Scientific discovery as meta-optimization: a combinatorial optimization case study
Pith reviewed 2026-06-26 05:10 UTC · model grok-4.3
The pith
Treating scientific discovery as meta-optimization where evaluation criteria are also optimized improves 3-SAT algorithm discovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
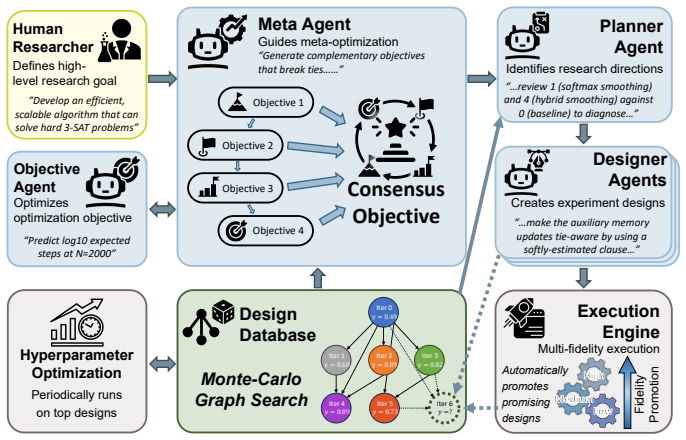
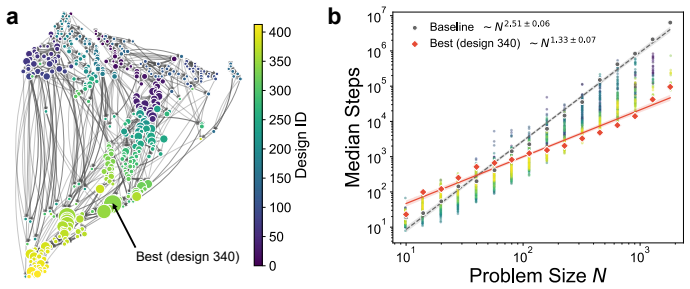
By formalizing research as meta-optimization, the paper shows that consensus objective aggregation, in which LLM-generated objective functions are combined via correlation-weighted voting, yields a stable, self-correcting evaluation criterion that evolves as understanding deepens. Applied to algorithm discovery for 3-SAT problems based on digital MemComputing machines, this reduces the baseline scaling with problem size N from ~N^{2.51} to ~N^{1.33} and delivers a ~67× speedup on the largest instances tested.
What carries the argument
Consensus objective aggregation, the mechanism that combines LLM-generated objective functions via correlation-weighted voting to create an evolving and stable evaluation criterion.
If this is right
- The time to solve larger 3-SAT instances scales much more slowly with problem size.
- The evaluation criterion becomes self-correcting and changes as new objectives are added.
- The same aggregation procedure can be used for discovery tasks outside 3-SAT because the framework is problem-agnostic.
- Simultaneous adjustment of the objective alongside the search space leads to concrete performance gains in algorithm quality.
Where Pith is reading between the lines
- The approach could be tested by generating objectives from several different large language models to check whether model-specific biases are reduced by the voting step.
- Similar scaling gains might appear if the method is tried on other combinatorial problems such as graph coloring or traveling salesman instances.
- Over repeated rounds the aggregated objective might converge toward a measure that better matches human notions of solution quality without explicit human input.
Load-bearing premise
LLM-generated objective functions can be combined via correlation-weighted voting to produce a meaningfully improved and stable evaluation criterion without the aggregation step itself introducing bias or circular dependence.
What would settle it
Applying the same discovery process to a fresh collection of larger 3-SAT instances and finding that the aggregated objective produces no better or worse scaling than a fixed single objective would falsify the central claim.
