MultiSynt/MT: Trillion-Token Multi-Parallel Pre-Training Data Translated Across 36 Languages
Pith reviewed 2026-07-02 13:12 UTC · model grok-4.3
The pith
Synthetic translations of English data let LLMs match native multilingual baselines with 72 percent fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
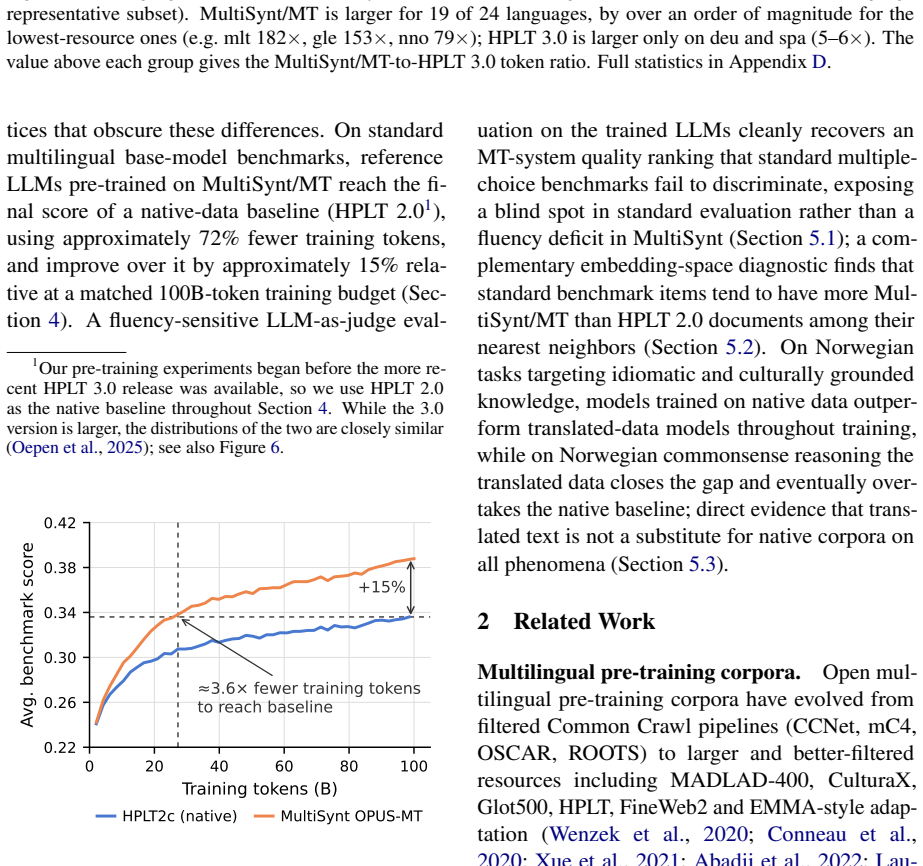
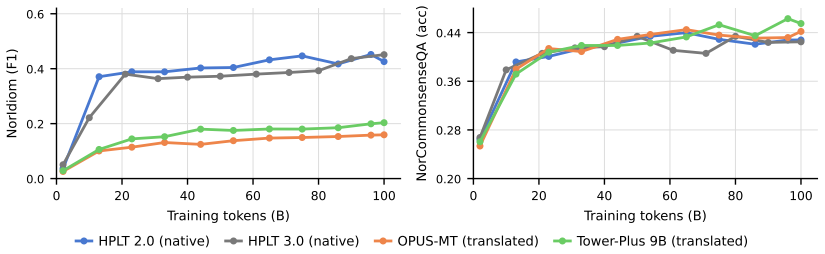
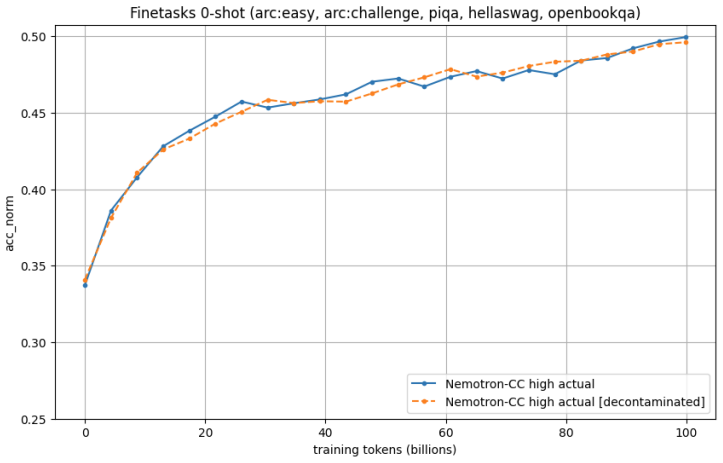
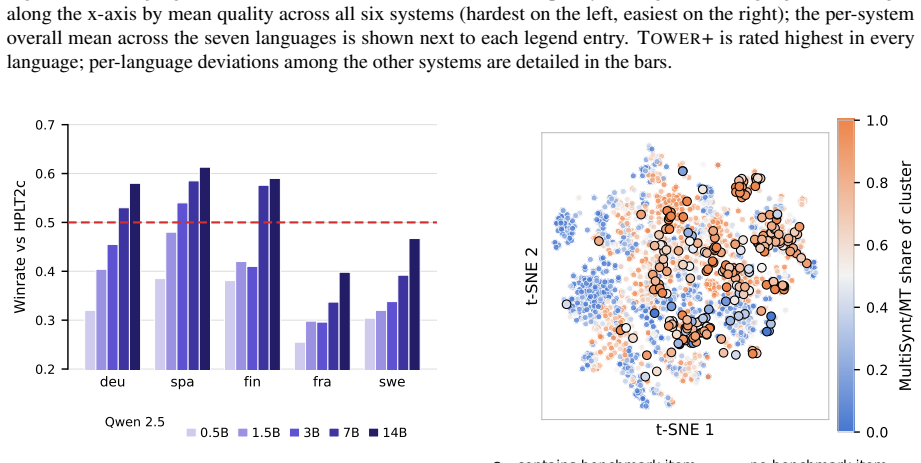
Reference LLMs trained on the MultiSynt/MT synthetic parallel corpus reach the final score of the native-data baseline HPLT 2.0 using roughly 