URDF Synthesis from RGB-D Sequences via Differentiable Joint Inference and Energy-Consistent Verification
Pith reviewed 2026-06-26 21:35 UTC · model grok-4.3
The pith
KinemaForge reconstructs accurate, energy-consistent URDF models from RGB-D sequences by jointly inferring shape and kinematics with a differentiable verifier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
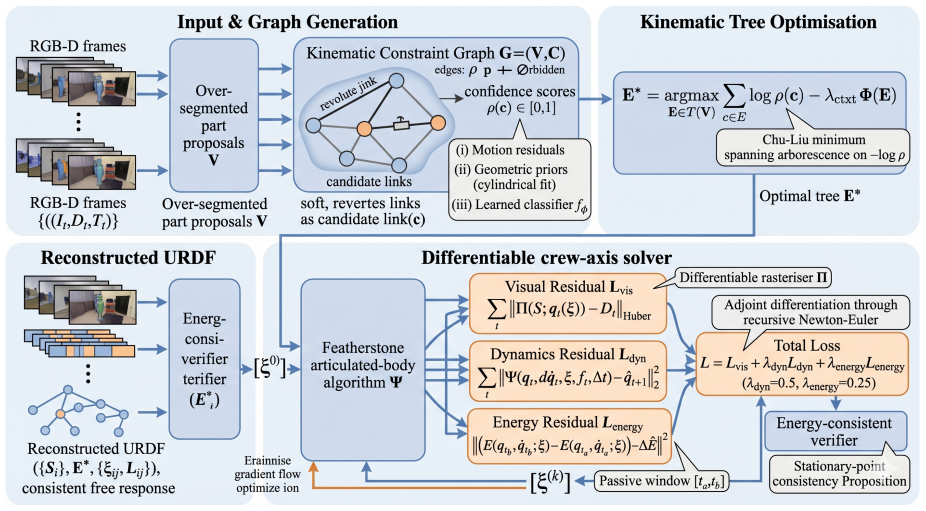
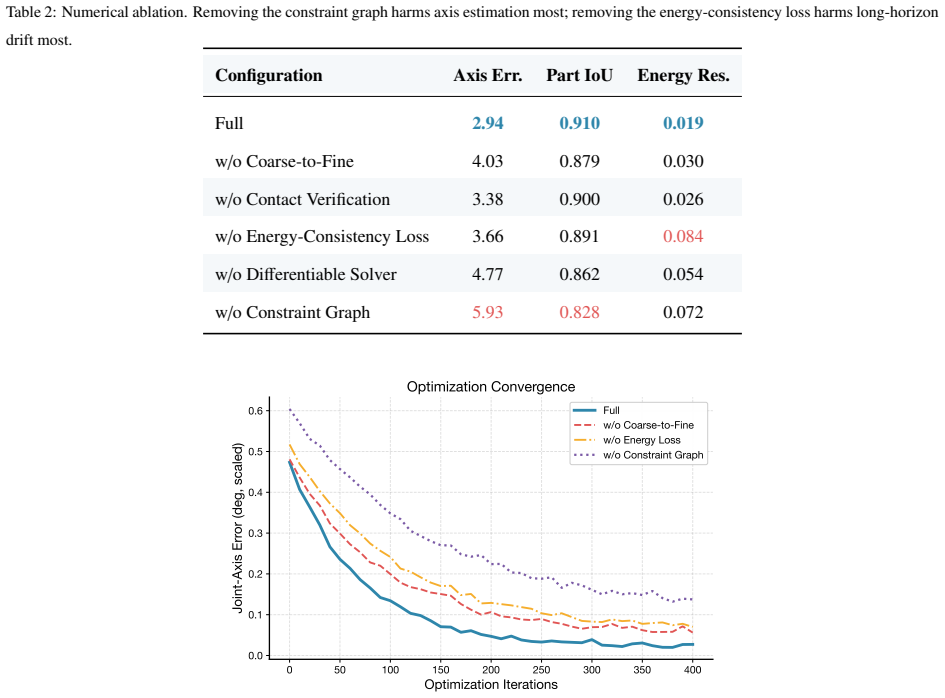
KinemaForge is a constraint-driven pipeline that jointly infers part-level shape, joint topology, and joint parameters from short RGB-D sequences and validates the result against an energy-consistent verifier built on differentiable rigid-body dynamics. The pipeline introduces three components: a kinematic constraint graph that encodes joint-part incidences as soft edges; a differentiable screw-axis solver that backpropagates from rendered observations through Featherstone's articulated-body algorithm to joint parameters; and an energy residual loss that penalises non-physical free responses of the reconstructed model. This produces URDFs with lower joint-axis error, less simulation drift, a
What carries the argument
the energy residual loss that penalises non-physical free responses of the reconstructed model
If this is right
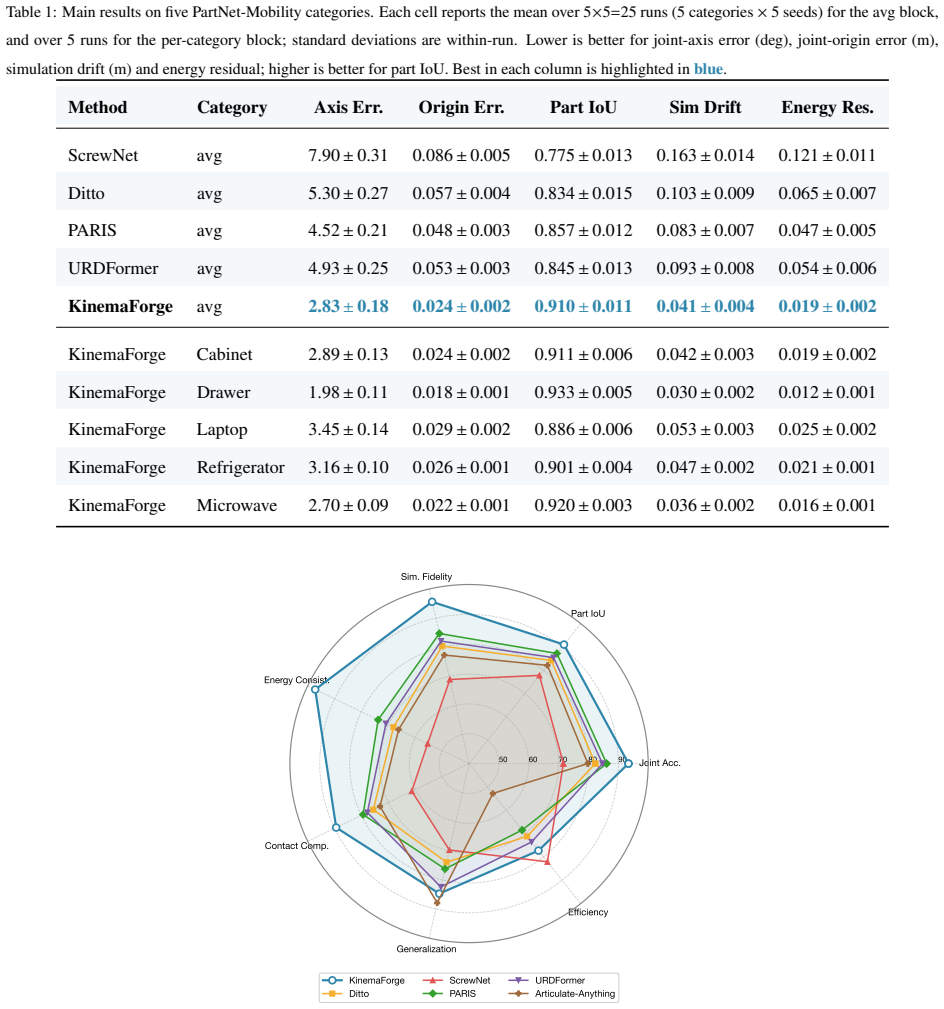
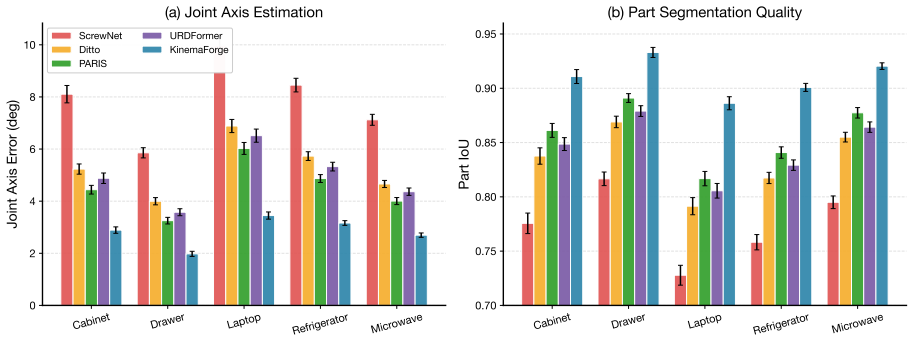
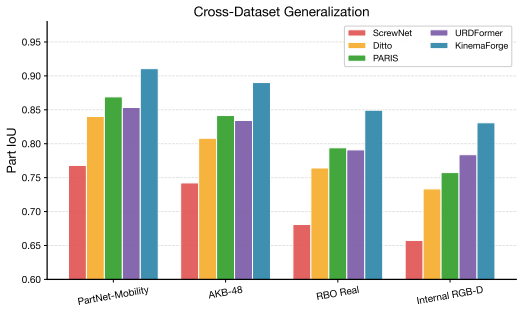
- Joint-axis error falls to 2.83 degrees, improving 37.4 percent over PARIS and 46.6 percent over Ditto.
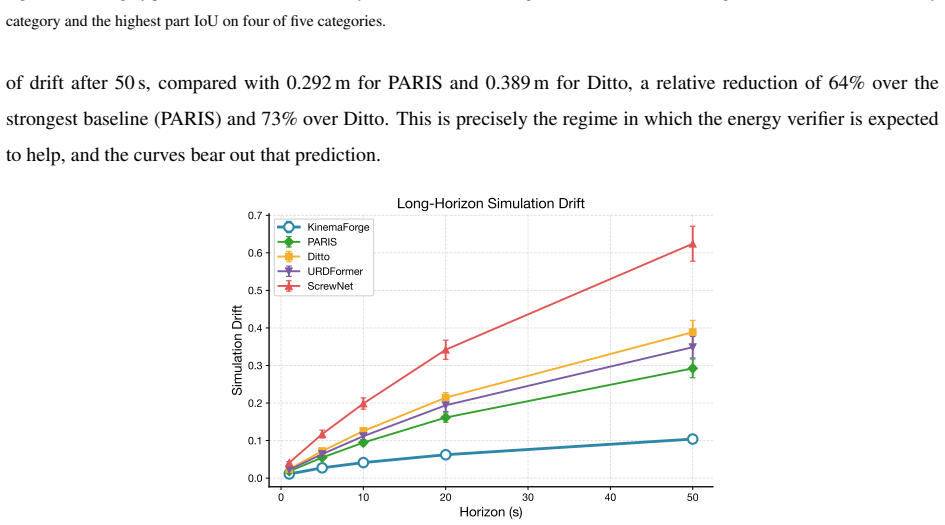
- Long-horizon simulation drift drops 64 percent versus PARIS in 50-second rollouts.
- Closed-loop manipulation success rate rises 14.6 percentage points over Ditto.