Figures
read the original abstract
Scientific discovery is fundamentally an optimization problem, defined by a vast "state space" of theories and experiments, and an evaluation criterion based on quality, novelty, and validity. Large language models (LLMs) have enabled automated exploration of this space, but we argue that simultaneous modification of the evaluation criteria is equally important. Here, we propose formalizing research as meta-optimization, where the optimization objective itself is also being optimized. Our key contribution is "consensus objective aggregation," where LLM-generated objective functions are combined via correlation-weighted voting, yielding a stable, self-correcting evaluation criterion that evolves as understanding deepens. We apply this framework to algorithm discovery for 3-SAT problems based on digital MemComputing machines, reducing the baseline scaling with problem size $N$ from $\sim N^{2.51}$ to $\sim N^{1.33}$ and delivering a $\sim 67\times$ speedup on the largest instances tested. As a problem-agnostic framework, we hope this approach will considerably aid scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper frames scientific discovery as a meta-optimization problem in which the evaluation criterion itself is optimized. Its central contribution is 'consensus objective aggregation,' in which multiple LLM-generated objective functions are combined via correlation-weighted voting to produce a stable, self-correcting criterion. Applied to the discovery of algorithms for 3-SAT instances using digital MemComputing machines, the method is reported to improve scaling from ~N^{2.51} to ~N^{1.33} and to deliver a ~67× speedup on the largest instances tested.
Significance. If the attribution of the scaling improvement and speedup to the aggregation mechanism can be rigorously established, the work would offer a concrete, problem-agnostic framework for automated scientific discovery that could be tested in other combinatorial domains. The reported numerical gains are large enough to be noteworthy if they survive ablation and external validation.
major comments (2)
- [Experimental results / 3-SAT case study] The experimental comparison (presumably in the results section) pits the full meta-optimization pipeline only against a baseline MemComputing solver and does not report an ablation that isolates consensus objective aggregation (single-LLM objective versus aggregated objective on identical instance sets). Without this isolation, the observed drop from N^{2.51} to N^{1.33} cannot be confidently ascribed to the proposed mechanism rather than to other uncontrolled factors in the search or solver implementation.
- [Consensus objective aggregation method] The correlation-weighted voting step (described in the methods) risks circular dependence: if the LLMs share training corpora or inductive biases, high pairwise correlation may simply reinforce common errors rather than converge on a more accurate criterion. No held-out model family, human-expert baseline, or external validation of the aggregated objective is described to rule out this closed-loop bias.
minor comments (2)
- [Abstract] The abstract states concrete performance numbers (scaling exponents, 67× speedup) but supplies no methods, data, error bars, or verification steps; these details should be summarized even in the abstract.
- [Methods] Notation for the correlation-weighted voting formula and the precise definition of the aggregated objective should be made fully explicit with an equation number so that the aggregation step can be reproduced independently.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional evidence would strengthen the claims. We respond to each major comment below and indicate the revisions planned.
read point-by-point responses
-
Referee: [Experimental results / 3-SAT case study] The experimental comparison (presumably in the results section) pits the full meta-optimization pipeline only against a baseline MemComputing solver and does not report an ablation that isolates consensus objective aggregation (single-LLM objective versus aggregated objective on identical instance sets). Without this isolation, the observed drop from N^{2.51} to N^{1.33} cannot be confidently ascribed to the proposed mechanism rather than to other uncontrolled factors in the search or solver implementation.
Authors: We agree that the current experiments do not isolate the contribution of consensus objective aggregation. The reported scaling and speedup compare the full pipeline against the baseline solver, leaving open the possibility that other factors contribute. In the revised manuscript we will add an ablation study that applies the discovery process using single-LLM objectives versus the aggregated objective on identical 3-SAT instance sets, allowing direct attribution of any improvement to the aggregation step. revision: yes
-
Referee: [Consensus objective aggregation method] The correlation-weighted voting step (described in the methods) risks circular dependence: if the LLMs share training corpora or inductive biases, high pairwise correlation may simply reinforce common errors rather than converge on a more accurate criterion. No held-out model family, human-expert baseline, or external validation of the aggregated objective is described to rule out this closed-loop bias.
