Cluster-Aware Dual-Level Test Specification Generation for Large-Scale Automotive Software Requirements
Pith reviewed 2026-06-27 02:49 UTC · model grok-4.3
The pith
Requirements clustering enables dual-level test specification generation that scales to thousands of automotive items while capturing cross-requirement dependencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
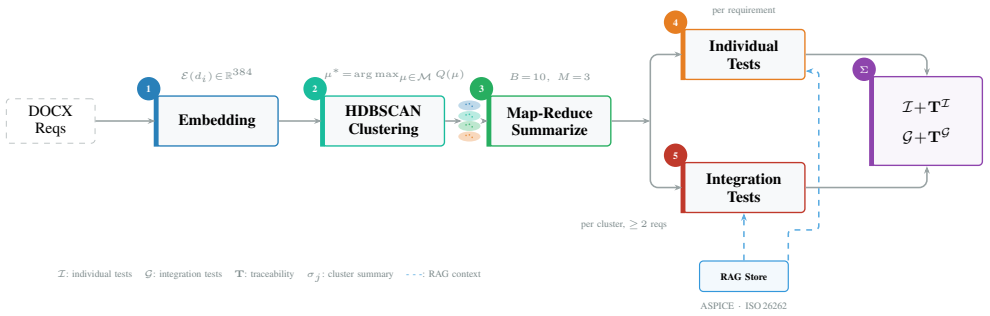
The cluster-aware dual-level approach first embeds requirements with sentence transformers, reduces dimensions with UMAP, and clusters them with HDBSCAN using an automatic minimum-size choice driven by combined normalized Silhouette and Calinski-Harabasz scores; each cluster is then distilled via multi-level map-reduce summarization that preserves quantitative thresholds and safety integrity levels, after which the pipeline generates verification tests for single requirements and integration tests for cluster-level feature behaviors, with bounded cross-cluster awareness supplied during each LLM call and all outputs grounded via RAG in the relevant standards.
What carries the argument
The Cluster-then-Summarize pipeline, which uses embedding-based clustering followed by map-reduce summarization to produce both individual and integration-level test specifications.
If this is right
- Integration test coverage rises because cluster topology supplies the groups needed to verify cross-requirement feature behavior.
- Summarization fidelity remains comparable to baseline methods through quality-criterion clustering and standard-grounded retrieval.
- The pipeline processes thousands of requirements without exceeding context limits or losing dependency information.
- Generated specifications satisfy both individual verification and cluster-level integration needs in one automated pass.
Where Pith is reading between the lines
- The same clustering-plus-dual-level pattern could be tested on large requirement sets from adjacent regulated domains such as medical-device software.
- If cluster quality metrics prove stable across projects, the automatic size selection could become a reusable preprocessing step for other requirement-analysis tasks.
- Extending the nearby-cluster context window might further reduce missed interactions, though this would require measuring the resulting token-budget trade-off.
Load-bearing premise
Embedding-based clustering with automatic minimum-size selection will group requirements such that the resulting clusters preserve the inter-requirement dependencies needed for meaningful integration tests.
What would settle it
A controlled comparison on the same requirement dataset in which the cluster-derived integration tests achieve lower coverage of documented cross-requirement interactions than either a non-clustered baseline or a human-generated reference set.
Figures

read the original abstract
Generating test specifications that satisfy Automotive SPICE SWE.6 requirements becomes increasingly challenging and time-consuming as projects scale to thousands of requirements. Because this manual process often consumes weeks of engineering effort, automation becomes a critical necessity. However, standard Large Language Model (LLM) approaches struggle at scale: processing requirements individually discards vital inter-requirement dependencies, while feeding entire corpora at once exceeds context-window limits, leading to incomplete integration coverage and redundant test cases. This paper presents a novel "Cluster-then-Summarize" pipeline that addresses these limitations through three-stages. Requirements are embedded using sentence transformers and grouped using UMAP dimensionality reduction followed by HDBSCAN density-based clustering. This grouping utilizes an automatic minimum cluster size selection driven by a quality criterion combining normalized Silhouette and Calinski-Harabasz scores. A multi-level map-reduce summarization algorithm then distills each cluster into concise, domain-conformant descriptions while preserving quantitative thresholds and safety integrity levels. The pipeline exploits the derived cluster topology to generate test specifications at two levels: individual requirement verification and cluster-level integration tests that verify cross-requirement feature behavior. A nearby-cluster context mechanism provides bounded cross-feature awareness during each LLM call, and Retrieval-Augmented Generation grounds all outputs in ISO 26262 and ASPICE standards. Evaluation on automotive requirement datasets of varying scale demonstrates that the cluster-aware approach improves integration test coverage and maintains summarization fidelity compared to baseline methods while scaling efficiently to thousands of requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a 'Cluster-then-Summarize' pipeline for automating test specification generation from large automotive requirements corpora to meet Automotive SPICE SWE.6. Requirements are embedded via sentence transformers, reduced with UMAP, and clustered with HDBSCAN using automatic minimum-size selection based on normalized Silhouette + Calinski-Harabasz scores. A multi-level map-reduce summarizer produces domain-conformant descriptions; dual-level test specs are then generated (per-requirement verification plus cluster-level integration tests) with nearby-cluster context and RAG grounding in ISO 26262/ASPICE. The central claim is that this yields higher integration-test coverage and better scalability than per-requirement or full-corpus LLM baselines while preserving summarization fidelity.
