Tensorizing Engram: Sharing Latents Across N-Gram Embeddings is Beneficial in LLMs
Pith reviewed 2026-06-27 19:26 UTC · model grok-4.3
The pith
Tensorizing n-gram embeddings with shared CP factors lets LLMs match Engram performance using far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
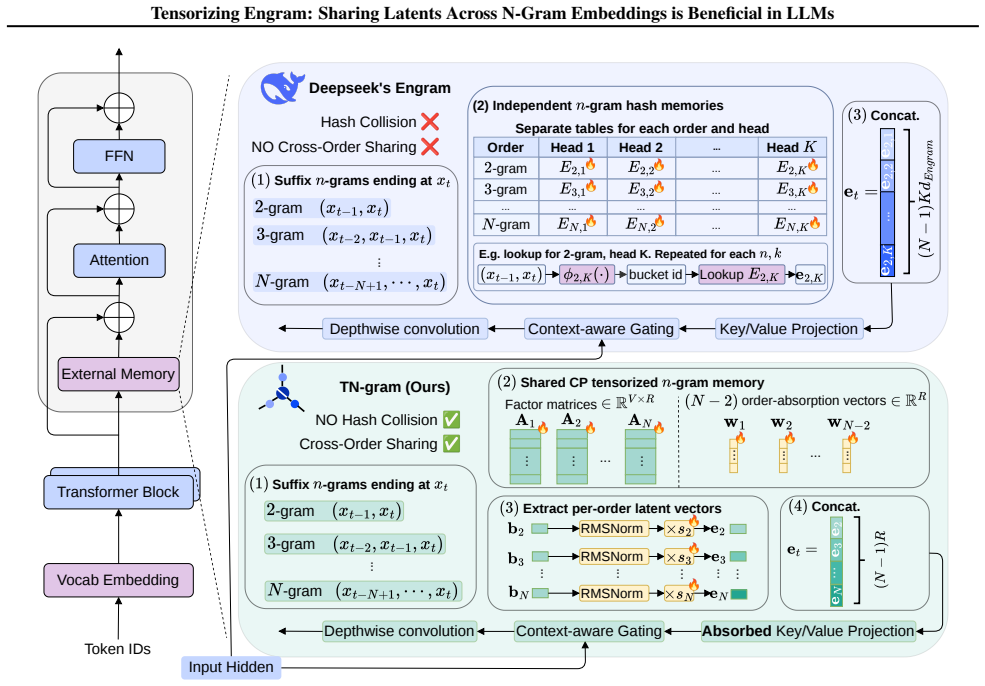
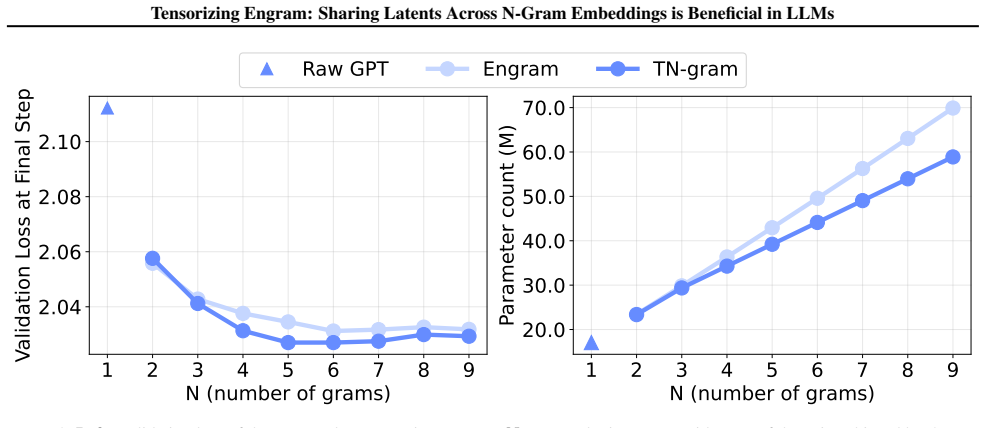
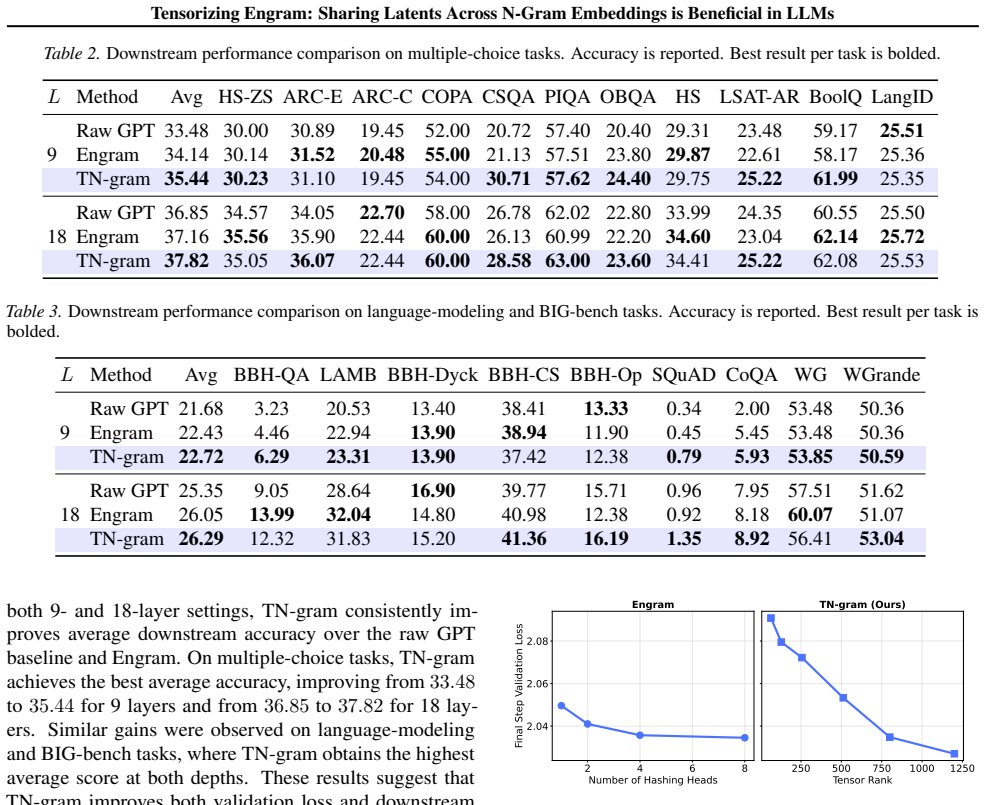
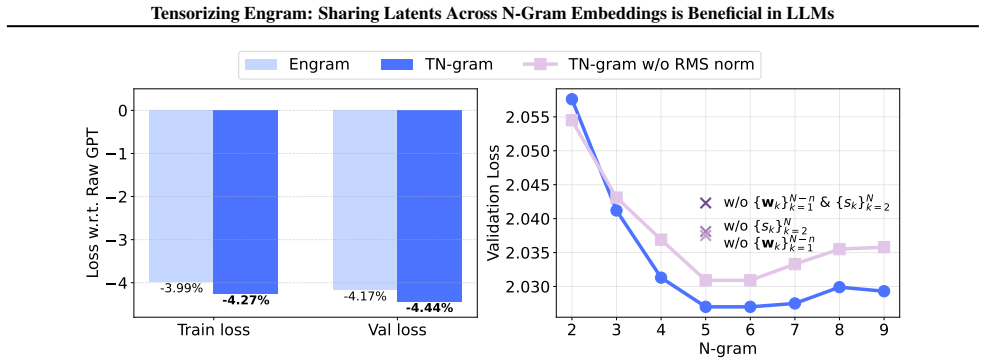
