Cross-Attention End-to-End ASR for Two-Party Conversations
Pith reviewed 2026-05-24 16:23 UTC · model grok-4.3
The pith
An end-to-end ASR model uses speaker-specific cross-attention on both parties' histories to improve recognition of two-party conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that an end-to-end speech recognition model can learn interactions between two speakers by exploiting their histories of conversational-context information that spans multiple turns, using a speaker-specific cross-attention mechanism that attends to the other speaker's output as well as the current speaker's output, and that this yields better recognition of long conversations than standard end-to-end models when evaluated on the Switchboard corpus.
What carries the argument
speaker-specific cross-attention mechanism that attends to both speakers' output histories guided by turn changes
If this is right
- The model outperforms standard end-to-end ASR models on the Switchboard corpus.
- It exploits two speakers' conversational-context histories that span multiple turns.
- The cross-attention lets the decoder look at the other speaker's output history in addition to the current speaker's.
- Recognition improves for long two-party conversations by learning speaker interactions inside the end-to-end framework.
Where Pith is reading between the lines
- The same cross-attention pattern could be tested on datasets with more than two speakers.
- