Generative Criticality in Large Language Model Temperature Scaling
Pith reviewed 2026-06-28 02:36 UTC · model grok-4.3
The pith
Treating LLM token embeddings as spins on a chain reveals a critical temperature Tc marked by a susceptibility peak and output collapse to one direction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
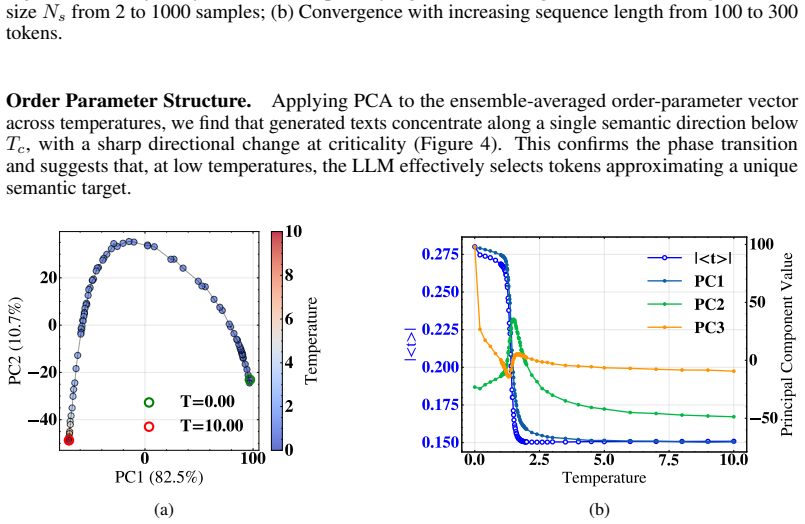
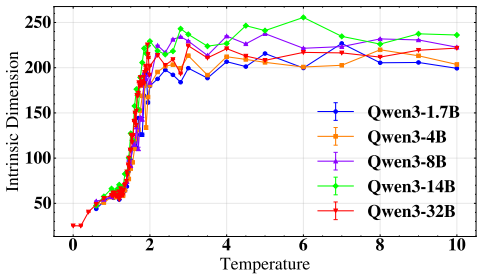
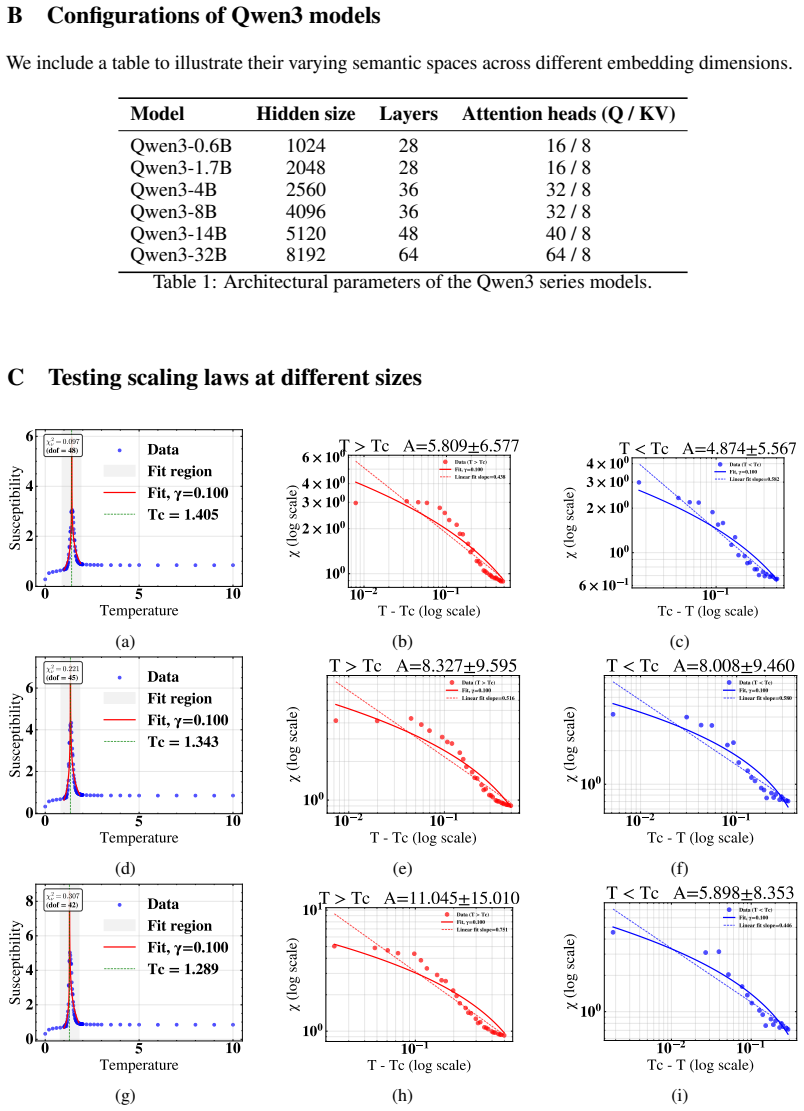
Defining a susceptibility from the connected two-point correlator and an order parameter from the ensemble-averaged embedding field, we vary the softmax temperature T and observe a sharp susceptibility peak near a characteristic Tc with power-law-like scaling, a concurrent rapid change in the order parameter, and a collapse onto a single semantic direction below Tc. The intrinsic dimension estimated by the two nearest neighbor (TwoNN) method independently corroborates these findings, reaching a minimum near Tc. Results are robust across model scales (Qwen3: 0.6B--32B) and prompt categories. While the phenomenology closely resembles a continuous phase transition, the non-equilibrium nature of
What carries the argument
Susceptibility constructed from the connected two-point correlator of token embeddings treated as continuous spin variables on a one-dimensional chain.
If this is right
- Below Tc the generated embeddings collapse onto a single semantic direction.
- The intrinsic dimension of the output distribution reaches a minimum near Tc.
- The observed scaling of susceptibility near Tc is consistent with power-law behavior.