Significance. If the clustering step reliably surfaces the inter-requirement dependencies that matter for integration testing, the method could materially reduce the weeks of manual effort currently required for large automotive projects and improve consistency with safety standards. The explicit scaling claim to thousands of requirements and the use of automatic cluster-size selection are practical strengths that would be valuable if supported by reproducible quantitative evidence.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim that the cluster-aware approach 'improves integration test coverage' is presented without any quantitative metrics (coverage percentages, deltas vs. baselines), baseline definitions, dataset sizes or characteristics, or statistical tests. This absence makes the central empirical claim impossible to assess from the supplied description.
- [Method (clustering pipeline and dual-level generation)] Method (clustering and test-generation stages): the pipeline asserts that UMAP+HDBSCAN clusters (selected via the combined quality criterion) will produce groups whose cross-requirement interactions are the ones relevant for integration tests. No validation is described—neither overlap with an explicit dependency graph, nor manual audit of intra-cluster pairs for shared signals/timing/safety relations, nor comparison of generated cluster tests against a gold-standard integration set. This assumption is load-bearing for the claim that cluster-level tests deliver meaningful integration coverage beyond co-located individual tests.
minor comments (2)
- [Method] The automatic minimum-cluster-size procedure is described at a high level; a short pseudocode block or explicit formula for the combined Silhouette/Calinski-Harabasz criterion would improve reproducibility.
- [Method] The 'nearby-cluster context mechanism' is mentioned but its exact scope (how many neighboring clusters, how they are selected, token budget) is not quantified, making it difficult to judge the bounded cross-feature awareness claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important gaps in the presentation of empirical results and validation of the core clustering assumption. We address each point below and commit to revisions that will make the claims fully assessable.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim that the cluster-aware approach 'improves integration test coverage' is presented without any quantitative metrics (coverage percentages, deltas vs. baselines), baseline definitions, dataset sizes or characteristics, or statistical tests. This absence makes the central empirical claim impossible to assess from the supplied description.
Authors: We agree that the abstract and evaluation section currently state the improvement at a high level without the requested quantitative details. The manuscript reports results on automotive datasets of varying scale but does not include explicit coverage percentages, baseline definitions, dataset characteristics, or statistical tests. In the revised version we will expand the evaluation section to report these metrics, including coverage percentages and deltas versus the per-requirement and full-corpus LLM baselines, together with dataset sizes, domain characteristics, and appropriate statistical tests. revision: yes
-
Referee: [Method (clustering pipeline and dual-level generation)] Method (clustering and test-generation stages): the pipeline asserts that UMAP+HDBSCAN clusters (selected via the combined quality criterion) will produce groups whose cross-requirement interactions are the ones relevant for integration tests. No validation is described—neither overlap with an explicit dependency graph, nor manual audit of intra-cluster pairs for shared signals/timing/safety relations, nor comparison of generated cluster tests against a gold-standard integration set. This assumption is load-bearing for the claim that cluster-level tests deliver meaningful integration coverage beyond co-located individual tests.
Authors: The clustering step is motivated by the use of semantic embeddings, under the assumption that requirements grouped by embedding similarity are likely to share integration-relevant interactions. We acknowledge that the current manuscript provides no explicit validation of this assumption against dependency graphs, manual audits of intra-cluster relations, or gold-standard integration test sets. In the revised manuscript we will add a validation subsection that includes a manual audit of sampled intra-cluster pairs for shared signals/timing/safety relations and, where available in the datasets, comparison of generated cluster-level tests against gold-standard integration sets. revision: yes
Circularity Check
No circularity: pipeline is a self-contained methodological description with no self-referential reductions
full rationale
The paper presents a three-stage pipeline (embedding via sentence transformers, UMAP+HDBSCAN clustering with automatic size selection via Silhouette/Calinski-Harabasz, followed by multi-level map-reduce summarization and dual-level test generation) without any equations, fitted parameters, or derivations that reduce outputs to inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked; the method is described as an engineering workflow evaluated on external datasets. The central claims concern empirical improvements in coverage and scalability, which rest on the pipeline's independent execution rather than any definitional equivalence or fitted-input renaming. This is the normal case of a non-circular applied-methods paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- minimum cluster size
axioms (1)
- domain assumption Sentence-transformer embeddings plus UMAP+HDBSCAN will produce clusters whose internal dependencies are relevant for integration testing.