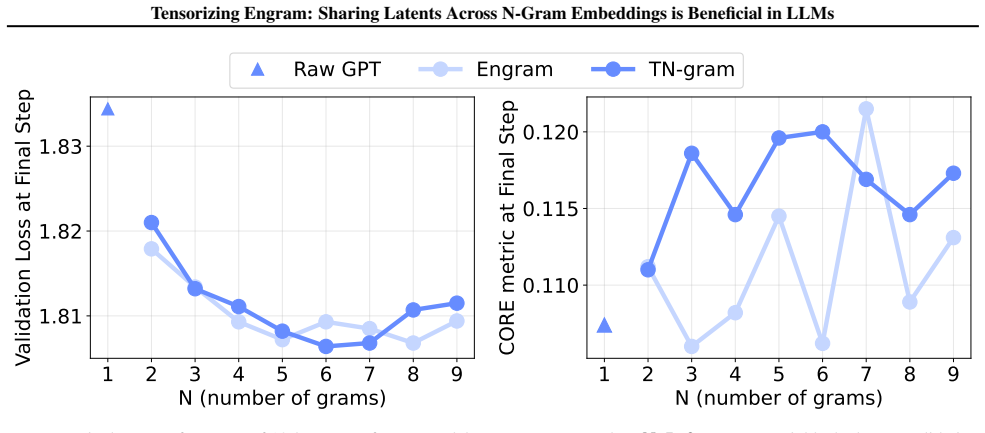
TN-gram represents tensorized n-gram embeddings through shared factors in the Canonical Polyadic (CP) form. It learns shared token-position factors together with order-absorption vectors to encode the embeddings of different n-gram orders. Comprehensive experiments demonstrate that TN-gram matches or even outperforms Engram-style n-gram modules while requiring much fewer parameters.