Authors: The risk of reinforcing shared biases is a substantive methodological concern. While the original experiments drew from multiple LLM providers, no held-out model or external validation was performed. The revision will include an explicit discussion of this limitation in the methods and results sections together with new experiments that incorporate at least one additional held-out model family to provide a partial check against closed-loop bias. A full human-expert baseline comparison lies outside the scope of the current study. revision: partial
Circularity Check
No circularity; derivation is self-contained empirical application of proposed method.
full rationale
The paper defines consensus objective aggregation as a new procedure (LLM-generated objectives combined by correlation-weighted voting) and reports its empirical effect on 3-SAT scaling as an outcome of applying that procedure. No equations, self-citations, or fitted parameters are shown reducing the reported scaling improvement (N^2.51 to N^1.33) or the aggregation step itself back to the inputs by construction. The central claim therefore remains an independent experimental result rather than a definitional or self-referential identity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Di Ventra.The Scientific Method: Reflections from a Practitioner
M. Di Ventra.The Scientific Method: Reflections from a Practitioner. Oxford University Press, Oxford, 2018
2018
-
[2]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv preprint arXiv:2408.06292, September 2024
Pith/arXiv arXiv 2024
-
[3]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search. arXiv preprint arXiv:2504.08066, April 2025
Pith/arXiv arXiv 2025
-
[4]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
Pith/arXiv arXiv 2025
-
[5]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, December 2023. ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-023-06792-0
-
[6]
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C. Landsness, Daniel L. Barabasi, Siddharth Narayanan, Nicky Evans, Shriya Reddy, Martha Foiani, Aizad Kamal, Leah P. Shriver, Fang Cao, Asmamaw T. Wassie, Jon M. Laurent, Edwin Melville-Green, Mayk Caldas, Albert Bou, Kaleigh F. Roberts, Sladjana Zagora...
Pith/arXiv arXiv 2025
-
[7]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, January 2024. ISSN 1476-4687. doi: ...
-
[8]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for scientific and algor...
Pith/arXiv arXiv 2025
-
[9]
Autonomous Code Evolution Meets NP-Completeness
Cunxi Yu, Rongjian Liang, Chia-Tung Ho, and Haoxing Ren. Autonomous Code Evolution Meets NP-Completeness. arXiv preprint arXiv:2509.07367, September 2025
arXiv 2025
-
[10]
Nature624(7990), 80–85 (2023) https://doi.org/10.1038/s41586-023-06735-9
Amil Merchant, Simon Batzner, Samuel S. Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk. Scaling deep learning for materials discovery.Nature, 624(7990):80–85, December 2023. ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-023-06735-9
-
[11]
Fiona Y . Wang, Di Sheng Lee, David L. Kaplan, and Markus J. Buehler. Swarms of Large Language Model Agents for Protein Sequence Design with Experimental Validation. arXiv preprint arXiv:2511.22311, November 2025
arXiv 2025
-
[12]
PhysAgent: A Multi-Agent Approach to the Automated Discovery of Physical Laws
Xiao-Qi Han, Ze-Feng Gao, Peng-Jie Guo, and Zhong-Yi Lu. PhysAgent: A Multi-Agent Approach to the Automated Discovery of Physical Laws. Qeios, August 2025
2025
-
[13]
Monte Carlo Tree Search for Comprehensive Exploration in LLM-Based Automatic Heuristic Design
Zhi Zheng, Zhuoliang Xie, Zhenkun Wang, and Bryan Hooi. Monte Carlo Tree Search for Comprehensive Exploration in LLM-Based Automatic Heuristic Design. arXiv preprint arXiv:2501.08603, January 2025. 10
arXiv 2025
-
[14]
Hui Wang, Xufeng Zhang, and Chaoxu Mu. Planning of Heuristics: Strategic Planning on Large Language Models with Monte Carlo Tree Search for Automating Heuristic Optimization. arXiv preprint arXiv:2502.11422, June 2025
arXiv 2025
-
[15]
He Wang and Liang Zeng. Automated Algorithmic Discovery for Scientific Computing through LLM-Guided Evolutionary Search: A Case Study in Gravitational-Wave Detection. arXiv preprint arXiv:2508.03661, November 2025
arXiv 2025
-
[16]
Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B. arXiv preprint arXiv:2406.07394, June 2024
arXiv 2024
-
[17]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv preprint arXiv:2305.10601, December 2023
Pith/arXiv arXiv 2023
-
[18]
From AI for Science to Agentic Science: A Survey on Autonomous Scientific Discovery
Jiaqi Wei, Yuejin Yang, Xiang Zhang, Yuhan Chen, Xiang Zhuang, Zhangyang Gao, Dongzhan Zhou, Guangshuai Wang, Zhiqiang Gao, Juntai Cao, Zijie Qiu, Ming Hu, Chenglong Ma, Shixiang Tang, Junjun He, Chunfeng Song, Xuming He, Qiang Zhang, Chenyu You, Shuangjia Zheng, Ning Ding, Wanli Ouyang, Nanqing Dong, Yu Cheng, Siqi Sun, Lei Bai, and Bowen Zhou. From AI f...
