Curriculum Reinforcement Learning Can Incentivize Reasoning Capacity in LLMs Beyond the Base Model
Pith reviewed 2026-06-26 11:08 UTC · model grok-4.3
The pith
Boundary-aware curriculum RL expands LLM reasoning capacity beyond the base model by introducing new patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
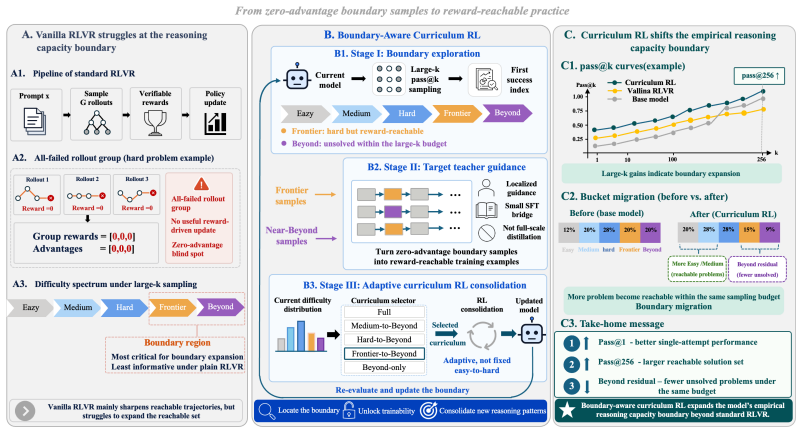
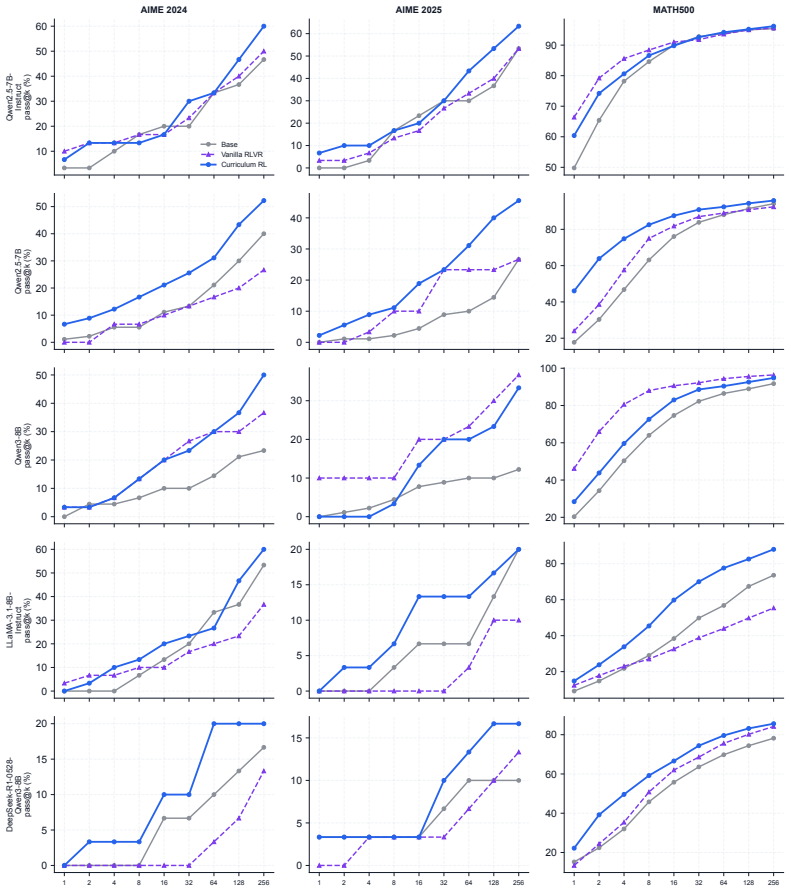
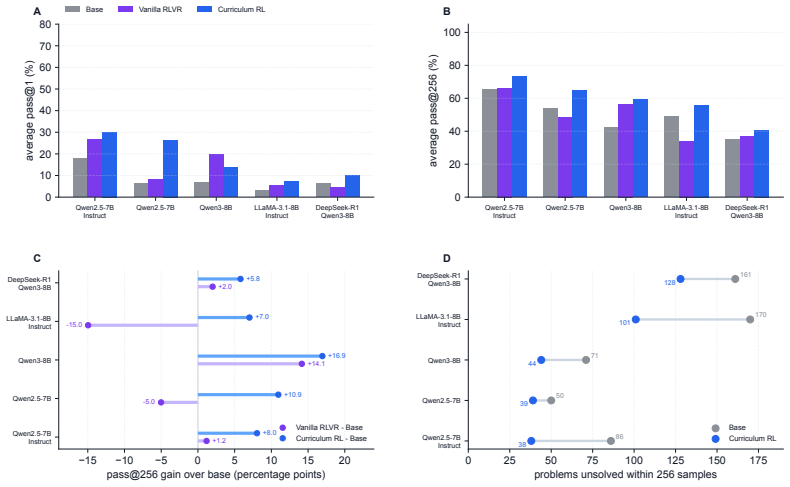
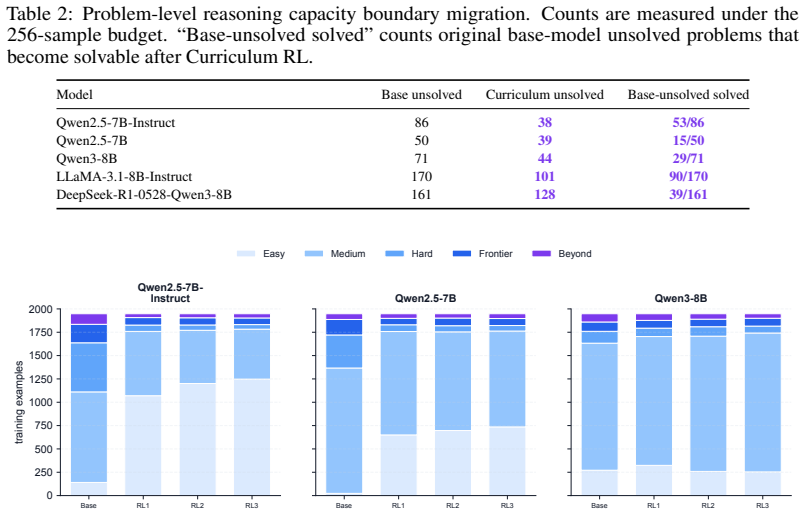
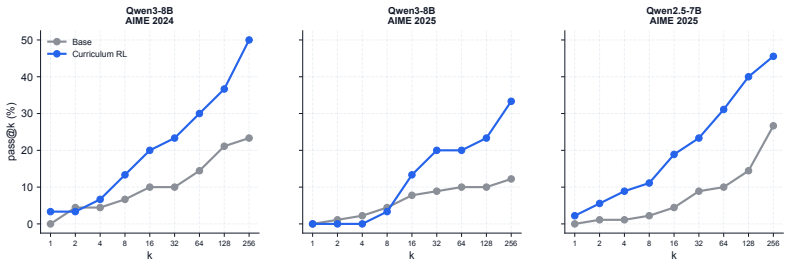
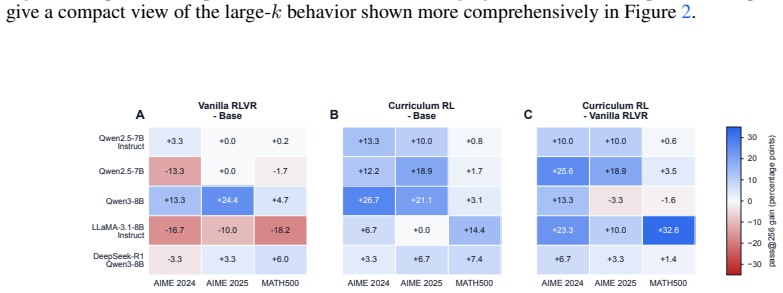
Boundary-aware Curriculum RL first uses pass@k sampling to locate the current reasoning capacity boundary, then applies targeted teacher guidance to examples near or beyond that boundary, and finally uses RL to consolidate the newly introduced reasoning patterns. Across multiple base models this yields simultaneous gains in pass@1 and pass@256, with the latter serving as a proxy for expanded capacity. The approach thereby moves beyond the reallocation-only behavior observed in vanilla RLVR.