- The same signatures appear across model scales from 0.6B to 32B parameters.
- The framework supplies quantitative observables for the collective structure of LLM outputs.
Where Pith is reading between the lines
- An operating temperature near Tc could balance coherence and diversity in generation without external tuning.
- The same correlator-based observables might be applied to other sampling methods such as nucleus sampling.
- The noted non-equilibrium character implies the transition may be a dynamical crossover rather than a true thermodynamic phase transition.
- Prompt engineering could shift the location of Tc by altering the effective interaction range along the token chain.
Load-bearing premise
Token embeddings generated by autoregressive sampling can be treated as continuous spin variables on a one-dimensional chain so that equilibrium statistical-mechanics quantities remain meaningful descriptors of the output distribution.
What would settle it
Repeating the full measurement protocol on a new family of models or with non-autoregressive sampling and finding no susceptibility peak at any temperature.
Figures
read the original abstract
We propose a statistical-field framework for text generated by large language models (LLMs), treating token embeddings as continuous spin variables on a one-dimensional chain. Defining a susceptibility from the connected two-point correlator and an order parameter from the ensemble-averaged embedding field, we vary the \texttt{softmax} temperature $T$ and observe a sharp susceptibility peak near a characteristic $T_c$ with power-law-like scaling, a concurrent rapid change in the order parameter, and a collapse onto a single semantic direction below $T_c$. The intrinsic dimension estimated by the two nearest neighbor (TwoNN) method independently corroborates these findings, reaching a minimum near $T_c$. Results are robust across model scales (Qwen3: 0.6B--32B) and prompt categories. While the phenomenology closely resembles a continuous phase transition, the non-equilibrium nature of autoregressive generation warrants further investigation. Our framework provides quantitative tools for probing the collective statistical structure of LLM outputs and suggests connections between decoding strategies and critical phenomena.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
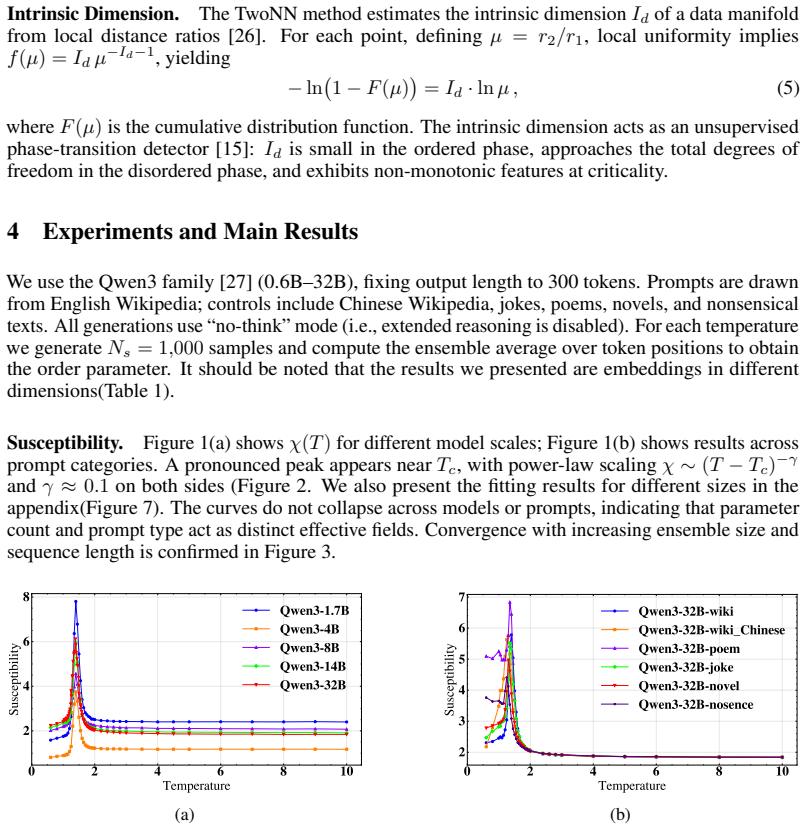
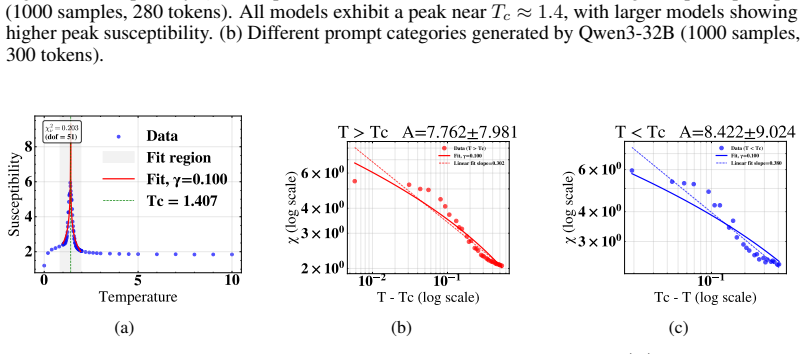
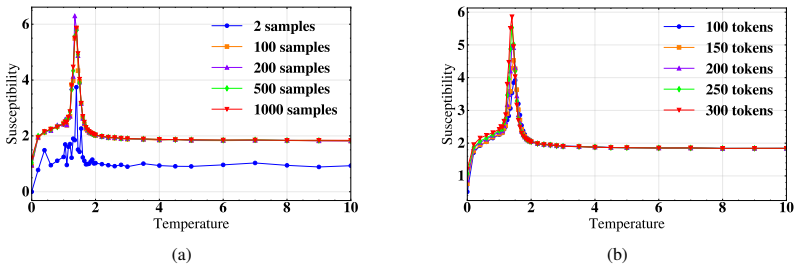
Summary. The manuscript proposes a statistical-field framework treating LLM token embeddings as continuous spins on a 1D chain. Susceptibility is defined from the connected two-point correlator and an order parameter from the ensemble-averaged embedding field; varying softmax temperature T yields a sharp susceptibility peak near a characteristic Tc with power-law-like scaling, a concurrent rapid change in the order parameter, semantic collapse below Tc, and a minimum in TwoNN intrinsic dimension near Tc. These features are reported as robust across Qwen3 model scales (0.6B–32B) and prompt categories, with the non-equilibrium character of autoregressive generation noted as requiring further study.
