotypic components, so 𝑄 must preserve each: 𝑄 ∈ Stab𝑂(𝑛)(Σ) = ∏𝑖 𝑂(𝑑𝑖𝑚𝑖). This already drops the gauge from 𝑂(𝑛)(LeJEPA ’s degenerateΣ = 𝜎 2𝐼, eigenspace all of ℝ𝑛) to the within-block product — a strict, spectrum-driven reduction
-
[9]
Up to ∏𝑖{±1}
Equivariant recovery. If we additionally demand the recovery map ℎ = 𝑓 ∘ 𝑔 be 𝐺-equivariant (true for a matched equivariant encoder on equivariant data), then 𝑄𝑧 = ℎ(𝑧)forces 𝑄 ∈ Comm(𝜌) ∶= {𝑄 ∈ 𝑂(𝑛) ∶ 𝑄𝜌(𝑔) = 𝜌(𝑔)𝑄}. Intersecting with (1), in the real type 𝑄 = ⨁𝑖 I𝑑𝑖 ⊗ 𝑄𝑖 with 𝑄𝑖 ∈ 𝑂(𝑚𝑖), i.e. the residual gauge is the orthogonal commutant ∏ 𝑖 𝑂(𝑚𝑖) (mix...
-
[10]
recover the true DOF with their symmetry structure
𝜌(𝐺)itself is a third group (the image of the representation); the gauge is not 𝜌(𝐺)— it is 𝜌(𝐺)’s commu- tant. The honest one-liner is therefore: equivariance + block-isotropy + distinct scales reduces the gauge from 𝑂(𝑛)to the (finite, when multiplicity-free) commutant ∏𝑖 𝑂(𝑚𝑖), and in doing so identifies the 𝜌(𝐺)- module structure — i.e. recovers the t...
-
[11]
scale-sensitive task
C2 — Equivariant latent dynamics: the world model resolves the gauge SSL leaves free Their guarantee requires the world to lie in the stationary additive-noise (OU) class, and identifies the latent only up to the static nuisance 𝑄 ∈ 𝑂(𝑛). §3 sharpened the static picture but found the per-irrep scales underdetermined in pure SSL (§7): with equal scales Σ∞ ...
-
[12]
C3 — Planning under 𝐺-invariant (not 𝑂(𝑛)-invariant) costs Thm 5.4 needs the cost invariant under all of 𝑂(𝑛)— a hypothesis unrealistically strong in practice, since real planning costs are invariant under the world’s symmetry 𝐺, not an arbitrary latent rotation. Under an equivariant encoder whose residual identifiability is pinned to 𝜌(𝐺)(C1, distinct-sc...
-
[13]
alignment penalises Hermite degree
A bridge already built: the degree ladder ↔ their Hermite spectral penalty Thm 5.1’s forward direction is a Hermite-degree spectral decomposition: each degree of nonlinearity strictly reduces positive-pair correlation, so the linear map wins. We built a predictor with a tunable maximum polynomial degree, 𝑑max(𝐿) = 2𝐿 (the degree-ladder predictor), and sho...