arXiv 2025
-
[19]
From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. From Automation to Autonomy: A Survey on Large Language Models in Scientific Discovery. arXiv preprint arXiv:2505.13259, September 2025
arXiv 2025
-
[20]
LLM4SR: A Survey on Large Language Models for Scientific Research
Ziming Luo, Zonglin Yang, Zexin Xu, Wei Yang, and Xinya Du. LLM4SR: A Survey on Large Language Models for Scientific Research. arXiv preprint arXiv:2501.04306, January 2025
arXiv 2025
-
[21]
Steffen Eger, Yong Cao, Jennifer D’Souza, Andreas Geiger, Christian Greisinger, Stephanie Gross, Yufang Hou, Brigitte Krenn, Anne Lauscher, Yizhi Li, Chenghua Lin, Nafise Sadat Moosavi, Wei Zhao, and Tristan Miller. Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evalu...
arXiv 2025
-
[22]
C. A. E. Goodhart. Problems of Monetary Management: The UK Experience. In C. A. E. Goodhart, editor,Monetary Theory and Practice: The UK Experience, pages 91–121. Macmillan Education UK, London, 1984. ISBN 978-1-349-17295-5. doi: 10.1007/978-1-349-17295-5_4
-
[23]
Defining and Characterizing Reward Gaming.Advances in Neural Information Processing Systems, 35: 9460–9471, December 2022
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and Characterizing Reward Gaming.Advances in Neural Information Processing Systems, 35: 9460–9471, December 2022
2022
-
[24]
The End of Reward Engineering: How LLMs Are Redefining Multi-Agent Coordination
Haoran Su, Yandong Sun, and Congjia Yu. The End of Reward Engineering: How LLMs Are Redefining Multi-Agent Coordination. arXiv preprint arXiv:2601.08237, January 2026
arXiv 2026
-
[25]
Yuanqi Du, Botao Yu, Tianyu Liu, Tony Shen, Junwu Chen, Jan G. Rittig, Kunyang Sun, Yikun Zhang, Zhangde Song, Bo Zhou, Cassandra Masschelein, Yingze Wang, Haorui Wang, Haojun Jia, Chao Zhang, Hongyu Zhao, Martin Ester, Teresa Head-Gordon, Carla P. Gomes, Huan Sun, Chenru Duan, Philippe Schwaller, and Wengong Jin. Accelerating Scientific Discovery with Au...