What carries the argument
Boundary-aware Curriculum RL, which detects the reasoning boundary via pass@k sampling and uses teacher guidance plus RL to embed new patterns on difficult examples.
If this is right
- Both pass@1 and pass@256 rise together, indicating gains in both efficiency and reachable capacity.
- The same curriculum sequence works across Qwen, Llama, and DeepSeek base models.
- Average pass@256 improves 9.8 points over the base models and 10.3 points over vanilla RLVR.
- The method supplies a concrete training loop that can be repeated to push the empirical boundary further.
Where Pith is reading between the lines
- Repeated application of the loop could produce a sequence of models whose reachable problem sets keep growing without external architectural changes.
- The teacher-guidance step might eventually be replaced by an automated verifier that proposes corrections only on boundary cases.
- The same boundary-detection idea could be tested on non-verifiable tasks if a reliable proxy for solution correctness can be defined.
Load-bearing premise
Higher pass@256 after the procedure means the model has acquired reasoning patterns absent from the base model rather than merely sampling the same patterns more efficiently.
What would settle it
An analysis showing that every correct trajectory found by the trained model is already generable by the base model under sufficiently large sampling, or a run in which pass@256 gains vanish when sampling temperature or decoding method changes.
Figures
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) is widely viewed as a promising path toward continuously improving large language models. Recent works, however, suggest that mainstream RLVR often reallocates sampling probabilities among trajectories already present in the base model: it can improve sampling efficiency, reflected by higher pass@1 scores, but yields limited gains, and can even decrease pass@k scores when k is large, and therefore may fail to expand the base model's reasoning capacity boundary. In this paper, we present a boundary-aware Curriculum RL approach to move beyond the base model's reasoning capacity boundary. Our approach first uses pass@k sampling to locate the current reasoning capacity boundary, then applies targeted teacher guidance to examples near or beyond that boundary, and finally uses RL to consolidate the newly introduced reasoning patterns. Across Qwen, Llama, and DeepSeek base models, boundary-aware Curriculum RL improves both pass@1 scores and pass@256 scores, with pass@1 reflecting one-attempt performance and pass@256 serving as an empirical proxy for the reasoning capacity boundary. In our experiments, average pass@256 improves by 9.8 percentage points over the base models and by 10.3 percentage points over Vanilla RLVR. These results suggest that boundary-aware Curriculum RL can provide a scalable route for LLMs to continuously improve beyond the base model's empirical reasoning capacity boundary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a boundary-aware Curriculum RL method for LLMs: it first uses pass@k sampling to identify the current reasoning capacity boundary, applies targeted teacher guidance to examples near or beyond that boundary, and then uses RLVR to consolidate the introduced reasoning patterns. Experiments across Qwen, Llama, and DeepSeek base models report that the approach improves both pass@1 and pass@256 (the latter treated as an empirical proxy for the capacity boundary), with average pass@256 gains of 9.8 pp over base models and 10.3 pp over vanilla RLVR. The central claim is that this provides a scalable route to expand reasoning capacity beyond the base model's empirical boundary, unlike standard RLVR which the authors argue mainly reallocates probability mass among already-present trajectories.
