From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment
Pith reviewed 2026-05-22 00:10 UTC · model grok-4.3
The pith
Task-sensitive attention heads can guide both data selection and parameter pruning to align LLMs far more efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation, acting as keys that unlock specific data patterns. Building on this observation, we propose From Parameters to Data (P2D), a unified framework that leverages these task-sensitive attention heads as a dual compass for both sample mining and structural pruning. To rigorously quantify the total pipeline cost, we introduce the Alignment Efficiency Ratio (AER) metric for both selection latency and training time. Mechanistically, P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data, establishing a synergistic 7.
What carries the argument
task-sensitive attention heads identified via a lightweight proxy and used as a dual compass for sample mining and structural pruning
Load-bearing premise
A sparse subset of attention heads plays a dominant role in task-specific adaptation and acts as keys that unlock specific data patterns.
What would settle it
An experiment in which data selected using randomly chosen attention heads performs no better than data selected using the task-sensitive heads identified by the proxy.
Figures







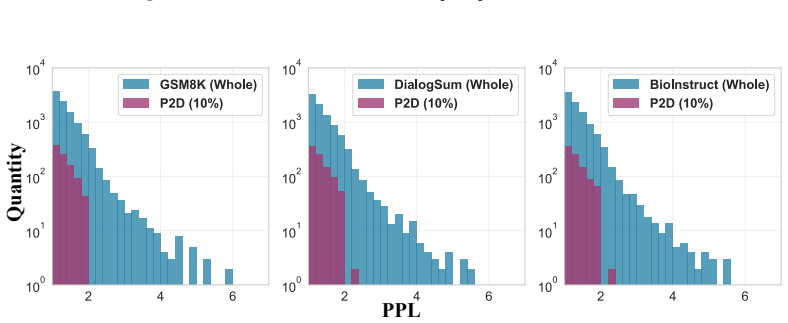
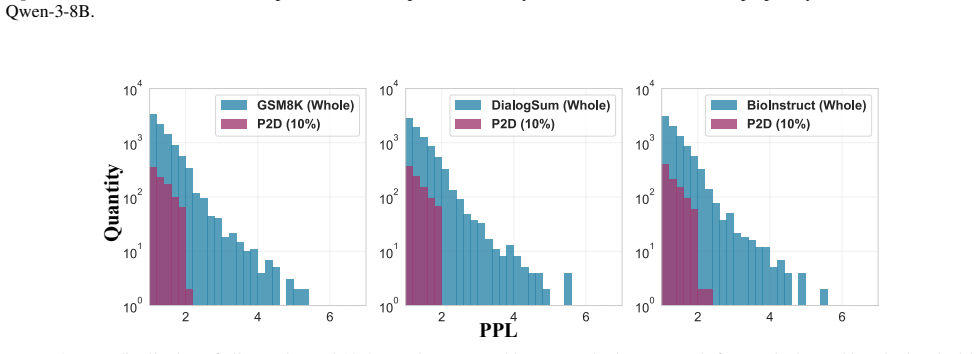

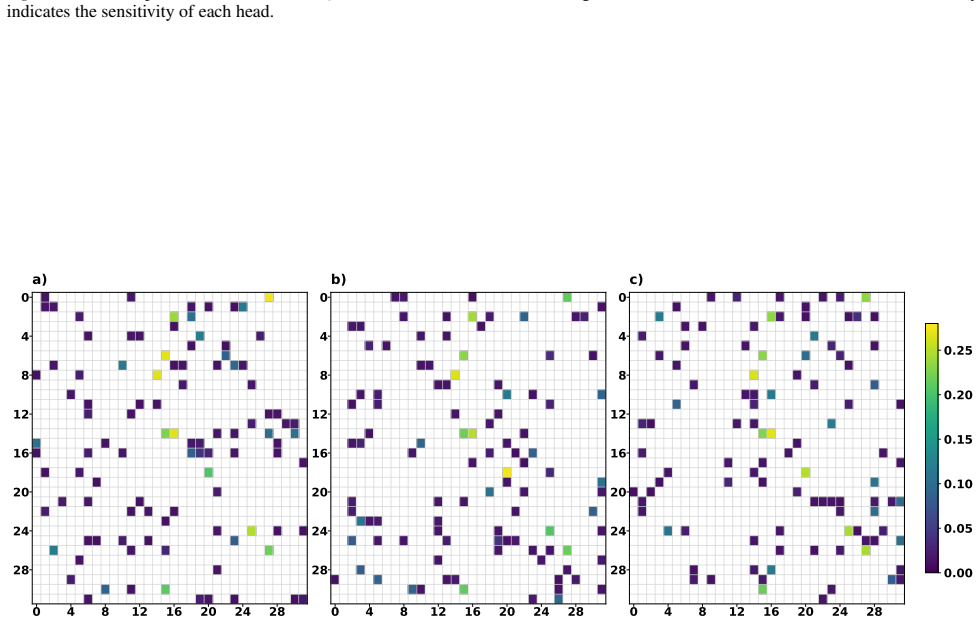
read the original abstract
Adapting Large Language Models (LLMs) to specialized domains typically incurs high data and computational overhead. While prior efficiency efforts have largely treated data selection and parameter-efficient fine-tuning as isolated processes, our empirical analysis suggests they may be intrinsically coupled. We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation, acting as keys that unlock specific data patterns. Building on this observation, we propose From Parameters to Data (P2D), a unified framework that leverages these task-sensitive attention heads as a dual compass for both sample mining and structural pruning. To rigorously quantify the total pipeline cost, we introduce the Alignment Efficiency Ratio (AER) metric for both selection latency and training time. Mechanistically, P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data, establishing a synergistic pipeline. Empirically, by updating merely 10% of attention heads on 10% of the data, P2D achieves an 8.3 pp performance gain over strong baselines and delivers a 7.0x end-to-end time speedup. These results validate that precise parameter-data synchronization eliminates redundancy, offering a new paradigm for efficient alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper posits the Strong Map Hypothesis that a sparse subset of attention heads dominates task-specific adaptation in LLMs and proposes the P2D framework to use these heads as a dual filter for data curation and structural pruning. It introduces the Alignment Efficiency Ratio (AER) metric and claims that updating 10% of heads on 10% of data yields an 8.3 pp gain over baselines and a 7.0x end-to-end speedup.
Significance. If the Strong Map Hypothesis is causally validated and the efficiency gains hold under controlled experiments, the work could advance efficient LLM alignment by demonstrating synergistic parameter-data selection. The AER metric provides a potentially useful holistic efficiency measure that accounts for both selection and training costs.
