Benchmarking Large Language Models for Grapheme-to-Phoneme Conversion: A Japanese Case Study
Pith reviewed 2026-06-26 11:57 UTC · model grok-4.3
The pith
Large language models convert Japanese text to phonetic readings more accurately than traditional morphological analyzers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
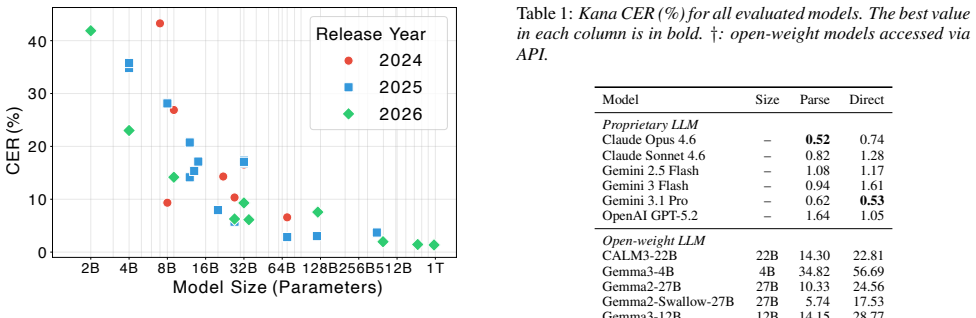
Large language models perform Japanese grapheme-to-phoneme conversion more accurately than conventional morphological analyzers, with the best models reaching kana character error rates below 0.52 percent on three thousand manually annotated sentences compared with 1.03 percent for the best traditional tool. Model size, version, and Japanese-specialized training are decisive factors. The parse mode, in which the model first performs morphological analysis before rule-based conversion, outperforms direct prediction for most models because the rules relieve the model of handling complex pronunciation exceptions. Feeding the resulting kana into a kana-input text-to-speech system yields better p
What carries the argument
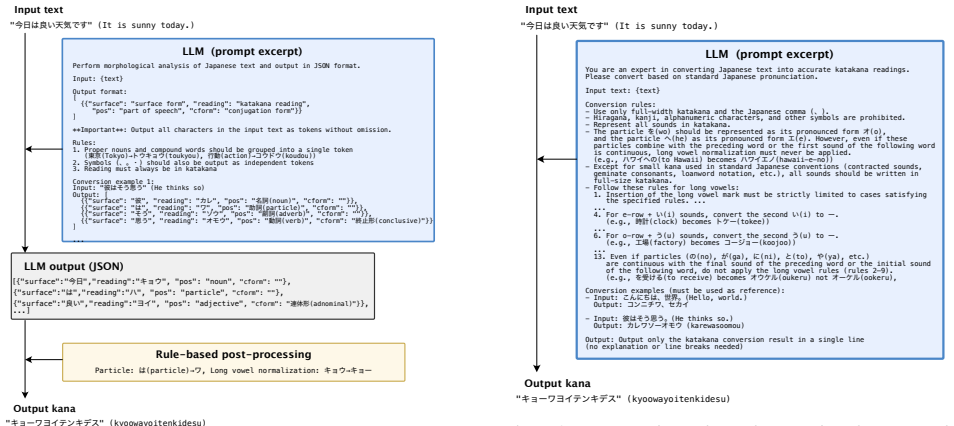
Parse-mode prompting, in which the LLM first performs morphological analysis before applying rule-based kana conversion.
Load-bearing premise
The three thousand manually annotated sentences are representative of real-world Japanese text and that character error rate directly predicts improvements in downstream text-to-speech pronunciation quality.
What would settle it
A new test set drawn from different domains where the best conventional analyzer records a lower kana character error rate than the top LLMs, or a listening test in which the TTS output from LLM kana shows no audible improvement over end-to-end TTS.
