Position: Deployed Reinforcement Learning should be Continual
Pith reviewed 2026-06-28 15:50 UTC · model grok-4.3
The pith
Deployed reinforcement learning agents must continue learning because post-deployment changes make any fixed policy suboptimal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Deploying an agent that is incapable of optimality but receives an evaluative reward signal is inherently a continual RL problem. Four sources of non-stationarity after deployment render any fixed policy suboptimal and necessitate never-ending learning. Successful real-world examples already show the advantages of this approach over the train-then-fix paradigm.
What carries the argument
Four sources of non-stationarity after deployment that make any fixed policy suboptimal.
If this is right
- The best deployed agents never stop adapting.
- Real-world continual RL examples already demonstrate concrete advantages over frozen policies.
- Moving away from the train-then-fix paradigm improves long-term performance.
- Specific measures can be taken to enable continual adaptation in deployed systems.
Where Pith is reading between the lines
- Evaluation protocols for deployed RL should track performance drift over months rather than initial test scores.
- Systems in dynamic domains such as robotics or online services would gain from architectures that treat lifelong learning as the default.
- Intermediate designs could combine scheduled retraining with lightweight online updates while full continual methods mature.
- Safety and monitoring practices must account for ongoing policy changes rather than assuming a static deployed agent.
Load-bearing premise
The four sources of non-stationarity are always present after deployment and sufficient to keep any fixed policy from remaining optimal.
What would settle it
A deployed RL system that maintains optimal performance over long periods without any further learning or adaptation in the presence of the four non-stationarity sources.
Figures


read the original abstract
Reinforcement Learning (RL) has received increasing attention and adoption in real-world use cases. Most of these systems follow a train-then-fix paradigm, where trained agents do not learn while interacting with the world until performance degrades and retraining becomes necessary. In this position paper, we argue that deploying an agent that is incapable of optimality, but receives an evaluative reward signal, is inherently a continual RL problem. We identify four sources of non-stationarity after deployment that necessitate never-ending learning, and highlight why the best deployed agents never stop adapting. We analyze successful examples of continual RL in the real world, and present the community with the advantages and measures to move away from the current train-then-fix paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a position paper arguing that any deployed RL agent incapable of optimality yet receiving an evaluative reward signal inherently constitutes a continual RL problem. It identifies four sources of non-stationarity after deployment that render fixed policies suboptimal, advocates abandoning the train-then-fix paradigm in favor of never-ending adaptation, analyzes real-world continual RL examples, and outlines advantages of this shift.
Significance. If the position is accepted, it could redirect RL research and deployment practices toward continual learning methods, promoting more robust real-world systems that adapt indefinitely rather than relying on static policies. The analysis of successful real-world examples provides concrete grounding for the argument.
major comments (2)
- [Abstract] Abstract: the central claim that the four sources of non-stationarity are always present and sufficient to make any fixed policy suboptimal is asserted without measurements, counterexamples, or discussion of cases where non-stationarity might be negligible or mitigated by robust static policies; this premise is load-bearing for the definitional argument that deployment is inherently continual RL.
- [Abstract] The argument that receiving an evaluative reward signal combined with sub-optimality necessitates never-ending learning does not address potential alternatives such as periodic offline retraining or robust policy design that could handle the identified non-stationarities without continuous online adaptation.
minor comments (1)
- The manuscript would benefit from explicit enumeration and brief definitions of the four sources of non-stationarity in a dedicated early section to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on our position paper. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the four sources of non-stationarity are always present and sufficient to make any fixed policy suboptimal is asserted without measurements, counterexamples, or discussion of cases where non-stationarity might be negligible or mitigated by robust static policies; this premise is load-bearing for the definitional argument that deployment is inherently continual RL.
Authors: As a position paper the central claim is definitional and conceptual rather than empirical. The four sources are presented as generally present in deployed settings where optimality cannot be guaranteed. We agree that the abstract would benefit from explicit discussion of edge cases. We will revise the abstract and add a short subsection clarifying that non-stationarity may be negligible in certain controlled environments and noting conditions under which robust static policies could suffice, while maintaining the position that the general case remains continual. revision: yes
-
Referee: [Abstract] The argument that receiving an evaluative reward signal combined with sub-optimality necessitates never-ending learning does not address potential alternatives such as periodic offline retraining or robust policy design that could handle the identified non-stationarities without continuous online adaptation.