72 percent fewer pre-training tokens and outperform it by approximately 15 percent relative at a matched 100-billion-token training budget.
What carries the argument
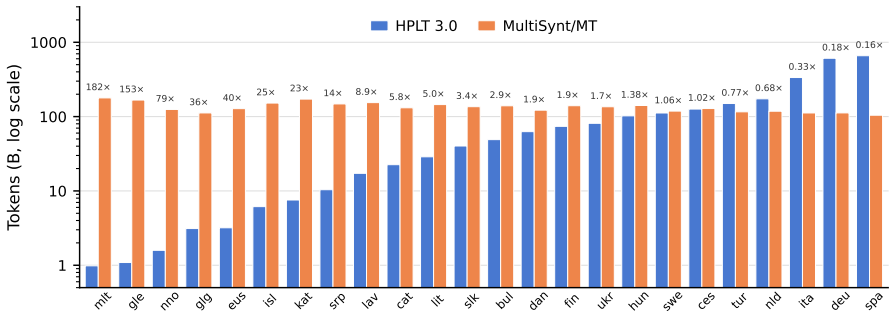
The MultiSynt/MT corpus itself: a row-aligned multi-parallel dataset produced by machine-translating 100 billion Nemotron-CC tokens into 36 languages with Tower+ and OPUS-MT/HPLT-MT systems.
If this is right
- Models reach equivalent benchmark performance with substantially lower total pre-training tokens.
- At a fixed 100-billion-token budget, synthetic data produces higher scores than the native baseline.