What carries the argument
Canonical Polyadic decomposition of the n-gram embedding tensor with shared token-position factors and order-absorption vectors that allow different orders to be encoded efficiently.
If this is right
- Multi-token patterns can be stored explicitly with reduced parameter overhead.
- Nested n-grams benefit from shared latent structures rather than independent tables.
- Hash collisions associated with per-order tables are sidestepped.
- Overall model capacity for language tasks is preserved or improved at lower memory cost.
Where Pith is reading between the lines
- Similar sharing mechanisms could apply to other tensor-structured linguistic features such as dependency trees.
- Higher-order n-grams become feasible without exponential growth in storage.
- The method may integrate with existing transformer architectures to improve handling of idiomatic expressions.
Load-bearing premise
The Canonical Polyadic decomposition with shared token-position factors and order-absorption vectors can represent the necessary distinctions among nested n-grams without the collisions or capacity loss that separate hash tables were introduced to avoid.
What would settle it
Training and evaluating TN-gram versus a hash-based n-gram module on a corpus rich in overlapping n-grams and measuring whether TN-gram shows higher perplexity or lower accuracy on predictions involving those overlaps.
Figures
read the original abstract
Modern language models represent text using discrete token-level embeddings, which forces recurring multi-token patterns to be learned implicitly across Transformer layers. Both Over-tokenized Transformers and Engram attempt to address this limitation by explicitly incorporating multi-token (n-gram) memories. However, they rely on separate hash tables for each n-gram order, which introduces hash collisions and prevents nested n-grams from sharing the underlying latent structures. To address these issues, we propose Tensorized Engram (TN-gram), a compact memory module that represents tensorized n-gram embeddings through shared factors in the Canonical Polyadic (CP) form. TN-gram learns shared token-position factors together with order-absorption vectors to encode the embeddings of different n-gram order. Comprehensive experiments demonstrate that TN-gram matches or even outperforms Engram-style n-gram modules while requiring much fewer parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Tensorized Engram (TN-gram) as a compact n-gram memory module for LLMs. It replaces per-order hash tables (as in Engram) with a Canonical Polyadic (CP) tensor decomposition that shares token-position factors across n-gram orders while using per-order absorption vectors to encode order-specific information. The central claim is that this sharing reduces parameters, avoids hash collisions, and enables latent sharing for nested n-grams, with comprehensive experiments showing that TN-gram matches or outperforms Engram-style modules.
Significance. If the empirical results hold and the representational capacity concern is addressed, the work would demonstrate a parameter-efficient tensor-based alternative for explicit multi-token memory in transformers. The approach directly targets the collision and non-sharing issues of prior hash-table methods while preserving the benefit of order-specific n-gram embeddings.
major comments (2)
- [Method (CP decomposition and absorption mechanism)] The load-bearing assumption that the CP factorization (shared token-position factors + order-absorption vectors) can recover the order-specific distinctions among nested n-grams without rank collapse or crosstalk is not automatically guaranteed by the CP form. If absorption vectors are limited-rank or act via simple scaling/addition, the shared factors may force collisions precisely on the nested cases the method targets; this requires either a theoretical argument or targeted ablation showing preserved distinctions.
- [Abstract and Experiments section] The abstract states that comprehensive experiments demonstrate the performance claim, yet provides no quantitative results, ablation details on tensor rank, or description of how absorption vectors or rank were selected. Without these, it is impossible to assess whether the reported gains are robust or post-hoc.
minor comments (1)
- [Method] Notation for the CP factors and absorption vectors should be introduced with explicit equations early in the method section to clarify how the shared factors interact with per-order terms.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond point-by-point to the major comments below, indicating planned revisions.
read point-by-point responses
-
Referee: [Method (CP decomposition and absorption mechanism)] The load-bearing assumption that the CP factorization (shared token-position factors + order-absorption vectors) can recover the order-specific distinctions among nested n-grams without rank collapse or crosstalk is not automatically guaranteed by the CP form. If absorption vectors are limited-rank or act via simple scaling/addition, the shared factors may force collisions precisely on the nested cases the method targets; this requires either a theoretical argument or targeted ablation showing preserved distinctions.
