Certification of Machine Learning Models via Directional Sharpness
Pith reviewed 2026-06-25 23:53 UTC · model grok-4.3
The pith
Directional sharpness indicates generalization ability more reliably than existing metrics and supports efficient auditing including zero-knowledge proofs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
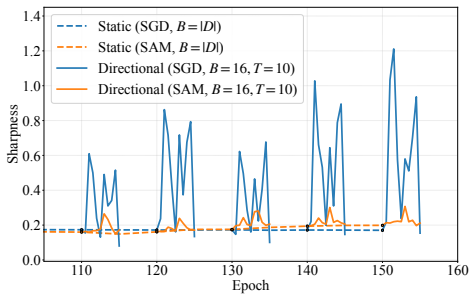
Directional sharpness is a metric designed to efficiently and reliably indicate generalization despite potential training deviations. It correlates more strongly with generalization than existing metrics and identifies models with poor generalization more reliably than existing metrics. Furthermore, directional sharpness is efficiently computable in model auditing settings, where the verifier has access to training data, and via zero-knowledge proofs that certify quality without revealing training data.
What carries the argument
Directional sharpness, a directional variant of the sharpness metric that enables efficient evaluation while remaining robust to deviations in the training procedure.
If this is right
- Auditors with access to training data can compute directional sharpness to certify model quality more reliably than with prior metrics.
- Zero-knowledge proofs can be constructed around directional sharpness to certify generalization properties without exposing the training data.
- The metric supplies a usable signal for quality even in cases where the training procedure was not followed exactly.
- Models flagged by directional sharpness as likely to generalize poorly can be rejected before deployment.
Where Pith is reading between the lines
- Auditing pipelines could adopt directional sharpness as a default check when training logs are incomplete or suspect.
- The zero-knowledge compatibility opens the possibility of public certification services that do not require participants to share proprietary data.
- If the metric remains stable across a wider range of architectures, it could reduce reliance on held-out test sets in regulated settings.
Load-bearing premise
The reported empirical and analytical evidence for stronger correlation and reliability will continue to hold when the training process deviates from the prescribed procedure.
What would settle it
A controlled experiment in which training is intentionally perturbed and directional sharpness then shows weaker correlation with measured generalization error than standard sharpness or test accuracy on the same models.
Figures
read the original abstract
In machine learning, model certification has been identified as an important method for gaining assurance about a model's trustworthiness and quality. A model's quality is largely determined by its ability to generalize, i.e., to perform well on data beyond what it was trained on. It is not possible to certify generalization directly, however, as it depends on unknown data and is not directly measurable. Proxies such as test accuracy can be misleading when the training process is perturbed (intentionally or accidentally), and metrics such as sharpness -- which has an empirically supported link to generalization -- are computationally expensive and can also serve as unreliable signals when training deviates from a prescribed procedure. In this work, we propose directional sharpness, a metric designed to efficiently and reliably indicate generalization despite potential training deviations. We provide empirical and analytical evidence that directional sharpness (1) correlates more strongly with generalization than existing metrics and (2) identifies models with poor generalization more reliably than existing metrics. Furthermore, directional sharpness is efficiently computable in model auditing settings, where the verifier has access to training data, and via zero-knowledge proofs that certify quality without revealing training data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes directional sharpness as a new metric for certifying the generalization ability of machine learning models. It claims to supply empirical and analytical evidence that directional sharpness correlates more strongly with generalization than existing metrics such as standard sharpness, identifies models with poor generalization more reliably (especially under training deviations), and admits efficient computation both in auditing settings with access to training data and via zero-knowledge proofs that avoid revealing the training data.
Significance. If the claimed correlations and reliability advantages hold under the stated conditions, directional sharpness could serve as a practical proxy for generalization in model certification pipelines, particularly where test accuracy is unreliable and where privacy-preserving verification is required. The zero-knowledge proof application is a concrete strength for deployment in auditing scenarios.
major comments (1)
- [Abstract] Abstract: the central claims rest on 'empirical and analytical evidence' for stronger correlation and reliability, yet the provided manuscript text contains no data tables, exclusion criteria, error bars, statistical tests, or derivation steps that would allow verification of these claims; this absence directly blocks assessment of whether the metric is load-bearingly superior.