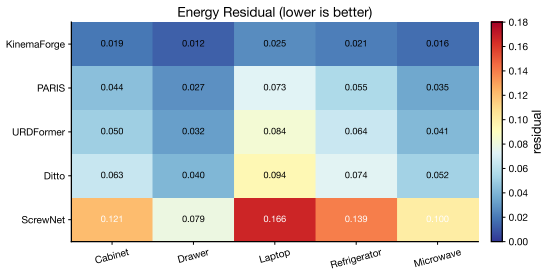
- The reconstructed models better satisfy energy conservation during free motion.
Where Pith is reading between the lines
- The technique might apply to other reconstruction problems where physical invariants need enforcement.
- It could support automatic dataset generation for training robot policies on articulated objects.
- If energy consistency transfers to contact scenarios, it reduces the gap between simulation and reality in robotics.
- Extensions to noisy or incomplete RGB-D data would test robustness in real settings.
Load-bearing premise
That minimizing the energy residual loss on free responses of the reconstructed model will produce URDFs that remain energy-consistent and drift-free under the contact and control conditions encountered in downstream manipulation tasks.
What would settle it
Observe whether the reconstructed URDF exhibits significant energy drift or increased simulation instability when used in a physics engine for contact-rich tasks, compared to models from other methods.
Figures
read the original abstract
Reconstructing simulation-ready digital twins of articulated objects from sensor observations remains constrained by two persistent gaps: (i) part-level geometric reconstruction is decoupled from kinematic-parameter estimation, and (ii) the recovered models often violate basic dynamic invariants such as energy conservation, leading to drift when the URDF is replayed in physics simulators. We present KinemaForge, a constraint-driven pipeline that jointly infers part-level shape, joint topology, and joint parameters from short RGB-D sequences and validates the result against an energy-consistent verifier built on differentiable rigid-body dynamics. The pipeline introduces three components: a kinematic constraint graph that encodes joint-part incidences as soft edges; a differentiable screw-axis solver that backpropagates from rendered observations through Featherstone's articulated-body algorithm to joint parameters; and an energy residual loss that penalises non-physical free responses of the reconstructed model. Across five PartNet-Mobility categories and an internal RGB-D benchmark, KinemaForge reduces the average joint-axis error from 4.52 degrees to 2.83 degrees (-37.4%) over the strongest geometric baseline (PARIS) and from 5.30 degrees to 2.83 degrees (-46.6%) over the interaction-based Ditto baseline, lowers long-horizon simulation drift by 64% (vs. PARIS) over 50 s rollouts, and yields URDFs whose closed-loop manipulation success rate improves by 14.6 percentage points over Ditto in our preliminary evaluation. Code and reconstruction data will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents KinemaForge, a constraint-driven pipeline for reconstructing simulation-ready URDFs of articulated objects from short RGB-D sequences. It jointly infers part-level shape, joint topology, and parameters via a kinematic constraint graph encoding joint-part incidences as soft edges, a differentiable screw-axis solver that backpropagates from rendered observations through Featherstone's articulated-body algorithm, and an energy residual loss that penalizes non-physical free responses. On five PartNet-Mobility categories and an internal RGB-D benchmark, it reports joint-axis error reduced to 2.83° (–37.4% vs. PARIS, –46.6% vs. Ditto), 64% lower long-horizon drift over 50 s rollouts vs. PARIS, and +14.6 pp closed-loop manipulation success vs. Ditto, with code and data to be released.