arXiv 2025
-
[26]
Renzhi Lu, Zonghe Shao, Yuemin Ding, Ruijuan Chen, Dongrui Wu, Housheng Su, Tao Yang, Fumin Zhang, Jun Wang, Yang Shi, Zhong-Ping Jiang, Han Ding, and Hai-Tao Zhang. Discovery of the reward function for embodied reinforcement learning agents.Nature Communications, 16(1):11064, December 2025. ISSN 2041-1723. doi: 10.1038/s41467-025-66009-y
-
[27]
M. G. Kendall. A New Measure of Rank Correlation.Biometrika, 30(1-2):81–93, June 1938. ISSN 0006-3444. doi: 10.1093/biomet/30.1-2.81
-
[28]
doi: 10.1007/s00355-011-0603-9
Peter Emerson. The original Borda count and partial voting.Social Choice and Welfare, 40(2): 353–358, February 2013. ISSN 1432-217X. doi: 10.1007/s00355-011-0603-9. 11
-
[29]
W. Barthel, A. K. Hartmann, M. Leone, F. Ricci-Tersenghi, M. Weigt, and R. Zecchina. Hiding Solutions in Random Satisfiability Problems: A Statistical Mechanics Approach.Physical Review Letters, 88(18):188701, April 2002. doi: 10.1103/PhysRevLett.88.188701
-
[30]
Massimiliano Di Ventra.MemComputing: Fundamentals and Applications. Oxford University Press, February 2022. ISBN 978-0-19-284532-0. doi: 10.1093/oso/9780192845320.001.0001
-
[31]
Traversa and Massimiliano Di Ventra
Fabio L. Traversa and Massimiliano Di Ventra. Polynomial-time solution of prime factorization and NP-complete problems with digital memcomputing machines.Chaos: An Interdisciplinary Journal of Nonlinear Science, 27(2):023107, February 2017. ISSN 1054-1500, 1089-7682. doi: 10.1063/1.4975761
-
[32]
Sean R. B. Bearden, Yan Ru Pei, and Massimiliano Di Ventra. Efficient solution of Boolean satisfiability problems with digital memcomputing.Scientific Reports, 10(1):19741, November
-
[33]
doi: 10.1038/s41598-020-76666-2
ISSN 2045-2322. doi: 10.1038/s41598-020-76666-2
-
[34]
Chesson Sipling, Yuan-Hang Zhang, and Massimiliano Di Ventra. Phase-space engineering and collective dynamics in memcomputing.Physical Review Applied, 25(1):014048, January 2026. doi: 10.1103/f8tv-jv1b
-
[35]
Survey of Multifidelity Methods in Uncertainty Propagation, Inference, and Optimization.SIAM Review, 60(3):550–591, January
Benjamin Peherstorfer, Karen Willcox, and Max Gunzburger. Survey of Multifidelity Methods in Uncertainty Propagation, Inference, and Optimization.SIAM Review, 60(3):550–591, January
-
[36]
Survey of multifidelity methods in uncertainty propagation, inference, and optimization,
ISSN 0036-1445, 1095-7200. doi: 10.1137/16M1082469
-
[37]
Hebo: Pushing the limits of sample-efficient hyperparameter optimisation.Journal of Artificial Intelligence Research, 74, 07 2022
Alexander Cowen-Rivers, Wenlong Lyu, Rasul Tutunov, Zhi Wang, Antoine Grosnit, Ryan-Rhys Griffiths, Alexandre Maravel, Jianye Hao, Jun Wang, Jan Peters, and Haitham Bou Ammar. Hebo: Pushing the limits of sample-efficient hyperparameter optimisation.Journal of Artificial Intelligence Research, 74, 07 2022
2022
-
[38]
The Exploration-Exploitation Dilemma: A Multidisciplinary Framework.PLOS ONE, 9(4):e95693, April 2014
Oded Berger-Tal, Jonathan Nathan, Ehud Meron, and David Saltz. The Exploration-Exploitation Dilemma: A Multidisciplinary Framework.PLOS ONE, 9(4):e95693, April 2014. ISSN 1932-
2014
-
[39]
doi: 10.1371/journal.pone.0095693
-
[40]
Machine Learning 47(2):235--256, ISSN 1573-0565, ://dx.doi.org/10.1023/A:1013689704352
Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. Finite-time Analysis of the Multiarmed Bandit Problem.Machine Learning, 47(2):235–256, May 2002. ISSN 1573-0565. doi: 10.1023/A:1013689704352
-
[41]
Johannes Czech, Patrick Korus, and Kristian Kersting. Improving AlphaZero Using Monte- Carlo Graph Search.Proceedings of the International Conference on Automated Planning and Scheduling, 31:103–111, May 2021. ISSN 2334-0843, 2334-0835. doi: 10.1609/icaps.v31i1. 15952
-
[42]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Master- ing the...