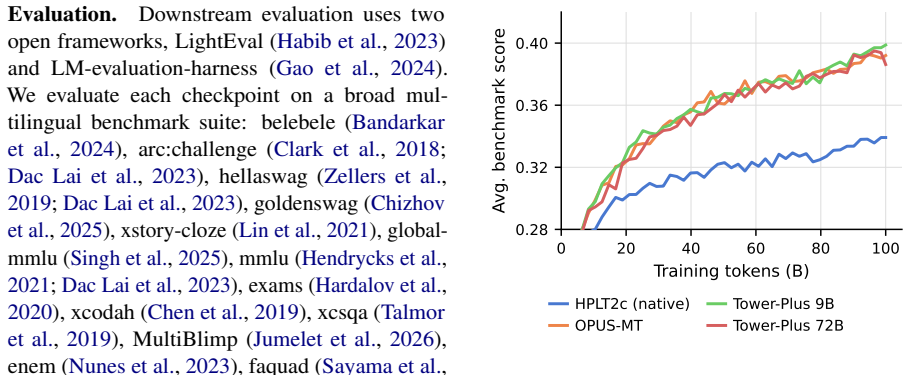
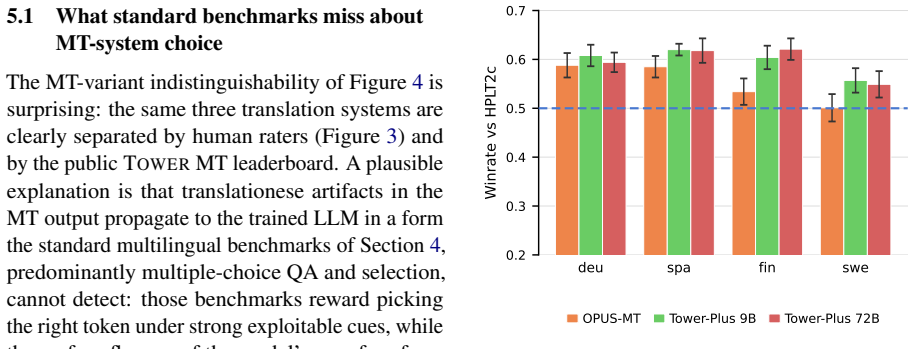
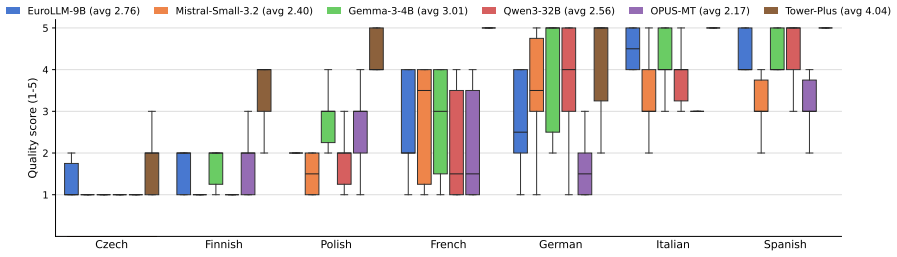
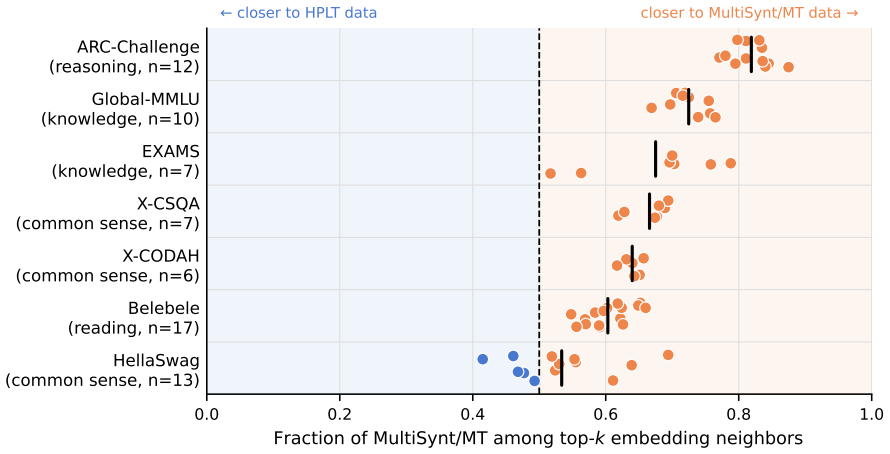
- Standard multiple-choice benchmarks miss translation-quality differences that fluency-sensitive LLM-as-judge evaluation recovers.
- Native data retains an advantage on Norwegian idiomatic and culturally grounded tasks.
- The corpus supplies the largest openly available pre-training resource for many medium- and lower-resource European languages.
Where Pith is reading between the lines
- The same translation pipeline could be applied to source data in additional languages once stronger machine-translation systems become available.
- Row-aligned outputs from multiple translation systems enable controlled experiments on how MT choice affects downstream model behavior.
- If source quality and translation fidelity matter more than native volume, future scaling laws may shift emphasis toward curated seed corpora rather than raw web crawls.
- Evaluation protocols that combine multiple-choice accuracy with fluency-sensitive judging may become necessary for reliable multilingual model comparison.
Load-bearing premise
Translated synthetic text preserves enough semantic and stylistic quality to serve as effective pre-training material comparable to native text.
What would settle it
Train identical reference LLMs on MultiSynt/MT and on HPLT 2.0 at the same token budget and measure whether the reported performance gap on the multilingual benchmark suite disappears or reverses.
Figures
read the original abstract
Open web-scale pre-training corpora remain concentrated in English, limiting multilingual LLM development. We introduce MultiSynt/MT, an open synthetic parallel corpus with approximately 4.8 trillion target-language tokens across 36 European languages, produced by translating 100 billion high-quality Nemotron-CC tokens with Tower+ and OPUS-MT/HPLT-MT systems. For many medium- and lower-resource European languages, this is the largest openly available pre-training resource. On a broad multilingual benchmark suite, reference LLMs trained on MultiSynt/MT reach the final score of HPLT 2.0, a native-data baseline, using roughly 72% fewer pre-training tokens, and outperform it by approximately 15% relative at a matched 100B-token training budget. Our analyses also identify evaluation blind spots: standard multiple-choice benchmarks miss translation-quality differences that a fluency-sensitive LLM-as-judge evaluation cleanly recovers on the trained LLMs (with no fluency deficit in MultiSynt itself), and Norwegian idiomatic and culturally grounded tasks remain better served by native data. We release the corpus, including row-aligned translations from multiple systems, to support controlled research on multilingual pre-training data and evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MultiSynt/MT, a synthetic multi-parallel pre-training corpus of ~4.8 trillion target-language tokens across 36 European languages, generated by translating 100 billion Nemotron-CC tokens with Tower+ and OPUS-MT/HPLT-MT systems. It claims that reference LLMs trained on this data reach the final score of the native-data baseline HPLT 2.0 using ~72% fewer pre-training tokens and outperform it by ~15% relative at a matched 100B-token budget. The work also identifies evaluation blind spots in standard benchmarks (recovered by LLM-as-judge fluency checks) and notes that native data remains superior on Norwegian idiomatic/cultural tasks; the corpus is released with row-aligned multi-system translations.
Significance. If the efficiency claims hold after verification of training controls and translation quality, the work would be a meaningful contribution to multilingual LLM pre-training by supplying the largest openly available resource for many medium- and lower-resource European languages. The explicit release of the full corpus (including multi-system alignments) is a clear strength that directly supports reproducible and controlled follow-up research on synthetic vs. native data. The discussion of benchmark limitations via LLM-as-judge evaluation is also useful for the field.
major comments (3)
- [Abstract] Abstract: the headline efficiency result (reaching HPLT 2.0 final score with 72% fewer tokens and +15% relative at 100B) is presented without any description of the reference LLM training setup, model size, optimizer, learning-rate schedule, or precise token-counting procedure, rendering the numbers unverifiable and the comparison to HPLT 2.0 impossible to assess.
- [Abstract and analyses section] Abstract and analyses section: the central claim that translated synthetic data can serve as drop-in pre-training material comparable to native text is load-bearing for the efficiency advantage, yet the manuscript itself states that native data remains superior on Norwegian idiomatic and culturally grounded tasks; no quantitative isolation of this gap (or its effect on aggregate scores) is provided, leaving open the possibility that benchmark gains are driven by easier subsets.
- [Abstract] Abstract: the LLM-as-judge fluency evaluation is offered as evidence that MultiSynt/MT has no fluency deficit, but this metric itself depends on an external model and addresses only one dimension; it does not test factual grounding, register, or syntactic fidelity across the 36 languages, which are required to substantiate the pre-training utility claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it stated the exact number of languages and the source English token count in the opening sentence rather than deferring to later text.
Simulated Author's Rebuttal
We are grateful for the referee's feedback, which has helped us identify areas for improvement in clarity and completeness. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline efficiency result (reaching HPLT 2.0 final score with 72% fewer tokens and +15% relative at 100B) is presented without any description of the reference LLM training setup, model size, optimizer, learning-rate schedule, or precise token-counting procedure, rendering the numbers unverifiable and the comparison to HPLT 2.0 impossible to assess.
Authors: We agree that additional context in the abstract would aid verifiability. The full manuscript details the reference LLM training setup in the experiments section, matching the HPLT 2.0 baseline protocol. We will revise the abstract to concisely describe the model scale, optimizer, and token counting procedure used for the comparison. revision: yes
-
Referee: [Abstract and analyses section] Abstract and analyses section: the central claim that translated synthetic data can serve as drop-in pre-training material comparable to native text is load-bearing for the efficiency advantage, yet the manuscript itself states that native data remains superior on Norwegian idiomatic and culturally grounded tasks; no quantitative isolation of this gap (or its effect on aggregate scores) is provided, leaving open the possibility that benchmark gains are driven by easier subsets.
Authors: The manuscript highlights this as a remaining advantage of native data. While the aggregate results demonstrate the overall benefit of MultiSynt/MT, we did not break down the contribution of the Norwegian tasks. In the revision, we will provide a quantitative isolation by reporting separate scores for Norwegian tasks and the rest of the benchmark to assess the impact on aggregates. revision: yes
-
Referee: [Abstract] Abstract: the LLM-as-judge fluency evaluation is offered as evidence that MultiSynt/MT has no fluency deficit, but this metric itself depends on an external model and addresses only one dimension; it does not test factual grounding, register, or syntactic fidelity across the 36 languages, which are required to substantiate the pre-training utility claim.
