World Models in Words: Auditing Physical State-Transition Commitments in Vision-Language Models
Pith reviewed 2026-06-29 08:16 UTC · model grok-4.3
The pith
Vision-language models often give correct answers about physical scenes while holding physically invalid internal states in their reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
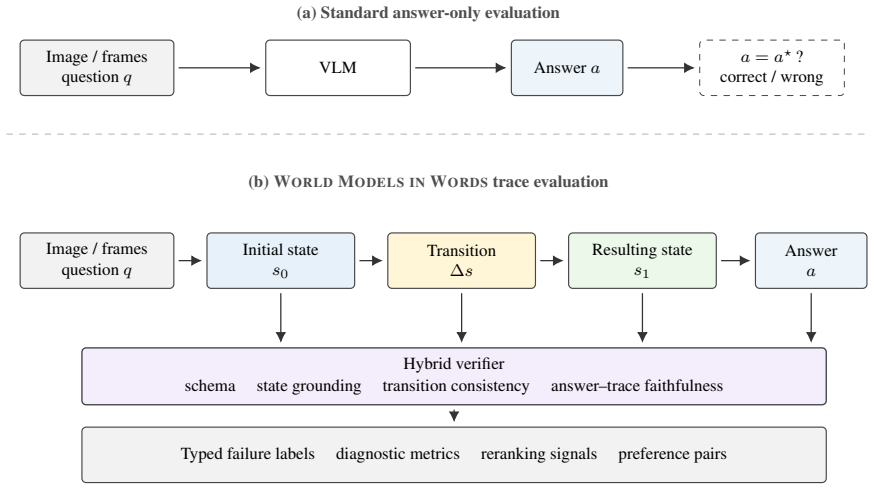
Instead of scoring only the mapping from image and question to answer, WMW asks models to produce a typed trace consisting of initial state s0, state transition Δs, resulting state s1, and answer a. The hybrid verifier checks for errors in objects, relations, forces, transitions, temporality, units, and faithfulness, demonstrating that answer-only evaluation misses substantial physical inconsistencies in model reasoning.
What carries the argument
The typed trace (s0, Δs, s1, a) together with the hybrid verifier that labels errors across schema validity, state grounding, transition consistency, and answer-trace compatibility.
If this is right
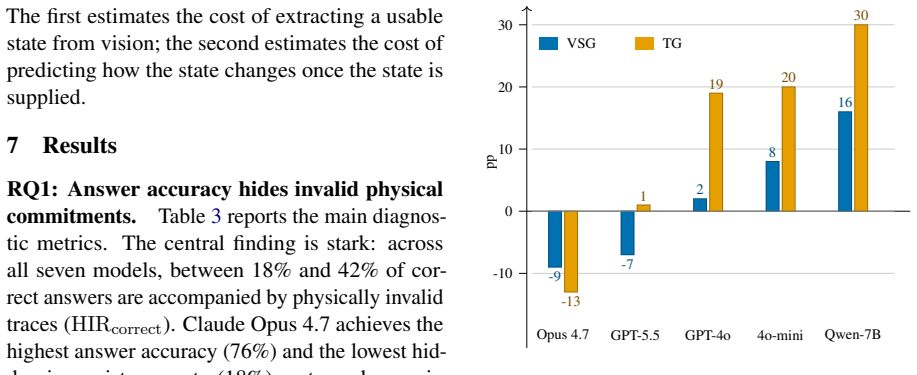
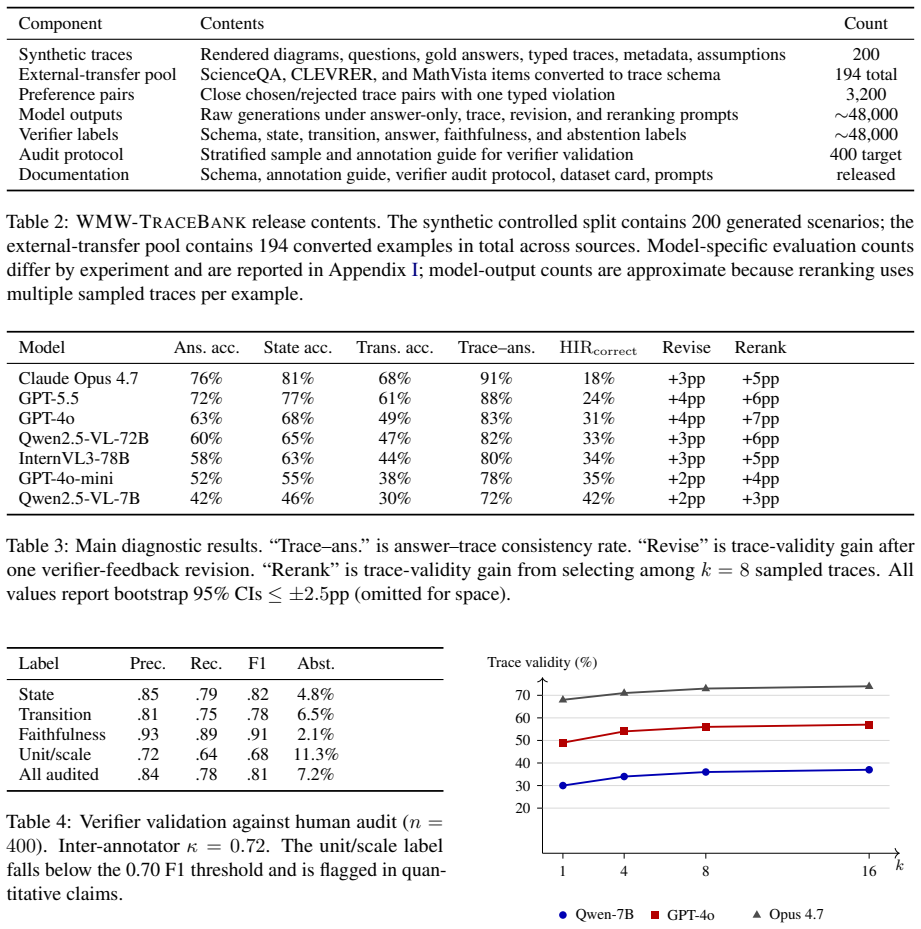
- 35% of correct answers from mid-tier VLMs are backed by physically invalid traces.
- Verifier-guided reranking can recover up to 7 percentage points of trace validity without loss in answer accuracy.
- Trace-level preference tuning reduces hidden inconsistency by 41% relative.
- The protocol allows measuring consistency between a VLM's stated physical commitments and its answers.
Where Pith is reading between the lines
- Applying this auditing method to larger models or different architectures could reveal scaling trends in physical consistency.
- Integrating the verifier into training loops might lead to VLMs that maintain coherent world models.
- Extending TraceBank to real-world videos or more complex physics could test generalizability beyond synthetic scenarios.
Load-bearing premise
The hybrid verifier accurately and without bias detects physical inconsistencies in the model-generated traces.
What would settle it
Compare the verifier's error labels against human expert annotations on a held-out set of traces to measure agreement rates.
Figures

read the original abstract