Significance. If the energy-consistent verifier produces URDFs that remain drift-free under the contact and control conditions of downstream tasks, the work would meaningfully advance reconstruction of physically plausible digital twins by coupling differentiable dynamics with geometric inference. The quantitative gains in kinematic accuracy, simulation stability, and task performance, together with the planned code release, would strengthen reproducibility and practical utility in robotics and computer vision.
major comments (1)
- [Abstract] Abstract (energy residual loss component): The loss penalizes non-physical free responses, yet the reported 64% drift reduction and 14.6 pp manipulation success gains are measured on contact-rich, closed-loop tasks. No indication is given that the verifier is applied or regularized on trajectories containing contacts or external wrenches; if the learned parameters satisfy energy conservation only in the absence of contacts, the headline improvements may not generalize and the central claim of energy-consistent URDFs for manipulation would require additional support.
minor comments (1)
- The abstract refers to a 'preliminary evaluation' for the manipulation success metric; specifying the number of trials, task diversity, and whether the same energy loss weighting was used would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the energy residual loss and its relation to the reported results. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (energy residual loss component): The loss penalizes non-physical free responses, yet the reported 64% drift reduction and 14.6 pp manipulation success gains are measured on contact-rich, closed-loop tasks. No indication is given that the verifier is applied or regularized on trajectories containing contacts or external wrenches; if the learned parameters satisfy energy conservation only in the absence of contacts, the headline improvements may not generalize and the central claim of energy-consistent URDFs for manipulation would require additional support.
Authors: We agree that the energy residual loss is formulated exclusively on free responses (no contacts or external wrenches). This isolates enforcement of energy conservation as a fundamental invariant, which is a prerequisite for stable long-term behavior even when contacts occur. The 50 s drift rollouts and closed-loop manipulation evaluations are performed inside a full physics simulator whose dynamics already incorporate contacts and gravity; the energy-consistent parameters reduce spurious dissipation that would otherwise amplify under those conditions. Nevertheless, the manuscript does not demonstrate explicit regularization on contact-containing trajectories. In revision we will (i) qualify the abstract and method sections to state the free-response scope of the loss, (ii) add a short discussion explaining why energy conservation remains beneficial under contacts, and (iii) include a brief ablation regularizing on a small set of simulated contact trajectories if space permits. These changes directly address the concern while preserving the core technical contribution. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The abstract and described pipeline introduce a kinematic constraint graph, differentiable screw-axis solver via Featherstone's algorithm, and an energy residual loss applied to free responses. No equations, self-citations, or fitted parameters are shown that reduce any claimed output (joint-axis error, drift reduction, or manipulation success) to the inputs by construction. The energy loss is presented as an added physical constraint rather than a tautological fit or renamed known result, and the reported improvements are empirical comparisons against external baselines (PARIS, Ditto). The derivation chain therefore supplies independent content beyond its inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- energy residual loss weighting coefficients