Authors: The LLM-as-judge evaluation is intended to address a specific blind spot in standard benchmarks regarding fluency. We recognize that it does not encompass all aspects of data quality such as factual grounding or syntactic fidelity. The pre-training claims are substantiated by the benchmark performance, with the judge serving as supporting analysis. We will revise the relevant sections to better delineate the limitations of this metric. revision: partial
Circularity Check
No circularity: empirical construction and external baseline comparison
full rationale
The paper constructs MultiSynt/MT by translating an external corpus (Nemotron-CC) using off-the-shelf MT systems (Tower+, OPUS-MT) and evaluates resulting LLMs against the independent HPLT 2.0 native baseline. No equations, fitted parameters, self-definitional loops, or load-bearing self-citations appear in the derivation. Claims rest on direct token-budget-matched training runs and benchmark scores, with explicit acknowledgment that native data remains superior on certain idiomatic tasks. This is a standard empirical contribution with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
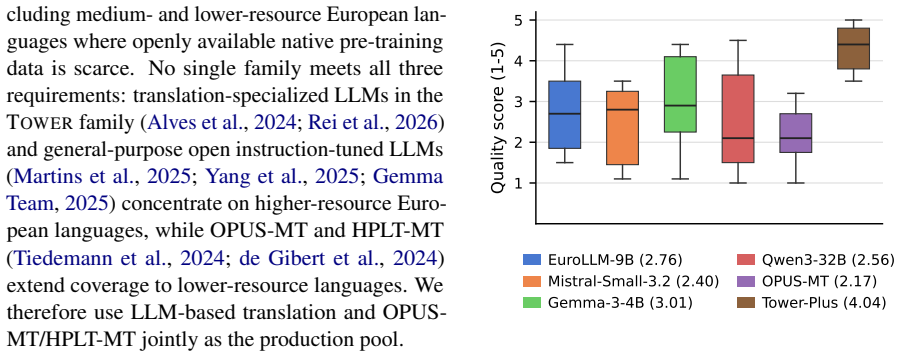
- domain assumption Machine translation output from Tower+ and OPUS-MT/HPLT-MT systems is of sufficient quality to serve as pre-training data without introducing systematic fluency or semantic deficits.
Reference graph
Works this paper leans on
-
[1]
multilingual
Translationese as a language in “multilingual” NMT , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
-
[2]
Translation studies in Scandinavia , volume=
Translationese in Swedish novels translated from English , author=. Translation studies in Scandinavia , volume=
-
[3]
CoRR , volume =
Martins, Pedro Henrique and Alves, Jo. CoRR , volume =. 2025 , doi =
2025
-
[4]
and Pombal, Jos
Rei, Ricardo and Guerreiro, Nuno M. and Pombal, Jos. Tower+: Bridging Generality and Translation Specialization in Multilingual. Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =
-
[5]
First Conference on Language Modeling , year =
Tower: An Open Multilingual Large Language Model for Translation-Related Tasks , author =. First Conference on Language Modeling , year =
-
[6]
2025 , doi =
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
2025
-
[7]
2025 , doi =
CoRR , volume =. 2025 , doi =
2025
-
[8]
LightEval: A lightweight framework for LLM evaluation , year =
Habib, Nathan and Fourrier, Cl. LightEval: A lightweight framework for LLM evaluation , year =
-
[9]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[10]
N or E val: A N orwegian Language Understanding and Generation Evaluation Benchmark
Mikhailov, Vladislav and Enstad, Tita and Samuel, David and Farseth a s, Hans Christian and Kutuzov, Andrey and Velldal, Erik and vrelid, Lilja. N or E val: A N orwegian Language Understanding and Generation Evaluation Benchmark. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.181
-
[11]
The Fourteenth International Conference on Learning Representations , year =
Learning from Synthetic Data Improves Multi-hop Reasoning , author =. The Fourteenth International Conference on Learning Representations , year =
-
[12]
AI models collapse when trained on recursively generated data
Shumailov, Ilia and Shumaylov, Zakhar and Zhao, Yiren and Papernot, Nicolas and Anderson, Ross and Gal, Yarin. AI models collapse when trained on recursively generated data. Nature. doi:10.1038/s41586-024-07566-y
-
[13]
The Tatoeba Translation Challenge -- Realistic Data Sets for Low Resource and Multilingual MT
Tiedemann, J. The Tatoeba Translation Challenge -- Realistic Data Sets for Low Resource and Multilingual MT. Proceedings of the Fifth Conference on Machine Translation. 2020. doi:10.18653/v1/2020.wmt-1.139
-
[14]
Recent advances in natural language processing , volume=
News from OPUS-A collection of multilingual parallel corpora with tools and interfaces , author=. Recent advances in natural language processing , volume=
-
[15]
, author=
Parallel data, tools and interfaces in OPUS. , author=. Lrec , volume=
-
[16]
Johnson, Melvin and Schuster, Mike and Le, Quoc V. and Krikun, Maxim and Wu, Yonghui and Chen, Zhifeng and Thorat, Nikhil and Vi \'e gas, Fernanda and Wattenberg, Martin and Corrado, Greg and Hughes, Macduff and Dean, Jeffrey. G oogle ' s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation. Transactions of the Association for Co...