Vision-language models (VLMs) are increasingly used to answer questions about physical scenes, yet most evaluations reduce performance to a final answer. This hides whether the model perceived the right objects, represented the right physical state, predicted a plausible transition, or merely selected the right option for the wrong reasons. We introduce \wmw, an evaluation framework for auditing the \emph{language-expressed physical commitments} of VLMs. Instead of scoring only $I,q\mapsto a$, we ask models to produce a typed trace $I,q\mapsto(s_0,\Delta s,s_1,a)$: an initial state, a state transition, a resulting state, and an answer. A hybrid verifier then checks schema validity, state grounding, transition consistency, and answer-trace compatibility, yielding typed error labels such as object, relation, force, transition, temporal, unit/scale, and faithfulness errors. We release \tracebank, a controlled trace resource with \nSeed schema- and recomputation-validated synthetic scenarios across \nFamilies physics families, \nPairs minimally perturbed contrastive preference pairs, verifier code, audit guidelines, and model outputs. We evaluate \nModels VLMs on both controlled and external physical-reasoning examples. \wmw reveals failures that answer-only evaluation misses: 35\% of correct answers from mid-tier models are backed by physically invalid traces. Verifier-guided reranking recovers up to 7 percentage points of trace validity without sacrificing answer accuracy, and trace-level preference tuning reduces hidden inconsistency by 41\% relative. The contribution is not another final-answer physics benchmark, but a reusable protocol for measuring whether a VLM's stated physical world can be true at the same time as its answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the WMW framework to audit VLMs' language-expressed physical commitments by requiring models to output typed traces I,q ↦ (s0, Δs, s1, a) rather than final answers alone. A hybrid verifier checks schema validity, state grounding, transition consistency, and answer compatibility on traces from TraceBank (nSeed synthetic scenarios across nFamilies physics families) and external examples. On nModels VLMs, it reports that 35% of correct answers from mid-tier models rest on physically invalid traces; verifier-guided reranking recovers up to 7pp trace validity without harming answer accuracy; and trace-level preference tuning reduces hidden inconsistency by 41% relative. The core contribution is the reusable protocol and released resources rather than a new answer-only benchmark.
Significance. If the verifier is shown to be accurate, the work supplies a concrete, reusable method for exposing inconsistencies between a VLM's stated physical states/transitions and its answers, together with practical interventions (reranking, preference tuning) that improve trace validity. The public release of TraceBank, verifier code, and model outputs is a clear strength that supports follow-on work.
major comments (2)
- [Abstract and §3] Abstract and §3 (hybrid verifier): the central quantitative claims (35% invalid traces, 7pp reranking gain, 41% tuning reduction) are produced entirely by applying the hybrid verifier; yet the manuscript supplies no calibration data (human agreement rates, error analysis on the nSeed scenarios, or comparison against ground-truth physics simulators). This is load-bearing for every reported metric.
- [§4] §4 (TraceBank construction): the synthetic scenarios are described as 'schema- and recomputation-validated,' but the validation procedure, coverage of real-world physical demands, and any bias introduced by the chosen state representations are not detailed. This directly affects whether the 35% figure can be interpreted as evidence about VLMs rather than an artifact of the benchmark construction.
minor comments (2)
- [Notation] Notation: define \wmw and \tracebank on first use in the main text and ensure consistent typesetting throughout.
- [Tables/figures] Tables/figures: add confidence intervals or statistical tests for the reported percentage-point improvements and relative reductions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional detail on the hybrid verifier and TraceBank would strengthen the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (hybrid verifier): the central quantitative claims (35% invalid traces, 7pp reranking gain, 41% tuning reduction) are produced entirely by applying the hybrid verifier; yet the manuscript supplies no calibration data (human agreement rates, error analysis on the nSeed scenarios, or comparison against ground-truth physics simulators). This is load-bearing for every reported metric.
Authors: We agree that calibration data for the hybrid verifier is important to support the quantitative claims. The verifier's schema-validity and recomputation components are deterministic and rule-based, but we acknowledge the absence of human agreement rates or simulator comparisons in the current text. In the revised manuscript we will add a dedicated subsection with: (i) inter-annotator agreement from a human validation study on a subset of nSeed scenarios, (ii) a breakdown of error types detected by the verifier, and (iii) a limited comparison against physics-simulator outputs on selected traces. These additions will directly buttress the 35% invalid-trace, 7pp reranking, and 41% tuning figures. revision: yes
-
Referee: [§4] §4 (TraceBank construction): the synthetic scenarios are described as 'schema- and recomputation-validated,' but the validation procedure, coverage of real-world physical demands, and any bias introduced by the chosen state representations are not detailed. This directly affects whether the 35% figure can be interpreted as evidence about VLMs rather than an artifact of the benchmark construction.
Authors: We agree that the current description of TraceBank validation is insufficiently detailed. The manuscript states that scenarios are schema- and recomputation-validated, yet does not elaborate the procedure, real-world coverage, or representational biases. In the revision we will expand §4 with: a step-by-step account of the validation checks, a discussion of how the nFamilies map to common physical demands, and an explicit analysis of biases that may arise from the chosen state representations, including concrete examples. This will allow readers to assess whether the 35% figure primarily reflects VLM behavior or benchmark artifacts. revision: yes
Circularity Check
No significant circularity; new measurement protocol with independent checks
full rationale
The paper defines WMW as an explicit auditing protocol that generates typed traces and applies a hybrid verifier with enumerated checks (schema validity, state grounding, transition consistency, answer compatibility). Quantitative results (35% invalid traces, 7pp recovery, 41% inconsistency reduction) are produced by running this verifier on model outputs against the released TraceBank synthetic scenarios. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the verifier rules and scenario construction are stated directly rather than derived from prior fitted quantities or author-unique theorems. The framework is therefore self-contained as a measurement tool.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The hybrid verifier can reliably detect physical state-transition inconsistencies without introducing its own systematic errors.
invented entities (2)
-
WMW framework
no independent evidence
-
TraceBank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923. Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. 2019. PHYRE: A new benchmark for physical reasoning. InAd- vances in Neural Information Processing Systems, volume 32. Vahid Balazadeh, Mohammadmehdi Ataei, Hyunmin Cheong, Amir Hosein Khasahmadi, and Rahu...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Genie: Generative interactive environments. InProceedings of the International Conference on Machine Learning. Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vi- tor Guizilini, and Yue Wang. 2025. PhysBench: Benchmarking and enhancing vision-language mod- els for physical world understanding.arXiv preprint arXiv:2501.16411. Chelsea Finn, Ian Goodfellow, an...
-
[3]
Measuring Faithfulness in Chain-of-Thought Reasoning
Unsupervised learning for physical interac- tion through video prediction. InAdvances in Neural Information Processing Systems, volume 29. Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Gra- ham Neubig. 2023. PAL: Program-aided language models. InProceedings of the International Confer- ence on Machine Learning. ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36. Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. InAdvances i...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.