-
[43]
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George Van Den Driessche, Thore Graepel, and Demis Hassabis. Mastering the game of Go without human knowledge.Nature, 550(7676):354–359, October 2017...
-
[44]
Hartmann and Heiko Rieger, editors.New Optimization Algorithms in Physics
Alexander K. Hartmann and Heiko Rieger, editors.New Optimization Algorithms in Physics. Wiley-VCH ; John Wiley, Weinheim : Chichester, 2004. ISBN 978-3-527-40406-3
2004
-
[45]
Scientific discovery as meta-optimization: a combinatorial optimization case study
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Perfo...
2019
-
[46]
Long-term memory gate(Fig. S1(a)). A sigmoid in log-space that switches on only for clauses carrying a large long-term memory: gatexl =σ lnx l,m −lnx l,thr ωl ,(S3) with xl,thr = 1000.4 and ωl = 2.03. The release mechanism therefore acts only on persistently violated clauses
-
[47]
Weak-satisfaction band(Fig. S1(b)). Two opposing sigmoids select clauses in a narrow satisfac- tion window: weak_band =σ cm −η ωb ·σ γ−c m ωb ,(S4) where η= 0.336 , γ= 0.282 , and ωb = 0.063. Notably, the optimized values satisfy η > γ , yielding a very narrow, low-amplitude response (peak ≈0.16 ). The band targets clauses hovering near the satisfaction b...
-
[48]
Bounded upward push(Fig. S1(c)). A ReLU gate that drivesx s,m toward a target value: push_up = max(x∗ s −x s,m,0) x∗s ,(S5) with x∗ s = 0.091. This is perhaps the most surprising parameter choice: the target sits near the lower bound of xs, so the push shuts off almost as soon as xs rises above ∼0.09 . Together with the narrow weak-band, it makes the rele...
-
[49]
Tail-safety gate(Fig. S1(d)). A sigmoid that damps release when xs,m approaches its upper bound: gatetail =σ xs,tail −x s,m +µ tail ·gate xl ωtail ,(S6) with xs,tail = 0.531 , µtail = 0.424 , and ωtail = 0.107 . The xl-dependent shift ( µtail ·gate xl) widens the safe operating range for high-penalty clauses, giving them more headroom before the safety cu...
-
[50]
Amplitude normalization(Fig. S1(e)). A power-law decay with a clause-state-driven floor: amppow = xl,norm xl,norm +x l,m p ,(S7) floor_gate = 1−(1−weak_band)(1−push_up),(S8) amp_norm = (1−f) amp pow +f, f=a floor ·floor_gate,(S9) where xl,norm = 10,087, p= 1.75 , and afloor = 0.0093. The power-law decay (Eq. (S7)) regulates the release term as xl,m increa...
-
[51]
The clause has been persistently violated (x l,m ≫x l,thr, viagate xl)
-
[52]
The clause sits in a critical satisfaction state (c m ≈0.3, viaweak_band)
-
[53]
The short-term memory is below target (x s,m < x ∗ s, viapush_up)
-
[54]
The short-term memory is not saturated (x s,m below safety threshold, viagate tail)
-
[55]
The release amplitude is properly regulated (viaamp_norm). The conjunction channels effort toward persistently stuck clauses that are close to flipping and need a gentle push, rather than clauses that are far from satisfaction or would resolve on their own through the baseline dynamics. Conservative parameter regime.The HEBO-optimized [ 35] hyperparameter...