-
[17]
Junczys-Dowmunt, Marcin and Grundkiewicz, Roman and Dwojak, Tomasz and Hoang, Hieu and Heafield, Kenneth and Neckermann, Tom and Seide, Frank and Germann, Ulrich and Aji, Alham Fikri and Bogoychev, Nikolay and Martins, Andr \'e F. T. and Birch, Alexandra. M arian: Fast Neural Machine Translation in C ++. Proceedings of ACL 2018, System Demonstrations. 201...
-
[18]
Nemotron- CC : Transforming C ommon C rawl into a Refined Long-Horizon Pretraining Dataset
Su, Dan and Kong, Kezhi and Lin, Ying and Jennings, Joseph and Norick, Brandon and Kliegl, Markus and Patwary, Mostofa and Shoeybi, Mohammad and Catanzaro, Bryan. Nemotron- CC : Transforming C ommon C rawl into a Refined Long-Horizon Pretraining Dataset. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[19]
CoRR , volume =
Open-sci-ref-0.01: Open and Reproducible Reference Baselines for Language Model and Dataset Comparison , author =. CoRR , volume =. 2025 , doi =
2025
-
[20]
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies (
Burchell, Laurie and de Gibert, Ona and Arefyev, Nikolay and Aulamo, Mikko and Ba. An Expanded Massive Multilingual Dataset for High-Performance Language Technologies (. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , address=
2025
-
[21]
CoRR , volume=
Oepen, Stephan and Arefyev, Nikolay and Aulamo, Mikko and Ba. CoRR , volume=. 2025 , doi=
2025
-
[22]
Penedo, Guilherme and Kydl. The. Advances in Neural Information Processing Systems , volume =. 2024 , doi =
2024
-
[23]
2019 , doi =
Shoeybi, Mohammad and Patwary, Mostofa and Puri, Raul and LeGresley, Patrick and Casper, Jared and Catanzaro, Bryan , journal =. 2019 , doi =
2019
-
[24]
Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages =
Towards a Cleaner Document-Oriented Multilingual Crawled Corpus , author =. Proceedings of the Thirteenth Language Resources and Evaluation Conference , pages =. 2022 , address =
2022
-
[25]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages =
Translation Artifacts in Cross-lingual Transfer Learning , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , pages =. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.618 , url =
-
[26]
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.44 , url =
-
[27]
2024 , note =
Cosmopedia: how to create large-scale synthetic data for pre-training , author =. 2024 , note =
2024
-
[28]
Proceedings of the 17th International Conference on Spoken Language Translation , pages =
How Human is Machine Translationese? Comparing Human and Machine Translations of Text and Speech , author =. Proceedings of the 17th International Conference on Spoken Language Translation , pages =. 2020 , address =. doi:10.18653/v1/2020.iwslt-1.34 , url =
-
[29]
Proceedings of the Second Arabic Natural Language Processing Conference , month = aug, year =
Improving Language Models Trained on Translated Data with Continual Pre-Training and Dictionary Learning Analysis , author =. Proceedings of the Second Arabic Natural Language Processing Conference , month = aug, year =. doi:10.18653/v1/2024.arabicnlp-1.7 , url =
-
[30]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[31]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =
When Is Multilinguality a Curse? Language Modeling for 250 High- and Low-Resource Languages , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/2024.emnlp-main.236 , url =
-
[32]
CoRR , volume =
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks , author =. CoRR , volume =. 2025 , doi =
2025
-
[33]
and Choi, Eunsol and Collins, Michael and Garrette, Dan and Kwiatkowski, Tom and Nikolaev, Vitaly and Palomaki, Jennimaria , journal =
Clark, Jonathan H. and Choi, Eunsol and Collins, Michael and Garrette, Dan and Kwiatkowski, Tom and Nikolaev, Vitaly and Palomaki, Jennimaria , journal =. 2020 , doi =
2020
-
[34]
2023 , doi =
CoRR , volume =. 2023 , doi =
2023
-
[35]
and Schwenk, Holger and Stoyanov, Veselin , booktitle =