Simulated Author's Rebuttal
We thank the referee for their review and for identifying an important point about verifiability of the central claims. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims rest on 'empirical and analytical evidence' for stronger correlation and reliability, yet the provided manuscript text contains no data tables, exclusion criteria, error bars, statistical tests, or derivation steps that would allow verification of these claims; this absence directly blocks assessment of whether the metric is load-bearingly superior.
Authors: The manuscript body (Sections 3 and 5) contains the analytical derivations and the empirical tables with correlation values, but we acknowledge that these elements are not summarized in the abstract and that additional statistical details (error bars, significance tests, explicit exclusion criteria) would improve verifiability. We will revise the abstract to briefly reference the key quantitative findings and will augment the experimental section with the requested statistical elements in the next version. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract and available text contain no equations, parameter-fitting procedures, self-citations, or derivation steps that could be inspected for reduction to inputs by construction. Claims rest on unspecified empirical and analytical evidence rather than any visible mathematical chain, ansatz, or uniqueness theorem. The derivation is therefore self-contained against external benchmarks with no load-bearing steps that reduce to self-definition, fitted inputs called predictions, or self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zero- knowledge proofs of training for deep neural networks
Kasra Abbaszadeh, Christodoulos Pappas, Jonathan Katz, and Dimitrios Papadopoulos. Zero- knowledge proofs of training for deep neural networks. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pages 4316–4330, 2024
2024
-
[2]
Foundations and Trends® in Machine Learning , author =
Pierre Alquier. User-friendly introduction to pac-bayes bounds.Foundations and Trends® in Machine Learning, 17(2):174–303, 2024.doi:10.1561/2200000100
-
[3]
Sharpness-aware minimization leads to low-rank features.Advances in Neural Information Processing Systems, 36:47032–47051, 2023
Maksym Andriushchenko, Dara Bahri, Hossein Mobahi, and Nicolas Flammarion. Sharpness-aware minimization leads to low-rank features.Advances in Neural Information Processing Systems, 36:47032–47051, 2023
2023
-
[4]
Towards understanding sharpness-aware mini- mization
Maksym Andriushchenko and Nicolas Flammarion. Towards understanding sharpness-aware mini- mization. InInternational conference on machine learning, pages 639–668. PMLR, 2022. 21
2022
-
[5]
Meenatchi Sundaram Muthu Selva Annamalai, Borja Balle, Jamie Hayes, Georgios Kaissis, and Emiliano De Cristofaro. The hitchhiker’s guide to efficient, end-to-end, and tight dp auditing.arXiv preprint arXiv:2506.16666, 2025
arXiv 2025
-
[6]
Why is sam robust to label noise? InThe Twelfth International Conference on Learning Representations, 2024
Christina Baek, J Zico Kolter, and Aditi Raghunathan. Why is sam robust to label noise? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[7]
Membership inference at- tacks and generalization: A causal perspective
Teodora Baluta, Shiqi Shen, S Hitarth, Shruti Tople, and Prateek Saxena. Membership inference at- tacks and generalization: A causal perspective. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 249–262, 2022
2022
-
[8]
Do we train on test data? purging cifar of near-duplicates.Journal of Imaging, 6(6):41, 2020
Bj ¨orn Barz and Joachim Denzler. Do we train on test data? purging cifar of near-duplicates.Journal of Imaging, 6(6):41, 2020
2020
-
[9]
Appen- zeller to brie: Efficient zero-knowledge proofs for mixed-mode arithmetic and Z2k