Authors: We acknowledge that the manuscript does not explicitly contrast continual online adaptation with alternatives such as periodic offline retraining or robust policy design. We will add a dedicated paragraph in the main text comparing these approaches, explaining why continuous adaptation provides advantages in responsiveness to the identified non-stationarities while noting that periodic retraining or robust design can serve as complementary strategies rather than complete substitutes. revision: yes
Circularity Check
No significant circularity; high-level argumentative position paper
full rationale
This is a position paper with no equations, parameters, derivations, or self-citations that could create circularity. The central claim—that deployed RL agents receiving evaluative rewards face four sources of non-stationarity making fixed policies suboptimal—is presented as an argumentative premise rather than a derived result that reduces to its own inputs by construction. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Solving Rubik's Cube with a Robot Hand
Akkaya, I., Andrychowicz, M., Chociej, M., Litwin, M., McGrew, B., Petron, A., Paino, A., Plappert, M., Powell, G., Ribas, R., et al. Solving Rubik’s Cube with a Robot Hand.arXiv preprint 1910.07113,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[2]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Man´e, D. Concrete Problems in AI Safety. arXiv preprint 1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Dota 2 with Large Scale Deep Reinforcement Learning
Berner, C., Brockman, G., Chan, B., Cheung, V ., Debiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., et al. Dota 2 with Large Scale Deep Reinforcement Learning.arXiv preprint 1912.06680,
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[4]
Step-size Optimization for Continual Learning.arXiv preprint 2401.17401,
Degris, T., Javed, K., Sharifnassab, A., Liu, Y ., and Sutton, R. Step-size Optimization for Continual Learning.arXiv preprint 2401.17401,
-
[5]
A., Schaffernicht, E., and Stoyanov, T
Iannotta, M., Yang, Y ., Stork, J. A., Schaffernicht, E., and Stoyanov, T. Can Context Bridge the Reality Gap? Sim-to-Real Transfer of Context-Aware Policies.arXiv preprint 2511.04249,
-
[6]
Accessed: 2026-01-11
URL https://www.ibm.com/think/topics/ model-deployment. Accessed: 2026-01-11. Jackson, J., Kravtsov, P., and Jain, S. Improving Cursor Tab with online RL. Cursor Blog (Research),