Significance. If the pass@256 gains demonstrably reflect reasoning patterns absent from the base model (rather than higher-probability sampling of low-probability but already-supported trajectories), the result would be significant: it would supply an empirical route for continuous post-training expansion of LLM reasoning boundaries, directly addressing the reallocation limitation the authors attribute to vanilla RLVR. The multi-model evaluation and explicit contrast with vanilla RLVR strengthen the potential impact if the key assumption holds.
major comments (2)
- [Experimental results / abstract] Experimental results (as summarized in the abstract and implied in the full manuscript): the claim that pass@256 improvements demonstrate expansion beyond the base model's reasoning capacity boundary rests on the assumption that newly successful trajectories lie outside the support of the base model's distribution. No direct verification is reported (e.g., no measurement of base-model probability on the additional successful rollouts, no comparison of trajectory novelty, or ablation confirming absence of the patterns pre-training). This is load-bearing for the central claim, as the skeptic's concern (more efficient sampling of existing patterns) remains unruled out by the presented evidence.
- [Method / curriculum construction] Method description (curriculum construction): the boundary-aware procedure relies on pass@k to locate the capacity boundary and teacher guidance on boundary examples, yet the manuscript supplies no ablation isolating the contribution of each component to the observed pass@256 lift. Without these controls it is difficult to attribute the gains specifically to introduction of new patterns versus other factors such as curriculum ordering or teacher signal strength.
minor comments (2)
- [Abstract] The abstract states average gains but does not report per-model breakdowns or variance; adding these would improve clarity of the multi-model claim.
- [Abstract / experiments] Notation for pass@k is used without explicit definition of the sampling temperature or decoding strategy; a brief clarification would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which correctly identify areas where additional evidence would strengthen our central claim. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental results / abstract] Experimental results (as summarized in the abstract and implied in the full manuscript): the claim that pass@256 improvements demonstrate expansion beyond the base model's reasoning capacity boundary rests on the assumption that newly successful trajectories lie outside the support of the base model's distribution. No direct verification is reported (e.g., no measurement of base-model probability on the additional successful rollouts, no comparison of trajectory novelty, or ablation confirming absence of the patterns pre-training). This is load-bearing for the central claim, as the skeptic's concern (more efficient sampling of existing patterns) remains unruled out by the presented evidence.
Authors: We acknowledge that the evidence is indirect and that direct verification (e.g., base-model log-probabilities on newly successful trajectories) would more conclusively address the reallocation concern. Our current argument relies on pass@256 as an established empirical proxy for distribution support together with the contrast to vanilla RLVR, which shows no comparable gains. To strengthen the manuscript, we will add an analysis computing base-model probabilities on the additional successful rollouts produced by our method. revision: yes
-
Referee: [Method / curriculum construction] Method description (curriculum construction): the boundary-aware procedure relies on pass@k to locate the capacity boundary and teacher guidance on boundary examples, yet the manuscript supplies no ablation isolating the contribution of each component to the observed pass@256 lift. Without these controls it is difficult to attribute the gains specifically to introduction of new patterns versus other factors such as curriculum ordering or teacher signal strength.