major comments (3)
- [Abstract] Abstract: The central empirical claim of an 8.3 pp performance gain and 7.0x speedup from updating merely 10% of attention heads on 10% of the data is presented without any description of experimental setup, datasets, baseline definitions, number of runs, or statistical tests. This directly undermines evaluation of the load-bearing result.
- [Abstract] Abstract: The Strong Map Hypothesis is derived from the same empirical observations used to identify heads and curate data, with no mention of independent held-out validation, causal ablation (e.g., proxy-selected heads vs. random 10% subsets), or falsification tests. Without such controls, the reported gains risk being attributable to generic sparsity rather than the hypothesized parameter-data mapping.
- [Abstract] Abstract: The Alignment Efficiency Ratio (AER) is introduced to quantify total pipeline cost including selection latency and training time, yet no definition, formula, or computation details are supplied. This leaves the 7.0x speedup claim ungrounded.
minor comments (1)
- [Abstract] The abstract refers to 'strong baselines' without naming them; the full manuscript should explicitly list and cite all comparison methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the abstract. We address each comment below and will revise the abstract to incorporate the requested clarifications while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of an 8.3 pp performance gain and 7.0x speedup from updating merely 10% of attention heads on 10% of the data is presented without any description of experimental setup, datasets, baseline definitions, number of runs, or statistical tests. This directly undermines evaluation of the load-bearing result.
Authors: We agree that the abstract would benefit from additional context to allow readers to evaluate the central claims more readily. In the revised manuscript we will update the abstract to briefly note the primary datasets, the strong baselines used for comparison, the number of random seeds, and the statistical tests applied. Full experimental details remain in the main body and appendices. revision: yes
-
Referee: [Abstract] Abstract: The Strong Map Hypothesis is derived from the same empirical observations used to identify heads and curate data, with no mention of independent held-out validation, causal ablation (e.g., proxy-selected heads vs. random 10% subsets), or falsification tests. Without such controls, the reported gains risk being attributable to generic sparsity rather than the hypothesized parameter-data mapping.
Authors: The hypothesis is motivated by initial observations but is evaluated through downstream task performance on held-out data. To directly address the concern regarding generic sparsity, we will add explicit ablation results comparing task-sensitive heads against random 10% subsets (both for heads and data) in the experiments section and will reference these controls concisely in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: The Alignment Efficiency Ratio (AER) is introduced to quantify total pipeline cost including selection latency and training time, yet no definition, formula, or computation details are supplied. This leaves the 7.0x speedup claim ungrounded.