Significance. If the equilibrium interpretation can be substantiated, the work supplies quantitative, reproducible diagnostics (connected correlator, order parameter, TwoNN dimension) that link decoding temperature to collective phenomena and could inform temperature selection. The cross-scale robustness and independent corroboration by intrinsic dimension are concrete strengths. The central claim, however, rests on the applicability of equilibrium statistical mechanics to autoregressive output distributions.
major comments (2)
- [Abstract; §3 (framework definition)] The mapping of autoregressive token sequences to an equilibrium 1D Ising-like chain is assumed without demonstration that the joint distribution over embeddings satisfies fluctuation-dissipation or cluster properties required for the connected correlator to be interpreted as a susceptibility. This assumption is load-bearing for the claim that the observed peak constitutes criticality rather than a sequential-conditioning artifact (see skeptic concern and abstract caveat on non-equilibrium nature).
- [§4 (results and figures)] No information is supplied on how the connected two-point correlator is estimated from finite samples, whether bootstrap or jackknife error bars are computed, or what statistical test establishes the power-law scaling and the location of Tc. This directly affects the soundness of the peak and scaling claims.
minor comments (2)
- [§3] Clarify the precise centering and normalization used for the embedding field when defining the order parameter.
- [§4] Add a brief methods paragraph on the TwoNN implementation and its sensitivity to sample size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, clarifying the phenomenological scope of the framework while committing to added methodological detail.
read point-by-point responses
-
Referee: [Abstract; §3 (framework definition)] The mapping of autoregressive token sequences to an equilibrium 1D Ising-like chain is assumed without demonstration that the joint distribution over embeddings satisfies fluctuation-dissipation or cluster properties required for the connected correlator to be interpreted as a susceptibility. This assumption is load-bearing for the claim that the observed peak constitutes criticality rather than a sequential-conditioning artifact (see skeptic concern and abstract caveat on non-equilibrium nature).
Authors: We agree the equilibrium mapping is an analogy rather than a derived result. The abstract already states that 'the non-equilibrium nature of autoregressive generation warrants further investigation' and presents the features as phenomenological resemblance to criticality. The connected correlator is employed as a diagnostic of collective structure in the generated sequences. We will revise §3 to state more explicitly that fluctuation-dissipation relations are not demonstrated and that the peak may partly reflect sequential conditioning; the framework is offered as a practical tool rather than a claim of thermodynamic equilibrium. revision: partial
-
Referee: [§4 (results and figures)] No information is supplied on how the connected two-point correlator is estimated from finite samples, whether bootstrap or jackknife error bars are computed, or what statistical test establishes the power-law scaling and the location of Tc. This directly affects the soundness of the peak and scaling claims.