Authors: We appreciate the referee's point on the representational properties of the CP form. TN-gram is motivated by the observation that order-absorption vectors can modulate shared factors to encode order-specific information without requiring separate tables. While the current manuscript does not include a formal proof against crosstalk, the empirical results across multiple tasks show that TN-gram matches or exceeds the performance of per-order hash tables, indicating that distinctions are preserved in practice. To directly address the concern, we will add a targeted ablation examining the effect of absorption vector rank on the model's ability to distinguish nested n-grams. revision: yes
-
Referee: [Abstract and Experiments section] The abstract states that comprehensive experiments demonstrate the performance claim, yet provides no quantitative results, ablation details on tensor rank, or description of how absorption vectors or rank were selected. Without these, it is impossible to assess whether the reported gains are robust or post-hoc.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will update the abstract to include key quantitative results (e.g., parameter reduction and perplexity or downstream metrics) and a brief statement on the tensor-rank selection procedure used in the experiments. revision: yes
Circularity Check
No circularity: architectural proposal validated by independent experiments
full rationale
The paper presents TN-gram as a new memory module based on CP decomposition with shared factors; its performance claims rest on empirical comparisons to Engram-style baselines rather than any derivation, fitted parameter, or self-citation that reduces the reported outcome to an input by construction. No load-bearing step equates the claimed benefit to a quantity defined inside the method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.17765 , year=
Faster language models with better multi-token prediction using tensor decomposition , author=. arXiv preprint arXiv:2410.17765 , year=
-
[2]
Liu, Hong and Zhang, Jiaqi and Wang, Chao and Hu, Xing and Lyu, Linkun and Sun, Jiaqi and Yang, Xurui and Wang, Bo and Li, Fengcun and Qian, Yulei and others , journal=
-
[3]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , editor =
2025
-
[4]
Cheng, Xin and Zeng, Wangding and Dai, Damai and Chen, Qinyu and Wang, Bingxuan and Xie, Zhenda and Huang, Kezhao and Yu, Xingkai and Hao, Zhewen and Li, Yukun and others , journal=
-
[5]
2025 , publisher =
Andrej Karpathy , title =. 2025 , publisher =
2025
-
[6]
2026 , publisher =
OpenAI , title =. 2026 , publisher =
2026
-
[7]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Guilherme Penedo and Hynek Kydl. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[8]
Manning, Christopher and Schutze, Hinrich , year=
-
[9]
1999 , publisher=
Chen, Stanley F and Goodman, Joshua , journal=. 1999 , publisher=
1999
-
[10]
Pauls, Adam and Klein, Dan , booktitle=
-
[11]
2015 , volume=
Cichocki, Andrzej and Mandic, Danilo and De Lathauwer, Lieven and Zhou, Guoxu and Zhao, Qibin and Caiafa, Cesar and PHAN, HUY ANH , journal=. 2015 , volume=
2015
-
[12]
2016 , publisher=
Cichocki, Andrzej and Lee, Namgil and Oseledets, Ivan and Phan, Anh-Huy and Zhao, Qibin and Mandic, Danilo P , journal=. 2016 , publisher=
2016
-
[13]
Gu, Yuxuan and Zhou, Wuyang and Iacovides, Giorgos and Mandic, Danilo , journal =
-
[14]
Gu, Yuxuan and Zhou, Wuyang and Iacovides, Giorgos and Mandic, Danilo , booktitle=. Te
-
[15]
Zhou, Wuyang and Gu, Yuxuan and Iacovides, Giorgos and Mandic, Danilo , booktitle=. Krom
-
[16]
Iacovides, Giorgos and Zhou, Wuyang and Li, Chao and Zhao, Qibin and Mandic, Danilo , journal=
-
[17]
Zhou, Wuyang and Iacovides, Giorgos and Konstantinidis, Kriton and Kisil, Ilya and Mandic, Danilo , journal=
-
[18]
Iacovides, Giorgos and Zhou, Wuyang and Mandic, Danilo , journal=
-
[19]
Advances in Neural Information Processing Systems , volume=
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser,. Advances in Neural Information Processing Systems , volume=
-
[20]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , booktitle=
-
[21]
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others , journal=
-
[22]
2001 , publisher=
Goodman, Joshua T , journal=. 2001 , publisher=
2001
-
[23]