Authors: We acknowledge that the abstract omits the formal definition of AER. We will revise the abstract to include a one-sentence definition (AER as the ratio of end-to-end baseline alignment time to P2D time, incorporating both selection and training costs) and will retain the full formula and computation details in the main text. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's chain begins with an empirical observation that data selection and parameter-efficient tuning may be coupled, from which the Strong Map Hypothesis is posited as an interpretive claim. The P2D framework is then constructed by using identified heads as a filter for pruning and sample selection, with results measured via the AER metric and reported performance deltas. This sequence does not reduce any claimed prediction or first-principles result to its inputs by construction; the hypothesis functions as a motivating observation rather than a self-referential definition, and the reported gains are measured outcomes of the proposed pipeline rather than statistically forced re-statements of the initial analysis. No equations, fitted parameters renamed as predictions, or self-citation chains that bear the central load appear in the provided text. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- 10% threshold for heads and data
axioms (1)
- ad hoc to paper Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation
invented entities (2)
-
Strong Map Hypothesis
no independent evidence
-
Alignment Efficiency Ratio (AER)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We posit the Strong Map Hypothesis: a sparse subset of attention heads plays a dominant role in task-specific adaptation... P2D identifies critical heads via a lightweight proxy and uses them as a functional filter to curate high-affinity data
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AER(f) = t_f / t_FFT ... updates merely 10% of attention heads on 10% of the data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
PMLR, 2019. Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. Humane, P., Cudrano, P., Kaplan, D. Z., Matteucci, M., Chakraborty, S., and Rish, I. Influence functions for efficient data selection in reasoning.arXiv preprint arXiv:2510.06108,...
-
[2]
The top-ranking heads form the task-sensitive setH T
Fast Head Identification:Each attention head in M0 is scored according to its relevance to the downstream task, using a lightweight proxy model or gradient-based criterion. The top-ranking heads form the task-sensitive setH T
-
[3]
The highest-scoring instances are gathered into the curated subsetD T
Parameter-Guided Data Selection:We use HT to compute a relevance score for every example in D, for instance by measuring how strongly the identified heads activate on each input. The highest-scoring instances are gathered into the curated subsetD T
-
[4]
lock”) and the curated high-affinity data (the “key
Sparse Head Adaptation:Only the parameters corresponding to HT are updated, and training is performed exclusively onD T . This focused adaptation produces the final modelM P2D while preserving the remaining pretrained weights. 14 From Parameters to Data: A Task-Parameter-Guided Fine-Tuning Pipeline for Efficient LLM Alignment By restricting both the param...
-
[5]
Your response must contain only step-by-step calculations and the final answer
-
[6]
Replace ‘<number>’ with the correct final result (either an integer or a floating-point number)
The final output **must** be formatted as: ####<number>. Replace ‘<number>’ with the correct final result (either an integer or a floating-point number). No deviations or alternative formats are allowed
-
[7]
Do not add any commentary, questions, greetings, or extra remarks
-
[8]
Ensure your calculations are clear, concise, and correct, but only include the steps required to arrive at the final answer. Please answer each question step by step and provide the final answer following the instructions below. Input: Below are some demonstrations of how to format your answers: Question:<Question 1> Answer:<Answer 1> ... **Strictly use t...
-
[9]
**Summarize the dialogue concisely and fully**, ensuring all main points are captured
-
[10]
**Avoid adding extra commentary or irrelevant details** that are not part of the dialogue content
-
[11]
If a dialogue is unclear, incomplete, or lacks meaningful content, respond with ”No valid content to summarize
-
[12]
Please summarize dialogues based on the given instructions and demonstrations below
**Ensure every summary field is filled out.** Leaving any field blank is not allowed. Please summarize dialogues based on the given instructions and demonstrations below. Input: Below are some demonstrations of how to format your answers: Dialogue:<Dialogue 1> Summary:<Summary 1> ... **Strictly use the format specified below:** Summary 1:<Your summary to ...
-
[13]
**Ensure your responses are concise, clear, and focused on the provided instruction.**
-
[14]
**Follow the logical order of questions.** Do not skip or merge responses
-
[15]
**Avoid adding extra commentary or irrelevant details. DO NOT repeat or summarize the question.** Input: Below are some demonstrations of how to format your answers: Instruction:<Demonstration 1 Instruction> Input:<Demonstration 1 Input> Answer:<Demonstration 1 Answer> ... **Strictly use the format specified below:** Question 1 Answer:<your answer to Ques...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.