DARE-EEG: A Foundation Model for Mining Dual-Aligned Representation of EEG
Pith reviewed 2026-05-20 10:00 UTC · model grok-4.3
The pith
DARE-EEG pre-trains EEG encoders to enforce mask-invariance by aligning multiple masked views of the same signal into a consistent latent subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DARE-EEG is a foundation model that explicitly enforces the mask-invariance property during pre-training by introducing mask alignment, which constrains representations from multiple masked views of the same EEG sample via contrastive learning, together with anchor alignment that aligns masked representations to momentum-updated complete features for semantic stability, plus conv-linear-probing that adapts the representations to heterogeneous electrode configurations and sampling rates through decoupled spectro-spatial projections.
What carries the argument
Dual-aligned representation learning, which uses contrastive learning to align multiple masked views of one EEG sample and momentum alignment to tie those views to stable complete-signal features.
If this is right
- State-of-the-art accuracy on diverse EEG benchmarks while keeping parameter counts relatively low.
- Superior portability when the same pre-trained model is applied to new datasets with different electrode configurations or sampling rates.
- More effective discovery of rich latent representations within EEG signals for downstream brain-computer interface tasks.
Where Pith is reading between the lines
- The same dual-alignment pattern could be tested on other biosignals such as ECG to check whether mask-invariance helps transfer across recording hardware.
- Real-time closed-loop BCI experiments would show whether the learned invariance reduces retraining needs when electrode placement varies session to session.
Load-bearing premise
That forcing representations from different masked views of the same EEG signal into one consistent latent subspace will automatically produce better transfer across datasets that differ in electrodes and sampling rates.
What would settle it
A controlled ablation that trains identical models with and without the dual-alignment losses and measures accuracy drop on a cross-dataset transfer task where masked views share minimal temporal overlap.
Figures








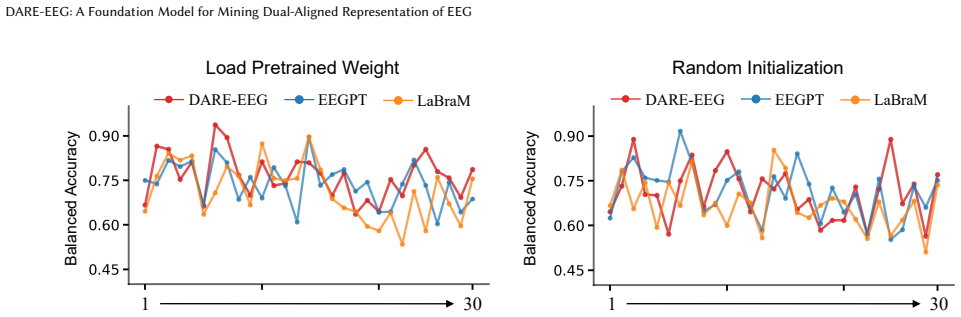



read the original abstract
Foundation models pre-trained through masked reconstruction on large-scale EEG data have emerged as a promising paradigm for learning generalizable neural representations across diverse brain-computer interface applications. However, a critical yet overlooked challenge is that EEG encoders must learn representations invariant to incomplete observations-when different masked views of the same signal have minimal overlap, existing methods fail to constrain them to a consistent latent subspace, leading to degraded transferability. To address this, we propose DARE-EEG, a self-supervised foundation model that explicitly enforces the mask-invariance property through dual-aligned representation learning during pre-training. Specifically, we introduce mask alignment that constrains representations from multiple masked views of the same EEG sample via contrastive learning, complementing anchor alignment that aligns masked representations to momentum-updated complete features for semantic stability. Additionally, we propose conv-linear-probing, a parameter-efficient strategy that adapts pre-trained representations to heterogeneous electrode configurations and sampling rates through decoupled spectro-spatial projections. Extensive experiments across diverse EEG benchmarks demonstrate that DARE-EEG consistently achieves state-of-the-art in accuracy performance while maintaining relatively low parameter complexity and superior cross-dataset portability compared to existing methods. Furthermore, DARE-EEG contributes to effectively discovering and utilizing the rich potential representations in EEG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DARE-EEG, a self-supervised EEG foundation model that enforces mask-invariance during pre-training via dual-aligned representation learning: mask alignment (contrastive learning on multiple masked views of the same sample) combined with anchor alignment (momentum-updated complete features for semantic stability). It introduces conv-linear-probing as a parameter-efficient adaptation mechanism for heterogeneous electrode configurations and sampling rates. Experiments across EEG benchmarks claim state-of-the-art accuracy, low parameter complexity, and superior cross-dataset portability relative to prior masked-reconstruction baselines.