2026
-
[7]
Accessed: 2026-01-28
URL https://cursor.com/blog/tab-rl. Accessed: 2026-01-28. James, S., Wohlhart, P., Kalakrishnan, M., Kalashnikov, D., Irpan, A., Ibarz, J., Levine, S., Hadsell, R., and Bous- malis, K. Sim-to-Real via Sim-to-Sim: Data-Efficient 10 Deployed Reinforcement Learning should be Continual Robotic Grasping via Randomized-to-Canonical Adapta- tion Networks. InIEEE...
2026
-
[8]
In-Context Learning can Perform Continual Learning Like Humans.arXiv preprint 2509.22764,
Kang, L., Wang, F., Liu, S., Chou, H.-C., Lin, C., and Ding, N. In-Context Learning can Perform Continual Learning Like Humans.arXiv preprint 2509.22764,
-
[9]
Accessed: 2026-01-27
URL https://tinyurl.com/4z52r3fe. Accessed: 2026-01-27. Lo, C., Roice, K., Panahi, P. M., Jordan, S. M., White, A., Mihucz, G., Aminmansour, F., and White, M. Goal- Space Planning with Subgoal Models.Journal of Ma- chine Learning Research,
2026
- [10]
-
[11]
ualberta.ca/RLAI/rewardhypothesis
URL http://incompleteideas.net/rlai.cs. ualberta.ca/RLAI/rewardhypothesis. html. Accessed: 2026-01-27. Sutton, R. S. and Barto, A. G.Reinforcement learning: An Introduction. MIT press,
2026
-
[12]
S., Bowling, M., and Pilarski, P
Sutton, R. S., Bowling, M., and Pilarski, P. M. The Alberta Plan for AI Research.arXiv preprint 2208.11173,
-
[13]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, M., Kwiatkowski, A., Terry, J., Balis, J. U., De Cola, G., Deleu, T., Goul˜ao, M., Kallinteris, A., Krimmel, M., KG, A., et al. Gymnasium: A Standard Interface for Reinforcement Learning Environments. InarXiv preprint 2407.17032,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Wan, Y . and Sutton, R. S. On Convergence of Average- Reward Off-Policy Control algorithms in Weakly Com- municating MDPs.arXiv preprint 2209.15141,
-
[15]
The damping coefficient bt grows in a noisily quadratic manner over time, as shown in Figure 3 (Gaussian noise σ= 0.02 )
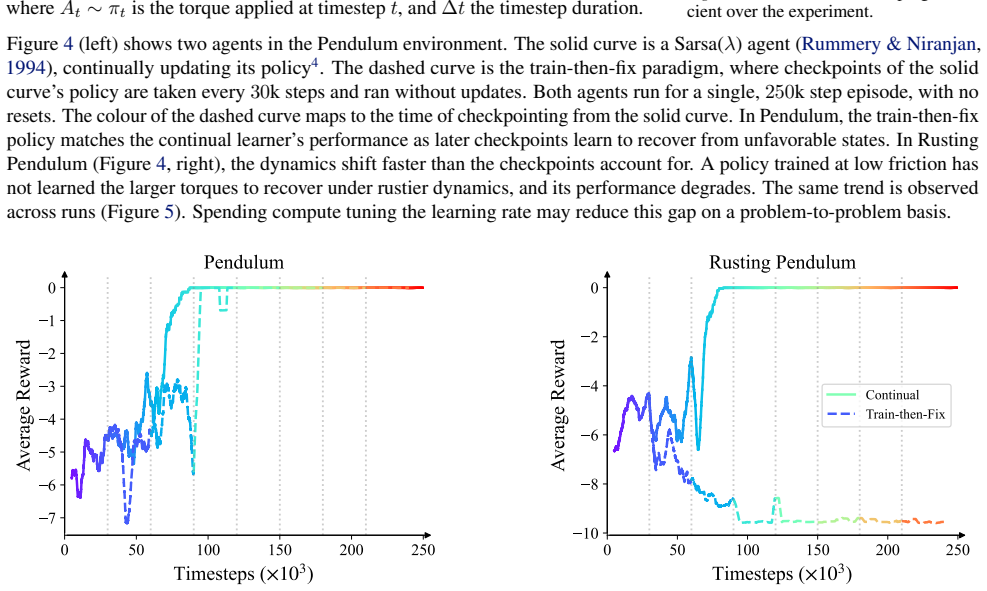
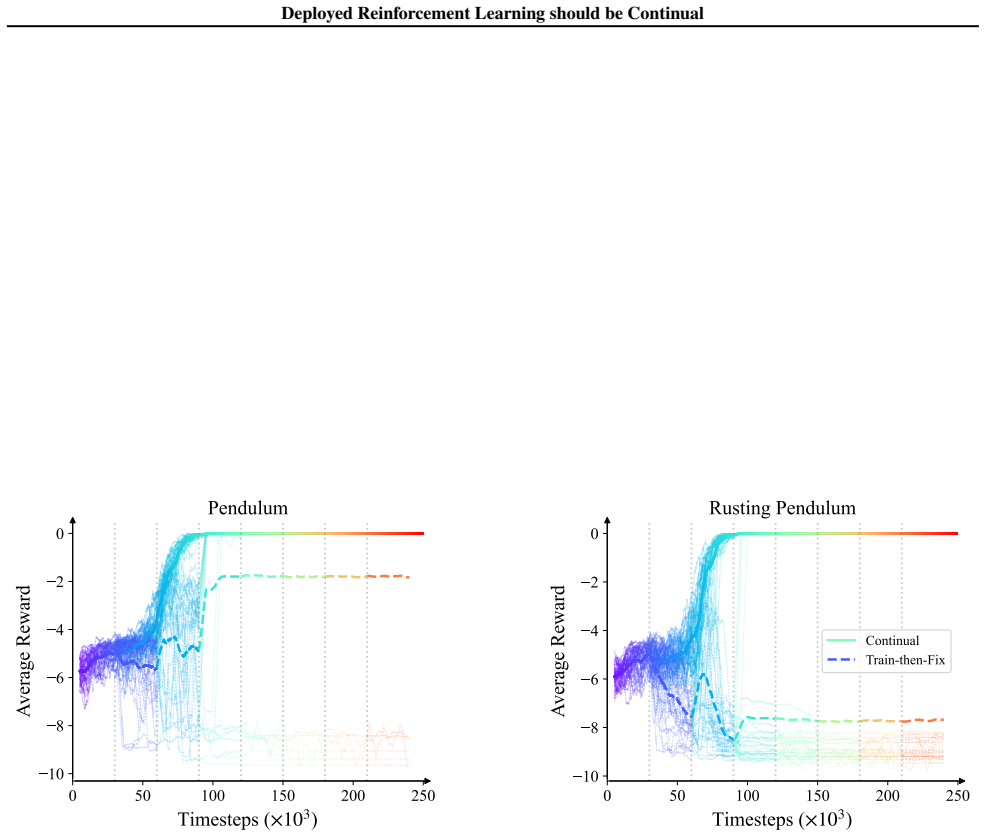
to include a damping term, −bt ˙θt. The damping coefficient bt grows in a noisily quadratic manner over time, as shown in Figure 3 (Gaussian noise σ= 0.02 ). This mimics rust that accumulates at the pendulum joint, making actions from older policies lack the necessary torque to overcome the rust and raise the pendulum. 0 50 100 150 200 250 Timesteps (×103...
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.