Carsten Baum, Lennart Braun, Alexander Munch-Hansen, Beno ˆıt Razet, and Peter Scholl. Appen- zeller to brie: Efficient zero-knowledge proofs for mixed-mode arithmetic and Z2k. In Giovanni Vigna and Elaine Shi, editors,ACM CCS 2021, pages 192–211. ACM Press, November 2021
2021
-
[10]
MozZ 2karella: Efficient vector-OLE and zero-knowledge proofs overZ2k
Carsten Baum, Lennart Braun, Alexander Munch-Hansen, and Peter Scholl. MozZ 2karella: Efficient vector-OLE and zero-knowledge proofs overZ2k. In Yevgeniy Dodis and Thomas Shrimpton, editors, CRYPTO 2022, Part IV, volume 13510 ofLNCS, pages 329–358. Springer, Cham, August 2022
2022
-
[11]
Mac’n’cheese: zero-knowledge proofs for boolean and arithmetic circuits with nested disjunctions
Carsten Baum, Alex J Malozemoff, Marc B Rosen, and Peter Scholl. Mac’n’cheese: zero-knowledge proofs for boolean and arithmetic circuits with nested disjunctions. InAnnual International Cryptol- ogy Conference, pages 92–122. Springer, 2021
2021
-
[12]
A unified stability analysis of SAM vs SGD: Role of data coher- ence and emergence of simplicity bias
Wei-Kai Chang and Rajiv Khanna. A unified stability analysis of SAM vs SGD: Role of data coher- ence and emergence of simplicity bias. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[13]
Coherent gradients: An approach to understanding generalization in gradient descent-based optimization
Satrajit Chatterjee. Coherent gradients: An approach to understanding generalization in gradient descent-based optimization. InInternational Conference on Learning Representations, 2020
2020
-
[14]
Why does sharpness-aware minimization generalize better than SGD? InThirty-seventh Conference on Neural Information Processing Systems, 2023
Zixiang Chen, Junkai Zhang, Yiwen Kou, Xiangning Chen, Cho-Jui Hsieh, and Quanquan Gu. Why does sharpness-aware minimization generalize better than SGD? InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[15]
Alessandro Chiesa, Yuncong Hu, Mary Maller, Pratyush Mishra, Psi Vesely, and Nicholas P. Ward. Marlin: Preprocessing zkSNARKs with universal and updatable SRS. In Anne Canteaut and Yuval Ishai, editors,EUROCRYPT 2020, Part I, volume 12105 ofLNCS, pages 738–768. Springer, Cham, May 2020
2020
-
[16]
Certified adversarial robustness via randomized smoothing
Jeremy Cohen, Elan Rosenfeld, and Zico Kolter. Certified adversarial robustness via randomized smoothing. Ininternational conference on machine learning, pages 1310–1320. PMLR, 2019
2019
-
[17]
Sharp minima can generalize for deep nets
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp minima can generalize for deep nets. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 1019–1028. JMLR.org, 2017. 22
2017
-
[18]
Improving line-point zero knowledge: Two multiplications for the price of one
Samuel Dittmer, Yuval Ishai, Steve Lu, and Rafail Ostrovsky. Improving line-point zero knowledge: Two multiplications for the price of one. In Heng Yin, Angelos Stavrou, Cas Cremers, and Elaine Shi, editors,ACM CCS 2022, pages 829–841. ACM Press, November 2022
2022
-
[19]
Preserving statistical validity in adaptive data analysis
Cynthia Dwork, Vitaly Feldman, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Aaron Leon Roth. Preserving statistical validity in adaptive data analysis. InProceedings of the forty-seventh annual ACM symposium on Theory of computing, pages 117–126, 2015
2015
-
[20]
In search of robust measures of generalization
Gintare Karolina Dziugaite, Alexandre Drouin, Brady Neal, Nitarshan Rajkumar, Ethan Caballero, Linbo Wang, Ioannis Mitliagkas, and Daniel M Roy. In search of robust measures of generalization. Advances in Neural Information Processing Systems, 33:11723–11733, 2020
2020
-
[21]
Gintare Karolina Dziugaite and Daniel M. Roy. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. InProceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence. AUAI Press, 2017