Authors: We agree that isolating the contributions of boundary identification and targeted teacher guidance is important. The revised manuscript will include two new ablations: (1) boundary-aware selection without teacher guidance and (2) teacher guidance applied without boundary awareness. These will quantify each component's role in the observed pass@256 improvements. revision: yes
Circularity Check
No derivation chain; empirical results only
full rationale
The paper reports experimental improvements in pass@1 and pass@256 after applying boundary-aware Curriculum RL to multiple base models (Qwen, Llama, DeepSeek). No equations, derivations, fitted parameters, or mathematical predictions appear in the provided text. The central claim rests on measured deltas between base models, vanilla RLVR, and the proposed method, with pass@256 treated as an empirical proxy rather than a quantity defined in terms of itself. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and no renaming of known results occurs. The work is therefore self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption pass@256 serves as a valid empirical proxy for the reasoning capacity boundary
Reference graph
Works this paper leans on
-
[1]
Rl for reasoning by adaptively revealing rationales
Mohammad Hossein Amani, Aryo Lotfi, Nicolas Baldwin, Samy Bengio, Mehrdad Farajtabar, Emmanuel Abbe, and Robert West. Rl for reasoning by adaptively revealing rationales. InThe F ourteenth International Conference on Learning Representations, 2025
2025
-
[2]
Online difficulty filtering for reasoning oriented reinforcement learning
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, Jeongyeon Nam, and Donghyun Kwak. Online difficulty filtering for reasoning oriented reinforcement learning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (V olume 1: Long Papers), pages 700–719, 2026
2026
-
[3]
Evaluating large language models trained on code
Mark Chen, Jerry Tworek, Heewoo Jun, et al. Evaluating large language models trained on code. https://arxiv.org/abs/2107.03374v2, 2021
Pith/arXiv arXiv 2021
-
[4]
Unveiling the key factors for distilling chain-of- thought reasoning
Xinghao Chen, Zhijing Sun, Guo Wenjin, et al. Unveiling the key factors for distilling chain-of- thought reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 15094–15119, 2025
2025
-
[5]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, et al. Training verifiers to solve math word problems. https://arxiv.org/abs/2110.14168v2, 2021
Pith/arXiv arXiv 2021
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. https://arxiv.org/abs/2507.06261v6, 2025
Pith/arXiv arXiv 2025
-
[7]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645(8081):633–638, 2025
DeepSeek-AI, Daya Guo, Dejian Yang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[8]
Omni-math: A universal olympiad level mathematic benchmark for large language models
Bofei Gao, Feifan Song, Zhe Yang, et al. Omni-math: A universal olympiad level mathematic benchmark for large language models. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[9]
Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai
Elliot Glazer, Ege Erdil, Tamay Besiroglu, et al. Frontiermath: A benchmark for evaluating advanced mathematical reasoning in ai. https://arxiv.org/abs/2411.04872v7, 2024
Pith/arXiv arXiv 2024
-
[10]
Rewarding the unlikely: Lifting grpo beyond distribution sharpening
Andre Wang He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting grpo beyond distribution sharpening. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25548–25560, 2025
2025
-
[11]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[12]
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes
Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, et al. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pages 8003–8017, 2023
2023
-
[13]
R-zero: Self-evolving reasoning llm from zero data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. https://arxiv.org/abs/2508.05004v4, 2025. 10
Pith/arXiv arXiv 2025
-
[14]
Mitigating catastrophic forgetting in large language models with self- synthesized rehearsal