2000
-
[56]
Strict binary pass/fail.Success means unsolved_fraction<0.5 ; a value of 0.49 is never penalized
-
[57]
This blocks designs from inflating headroom by running with inflated budgets
Schedule-faithful headroom.Budget headroom is computed from theschedule budget B(N) (a deterministic function of N and the fidelity cap), not from the run’s max_steps. This blocks designs from inflating headroom by running with inflated budgets
-
[58]
designs reach N= 640 under the adaptive schedule, but this is largely driven by hovering just below the unsolved_fraction< 0.5 gate while median_step explodes at higher N
Smooth-max bottleneck detection.Rather than sampling headroom at a single point, the objective takes a smooth-max (log-sum-exp) of log(median_step/B(N)) over the last 3 cleared levels plus conservative worst-window predictions at N= 1810 and N= 2560 . The worst bottleneck is identified without being dominated by a single noisy data point. Further componen...
-
[59]
A design that appears to improve may simply have been tested on an easier schedule, making consensus rankings unreliable
Inconsistent evaluation.When the schedule shifts between iterations, scores from different iterations are not directly comparable. A design that appears to improve may simply have been tested on an easier schedule, making consensus rankings unreliable
-
[60]
Schedule echo chamber.The LLM agent, aware of the current top designs and existing schedules, tended to propose schedules favoring those same designs, which is self-reinforcing bias analogous to the objective echo chamber (Sec. S2.2)
-
[61]
push” (xs ≈1 ) and “hold
No quality criterion.Unlike solver designs, which can be ranked by objective performance, there is no obvious ground truth for schedule quality. The system had no reliable signal for judging whether a new schedule was more informative than its predecessor. We resolved these issues by fixing the evaluation schedule and pairing it with rule-based multi-fide...
-
[62]
Make ONE small, principled modification to baseline
-
[63]
Build on proven ideas from reference experiments
-
[64]
Follow the Planner’s direction and rationale
-
[65]
explanation
Explain how changes should improve the objective ## Required Components {component_descriptions} Available imports: ‘math‘, ‘numpy‘, ‘scipy‘, ‘torch‘, and standard libraries ## Output Format Return a JSON object with: ‘‘‘json { "explanation": "Rationale for modification, referencing evidence and strategy", 29 "solver_code": "Complete Python code with impo...
-
[66]
Assess research progress
-
[67]
- You can adjust objective weights: amplify useful ones, suppress harmful ones
**Maintain and update an evolving consensus objective function** - Objective functions are periodically generated by Objective Agent - Planner/Designer Agents/hyperparameter optimizer minimize the consensus objective. - You can adjust objective weights: amplify useful ones, suppress harmful ones
-
[68]
research_assessment
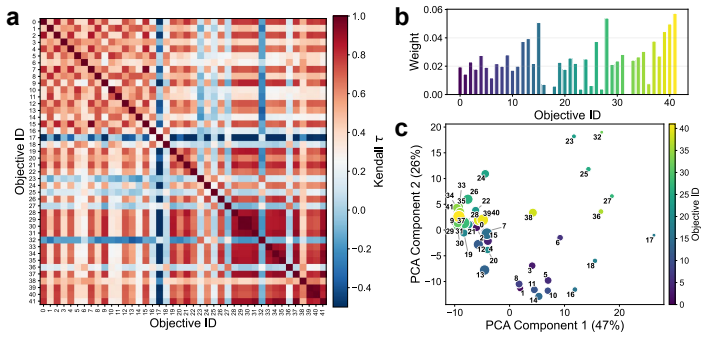
Guide the Objective Agent in generating new objectives. ## Experiment Schedule (for reference - will be used unchanged): 33 ‘‘‘python {baseline_schedule_code} ‘‘‘ ## Current Objective Functions {objective_summary_with_code} ## Objective Performance Analysis **Kendall Tau Correlation Matrix** (measures agreement between objectives): {objective_correlation_...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.