Figures
read the original abstract
Grapheme-to-phoneme (G2P) conversion is essential for controllable and robust text-to-speech, and large language models (LLMs), with broad linguistic knowledge, offer a promising approach. We benchmarked over 30 LLMs on Japanese G2P, comparing them with conventional morphological analyzers on 3000 manually annotated sentences. We evaluated two prompting strategies: a parse mode, where the LLM performs morphological analysis followed by rule-based kana conversion, and a direct mode, where the LLM directly predicts kana readings. The results show that model size, version, and Japanese-specialized training are key factors, with the best LLMs achieving kana character error rate below 0.52\% vs. the best conventional tool (1.03\%). Parse mode outperforms direct mode for most models, as rule-based post-processing relieves the LLM of handling complex pronunciation rules. We also show that feeding LLM-predicted kana into a kana-input TTS yields better pronunciation than end-to-end TTS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks over 30 LLMs for Japanese grapheme-to-phoneme conversion using parse and direct prompting modes on 3000 manually annotated sentences, reporting that the best LLMs reach kana CER below 0.52% compared to 1.03% for the best conventional morphological analyzer. Parse mode outperforms direct mode for most models due to rule-based post-processing, model size and Japanese specialization matter, and LLM-predicted kana fed to a kana-input TTS yields better pronunciation than end-to-end TTS.
Significance. If the results hold under scrutiny of the test set and metric, the work provides a concrete, reproducible benchmark showing LLMs can outperform traditional G2P tools for Japanese, with practical implications for controllable TTS. The explicit error-rate comparisons and mode ablation offer useful data points for the field.
major comments (2)
- [§4] §4 (Dataset): The central claim that LLMs achieve <0.52% CER (vs. 1.03% conventional) depends on the 3000 sentences being an unbiased, representative sample. The manuscript must specify selection criteria, coverage of proper nouns/loanwords/rare readings, and any balancing for frequency to support generalization to real-world Japanese text.
- [§6] §6 (TTS Evaluation): The claim that LLM kana improves TTS pronunciation over end-to-end systems rests on CER without perceptual validation or listening tests; character errors (especially pitch-accent) may not equally affect audible quality, so the downstream benefit requires direct evidence.
minor comments (2)
- [§3.2] §3.2 (Prompting): Provide the exact prompt templates for parse and direct modes rather than high-level descriptions, to enable replication.
- [Table 2] Table 2 (Results): Report per-model standard deviations or bootstrap CIs on CER to allow assessment of whether the 0.52% vs 1.03% gap is statistically reliable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the presentation of the dataset and evaluation. We respond to each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Dataset): The central claim that LLMs achieve <0.52% CER (vs. 1.03% conventional) depends on the 3000 sentences being an unbiased, representative sample. The manuscript must specify selection criteria, coverage of proper nouns/loanwords/rare readings, and any balancing for frequency to support generalization to real-world Japanese text.
Authors: We agree that the manuscript provides insufficient detail on dataset construction to fully support generalization claims. The original text only states that the sentences are 'manually annotated' without describing sampling. In the revised version we will expand §4 with the available information on selection (random sampling from a multi-genre corpus with post-hoc checks for coverage of proper nouns, loanwords and low-frequency readings) and will add an explicit limitations paragraph noting that formal stratification by frequency was not performed. revision: yes
-
Referee: [§6] §6 (TTS Evaluation): The claim that LLM kana improves TTS pronunciation over end-to-end systems rests on CER without perceptual validation or listening tests; character errors (especially pitch-accent) may not equally affect audible quality, so the downstream benefit requires direct evidence.
Authors: We accept that CER is an imperfect proxy for audible quality, particularly for pitch-accent errors. The manuscript relies on CER because it is objective, reproducible, and standard for G2P. In revision we will add a dedicated limitations paragraph in §6 acknowledging this gap and stating that perceptual listening tests would be needed for stronger downstream claims. We will not conduct new listening tests, as that would constitute a substantially different study. revision: partial
Circularity Check
No circularity: pure empirical benchmarking with direct measurements on fixed test set
full rationale
The paper performs direct empirical evaluation of LLMs versus conventional tools on a held-out set of 3000 manually annotated sentences, reporting character error rates without any derivations, equations, fitted parameters, or self-citations that reduce the reported results to prior fitted quantities or definitions. No load-bearing steps exist that collapse by construction; the central claims rest on observable error counts rather than any self-referential chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Grapheme-to-phoneme (G2P) conversion is a core component of text-to-speech (TTS) systems, in which written text is trans- formed into phonetic representations [1–5]. Recent end-to- end (E2E) TTS including large language model (LLM)-based ones directly convert text to speech waveforms [6–9], implicitly learning pronunciation rules from trainin...