2017
-
[22]
Towards llm unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu. Towards llm unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond. InInternational Conference on Machine Learning, pages 15762–15778. PMLR, 2025
2025
-
[23]
The inverse variance–flatness relation in stochastic gradient descent is critical for finding flat minima.Proceedings of the National Academy of Sciences, 118(9):e2015617118, 2021
Yu Feng and Yuhai Tu. The inverse variance–flatness relation in stochastic gradient descent is critical for finding flat minima.Proceedings of the National Academy of Sciences, 118(9):e2015617118, 2021
2021
-
[24]
How tight can pac-bayes be in the small data regime?Advances in Neural Information Processing Systems, 34:4093–4105, 2021
Andrew Foong, Wessel Bruinsma, David Burt, and Richard Turner. How tight can pac-bayes be in the small data regime?Advances in Neural Information Processing Systems, 34:4093–4105, 2021
2021
-
[25]
Sharpness-aware minimization for efficiently improving generalization
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization. InInternational Conference on Learning Representations, 2021
2021
-
[26]
Secure and confidential certificates of online fairness.Advances in Neural Information Processing Systems, 38:40077–40107, 2025
Olive Franzese, Ali Shahin Shamsabadi, Carter Luck, and Hamed Haddadi. Secure and confidential certificates of online fairness.Advances in Neural Information Processing Systems, 38:40077–40107, 2025
2025
-
[27]
Williamson, and Oana Ciobotaru
Ariel Gabizon, Zachary J. Williamson, and Oana Ciobotaru. PLONK: Permutations over Lagrange- bases for oecumenical noninteractive arguments of knowledge. Cryptology ePrint Archive, Report 2019/953, 2019. URL:https://eprint.iacr.org/2019/953
2019
-
[28]
Backdoor attacks and countermeasures on deep learning: A comprehensive review
Yansong Gao, Bao Gia Doan, Zhi Zhang, Siqi Ma, Jiliang Zhang, Anmin Fu, Surya Nepal, and Hy- oungshick Kim. Backdoor attacks and countermeasures on deep learning: A comprehensive review. arXiv preprint arXiv:2007.10760, 2020
arXiv 2007
-
[29]
Memorization through the lens of curvature of loss function around samples
Isha Garg, Deepak Ravikumar, and Kaushik Roy. Memorization through the lens of curvature of loss function around samples. InProceedings of the 41st International Conference on Machine Learning, pages 15083–15101, 2024
2024
-
[30]
Experimenting with zero-knowledge proofs of training
Sanjam Garg, Aarushi Goel, Somesh Jha, Saeed Mahloujifar, Mohammad Mahmoody, Guru-Vamsi Policharla, and Mingyuan Wang. Experimenting with zero-knowledge proofs of training. InPro- ceedings of the 2023 ACM SIGSAC conference on computer and communications security, pages 1880–1894, 2023. 23
2023
-
[31]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
2020
-
[32]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations, 2015
2015
-
[33]
On the size of pairing-based non-interactive arguments
Jens Groth. On the size of pairing-based non-interactive arguments. In Marc Fischlin and Jean- S´ebastien Coron, editors,EUROCRYPT 2016, Part II, volume 9666 ofLNCS, pages 305–326. Springer, Berlin, Heidelberg, May 2016
2016
-
[34]
Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
Tianyu Gu, Kang Liu, Brendan Dolan-Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks.Ieee Access, 7:47230–47244, 2019
2019
-
[35]
Annotation artifacts in natural language inference data
Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R Bowman, and Noah A Smith. Annotation artifacts in natural language inference data. InProceedings of NAACL- HLT, pages 107–112, 2018
2018
-
[36]
A pac-bayesian link be- tween generalisation and flat minima