Reference graph
Works this paper leans on
-
[1]
A systematic liter- ature review on using natural language processing in software require- ments engineering,
S.-C. Necula, F. Dumitriu, and V . Greavu-¸ Serban, “A systematic liter- ature review on using natural language processing in software require- ments engineering,”Electronics, vol. 13, no. 11, p. 2055, 2024
2055
-
[2]
Machine learning techniques for requirements engineering: A comprehensive literature review,
A. M. Rosado da Cruz and E. F. Cruz, “Machine learning techniques for requirements engineering: A comprehensive literature review,”Software, vol. 4, no. 3, p. 14, 2025
2025
-
[3]
Automotive SPICE process assessment / reference model, version 3.1,
VDA QMC Working Group 13, “Automotive SPICE process assessment / reference model, version 3.1,” Verband der Automobilindustrie (VDA), Tech. Rep., 2017
2017
-
[4]
International Organization for Standardization,ISO 26262: Road Vehi- cles – Functional Safety, Std., 2018, parts 1–12
2018
-
[5]
Sum- marization of elicitation conversations to locate requirements-relevant information,
T. Spijkman, X. de Bondt, F. Dalpiaz, and S. Brinkkemper, “Sum- marization of elicitation conversations to locate requirements-relevant information,” inInternational Working Conference on Requirements Engineering: Foundation for Software Quality (REFSQ), ser. Lecture Notes in Computer Science, vol. 13975. Springer, 2023, pp. 127–143
2023
-
[6]
Natural language processing for requirements engineering: A systematic mapping study,
L. Zhao, W. Alhoshan, A. Ferrari, K. J. Letsholo, M. A. Ajagbe, R. T. Batista-Navarro, and M. Sherwood, “Natural language processing for requirements engineering: A systematic mapping study,” vol. 54, no. 3. ACM, 2022, pp. 1–41
2022
-
[7]
Large language models (LLMs) for requirements engineering (RE): A systematic literature review,
N. Nascimento, A. Santos, and C. Lucena, “Large language models (LLMs) for requirements engineering (RE): A systematic literature review,”arXiv preprint arXiv:2509.11446, 2025
-
[8]
Abstractive text summarization: State of the art, challenges, and improvements,
H. Abdelaal, M. Kabir, K. N. Phan, and S. R. Fuad, “Abstractive text summarization: State of the art, challenges, and improvements,”arXiv preprint arXiv:2409.02413, 2024
-
[9]
Clustering and summarization of chat dialogues,
T. Jonsson, “Clustering and summarization of chat dialogues,” Master’s thesis, Linköping University, 2021
2021
-
[10]
Hierarchical summarization: Scaling up multi-document summarization,
J. Christensen, S. Soderland, G. Bansal, and Mausam, “Hierarchical summarization: Scaling up multi-document summarization,” inProceed- ings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, 2014, pp. 902–912
2014
-
[11]
Reducing redundancy in software testing: A K-means clustering approach to test case minimization,
S. Sharmaet al., “Reducing redundancy in software testing: A K-means clustering approach to test case minimization,”Journal of Information Systems Engineering and Management, vol. 10, no. 3s, 2025
2025
-
[12]
Clustering support for automated trac- ing,
C. Duan and J. Cleland-Huang, “Clustering support for automated trac- ing,” inProceedings of the 22nd IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM, 2007, pp. 244–253
2007
-
[13]
Identifying the requirement conflicts in SRS documents using sentence transformers and NER,
S. Mohamad, A. Cailliau, and R. Darimont, “Identifying the requirement conflicts in SRS documents using sentence transformers and NER,” arXiv preprint arXiv:2206.13690, 2022
-
[14]
Sentence-BERT: Sentence embeddings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” inProceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Hong Kong, China: Association for Computational Linguistics, 2019, pp. 3982–3992
2019
-
[15]
A transformer-based approach for abstractive summarization of requirements from obligations in software engineering contracts,
C. Jain, S. Raje, and G. Deshpande, “A transformer-based approach for abstractive summarization of requirements from obligations in software engineering contracts,”Automated Software Engineering, vol. 30, no. 2, 2023
2023
-
[16]
RepoSum- mary: Feature-oriented summarization and documentation generation for code repositories,