axioms (1)
- standard math Featherstone's articulated-body algorithm can be differentiated end-to-end for joint-parameter optimization
Reference graph
Works this paper leans on
-
[1]
Coumans, Y
E. Coumans, Y . Bai, PyBullet, a Python module for physics simulation for games, robotics and machine learning, http://pybullet.org(2016–2021)
2016
-
[2]
H. Zhao, L. Yan, Z. Hou, J. Lin, Y . Zhao, Z. Ji, Y . Wang, Error analysis strategy for long-term correlated network systems: Generalized nonlinear stochastic processes and dual-layer filtering architecture, IEEE Internet of Things Journal (2025)
2025
-
[3]
Z. Li, Y . Hu, Z. Chen, Q. Huang, G. Qiu, Z. Fu, M. Liu, Retrack: Evidence-driven dual-stream directional anchor calibration network for composed video retrieval, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[4]
Z. Yu, M. Y . I. Idris, P. Wang, R. Qureshi, Dinov3-powered multi-task foundation model for quantitative remote sensing estimation (student abstract), in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 40, 2026, pp. 41455–41456
2026
-
[5]
S. Jia, N. Zhu, J. Zhong, J. Zhou, H. Zhang, J.-N. Hwang, L. Li, Ram: Recover any 3d human motion in-the-wild (2026).arXiv:2603.19929. URLhttps://arxiv.org/abs/2603.19929
Pith/arXiv arXiv 2026
-
[6]
Z. Chen, Y . Hu, Z. Fu, Z. Li, J. Huang, Q. Huang, Y . Wei, Intent: Invariance and discrimination-aware noise mit- igation for robust composed image retrieval, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[7]
Z. Yu, H. Jiang, P. Wang, Z. Lin, Y . Xiang, Spatiotemporal alignment for remote sensing image recovery via terrain-aware diffusion, in: ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2026, pp. 11257–11261
2026
-
[8]
L. Li, S. Jia, J. Wang, Z. Jiang, F. Zhou, J. Dai, T. Zhang, Z. Wu, J.-N. Hwang, Human Motion Instruction Tuning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[9]
Z. Li, Y . Hu, Z. Chen, S. Zhang, Q. Huang, Z. Fu, Y . Wei, Habit: Chrono-synergia robust progressive learning framework for composed image retrieval, in: Proceedings of the AAAI Conference on Artificial Intelligence, 2026. 14
2026
- [10]
-
[11]
L. Li, S. Jia, J.-N. Hwang, Multiple human motion understanding, in: Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 40, 2026, pp. 6297–6305
2026
-
[12]
Z. Fu, Y . Hu, Q. Yang, S. Zhang, Z. Chen, Z. Li, Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[13]
R. Gu, S. Jia, Y . Ma, J. Zhong, J.-N. Hwang, L. Li, Mocount: Motion-based repetitive action counting, in: Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9026–9034
2025
-
[14]
L. Li, S. Jia, J. Wang, Z. An, J. Li, J.-N. Hwang, S. Belongie, Chatmotion: A multimodal multi-agent for human motion analysis, arXiv preprint arXiv:2502.18180 (2025)
arXiv 2025
-
[15]
Z. Li, Y . Hu, Z. Chen, M. Zhang, Z. Fu, L. Nie, Conesep: Cone-based robust noise-unlearning compositional network for composed image retrieval, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[16]
S. Jia, L. Li, Adaptive masking enhances visual grounding, arXiv preprint arXiv:2410.03161 (2024)
arXiv 2024
-
[17]
B. Li, H. Dong, D. Zhang, Z. Zhao, J. Gao, X. Li, Exploring efficient open-vocabulary segmentation in the remote sensing, arXiv preprint arXiv:2509.12040 (2025)
arXiv 2025
-
[18]
B. Li, D. Zhang, Z. Zhao, J. Gao, X. Li, Stitchfusion: Weaving any visual modalities to enhance multimodal semantic segmentation, in: Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 1308–1317
2025
-
[19]
Z. Chen, A. Walsman, M. Memmel, K. Mo, A. Fang, K. Vemuri, A. Wu, D. Fox, A. Gupta, URDFormer: A pipeline for constructing articulated simulation environments from real-world images, in: Robotics: Science and Systems (RSS), 2024
2024
-
[20]