Significance. If the results hold after isolating the contribution of the alignment objectives, the work would offer a concrete mechanism for improving representation consistency under incomplete observations, which is a practical bottleneck in EEG transfer learning. The conv-linear-probing strategy is a clear engineering contribution for deployment across variable hardware setups.
major comments (2)
- [§3.2] §3.2 (Dual-Aligned Pre-training): the central claim that dual alignment produces superior cross-dataset portability rests on the untested assumption that the contrastive mask-alignment and momentum-anchor terms measurably tighten the latent subspace beyond what standard masked reconstruction already achieves. No invariance metric (e.g., average cosine similarity or mutual information between differently masked views of the same sample) is reported.
- [§4.3] §4.3 and Table 4 (Cross-dataset Portability): the reported gains are not accompanied by ablations that remove only the two alignment losses while keeping the conv-linear-probing head and all other hyperparameters fixed. Without this control, the portability advantage cannot be confidently attributed to the proposed dual-alignment rather than to the probing strategy or dataset-specific factors.
minor comments (2)
- [Figure 2] Figure 2 (architecture diagram): the flow from masked views through the dual-alignment heads to the momentum encoder is difficult to follow; adding explicit arrows or a legend for the contrastive and anchor losses would improve clarity.
- [§4.1] §4.1 (Experimental Setup): the description of how electrode configurations and sampling rates are normalized across source and target datasets is brief; a short table listing the exact channel counts and rates for each benchmark would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the contribution of the dual-alignment objectives. We respond to each major comment below and have revised the manuscript accordingly to provide additional evidence.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Dual-Aligned Pre-training): the central claim that dual alignment produces superior cross-dataset portability rests on the untested assumption that the contrastive mask-alignment and momentum-anchor terms measurably tighten the latent subspace beyond what standard masked reconstruction already achieves. No invariance metric (e.g., average cosine similarity or mutual information between differently masked views of the same sample) is reported.
Authors: We agree that an explicit invariance metric would strengthen the presentation of the mask-invariance property. In the revised manuscript we have added a quantitative analysis in §3.2 (and supplementary material) that reports average cosine similarity between representations of differently masked views of the same sample. The results show that the combination of mask alignment and anchor alignment yields measurably higher similarity scores than the masked-reconstruction baseline alone, supporting the claim that dual alignment tightens the latent subspace. revision: yes
-
Referee: [§4.3] §4.3 and Table 4 (Cross-dataset Portability): the reported gains are not accompanied by ablations that remove only the two alignment losses while keeping the conv-linear-probing head and all other hyperparameters fixed. Without this control, the portability advantage cannot be confidently attributed to the proposed dual-alignment rather than to the probing strategy or dataset-specific factors.
Authors: We acknowledge the value of isolating the alignment losses. The revised manuscript now includes an ablation in §4.3 that removes only the mask-alignment and anchor-alignment terms while retaining the conv-linear-probing head and all other hyperparameters. The updated Table 4 and accompanying text show that cross-dataset portability degrades when the alignment objectives are ablated, indicating that the dual-alignment mechanism contributes to the observed gains beyond the probing strategy. revision: yes
Circularity Check
No circularity: derivation chain is self-contained and empirically grounded
full rationale
The paper introduces dual-aligned contrastive and momentum alignment as explicit new objectives to enforce mask-invariance during self-supervised pre-training on EEG data, then validates resulting portability gains through experiments on heterogeneous datasets using conv-linear-probing adaptation. No load-bearing step reduces by construction to its own inputs: the alignment losses are not fitted parameters renamed as predictions, no self-citation chain justifies a uniqueness claim, and no ansatz or renaming of known results is presented as a derivation. The central claims rest on the proposed architectural additions and benchmark results rather than tautological equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Masked reconstruction on large-scale EEG data learns generalizable neural representations across BCI applications
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce mask alignment that constrains representations from multiple masked views of the same EEG sample via contrastive learning, complementing anchor alignment that aligns masked representations to momentum-updated complete features
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DARE-EEG consistently achieves state-of-the-art in accuracy performance while maintaining relatively low parameter complexity and superior cross-dataset portability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Al- shehri, Sultan Almakdi, Yazeed Yasin Ghadi, and Jawad Ahmad
Saadullah Farooq Abbasi, Awais Abbas, Iftikhar Ahmad, Mohammed S. Al- shehri, Sultan Almakdi, Yazeed Yasin Ghadi, and Jawad Ahmad. 2023. Automatic neonatal sleep stage classification: A comparative study.Heliyon9, 11 (2023). doi:10.1016/j.heliyon.2023.e22195
-
[2]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli. 2022. data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language. InProceedings of the 39th International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csa...