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. Mitigating catastrophic forgetting in large language models with self- synthesized rehearsal. https://arxiv.org/abs/2403.01244v2, 2024
arXiv 2024
-
[15]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
Wei Huang, Anda Cheng, and Yinggui Wang. Mitigating catastrophic forgetting in large language models with forgetting-aware pruning. https://arxiv.org/abs/2509.08255v1, 2025
arXiv 2025
-
[16]
Unlocking the power of function vectors for characterizing and mitigating catastrophic forgetting in continual instruction tuning
Gangwei Jiang, Caigao Jiang, Zhaoyi Li, Siqiao Xue, Jun Zhou, Linqi Song, Defu Lian, and Ying Wei. Unlocking the power of function vectors for characterizing and mitigating catastrophic forgetting in continual instruction tuning. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[17]
Tacler: Tailored curriculum reinforcement learning for efficient reasoning
Huiyuan Lai and Malvina Nissim. Tacler: Tailored curriculum reinforcement learning for efficient reasoning. https://arxiv.org/abs/2601.21711v1, 2026
arXiv 2026
-
[18]
Language models can easily learn to reason from demonstrations
Dacheng Li, Shiyi Cao, Tyler Griggs, et al. Language models can easily learn to reason from demonstrations. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 15979–15997, 2025
2025
-
[19]
Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[20]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[21]
An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 33:3776–3786, 2025
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 33:3776–3786, 2025
2025
-
[22]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. S1: Simple test-time scaling. https://arxiv.org/abs/2501.19393v3, 2025
Pith/arXiv arXiv 2025
-
[23]
Openai o1 system card, 2024
openai. Openai o1 system card, 2024
2024
-
[24]
Curriculum reinforcement learning from easy to hard tasks improves llm reasoning
Shubham Parashar, Shurui Gui, Xiner Li, et al. Curriculum reinforcement learning from easy to hard tasks improves llm reasoning. InThe F ourteenth International Conference on Learning Representations, 2025
2025
-
[25]
Seed1.5-thinking: Advancing superb reasoning models with reinforcement learning
ByteDance Seed, Jiaze Chen, Tiantian Fan, et al. Seed1.5-thinking: Advancing superb reasoning models with reinforcement learning. https://arxiv.org/abs/2504.13914v3, 2025
arXiv 2025
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[27]
Xuerui Su, Shufang Xie, Guoqing Liu, Yingce Xia, Renqian Luo, Peiran Jin, Zhiming Ma, Yue Wang, Zun Wang, and Yuting Liu. Trust region preference approximation: A simple and stable reinforcement learning algorithm for llm reasoning. https://arxiv.org/abs/2504.04524v2, 2025
arXiv 2025
-
[28]
Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models
Haoxiang Sun, Yingqian Min, Zhipeng Chen, Wayne Xin Zhao, and Ji-Rong Wen. Challenging the boundaries of reasoning: An olympiad-level math benchmark for large language models. https://arxiv.org/abs/2503.21380v3, 2025
Pith/arXiv arXiv 2025
-
[29]
Kimi k1.5: Scaling reinforcement learning with llms
Kimi Team, Angang Du, Bofei Gao, et al. Kimi k1.5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025
Pith/arXiv arXiv 2025
-
[30]
Continual gradient low-rank projec- tion fine-tuning for llms
Chenxu Wang, Yilin Lyu, Zicheng Sun, and Liping Jing. Continual gradient low-rank projec- tion fine-tuning for llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 14815–14829, 2025. 11
2025
-
[31]
Inscl: A data-efficient continual learning paradigm for fine-tuning large language models with instructions
Yifan Wang, Yafei Liu, Chufan Shi, Haoling Li, Chen Chen, Haonan Lu, and Yujiu Yang. Inscl: A data-efficient continual learning paradigm for fine-tuning large language models with instructions. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long P...
2024
-
[32]
Reasoning scaffolding: Distilling the flow of thought from llms
Xiangyu Wen, Junhua Huang, Zeju Li, Min Li, Jianyuan Zhong, Zhijian Xu, Mingxuan Yuan, Yongxiang Huang, and Qiang Xu. Reasoning scaffolding: Distilling the flow of thought from llms. InThe F ourteenth International Conference on Learning Representations, 2025