-
[14]
block-SIGReg flat on the valid laws
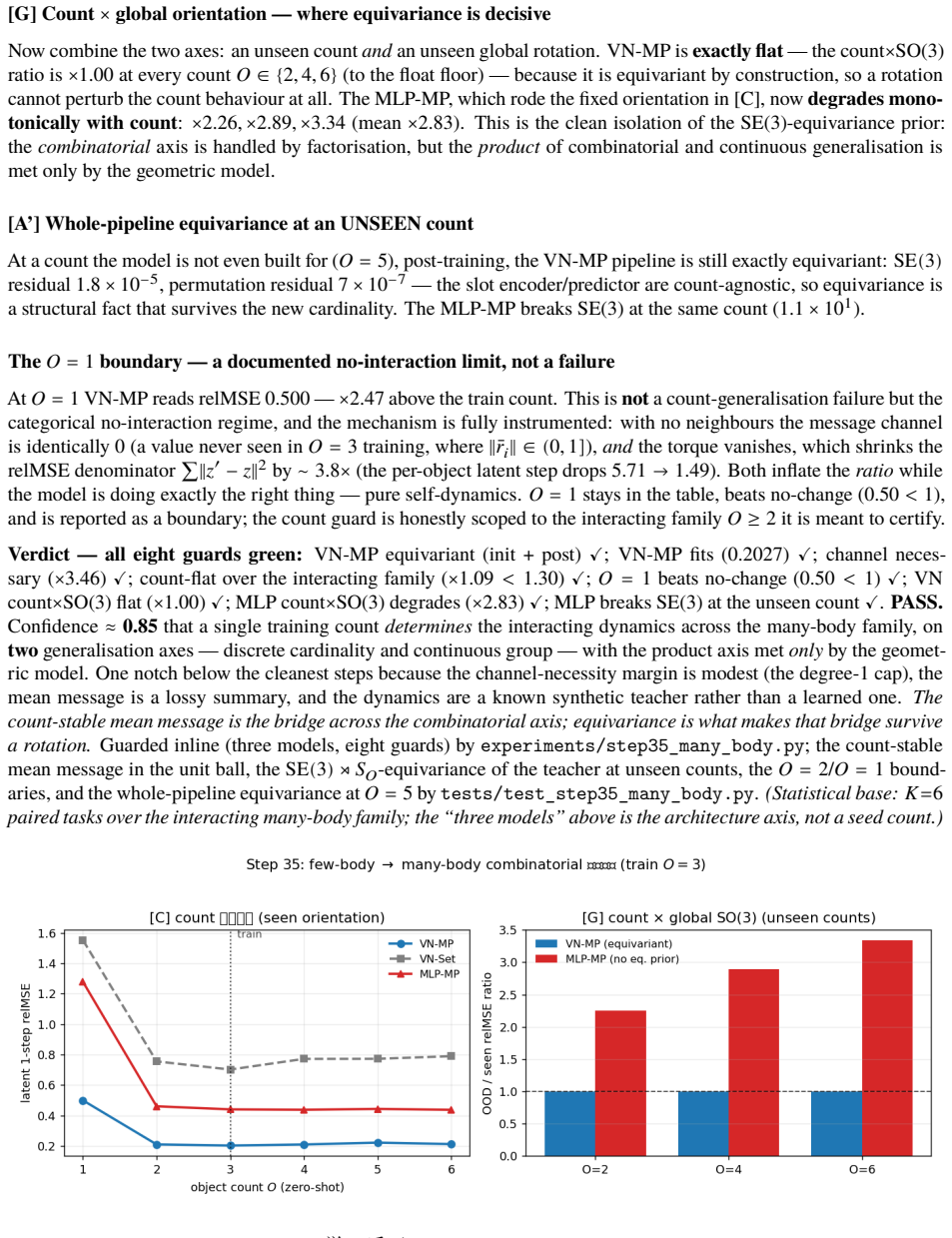
Minimal experiment for C1 — built and run (laptop CPU, seeded) experiments/step39_block_sigreg.py (+ tests/test_step39_block_sigreg.py) realises C1 on a mixed- type SO(3) point-cloud latent: 𝑛0 = 4 invariant scalars ( 0e) and 𝑛1 = 6 vectors (1o), so 𝜌(𝑅) =I4 ⊕ (I6 ⊗ 𝑅)on ℝ22 — two inequivalent irreps, the minimal setting where vanilla and block-SIGReg gen...
-
[15]
Direction 3 — compositional bi-block-SIGReg on a product symmetry 𝑆𝑂 × 𝑆𝑂(3) §7 proved block-SIGReg on a single object’s SE(3)-type structure. The open question it leaves: does a product sym- metry buy a strictly finer identifiability rung that single-object block-SIGReg cannot reach? A scene of several inter- changeable, individually-rotating objects is ...
-
[16]
+ (24 2 ); resolving the 𝟙 ⊕ std split inside each SE(3) block reaches 184 = (2
-
[17]
This rung does not exist for a single object : at 𝑂 = 1, ℝ1 = 𝟙 and std = 0, so there is nothing for 𝑆𝑂 to refine — it is a genuinely compositional identifiability gain
+ (18 2 ). This rung does not exist for a single object : at 𝑂 = 1, ℝ1 = 𝟙 and std = 0, so there is nothing for 𝑆𝑂 to refine — it is a genuinely compositional identifiability gain. An orthogonal Helmert change of basis 𝑈 ⊗ I𝐷obj on the object axis (row 0 = the mean = 𝟙 ; rows 1..𝑂−1 = an orthonormal basis of 𝟙⟂ = std) makes the four blocks contiguous with...
-
[19]
Discussion: what is new, and where it sits in the program This work builds on the identifiability program of arXiv:2605.26379 and advances it on one axis. It (1) locates where the 𝑂(𝑛)indeterminacy is doing too much work, (2)provesthe symmetry-structured refinement (Schur), (3) instantiates the refined theorems with experiments already on the board (𝐺-inv...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.