L. Le, J. Xie, W. Liang, H.-J. Wang, Y . Yang, Y . J. Ma, K. Vedder, A. Krishna, D. Jayaraman, E. Eaton, Articulate-anything: Automatic modeling of articulated objects via a vision-language foundation model, in: International Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Z. Yu, M. Y . I. Idris, H. Wang, P. Wang, J. Chen, K. Wang, From physics to foundation models: A review of ai-driven quantitative remote sensing inversion, arXiv preprint arXiv:2507.09081 (2025). 15
arXiv 2025
-
[22]
J. Liu, A. Mahdavi-Amiri, M. Savva, PARIS: Part-level reconstruction and motion analysis for articulated ob- jects, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 352– 363
2023
-
[23]
B. Deng, J. P. Lewis, T. Jeruzalski, G. Pons-Moll, G. Hinton, M. Norouzi, A. Tagliasacchi, NASA: Neural articulated shape approximation, in: European Conference on Computer Vision (ECCV), 2020, pp. 612–628
2020
-
[24]
Jiang, Y
H. Jiang, Y . Mao, M. Savva, A. X. Chang, OPD: Single-view 3D openable part detection, in: European Confer- ence on Computer Vision (ECCV), 2022, pp. 410–426
2022
-
[25]
B. Li, F. Wang, D. Zhang, Z. Zhao, J. Gao, X. Li, Maris: Marine open-vocabulary instance segmentation with geometric enhancement and semantic alignment, arXiv preprint arXiv:2510.15398 (2025)
arXiv 2025
-
[26]
B. Li, T. Huo, D. Zhang, Z. Zhao, J. Gao, X. Li, Exploring the underwater world segmentation without extra training, arXiv preprint arXiv:2511.07923 (2025)
arXiv 2025
-
[27]
B. Li, D. Zhang, Z. Zhao, J. Gao, X. Li, U3m: Unbiased multiscale modal fusion model for multimodal semantic segmentation, Pattern Recognition 168 (2025) 111801
2025
-
[28]
Y . Chen, Z. Cao, H. Ren, C. Yang, W. Li, S. Wang, Y . Wang, L. Zhang, Y . Shao, Z. Zhao, et al., Roborouter: Training-free policy routing for robotic manipulation, arXiv preprint arXiv:2603.07892 (2026)
Pith/arXiv arXiv 2026
-
[29]
Jiang, T
G. Jiang, T. Zhang, D. Li, Z. Zhao, H. Li, M. Li, H. Wang, Stg-avatar: Animatable human avatars via spacetime gaussian, in: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2025, pp. 20058–20065
2025
-
[30]
S. Yan, P. Shi, Z. Zhao, K. Wang, K. Cao, J. Wu, J. Li, Turboreg: Turboclique for robust and efficient point cloud registration, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26371–26381
2025
-
[31]
Z. Zhao, H. Yang, B. Liao, Y . Zeng, S. Yan, Y . Gu, P. Liu, Y . Zhou, H. Li, J. Civera, Advances in global solvers for 3d vision, arXiv preprint arXiv:2602.14662 (2026)
arXiv 2026
-
[32]
J. Chan, Z. Zhao, Y .-L. Liu, Adagar: Adaptive gabor representation for dynamic scene reconstruction, arXiv preprint arXiv:2601.00796 (2026)
arXiv 2026
-
[33]
Z. Yu, J. Wang, H. Chen, M. Y . I. Idris, Qrs-trs: Style transfer-based image-to-image translation for carbon stock estimation in quantitative remote sensing, IEEE Access (2025)
2025
-
[34]
Featherstone, Rigid Body Dynamics Algorithms, Springer, 2008
R. Featherstone, Rigid Body Dynamics Algorithms, Springer, 2008. 16
2008
-
[35]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, H. Su, SAPIEN: A simulated part-based interactive environment, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 11094–11104
2020
-
[36]
Jiang, C.-C
Z. Jiang, C.-C. Hsu, Y . Zhu, Ditto: Building digital twins of articulated objects from interaction, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 5616–5626
2022
-
[37]
A. Jain, R. Lioutikov, C. Chuck, S. Niekum, ScrewNet: Category-independent articulation model estimation from depth images using screw theory, in: Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 13670–13677
2021
-
[38]
L. Liu, W. Xu, H. Fu, S. Qian, Q. Yu, Y . Han, C. Lu, AKB-48: A real-world articulated object knowledge base, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 14809–14818
2022
-
[39]
Martín-Martín, C
R. Martín-Martín, C. Eppner, O. Brock, The RBO dataset of articulated objects and interactions, The Interna- tional Journal of Robotics Research 38 (9) (2019) 1013–1019