Maxime Haddouche, Paul Viallard, Umut S ¸ims ¸ekli, and Benjamin Guedj. A pac-bayesian link be- tween generalisation and flat minima. InALT 2025-36th International Conference on Algorithmic Learning Theory, pages 1–31, 2025
2025
-
[37]
Equality of opportunity in supervised learning
Moritz Hardt, Eric Price, and Nathan Srebro. Equality of opportunity in supervised learning. InPro- ceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 3323–3331, Red Hook, NY , USA, 2016. Curran Associates Inc
2016
-
[38]
Asymmetric valleys: Beyond sharp and flat local minima
Haowei He, Gao Huang, and Yang Yuan. Asymmetric valleys: Beyond sharp and flat local minima. Advances in neural information processing systems, 32, 2019
2019
-
[39]
Aggarwal, and Jiliang Tang
Pengfei He, Han Xu, Jie Ren, Yingqian Cui, Shenglai Zeng, Hui Liu, Charu C. Aggarwal, and Jiliang Tang. Sharpness-aware data poisoning attack. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[40]
Generalization bounds: Perspectives from information theory and pac-bayes.Foundations and Trends in Machine Learning, 18(1):1–223, 2025
Fredrik Hellstr ¨om, Giuseppe Durisi, Benjamin Guedj, and Maxim Raginsky. Generalization bounds: Perspectives from information theory and pac-bayes.Foundations and Trends in Machine Learning, 18(1):1–223, 2025
2025
-
[41]
Member- ship inference via backdooring
Hongsheng Hu, Zoran Salcic, Gillian Dobbie, Jinjun Chen, Lichao Sun, and Xuyun Zhang. Member- ship inference via backdooring. InInternational Joint Conference on Artificial Intelligence (31st: 2022), pages 3832–3838. International Joint Conferences on Artificial Intelligence Organization, 2022
2022
-
[42]
On feature learning in the presence of spurious correlations
Pavel Izmailov, Polina Kirichenko, Nate Gruver, and Andrew Gordon Wilson. On feature learning in the presence of spurious correlations. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc
2022
-
[43]
Fantastic generalization measures and where to find them
Yiding Jiang, Behnam Neyshabur*, Hossein Mobahi, Dilip Krishnan, and Samy Bengio. Fantastic generalization measures and where to find them. InInternational Conference on Learning Represen- tations, 2020. 24
2020
-
[44]
Provable certificates for adversarial examples: Fitting a ball in the union of polytopes.Advances in neural information processing systems, 32, 2019
Matt Jordan, Justin Lewis, and Alexandros G Dimakis. Provable certificates for adversarial examples: Fitting a ball in the union of polytopes.Advances in neural information processing systems, 32, 2019
2019
-
[45]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInterna- tional Conference on Learning Representations, 2017
2017
-
[46]
Better theory for SGD in the nonconvex world.Transactions on Machine Learning Research, 2023
Ahmed Khaled and Peter Richt ´arik. Better theory for SGD in the nonconvex world.Transactions on Machine Learning Research, 2023
2023
-
[47]
Blind justice: Fairness with encrypted sensitive attributes
Niki Kilbertus, Adri `a Gasc ´on, Matt Kusner, Michael Veale, Krishna Gummadi, and Adrian Weller. Blind justice: Fairness with encrypted sensitive attributes. InInternational Conference on Machine Learning, pages 2630–2639. PMLR, 2018
2018
-
[48]
Wilds: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Bal- subramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. InInternational conference on machine learning, pages 5637–5664. PMLR, 2021
2021
-
[49]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009
2009
-
[50]
Asam: Adaptive sharpness- aware minimization for scale-invariant learning of deep neural networks
Jungmin Kwon, Jeongseop Kim, Hyunseo Park, and In Kwon Choi. Asam: Adaptive sharpness- aware minimization for scale-invariant learning of deep neural networks. InInternational conference on machine learning, pages 5905–5914. PMLR, 2021
2021
-
[51]
libsnark: a C++ library for zkSNARK proofs, 2017