work page 2022
-
[3]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. 2021. Emerging Properties in Self-Supervised Vision Transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, Montreal, QC, Canada, 9650–9660. doi:10.1109/ ICCV48922.2021.00951
-
[4]
Ching Chang, Chiao-Tung Chan, Wei-Yao Wang, Wen-Chih Peng, and Tien-Fu Chen. 2024. TimeDRL: Disentangled Representation Learning for Multivariate Time-Series. In2024 IEEE 40th International Conference on Data Engineering (ICDE). 625–638. doi:10.1109/ICDE60146.2024.00054
- [5]
-
[6]
Zhihua Chen, Bo Hu, Zhongsheng Chen, and Jiarui Zhang. 2024. Progress and Thinking on Self-Supervised Learning Methods in Computer Vision: A Review. IEEE Sensors Journal24, 19 (2024), 29524–29544. doi:10.1109/JSEN.2024.3443885
-
[7]
Xiaohan Ding, Yiyuan Zhang, Yixiao Ge, Sijie Zhao, Lin Song, Xiangyu Yue, and Ying Shan. 2024. UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio Video Point Cloud Time-Series and Image Recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Seattle, WA, USA). 5513–5524
work page 2024
-
[8]
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Haus- dorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. 2000. PhysioBank, PhysioToolkit, and PhysioNet.Circulation101, 23 (2000), e215–e220. arXiv:https://www.ahajournals.org/doi/pdf/10.1161/01.CIR.101.23.e215 doi:10. 1161/01.CIR....
-
[9]
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. 2020. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning. InAdvances in Neural Information Proce...
work page 2020
-
[10]
He He and Dongrui Wu. 2020. Transfer Learning for Brain–Computer Interfaces: A Euclidean Space Data Alignment Approach.IEEE Transactions on Biomedical Engineering67, 2 (2020), 399–410. doi:10.1109/TBME.2019.2913914
-
[11]
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick
-
[12]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Masked Autoencoders Are Scalable Vision Learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, New Orleans, LA, USA, 16000–16009. doi:10.1109/CVPR52688.2022.01553
-
[13]
Gan Huang, Zhenxing Hu, Weize Chen, Shaorong Zhang, Zhen Liang, Linling Li, Li Zhang, and Zhiguo Zhang. 2022. M3CV: A multi-subject, multi-session, and multi-task database for EEG-based biometrics challenge.NeuroImage264 (2022), 119666. doi:10.1016/j.neuroimage.2022.119666
-
[14]
Wei-Bang Jiang, Li-Ming Zhao, and Bao-Liang Lu. 2024. Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. InPro- ceedings of the Twelfth International Conference on Learning Representations (ICLR 2024). https://openreview.net/forum?id=QzTpTRVtrP Spotlight / Conference paper
work page 2024
-
[15]
Jin Jing, Wendong Ge, Shenda Hong, Marta Bento Fernandes, Zhen Lin, Chaoqi Yang, Sungtae An, Aaron F Struck, Aline Herlopian, Ioannis Karakis, et al. 2023. Development of expert-level classification of seizures and rhythmic and periodic patterns during EEG interpretation.Neurology100, 17 (2023), e1750–e1762
work page 2023
- [16]
-
[17]
Analysis of a sleep-dependent neuronal feedback loop: the slow-wave microcontinuity of the eeg,
Analysis of a sleep-dependent neuronal feedback loop: the slow-wave microcontinuity of the EEG.IEEE Transactions on Biomedical Engineering47, 9 (2000), 1185–1194. doi:10.1109/10.867928
-
[18]
Demetres Kostas, Stéphane Aroca-Ouellette, and Frank Rudzicz. 2021. BENDR: Using Transformers and a Contrastive Self-Supervised Learning Task to Learn From Massive Amounts of EEG Data.Frontiers in Human NeuroscienceVolume 15 - 2021 (2021). doi:10.3389/fnhum.2021.653659
-
[19]
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance. 2018. EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces.Journal of Neural Engineering 15, 5 (jul 2018), 056013. doi:10.1088/1741-2552/aace8c
-
[20]
Hongli Li, Man Ding, Ronghua Zhang, and Chunbo Xiu. 2022. Motor imagery EEG classification algorithm based on CNN-LSTM feature fusion network.Biomedical Signal Processing and Control72 (2022), 103342. doi:10.1016/j.bspc.2021.103342
-
[21]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