J. Zhang, W. Hou, X. Tang, J. Chen, Y . Zhou, and Q. Wei, “RepoSum- mary: Feature-oriented summarization and documentation generation for code repositories,”arXiv preprint arXiv:2510.11039, 2025
-
[17]
MARE: Multi-agents col- laboration framework for requirements engineering,
D. Jin, Z. Jin, X. Chen, and C. Wang, “MARE: Multi-agents col- laboration framework for requirements engineering,”arXiv preprint arXiv:2405.03256, 2024
-
[18]
A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects,
A. E. Ezugwu, A. M. Ikotun, O. N. Oyelade, L. Abualigah, J. O. Agushaka, C. I. Eke, and A. A. Akinyelu, “A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects,”Engineering Ap- plications of Artificial Intelligence, vol. 110, p. 104743, 2022
2022
-
[19]
A density-based algorithm for discovering clusters in large spatial databases with noise,
M. Ester, H.-P. Kriegel, J. Sander, and X. Xu, “A density-based algorithm for discovering clusters in large spatial databases with noise,” inPro- ceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD). AAAI Press, 1996, pp. 226–231
1996
-
[20]
Density-based clustering based on hierarchical density estimates,
R. J. G. B. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical density estimates,” inProceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), ser. Lecture Notes in Computer Science, vol. 7819. Springer, 2013, pp. 160–172
2013
-
[21]
Use case identification of natural language system requirements with graph-based clustering,
F. Pudlitz, F. Brokhausen, and A. V ogelsang, “Use case identification of natural language system requirements with graph-based clustering,” Design Science, vol. 9, 2023
2023
-
[22]
Enhancing software requirements cluster labeling using Wikipedia,
J. Mund, H. Femmer, D. Mendez, and J. Eckhardt, “Enhancing software requirements cluster labeling using Wikipedia,”IEEE Access, vol. 7, pp. 145 406–145 419, 2019
2019
-
[23]
BART: Denoising sequence-to- sequence pre-training for natural language generation, translation, and comprehension,
M. Lewis, Y . Liu, N. Goyal, M. Ghazvininejad, A. Mohamed, O. Levy, V . Stoyanov, and L. Zettlemoyer, “BART: Denoising sequence-to- sequence pre-training for natural language generation, translation, and comprehension,” pp. 7871–7880, 2020
2020
-
[24]
Natural language requirements processing: A 4d vision,
A. Ferrari, F. Dell’Orletta, A. Esuli, V . Gervasi, and S. Gnesi, “Natural language requirements processing: A 4d vision,”IEEE Software, vol. 34, no. 6, pp. 28–35, 2017, pURE dataset available at https://zenodo.org/ records/1414117
-
[25]
Research directions for using LLM in software requirement engineering: A systematic review,
F. Siavashi, D. Truscan, and O.-C. Granmo, “Research directions for using LLM in software requirement engineering: A systematic review,” Frontiers in Computer Science, vol. 7, 2025
2025
-
[26]
Generating high-level test cases from requirements using LLM: An industry study,
S. Masudaet al., “Generating high-level test cases from requirements using LLM: An industry study,”arXiv preprint arXiv:2510.03641, 2025
-
[27]
Multi-step generation of test specifications using large language models,
S. Adabalaet al., “Multi-step generation of test specifications using large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), Industry Track. Association for Computational Linguistics, 2025
2025
-
[28]
Testing procedure generation based on testing requirements for automotive components with LLM fine-tuning,
M.-Y . Chow and M. Kitani, “Testing procedure generation based on testing requirements for automotive components with LLM fine-tuning,” inNatural Language Processing and Information Systems (NLDB 2025), ser. Lecture Notes in Computer Science, vol. 15837. Springer, 2026
2025
-
[29]
Automating a complete software test process using LLMs: An automotive case study,
S. Wang, Y . Yu, R. Feldt, and D. Parthasarathy, “Automating a complete software test process using LLMs: An automotive case study,”arXiv preprint arXiv:2502.04008, 2025
-
[30]
Automated control logic test case generation using large language models,
H. Koziolek, V . Ashiwal, S. Bandyopadhyay, and K. R. Chandrika, “Automated control logic test case generation using large language models,”arXiv preprint arXiv:2405.01874, 2024
-
[31]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.