SCIPR Lab. libsnark: a C++ library for zkSNARK proofs, 2017. URL:https://github.com/ scipr-lab/libsnark
2017
-
[52]
Certified robustness to adversarial examples with differential privacy
Mathias Lecuyer, Vaggelis Atlidakis, Roxana Geambasu, Daniel Hsu, and Suman Jana. Certified robustness to adversarial examples with differential privacy. In2019 IEEE symposium on security and privacy (SP), pages 656–672. IEEE, 2019
2019
-
[53]
Friendly sharpness-aware min- imization
Tao Li, Pan Zhou, Zhengbao He, Xinwen Cheng, and Xiaolin Huang. Friendly sharpness-aware min- imization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5631–5640, 2024
2024
-
[54]
Backdoor learning: A survey.IEEE Transac- tions on Neural Networks and Learning Systems, 35(1):5–22, 2024
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey.IEEE Transac- tions on Neural Networks and Learning Systems, 35(1):5–22, 2024
2024
-
[55]
BackdoorBox: A python toolbox for backdoor learning
Yiming Li, Mengxi Ya, Yang Bai, Yong Jiang, and Shu-Tao Xia. BackdoorBox: A python toolbox for backdoor learning. InICLR Workshop, 2023
2023
-
[56]
Jiaxiang Liu, Simon Oya, and Florian Kerschbaum. Generalization techniques empirically outper- form differential privacy against membership inference.arXiv preprint arXiv:2110.05524, 2021
arXiv 2021
-
[57]
Sharpness-aware quantization for deep neural networks
Jing Liu, Jianfei Cai, and Bohan Zhuang. Sharpness-aware quantization for deep neural networks. arXiv preprint arXiv:2111.12273, 2021
arXiv 2021
-
[58]
McAllester
David A. McAllester. Some pac-bayesian theorems. InProceedings of the Eleventh Annual Con- ference on Computational Learning Theory, COLT’ 98, page 230–234, New York, NY , USA, 1998. Association for Computing Machinery. 25
1998
-
[59]
Pac-bayesian model averaging
David A McAllester. Pac-bayesian model averaging. InProceedings of the twelfth annual conference on Computational learning theory, pages 164–170, 1999
1999
-
[60]
Power-law escape rate of sgd
Takashi Mori, Liu Ziyin, Kangqiao Liu, and Masahito Ueda. Power-law escape rate of sgd. In International Conference on Machine Learning, pages 15959–15975. PMLR, 2022
2022
-
[61]
Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience
Vaishnavh Nagarajan and Zico Kolter. Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience. InInternational Conference on Learning Representations, 2019
2019
-
[62]
Information-theoretic generalization bounds for sgld via data-dependent estimates.Advances in Neu- ral Information Processing Systems, 32, 2019
Jeffrey Negrea, Mahdi Haghifam, Gintare Karolina Dziugaite, Ashish Khisti, and Daniel M Roy. Information-theoretic generalization bounds for sgld via data-dependent estimates.Advances in Neu- ral Information Processing Systems, 32, 2019
2019
-
[63]
Information-theoretic generalization bounds for stochastic gradient descent
Gergely Neu, Gintare Karolina Dziugaite, Mahdi Haghifam, and Daniel M Roy. Information-theoretic generalization bounds for stochastic gradient descent. InConference on Learning Theory, pages 3526–3545. PMLR, 2021
2021
-
[64]
Northcutt, Anish Athalye, and Jonas Mueller
Curtis G. Northcutt, Anish Athalye, and Jonas Mueller. Pervasive label errors in test sets destabilize machine learning benchmarks. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[65]
Fairness audit of machine learning models with confidential computing
Saerom Park, Seongmin Kim, and Yeon-sup Lim. Fairness audit of machine learning models with confidential computing. InProceedings of the ACM Web Conference 2022, pages 3488–3499, 2022
2022
-
[66]
Tighter risk certifi- cates for neural networks.Journal of Machine Learning Research, 22(227):1–40, 2021
Mar ´ıa P´erez-Ortiz, Omar Rivasplata, John Shawe-Taylor, and Csaba Szepesv´ari. Tighter risk certifi- cates for neural networks.Journal of Machine Learning Research, 22(227):1–40, 2021