work page 2008
-
[22]
2005.Electroencephalography: basic principles, clinical applications, and related fields
Ernst Niedermeyer and FH Lopes da Silva. 2005.Electroencephalography: basic principles, clinical applications, and related fields. Lippincott Williams & Wilkins
work page 2005
-
[23]
2006.Electric fields of the brain: the neurophysics of EEG
Paul L Nunez and Ramesh Srinivasan. 2006.Electric fields of the brain: the neurophysics of EEG. Oxford university press
work page 2006
-
[24]
Iyad Obeid and Joseph Picone. 2016. The Temple University Hospital EEG Data Corpus.Frontiers in NeuroscienceVolume 10 - 2016 (2016). doi:10.3389/fnins. 2016.00196
-
[25]
Wei Yan Peh, Yuanyuan Yao, and Justin Dauwels. 2022. Transformer Convo- lutional Neural Networks for Automated Artifact Detection in Scalp EEG. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC). 3599–3602. doi:10.1109/EMBC48229.2022.9871916
-
[26]
Roy, Marcel Hinss, Fabien Lotte, Ludovic Darmet, and Si- mon Ladouce
Raphaëlle N. Roy, Marcel Hinss, Fabien Lotte, Ludovic Darmet, and Si- mon Ladouce. 2021. Passive BCI Cross-Session Workload EEG Dataset. Neuroergonomics Conference Passive BCI Challenge. https://www. neuroergonomicsconference.um.ifi.lmu.de/pbci/ Accessed: 2025-9
work page 2021
-
[27]
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Do- minique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wolfram Burgard, and Tonio Ball
-
[28]
Deep learning with convolutional neural networks for EEG de- coding and visualization.Human Brain Mapping38, 11 (2017), 5391–
work page 2017
-
[29]
arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/hbm.23730 doi:10.1002/hbm.23730
-
[30]
Sina Shafiezadeh, Gian Marco Duma, Marco Pozza, and Alberto Testolin. 2024. A systematic review of cross-patient approaches for EEG epileptic seizure pre- diction.Journal of Neural Engineering21, 6 (dec 2024), 061004. doi:10.1088/1741- 2552/ad9682
-
[31]
Yang Shao, Yueying Zhou, Peiliang Gong, Qianru Sun, and Daoqiang Zhang
-
[32]
doi:10.1109/TNSRE.2024.3415364
A Dual-Adversarial Model for Cross-Time and Cross-Subject Cognitive Workload Decoding.IEEE Transactions on Neural Systems and Rehabilitation Engineering32 (2024), 2324–2335. doi:10.1109/TNSRE.2024.3415364
-
[33]
Yang Shao, Yueying Zhou, Xuyun Wen, Peiliang Gong, Qun Dai, and Daoqiang Zhang. 2026. Exploring Cognitive Workload Recognition Using CogRepLKNet with EEG-fMRI.Neural Networks(2026), 108575. doi:10.1016/j.neunet.2026. 108575
-
[34]
Yang Shao, Yueying Zhou, and Daoqiang Zhang. 2025. BDANet: A Binary- Dimensional Aware Network with Multi-Wise Attention for Cognitive Workload Recognition. In2025 13th International Conference on Brain-Computer Interface (BCI). 1–8. doi:10.1109/BCI65088.2025.10931257 Shao et al
-
[35]
Qingshan She, Chenqi Zhang, Feng Fang, Yuliang Ma, and Yingchun Zhang
-
[36]
Multisource Associate Domain Adaptation for Cross-Subject and Cross- Session EEG Emotion Recognition.IEEE Transactions on Instrumentation and Measurement72 (2023), 1–12. doi:10.1109/TIM.2023.3277985
- [37]
-
[38]
Yonghao Song, Qingqing Zheng, Bingchuan Liu, and Xiaorong Gao. 2023. EEG Conformer: Convolutional Transformer for EEG Decoding and Visualization. IEEE Transactions on Neural Systems and Rehabilitation Engineering31 (2023), 710–719. doi:10.1109/TNSRE.2022.3230250
-
[39]
Michael Tangermann, Kai-Robert Müller, Ad Aertsen, Niels Birbaumer, Benjamin Blankertz, Gottfried Curio, Bernhard Graimann, Christina Hammon, Jane E Huggins, Dean J Krusienski, et al . 2012. Review of the BCI Competition IV. Frontiers in Neuroscience6 (2012), 55
work page 2012
-
[40]
Akiyoshi Tomihari and Issei Sato. 2024. Understanding Linear Probing then Fine-tuning Language Models from NTK Perspective. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 139786–139822. doi:10.52202/079017-4436
-
[41]
Guagnyu Wang, Wenchao Liu, Yuhong He, Cong Xu, Lin Ma, and Haifeng Li. 2024. EEGPT: Pretrained Transformer for Universal and Reliable Representation of EEG Signals. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 39249–39280. do...