Authors: We accept that these procedural details are missing. In the revised manuscript we will add a dedicated paragraph in §4 describing: (i) the ensemble construction (multiple independent generations per prompt), (ii) the explicit estimator for the connected two-point correlator, (iii) bootstrap resampling for error bars on susceptibility and order-parameter curves, and (iv) the fitting protocol used to locate Tc and assess power-law scaling. revision: yes
Circularity Check
No circularity: direct measurement of defined observables under temperature variation
full rationale
The paper defines susceptibility via the connected two-point correlator of embedding vectors and an order parameter via the ensemble-averaged field, then directly computes these quantities while varying the softmax temperature T on sampled outputs. The reported peak near Tc, power-law-like scaling, order-parameter jump, and TwoNN dimension minimum are all empirical observations from this procedure, not quantities fitted to data and re-labeled as predictions. No self-citations, ansatzes, or uniqueness theorems are invoked to justify the central claims; the framework is applied to generated sequences without reducing the target phenomenology to its own inputs by construction. The non-equilibrium caveat is explicitly noted, confirming the analysis remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token embeddings can be treated as continuous spin variables on a one-dimensional chain
Reference graph
Works this paper leans on
-
[1]
Penguin uK, 2003
Steven Pinker.The language instinct: How the mind creates language. Penguin uK, 2003
2003
-
[2]
Walter de Gruyter, 2002
Noam Chomsky.Syntactic structures. Walter de Gruyter, 2002
2002
-
[3]
The debate over understanding in ai’s large language models.Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023
Melanie Mitchell and David C Krakauer. The debate over understanding in ai’s large language models.Proceedings of the National Academy of Sciences, 120(13):e2215907120, 2023
2023
-
[4]
Colin Scheibner, Lindsay M. Smith, and William Bialek. Large language models and the entropy of english.ArXiv, abs/2512.24969, 2025
-
[5]
Entropy rate estimates for natural language—a new extrapolation of compressed large-scale corpora.Entropy, 18(10):364, 2016
Ryosuke Takahira, Kumiko Tanaka-Ishii, and Łukasz D˛ ebowski. Entropy rate estimates for natural language—a new extrapolation of compressed large-scale corpora.Entropy, 18(10):364, 2016
2016
-
[6]
Mutual information functions of natural language texts
Wentian Li. Mutual information functions of natural language texts. Santa Fe Institute Santa Fe, NM, USA, 1989
1989
-
[7]
Phase transition in large language models and the criticality of natural languages
Kai Nakaishi, Yoshihiko Nishikawa, and Koji Hukushima. Critical phase transition in large language models.arXiv preprint arXiv:2406.05335, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Phase transitions in large language models and the o(n) model.arXiv preprint arXiv:2501.16241, 2025
Youran Sun and Babak Haghighat. Phase transitions in large language models and the o(n) model.arXiv preprint arXiv:2501.16241, 2025
-
[9]
Machine learning and the physical sciences
Giuseppe Carleo, Ignacio Cirac, Kyle Cranmer, Laurent Daudet, Maria Schuld, Naftali Tishby, Leslie V ogt-Maranto, and Lenka Zdeborová. Machine learning and the physical sciences. Reviews of Modern Physics, 91(4):045002, 2019
2019
-
[10]
World Scientific, 2005
Daniel J Amit and Victor Martin-Mayor.Field theory, the renormalization group, and critical phenomena: graphs to computers. World Scientific, 2005. 5
2005
-
[11]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[12]