2019
-
[40]
X. Wang, B. Zhou, Y . Shi, X. Chen, Q. Zhao, K. Xu, Shape2Motion: Joint analysis of motion parts and attributes from 3D shapes, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 8876–8884
2019
-
[41]
X. Li, H. Wang, L. Yi, L. J. Guibas, A. L. Abbott, S. Song, Category-level articulated object pose estimation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3706–3715
2020
-
[42]
L. Liu, H. Xue, W. Xu, H. Fu, C. Lu, Toward real-world category-level articulation pose estimation, IEEE Transactions on Image Processing 31 (2022) 1072–1083
2022
-
[43]
K. Mo, L. J. Guibas, M. Mukadam, A. Gupta, S. Tulsiani, Where2Act: From pixels to actions for articulated 3D objects, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 6813–6823
2021
-
[44]
Abbatematteo, S
B. Abbatematteo, S. Tellex, G. Konidaris, Learning to generalize kinematic models to novel objects, in: Confer- ence on Robot Learning (CoRL), 2019, pp. 1289–1299
2019
-
[45]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, R. Ng, NeRF: Representing scenes as neural radiance fields for view synthesis, in: European Conference on Computer Vision (ECCV), 2020, pp. 405–421. 17
2020
-
[46]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, G. Drettakis, 3D Gaussian Splatting for real-time radiance field rendering, ACM Transactions on Graphics 42 (4) (2023)
2023
-
[47]
Noguchi, X
A. Noguchi, X. Sun, S. Lin, T. Harada, Neural articulated radiance field, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 5762–5772
2021
-
[48]
Heiden, Z
E. Heiden, Z. Liu, V . Vineet, E. Coumans, G. S. Sukhatme, Inferring articulated rigid body dynamics from RGBD video, in: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
2022
-
[49]
Khalil, Dynamic modeling of robots using recursive Newton-Euler techniques, in: International Conference on Informatics in Control, Automation and Robotics (ICINCO), 2010
W. Khalil, Dynamic modeling of robots using recursive Newton-Euler techniques, in: International Conference on Informatics in Control, Automation and Robotics (ICINCO), 2010
2010
-
[50]
C. D. Freeman, E. Frey, A. Raichuk, S. Girgin, I. Mordatch, O. Bachem, Brax – a differentiable physics en- gine for large scale rigid body simulation, in: Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[51]
Werling, D
K. Werling, D. Omens, J. Lee, I. Exarchos, C. K. Liu, Fast and feature-complete differentiable physics for articulated rigid bodies with contact, in: Robotics: Science and Systems (RSS), 2021
2021
-
[52]
Y . Hu, L. Anderson, T.-M. Li, Q. Sun, N. Carr, J. Ragan-Kelley, F. Durand, DiffTaichi: Differentiable program- ming for physical simulation, in: International Conference on Learning Representations (ICLR), 2020
2020
-
[53]
T. A. Howell, S. Le Cleac’h, J. Brüdigam, J. Z. Kolter, M. Schwager, Z. Manchester, Dojo: A differentiable physics engine for robotics, arXiv preprint arXiv:2203.00806 (2022)
arXiv 2022
-
[54]
Strecke, J
M. Strecke, J. Stückler, DiffSDFSim: Differentiable rigid-body dynamics with implicit shapes, in: International Conference on 3D Vision (3DV), 2021
2021
-
[55]
K. M. Jatavallabhula, M. Macklin, F. Golemo, V . V oleti, L. Petrini, M. Weiss, B. Considine, J. Parent-Lévesque, K. Xie, K. Erleben, L. Paull, F. Shkurti, D. Nowrouzezahrai, S. Fidler, gradsim: Differentiable simulation for system identification and visuomotor control, in: International Conference on Learning Representations (ICLR), 2021
2021
-
[56]
T. Mu, Z. Ling, F. Xiang, D. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, H. Su, ManiSkill: Generalizable manipula- tion skill benchmark with large-scale demonstrations, in: Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
2021
-
[57]
H. Geng, H. Xu, C. Zhao, C. Xu, L. Yi, S. Huang, H. Wang, GAPartNet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 7081–7091. 18
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.