Conneau, Alexis and Rinott, Ruty and Lample, Guillaume and Williams, Adina and Bowman, Samuel R. and Schwenk, Holger and Stoyanov, Veselin , booktitle =. 2018 , address =. doi:10.18653/v1/D18-1269 , url =
-
[36]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , month=
Unsupervised Cross-lingual Representation Learning at Scale , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages =. 2020 , address =. doi:10.18653/v1/2020.acl-main.747 , url =
-
[37]
2024 , eprint =
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier , author =. 2024 , eprint =
2024
-
[38]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages =
A New Massive Multilingual Dataset for High-Performance Language Technologies , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages =. 2024 , address =
2024
-
[39]
de Gibert, Ona and Attieh, Joseph and Vahtola, Teemu and Aulamo, Mikko and Li, Zihao and V. Scaling Low-Resource. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.1408 , url =
-
[40]
Proceedings of the 41st International Conference on Machine Learning , year =
A Tale of Tails: Model Collapse as a Change of Scaling Laws , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[41]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Pretraining Language Models Using Translationese , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , address =. doi:10.18653/v1/2024.emnlp-main.334 , url =
-
[42]
Length-Controlled
Dubois, Yann and Galambosi, Bal. Length-Controlled. First Conference on Language Modeling , year =
-
[43]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
Understanding Back-Translation at Scale , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =. 2018 , address =. doi:10.18653/v1/D18-1045 , url =
-
[44]
CoRR , volume =
Domain, Translationese and Noise in Synthetic Data for Neural Machine Translation , author =. CoRR , volume =. 2019 , doi =
2019
-
[45]
2024 , url =
Etxaniz, Julen and Azkune, Gorka and Soroa, Aitor and Lopez de Lacalle, Oier and Artetxe, Mikel , booktitle =. 2024 , url =
2024
-
[46]
Fan, Angela and Bhosale, Shruti and Schwenk, Holger and Ma, Zhiyi and El-Kishky, Ahmed and Goyal, Siddharth and Baines, Mandeep and Celebi, Onur and Wenzek, Guillaume and Chaudhary, Vishrav and Goyal, Naman and Birch, Tom and Liptchinsky, Vitaliy and Edunov, Sergey and Auli, Michael and Joulin, Armand , journal =. Beyond. 2021 , url =
2021
-
[47]
Freitag, Markus and Grangier, David and Caswell, Isaac , booktitle =. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.5 , url =
-
[48]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , journal =. The. 2021 , doi =
2021
-
[49]
First Conference on Language Modeling , year =
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data , author =. First Conference on Language Modeling , year =
-
[50]
Proceedings of the Fourth Conference on Machine Translation , year =
Translationese in Machine Translation Evaluation , author =. Proceedings of the Fourth Conference on Machine Translation , year =
-
[51]
Statistical Power and Translationese in Machine Translation Evaluation , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , address =. doi:10.18653/v1/2020.emnlp-main.6 , url =
-
[52]
A Survey on
Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and Wang, Saizhuo and Zhang, Kun and Lin, Zhouchi and Zhang, Bowen and Ni, Lionel and Gao, Wen and Wang, Yuanzhuo and Guo, Jian , journal =. A Survey on. 2026 , doi =
2026
-
[53]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[54]
Challenges and Strategies in Cross-Cultural
Hershcovich, Daniel and Frank, Stella and Lent, Heather and de Lhoneux, Miryam and Abdou, Mostafa and Brandl, Stephanie and Bugliarello, Emanuele and Cabello Piqueras, Laura and Chalkidis, Ilias and Cui, Ruixiang and Fierro, Constanza and Margatina, Katerina and Rust, Phillip and S. Challenges and Strategies in Cross-Cultural. Proceedings of the 60th Annu...