Hot or cold? adaptive temperature sampling for code generation with large language models
Yuqi Zhu, Jia Li, Ge Li, YunFei Zhao, Zhi Jin, and Hong Mei. Hot or cold? adaptive temperature sampling for code generation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 437–445, 2024
2024
-
[13]
Critical behavior in physics and probabilistic formal languages
Henry W Lin and Max Tegmark. Critical behavior in physics and probabilistic formal languages. Entropy, 19(7):299, 2017
2017
-
[14]
Cheng-Shang Chang. A simple explanation for the phase transition in large language models with list decoding.arXiv preprint arXiv:2303.13112, 2023
-
[15]
Mendes-Santos, X
T. Mendes-Santos, X. Turkeshi, M. Dalmonte, and Alex Rodriguez. Unsupervised learning universal critical behavior via the intrinsic dimension.Physical Review X, 11(1), February 2021
2021
-
[16]
Measuring the Intrinsic Dimension of Objective Landscapes
Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes.arXiv preprint arXiv:1804.08838, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Springer Nature, 2023
Christopher M Bishop and Hugh Bishop.Deep learning: Foundations and concepts. Springer Nature, 2023
2023
-
[18]
Zhen Yang, Yingxue Zhang, Fandong Meng, and Jie Zhou. Teal: Tokenize and embed all for multi-modal large language models.arXiv preprint arXiv:2311.04589, 2023
-
[19]
Semantic tokenizer for enhanced natural language processing.arXiv preprint arXiv:2304.12404, 2023
Sandeep Mehta, Darpan Shah, Ravindra Kulkarni, and Cornelia Caragea. Semantic tokenizer for enhanced natural language processing.arXiv preprint arXiv:2304.12404, 2023
-
[20]
Text representations and word embeddings: Vectorizing textual data
Roman Egger. Text representations and word embeddings: Vectorizing textual data. InApplied data science in tourism: Interdisciplinary approaches, methodologies, and applications, pages 335–361. Springer, 2022
2022
-
[21]
Spontaneous symmetry breaking in the o (n) model for large n.Physical Review D, 10(8):2491, 1974
Sidney Coleman, Roman Jackiw, and HDavid Politzer. Spontaneous symmetry breaking in the o (n) model for large n.Physical Review D, 10(8):2491, 1974
1974
-
[22]
Exact solution of the o (n) model on a random lattice.Nuclear Physics B, 455(3):577–618, 1995
Bertrand Eynard and Charlotte Kristjansen. Exact solution of the o (n) model on a random lattice.Nuclear Physics B, 455(3):577–618, 1995
1995
-
[23]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[24]
Spin-spin correlations in the two-dimensional ising model.Il Nuovo Cimento B (1965-1970), 44(2):276–305, 1966
Leo P Kadanoff. Spin-spin correlations in the two-dimensional ising model.Il Nuovo Cimento B (1965-1970), 44(2):276–305, 1966
1965
-
[25]
Oxford university press, 2021
Jean Zinn-Justin.Quantum field theory and critical phenomena, volume 171. Oxford university press, 2021
2021
-
[26]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 7(1):12140, 2017
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 7(1):12140, 2017
2017
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
The renormalization group and the ϵ expansion.Physics Reports, 12(2):75–199, 1974
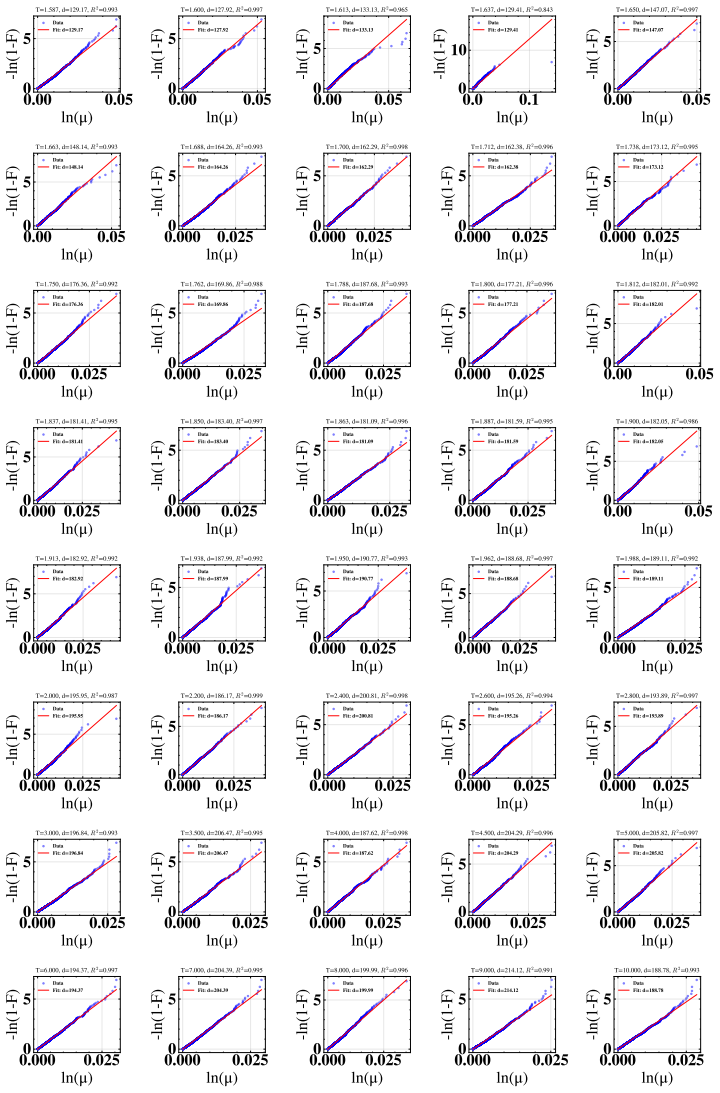
Kenneth G Wilson and John Kogut. The renormalization group and the ϵ expansion.Physics Reports, 12(2):75–199, 1974. 6 A TwoNN Fitting We present the data and fitting plot for the TwoNN method applied to Qwen3-32B in the appendix to show more details. 0.0 0.1 ln( ) 0 5-ln(1-F) T=0.000, d=27.80, R 2=-1.195 Data Fit: d=27.80 0.0 0.2 ln( ) 0 5-ln(1-F) T=0.200...
1974
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.