Zellers, Rowan and Holtzman, Ari and Bisk, Yonatan and Farhadi, Ali and Choi, Yejin , booktitle=
-
[24]
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal=
-
[25]
Gordon, Andrew and Kozareva, Zornitsa and Roemmele, Melissa. * SEM 2012: The First Joint Conference on Lexical and Computational Semantics -- Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation ( S em E val 2012). 2012
2012
-
[26]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1421
-
[27]
Bisk, Yonatan and Zellers, Rowan and Gao, Jianfeng and Choi, Yejin and others , booktitle=
-
[28]
Mihaylov, Todor and Clark, Peter and Khot, Tushar and Sabharwal, Ashish , booktitle=
-
[29]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Paperno, Denis and Kruszewski, Germ \'a n and Lazaridou, Angeliki and Pham, Ngoc Quan and Bernardi, Raffaella and Pezzelle, Sandro and Baroni, Marco and Boleda, Gemma and Fern \'a ndez, Raquel. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2016. doi:10.18653/v1/P16-1144
-
[30]
SQ u AD : 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, Pranav and Zhang, Jian and Lopyrev, Konstantin and Liang, Percy. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016. doi:10.18653/v1/D16-1264
-
[31]
Transactions of the Association for Computational Linguistics
Reddy, Siva and Chen, Danqi and Manning, Christopher D. Transactions of the Association for Computational Linguistics. 2019. doi:10.1162/tacl_a_00266
-
[32]
Levesque, Hector J and Davis, Ernest and Morgenstern, Leora , journal=
-
[33]
B ool Q : Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, Christopher and Lee, Kenton and Chang, Ming-Wei and Kwiatkowski, Tom and Collins, Michael and Toutanova, Kristina. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1300
-
[34]
Zhong, Wanjun and Cui, Ruixiang and Guo, Yiduo and Liang, Yaobo and Lu, Shuai and Wang, Yanlin and Saied, Amin and Chen, Weizhu and Duan, Nan , booktitle=
-
[35]
Transactions on Machine Learning Research , year=
Srivastava, Aarohi and Rastogi, Abhinav and Rao, Abhishek and Shoeb, Abu Awal Md and Abid, Abubakar and Fisch, Adam and Brown, Adam R and Santoro, Adam and Gupta, Aditya and Garriga-Alonso, Adri. Transactions on Machine Learning Research , year=
-
[36]
2021 , publisher=
Sakaguchi, Keisuke and Bras, Ronan Le and Bhagavatula, Chandra and Choi, Yejin , journal=. 2021 , publisher=
2021
-
[37]
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and others , journal=
-
[38]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[39]
Kingma, Diederik P and Ba, Jimmy , journal=
-
[40]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Ainslie, Joshua and Lee-Thorp, James and De Jong, Michiel and Zemlyanskiy, Yury and Lebr. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[41]
Llama Team , journal=
-
[42]
and Bader, Brett W
Kolda, Tamara G. and Bader, Brett W. , title =. SIAM Review , volume =. 2009 , doi =
2009
-
[43]
Zhou, Yanqi and Lei, Tao and Liu, Hanxiao and Du, Nan and Huang, Yanping and Zhao, Vincent and Dai, Andrew M and Le, Quoc V and Laudon, James and others , journal=
-
[44]
2017 , url=
Noam Shazeer and Azalia Mirhoseini and Krzysztof Maziarz and Andy Davis and Quoc Le and Geoffrey Hinton and Jeff Dean , booktitle=. 2017 , url=
2017
-
[45]
2017 , publisher=
Bojanowski, Piotr and Grave, Edouard and Joulin, Armand and Mikolov, Tomas , journal=. 2017 , publisher=
2017
-
[46]
Brants, Thorsten and Popat, Ashok and Xu, Peng and Och, Franz Josef and Dean, Jeffrey , booktitle=
-
[47]
Nguyen, Timothy , journal=
-
[48]
Yu, Da and Cohen, Edith and Ghazi, Badih and Huang, Yangsibo and Kamath, Pritish and Kumar, Ravi and Liu, Daogao and Zhang, Chiyuan , journal=
-
[49]
Pagnoni, Artidoro and Pasunuru, Ramakanth and Rodriguez, Pedro and Nguyen, John and Muller, Benjamin and Li, Margaret and Zhou, Chunting and Yu, Lili and Weston, Jason E and Zettlemoyer, Luke and others , booktitle=
-
[50]
Tito Svenstrup, Dan and Hansen, Jonas and Winther, Ole , journal=
-
[51]
Xu, Mingxue and Xu, Yao Lei and Mandic, Danilo P , journal=
-
[52]
Novikov, Alexander and Podoprikhin, Dmitrii and Osokin, Anton and Vetrov, Dmitry P , journal=
-
[53]
Frank Wilcoxon , journal =
-
[54]
Yang, Yifan and Zhou, Jiajun and Wong, Ngai and Zhang, Zheng. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.174
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.