-
[2]
Benchmarking Large Language Models for Grapheme-to-Phoneme Conversion: A Japanese Case Study
Japanese Grapheme-to-Phoneme Conversion Japanese grapheme-to-phoneme requires converting mixed- script text (kanji, hiragana, katakana, numerals, and Latin char- acters) into a phonetic representation. Accurate G2P conversion requires consideration of multiple linguistic factors. Word segmentation.Japanese text is written without spaces between words, req...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Proper nouns and compound words should be grouped into a single token ( 東京 (Tokyo)→トウキョウ (toukyou), 行動 (action)→コウドウ (koudou))
-
[4]
Symbols ( 、。・ ) should also be output as independent tokens
-
[5]
彼はそう思う
Reading must always be in katakana Conversion example 1: Input: " 彼はそう思う " (He thinks so) Output: [ {{"surface": " 彼 ", "reading": " カレ ", "pos": " 名詞 (noun)", "cform": ""}}, {{"surface": " は ", "reading": " ワ ", "pos": " 助詞 (particle)", "cform": ""}}, {{"surface": " そう ", "reading": " ソウ ", "pos": " 副詞 (adverb)", "cform": ""}}, {{"surface": " 思う ", "read...
-
[6]
今日は良い天気です
LLM-based G2P We evaluate two approaches for using LLMs in Japanese G2P, inspired by the cascade and direct methods studied by Fetrat Qharabagh et al. [23]. Ideally, the LLM would directly convert text to kana in a single step, which we refer to as direct mode. However, our preliminary experiments showed that instructing the LLM to handle all pronunciatio...
-
[7]
Insertion of the long vowel mark must be strictly limited to cases satisfying the specified rules
-
[8]
(e.g., 時計 (clock) becomes トケー (tokee))
For e-row + い (i) sounds, convert the second い (i) to ー . (e.g., 時計 (clock) becomes トケー (tokee))
-
[9]
(e.g., 工場 (factory) becomes コージョー (koojoo))
For o-row + う (u) sounds, convert the second う (u) to ー . (e.g., 工場 (factory) becomes コージョー (koojoo))
-
[10]
キョーワヨイテンキデス
Even if particles ( の (no), が (ga), に (ni), と (to), や (ya), etc.) are continuous with the final sound of the preceding word or the initial sound of the following word, do not apply the long vowel rules (rules 2–9). (e.g., を受ける (to receive) becomes オウケル (oukeru) not オーケル (ookeru), Conversion examples (must be used as reference): - Input: こんにちは、世界。 (Hello, ...
2024
-
[11]
Dataset and evaluation metric We used 3,000 sentences from the nonpara30 subset of the JVS (Japanese versatile speech) corpus [24]
Experiments 4.1. Dataset and evaluation metric We used 3,000 sentences from the nonpara30 subset of the JVS (Japanese versatile speech) corpus [24]. The sentences cover diverse phenomena, including onomatopoeia and loan- words, which are frequently out-of-vocabulary and thus particu- larly challenging for conventional dictionary-based tools. Using UniDic-...
-
[12]
For the experiments, we fine-tuned CosyV oice 2 [8] with LoRA [32] on the Corpus of Spontaneous Japanese (CSJ) [33] to accept kana input
Discussion: Comparison with E2E TTS To investigate the effectiveness of G2P on TTS, we compared the pronunciation accuracy of G2P-based TTS and E2E TTS systems. For the experiments, we fine-tuned CosyV oice 2 [8] with LoRA [32] on the Corpus of Spontaneous Japanese (CSJ) [33] to accept kana input. For G2P-based synthesis, LLM- predicted kana sequences wer...
-
[13]
The best proprietary API models achieved kana CER below 0.6%, outperforming conventional morpho- logical analyzers
Conclusions We presented a large-scale benchmark of LLM-based G2P con- version for Japanese. The best proprietary API models achieved kana CER below 0.6%, outperforming conventional morpho- logical analyzers. Parse mode was more effective than di- rect mode for most models, and Japanese-specialized training greatly improved local LLM performance. We also ...