-
[42]
Jiquan Wang, Sha Zhao, Zhiling Luo, Yangxuan Zhou, Shijian Li, and Gang Pan
-
[43]
doi:10.1016/j.neunet.2025.107816
EEGMamba: An EEG foundation model with Mamba.Neural Networks192 (2025), 107816. doi:10.1016/j.neunet.2025.107816
-
[44]
Pengpai Wang, Tiantian Xie, Yueying Zhou, Peiliang Gong, and Rosa H. M. Chan. 2025. TCPL: task-conditioned prompt learning for few-shot cross-subject motor imagery EEG decoding.Frontiers in NeuroscienceVolume 19 - 2025 (2025). doi:10.3389/fnins.2025.1689286
-
[45]
Xiaohu Wang, Yongmei Ren, Ze Luo, Wei He, Jun Hong, and Yinzhen Huang
-
[46]
Deep learning-based EEG emotion recognition: Current trends and future perspectives.Frontiers in PsychologyVolume 14 - 2023 (2023). doi:10.3389/fpsyg. 2023.1126994
-
[47]
Yijun Wang, Xiaogang Chen, Xiaorong Gao, and Shangkai Gao. 2017. A Bench- mark Dataset for SSVEP-Based Brain-Computer Interfaces.IEEE Transactions on Neural Systems and Rehabilitation Engineering25, 10 (2017), 1746–1752. doi:10.1109/TNSRE.2016.2627556
-
[48]
Tracy Warbrick. 2022. Simultaneous EEG-fMRI: What Have We Learned and What Does the Future Hold?Sensors22, 6 (2022). doi:10.3390/s22062262
- [49]
- [50]
-
[51]
Chaoqi Yang, M Westover, and Jimeng Sun. 2023. BIOT: Biosignal Transformer for Cross-data Learning in the Wild. InAdvances in Neu- ral Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 78240–78260. https://proceedings.neurips.cc/paper_files/paper/2023/file/ f6b30f3...
work page 2023
-
[52]
Chaoqi Yang, Cao Xiao, M Brandon Westover, and Jimeng Sun. 2023. Self- Supervised Electroencephalogram Representation Learning for Automatic Sleep Staging: Model Development and Evaluation Study.JMIR AI2 (26 Jul 2023), e46769. doi:10.2196/46769
-
[53]
Chaoning Zhang, Chenshuang Zhang, Junha Song, John Seon Keun Yi, and In So Kweon. 2023. A Survey on Masked Autoencoder for Visual Self-supervised Learning. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence (IJCAI-23). International Joint Conferences on Artificial Intelligence Organization, Macau, China, 6805–6813
work page 2023
- [54]
-
[55]
Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, and Shirui Pan
Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Y. Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, and Shirui Pan
-
[56]
doi:10.1109/TPAMI.2024.3387317
Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects.IEEE Transactions on Pattern Analysis and Machine Intelligence46, 10 (2024), 6775–6794. doi:10.1109/TPAMI.2024.3387317
-
[57]
Pengbo Zhang, Xue Wang, Weihang Zhang, and Junfeng Chen. 2019. Learning Spatial–Spectral–Temporal EEG Features With Recurrent 3D Convolutional Neural Networks for Cross-Task Mental Workload Assessment.IEEE Transactions on Neural Systems and Rehabilitation Engineering27, 1 (2019), 31–42. doi:10.1109/ TNSRE.2018.2884641
-
[58]
Wei-Long Zheng, Wei Liu, Yifei Lu, Bao-Liang Lu, and Andrzej Cichocki. 2019. EmotionMeter: A Multimodal Framework for Recognizing Human Emotions. IEEE Transactions on Cybernetics49, 3 (2019), 1110–1122. doi:10.1109/TCYB.2018. 2797176
-
[59]
Wei-Long Zheng and Bao-Liang Lu. 2015. Investigating Critical Frequency Bands and Channels for EEG-based Emotion Recognition with Deep Neural Networks.IEEE Transactions on Autonomous Mental Development7, 3 (2015), 162–175. doi:10.1109/TAMD.2015.2431497 DARE-EEG: A Foundation Model for Mining Dual-Aligned Representation of EEG A Notation Table This section...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.