2021
-
[67]
Relative flatness and generalization
Henning Petzka, Michael Kamp, Linara Adilova, Cristian Sminchisescu, and Mario Boley. Relative flatness and generalization. In A. Beygelzimer, Y . Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021
2021
-
[68]
Do imagenet classifiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InInternational conference on machine learning, pages 5389–5400. PMLR, 2019
2019
-
[69]
Mansi Sakarvadia, Aswathy Ajith, Arham Mushtaq Khan, Nathaniel C Hudson, Caleb Geniesse, Kyle Chard, Yaoqing Yang, Ian Foster, and Michael W. Mahoney. Mitigating memorization in language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[70]
The impact of neural network overparameterization on gradient confusion and stochastic gradient descent
Karthik Abinav Sankararaman, Soham De, Zheng Xu, W Ronny Huang, and Tom Goldstein. The impact of neural network overparameterization on gradient confusion and stochastic gradient descent. InInternational conference on machine learning, pages 8469–8479. PMLR, 2020
2020
-
[71]
Confidential-dpproof: Confidential proof of differentially private training
Ali Shahin Shamsabadi, Gefei Tan, Tudor Ioan Cebere, Aur ´elien Bellet, Hamed Haddadi, Nicolas Papernot, Xiao Wang, and Adrian Weller. Confidential-dpproof: Confidential proof of differentially private training. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[72]
Confidential-profitt: confidential proof 26 of fair training of trees
Ali Shahin Shamsabadi, Sierra Calanda Wyllie, Nicholas Franzese, Natalie Dullerud, S ´ebastien Gambs, Nicolas Papernot, Xiao Wang, and Adrian Weller. Confidential-profitt: confidential proof 26 of fair training of trees. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[73]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. InIEEE Symposium on Security and Privacy, pages 3–18. IEEE Computer Society, 2017
2017
-
[74]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. InInternational Conference on Learning Representations, 2015
2015
-
[75]
Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch.Advances in Neural Information Processing Systems, 35:19165–19178, 2022
Hossein Souri, Liam Fowl, Rama Chellappa, Micah Goldblum, and Tom Goldstein. Sleeper agent: Scalable hidden trigger backdoors for neural networks trained from scratch.Advances in Neural Information Processing Systems, 35:19165–19178, 2022
2022
-
[76]
Sharpness-aware minimiza- tion enhances feature quality via balanced learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, and Aditi Raghunathan. Sharpness-aware minimiza- tion enhances feature quality via balanced learning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[77]
Zkdl: Efficient zero-knowledge proofs of deep learning training.IEEE Transactions on Information Forensics and Security, 2024
Haochen Sun, Tonghe Bai, Jason Li, and Hongyang Zhang. Zkdl: Efficient zero-knowledge proofs of deep learning training.IEEE Transactions on Information Forensics and Security, 2024
2024
-
[78]
Inflation of test accuracy due to data leakage in deep learning-based classification of oct images.Scientific Data, 9(1):580, 2022
Iulian Emil Tampu, Anders Eklund, and Neda Haj-Hosseini. Inflation of test accuracy due to data leakage in deep learning-based classification of oct images.Scientific Data, 9(1):580, 2022
2022
-
[79]
Founding zero-knowledge proof of training on optimum vicinity
Gefei Tan, Adri `a Gasc´on, Sarah Meiklejohn, Mariana Raykova, Xiao Wang, and Ning Luo. Founding zero-knowledge proof of training on optimum vicinity. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 1173–1187, 2025
2025
-
[80]
Sharpness-aware machine unlearning
Haoran Tang and Rajiv Khanna. Sharpness-aware machine unlearning. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.