-
[14]
Generative AI Use Disclosure Claude Code, ChatGPT, and Gemini were used for manuscript editing
-
[15]
Conditional and joint models for grapheme-to- phoneme conversion,
S. F. Chen, “Conditional and joint models for grapheme-to- phoneme conversion,” inEurospeech 2003, 2003, pp. 2033–2036
2003
-
[16]
Sequence-to-sequence neural net mod- els for grapheme-to-phoneme conversion,
K. Yao and G. Zweig, “Sequence-to-sequence neural net mod- els for grapheme-to-phoneme conversion,” inInterspeech 2015, 2015, pp. 3330–3334
2015
-
[17]
Grapheme-to-phoneme models for (al- most) any language,
A. Deri and K. Knight, “Grapheme-to-phoneme models for (al- most) any language,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pp. 399–408
2016
-
[18]
Epitran: Precision G2P for many languages,
D. R. Mortensen, S. Dalmia, and P. Littell, “Epitran: Precision G2P for many languages,” inProceedings of LREC 2018, 2018
2018
-
[19]
Results of the second SIGMORPHON shared task on multilingual grapheme-to-phoneme conversion,
L. F. Ashby, T. M. Bartley, S. Clematide, L. D. Signore, C. Gib- son, K. Gorman, Y . Lee-Sikka, P. Makarov, A. Malanoski, S. Miller, O. Ortiz, R. Raff, A. Sengupta, B. Seo, Y . Spektor, and W. Yan, “Results of the second SIGMORPHON shared task on multilingual grapheme-to-phoneme conversion,” inProceed- ings of the 18th SIGMORPHON Workshop on Computational...
2021
-
[20]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inInter- national Conference on Machine Learning, 2021, pp. 5530–5540
2021
-
[21]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y . Gu, C. Deng, W. Wang, S. Zhang, Z. Yan, and J. Zhou, “CosyV oice 2: Scalable streaming speech synthesis with large language models,” arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), 2025, pp. 6255–6271
2025
-
[24]
Open JTalk,
K. Tokuda and A. Lee, “Open JTalk,” https://open-jtalk. sourceforge.net/
-
[25]
Applying conditional random fields to Japanese morphological analysis,
T. Kudo, K. Yamamoto, and Y . Matsumoto, “Applying conditional random fields to Japanese morphological analysis,” inProceed- ings of EMNLP 2004, 2004, pp. 230–237
2004
-
[26]
Japanese pronunciation prediction as phrasal statistical machine translation,
J. Hatori and H. Suzuki, “Japanese pronunciation prediction as phrasal statistical machine translation,” inProceedings of the 5th International Joint Conference on Natural Language Processing, 2011, pp. 120–128
2011
-
[27]
Phonetic and prosodic information estimation from texts for genuine Japanese end-to-end text-to-speech,
N. Kakegawa, S. Hara, M. Abe, and Y . Ijima, “Phonetic and prosodic information estimation from texts for genuine Japanese end-to-end text-to-speech,” inInterspeech 2021, 2021, pp. 126– 130
2021
-
[28]
Enhancing Japanese text-to-speech ac- curacy with a novel combination Transformer-BERT-based G2P: Integrating pronunciation dictionaries and accent sandhi,
K. Kurihara and M. Sano, “Enhancing Japanese text-to-speech ac- curacy with a novel combination Transformer-BERT-based G2P: Integrating pronunciation dictionaries and accent sandhi,” inIn- terspeech 2024, 2024, pp. 2790–2794
2024
-
[29]
CC-G2PnP: Streaming grapheme-to-phoneme and prosody with Conformer-CTC for un- segmented languages,
Y . Shirahata and R. Yamamoto, “CC-G2PnP: Streaming grapheme-to-phoneme and prosody with Conformer-CTC for un- segmented languages,” arXiv preprint arXiv:2602.17157, 2026
-
[30]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Dong, Y . Du, C. Yang, Y . Chen, Z. Chen, J. Jiang, R. Ren, Y . Li, X. Tang, Z. Liu, P. Liu, J.-Y . Nie, and J.-R. Wen, “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
LLMSegm: Surface- level morphological segmentation using large language model,
K. Batsuren, G. Collell, and E. Vylomova, “LLMSegm: Surface- level morphological segmentation using large language model,” in Proceedings of LREC-COLING 2024, 2024, pp. 10 665–10 674
2024
-
[32]
Evaluating large language models for the tasks of PoS tagging within the Universal Dependency frame- work,
M. Machado and E. Ruiz, “Evaluating large language models for the tasks of PoS tagging within the Universal Dependency frame- work,” inProceedings of the 16th International Conference on Computational Processing of Portuguese, 2024, pp. 454–460