2025
-
[33]
Reinforcement learning with verifiable rewards im- plicitly incentivizes correct reasoning in base llms
Xumeng Wen, Zihan Liu, Shun Zheng, et al. Reinforcement learning with verifiable rewards im- plicitly incentivizes correct reasoning in base llms. InThe F ourteenth International Conference on Learning Representations, 2025
2025
-
[34]
Enhancing long-chain reasoning distillation through error- aware self-reflection
Zhuoyang Wu, Xinze Li, Zhenghao Liu, Yukun Yan, Zhiyuan Liu, Minghe Yu, Cheng Yang, Yu Gu, Ge Yu, and Maosong Sun. Enhancing long-chain reasoning distillation through error- aware self-reflection. https://arxiv.org/abs/2505.22131v2, 2025
arXiv 2025
-
[35]
Training large language models for reasoning through reverse curriculum reinforcement learning
Zhiheng Xi, Wenxiang Chen, Boyang Hong, et al. Training large language models for reasoning through reverse curriculum reinforcement learning. InF orty-First International Conference on Machine Learning, 2024
2024
-
[36]
Learning to reason under off-policy guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. https://arxiv.org/abs/2504.14945v5, 2025
Pith/arXiv arXiv 2025
-
[37]
Qwen2.5-math technical report: Toward mathe- matical expert model via self-improvement
An Yang, Beichen Zhang, Binyuan Hui, et al. Qwen2.5-math technical report: Toward mathe- matical expert model via self-improvement. https://arxiv.org/abs/2409.12122v1, 2024
Pith/arXiv arXiv 2024
-
[38]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report. https://arxiv.org/abs/2505.09388v1, 2025
Pith/arXiv arXiv 2025
-
[39]
Qiying Yu, Zheng Zhang, Ruofei Zhu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[40]
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? InThe Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[41]
Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. InSecond Conference on Language Modeling, 2025
2025
-
[42]
Cures: From gradient analysis to efficient curriculum learning for reasoning llms
Yongcheng Zeng, Zexu Sun, Bokai Ji, Erxue Min, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Haifeng Zhang, Xu Chen, and Jun Wang. Cures: From gradient analysis to efficient curriculum learning for reasoning llms. InThe F ourteenth International Conference on Learning Representations, 2025
2025
-
[43]
On the interplay of pre-training, mid-training, and rl on reasoning language models, 2025
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models, 2025
2025
-
[44]
Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach
Rosie Zhao, Alexandru Meterez, Sham M. Kakade, Cengiz Pehlevan, Samy Jelassi, and Eran Malach. Echo chamber: Rl post-training amplifies behaviors learned in pretraining. InSecond Conference on Language Modeling, 2025
2025
-
[45]
Automatic curricu- lum expert iteration for reliable llm reasoning
Zirui Zhao, Hanze Dong, Amrita Saha, Caiming Xiong, and Doyen Sahoo. Automatic curricu- lum expert iteration for reliable llm reasoning. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[46]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. https://arxiv.org/abs/2412.06559v4, 2024
arXiv 2024
-
[47]
Group sequence policy optimization, 2025
Chujie Zheng, Shixuan Liu, Mingze Li, et al. Group sequence policy optimization, 2025. 12
2025
-
[48]
Spurious forgetting in continual learning of language models
Junhao Zheng, Xidi Cai, Shengjie Qiu, and Qianli Ma. Spurious forgetting in continual learning of language models. https://arxiv.org/abs/2501.13453v1, 2025
arXiv 2025
-
[49]
Ttrl: Test-time reinforcement learning
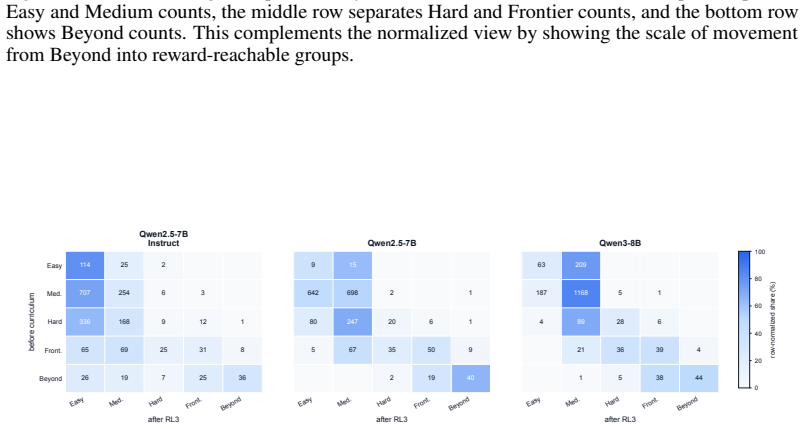
Yuxin Zuo, Kaiyan Zhang, Li Sheng, et al. Ttrl: Test-time reinforcement learning. https://arxiv.org/abs/2504.16084v3, 2025. 13 A Supplementary Experimental Figures This appendix provides additional visual evidence for the main empirical claims: boundary-aware Curriculum RL improves large-k behavior more consistently than Vanilla RLVR, and the curriculum e...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.