-
[55]
2020 , publisher =
Hu, Junjie and Ruder, Sebastian and Siddhant, Aditya and Neubig, Graham and Firat, Orhan and Johnson, Melvin , booktitle =. 2020 , publisher =
2020
-
[56]
ImaniGooghari, Ayyoob and Lin, Peiqin and Kargaran, Amir Hossein and Severini, Silvia and Jalili Sabet, Masoud and Kassner, Nora and Ma, Chunlan and Schmid, Helmut and Martins, Andr. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2023 , address =. doi:10.18653/v1/2023.acl-long.61 , url =
-
[57]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year =
Can Machine Translation Bridge Multilingual Pretraining and Cross-lingual Transfer Learning? , author =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year =
2024
-
[58]
2024 , eprint =
Ji, Shaoxiong and Li, Zihao and Paul, Indraneil and Paavola, Jaakko and Lin, Peiqin and Chen, Pinzhen and O'Brien, Dayy. 2024 , eprint =
2024
-
[59]
2025 , eprint =
Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data , author =. 2025 , eprint =
2025
-
[60]
Preliminary Ranking of
Kocmi, Tom and Avramidis, Eleftherios and Bawden, Rachel and Bojar, Ond. Preliminary Ranking of. 2025 , eprint =
2025
-
[61]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =
Translationese and Its Dialects , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =. 2011 , address =
2011
-
[62]
Transactions of the Association for Computational Linguistics , volume =
Quality at a Glance: An Audit of Web-Crawled Multilingual Datasets , author =. Transactions of the Association for Computational Linguistics , volume =. 2022 , doi =
2022
-
[63]
2023 , doi =
Kudugunta, Sneha and Caswell, Isaac and Zhang, Biao and Garcia, Xavier and Xin, Derrick and Kusupati, Aditya and Stella, Romi and Bapna, Ankur and Firat, Orhan , booktitle =. 2023 , doi =
2023
-
[64]
Advances in Neural Information Processing Systems , volume =
Cross-lingual Language Model Pretraining , author =. Advances in Neural Information Processing Systems , volume =. 2019 , url =
2019
-
[65]
Lauren. The. Advances in Neural Information Processing Systems, Datasets and Benchmarks Track , year =
-
[66]
Deduplicating Training Data Makes Language Models Better , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , year =. doi:10.18653/v1/2022.acl-long.577 , url =
-
[67]
A Comparison of Language Modeling and Translation as Multilingual Pretraining Objectives , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.888 , url =
-
[68]
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir Yitzhak and Bansal, Hritik and Guha, Etash Kumar and Keh, Sedrick Scott and Arora, Kushal and Garg, Saurabh and Xin, Rui and Muennighoff, Niklas and Heckel, Reinhard and Mercat, Jean and Chen, Mayee F. and Gururangan, Suchin and Wortsman, Mitchell and Albalak...
2024
-
[69]
Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting
Li, Zihao and Ji, Shaoxiong and Luo, Hengyu and Tiedemann, J. Rethinking Multilingual Continual Pretraining: Data Mixing for Adapting. 2025 , eprint =
2025
-
[70]
Transactions of the Association for Computational Linguistics , volume =
Multilingual Denoising Pre-training for Neural Machine Translation , author =. Transactions of the Association for Computational Linguistics , volume =. 2020 , doi =
2020
-
[71]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.153 , url =
-
[72]
Liu, Chen Cecilia and Koto, Fajri and Baldwin, Timothy and Gurevych, Iryna , booktitle =. Are Multilingual. 2024 , address =. doi:10.18653/v1/2024.naacl-long.112 , url =
-
[73]
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.757 , url =
-
[74]
Having Beer after Prayer? Measuring Cultural Bias in Large Language Models , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.862 , url =
-
[75]
and Nguyen, Thien Huu
Nguyen, Thuat and Nguyen, Chien Van and Lai, Viet Dac and Man, Hieu and Ngo, Nghia Trung and Dernoncourt, Franck and Rossi, Ryan A. and Nguyen, Thien Huu. C ultura X : A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resou...
2024
-
[76]
Nature , volume =
Scaling Neural Machine Translation to 200 Languages , author =. Nature , volume =. 2024 , doi =
2024
-
[77]
2024 , howpublished =
2024
-
[78]
Computational Linguistics , volume =
Survey of Cultural Awareness in Language Models: Text and Beyond , author =. Computational Linguistics , volume =. 2025 , doi =
2025
-
[79]
Penedo, Guilherme and Malartic, Quentin and Hesslow, Daniel and Cojocaru, Ruxandra and Alobeidli, Hamza and Cappelli, Alessandro and Pannier, Baptiste and Almazrouei, Ebtesam and Launay, Julien , booktitle =. The. 2023 , url =
2023
-
[80]
CoRR , volume =
Penedo, Guilherme and Kydl. CoRR , volume =. 2025 , doi =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.