2024
-
[33]
A comparative analysis of word segmentation, part-of-speech tagging, and named entity recognition for historical Chinese sources, 1900–1950,
Z. Fang, L.-C. Wu, X. Kong, and S. D. Stewart, “A comparative analysis of word segmentation, part-of-speech tagging, and named entity recognition for historical Chinese sources, 1900–1950,” in Proceedings of the 5th International Conference on Natural Lan- guage Processing for Digital Humanities, 2025, pp. 1–6
1900
-
[34]
Leveraging large language mod- els for text normalization of non-standard words in text-to- speech synthesis,
M. Ma, H. Zen, and J. Zhao, “Leveraging large language mod- els for text normalization of non-standard words in text-to- speech synthesis,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2026, pp. 18 622– 18 626
2026
-
[35]
PhonologyBench: Evaluating phonological skills of large language models,
A. Suvarna, H. Khandelwal, and N. Peng, “PhonologyBench: Evaluating phonological skills of large language models,” arXiv preprint arXiv:2404.02456, 2024
-
[36]
Improv- ing grapheme-to-phoneme conversion through in-context knowl- edge retrieval with large language models,
D. Han, M. Cui, J. Kang, X. Wu, X. Liu, and H. Meng, “Improv- ing grapheme-to-phoneme conversion through in-context knowl- edge retrieval with large language models,” inISCSLP 2024, 2024
2024
-
[37]
LLM- powered grapheme-to-phoneme conversion: Benchmark and case study,
M. F. Qharabagh, Z. Dehghanian, and H. R. Rabiee, “LLM- powered grapheme-to-phoneme conversion: Benchmark and case study,” arXiv preprint arXiv:2409.08554, 2024
-
[38]
JSUT and JVS: Free Japanese voice corpora for accelerating speech synthesis research,
S. Takamichi, R. Sonobe, K. Mitsui, Y . Saito, T. Koriyama, N. Tanji, and H. Saruwatari, “JSUT and JVS: Free Japanese voice corpora for accelerating speech synthesis research,”Acoustical Science and Technology, vol. 41, no. 5, pp. 761–768, 2020
2020
-
[39]
Continual pre- training for cross-lingual LLM adaptation: Enhancing Japanese language capabilities,
K. Fujii, T. Nakamura, M. Loem, H. Iida, M. Ohi, K. Hattori, H. Shota, S. Mizuki, R. Yokota, and N. Okazaki, “Continual pre- training for cross-lingual LLM adaptation: Enhancing Japanese language capabilities,” inProceedings of the First Conference on Language Modeling (COLM), 2024
2024
-
[40]
Pointwise prediction for ro- bust, adaptable Japanese morphological analysis,
G. Neubig, Y . Nakata, and S. Mori, “Pointwise prediction for ro- bust, adaptable Japanese morphological analysis,” inProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, 2011, pp. 529–533
2011
-
[41]
KWJA: A unified Japanese an- alyzer based on foundation models,
N. Ueda, K. Omura, T. Kodama, H. Kiyomaru, Y . Murawaki, D. Kawahara, and S. Kurohashi, “KWJA: A unified Japanese an- alyzer based on foundation models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), 2023, pp. 538–548
2023
-
[42]
Sudachi: a Japanese tokenizer for business,
K. Takaoka, S. Hisamoto, N. Kawahara, M. Sakamoto, Y . Uchida, and Y . Matsumoto, “Sudachi: a Japanese tokenizer for business,” inProceedings of LREC 2018, 2018
2018
-
[43]
Vaporetto: Efficient Japanese tokenization based on improved pointwise linear classi- fication,
K. Akabe, S. Kanda, Y . Oda, and S. Mori, “Vaporetto: Efficient Japanese tokenization based on improved pointwise linear classi- fication,” arXiv preprint arXiv:2406.17185, 2024
-
[44]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[45]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “DeepSeek-R1: In- centivizing reasoning capability in LLMs via reinforcement learn- ing,” arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inInternational Conference on Learning Repre- sentations (ICLR), 2022
2022
-
[47]
Corpus of spontaneous Japanese: its design and evaluation,
K. Maekawa, “Corpus of spontaneous Japanese: its design and evaluation,” inISCA & IEEE Workshop on Spontaneous Speech Processing and Recognition, 2003
2003
-
[48]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inInternational Conference on Machine Learning, 2023, pp. 28 492–28 518
2023
-
[49]
UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,” inInterspeech 2022, 2022, pp. 4521–4525
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.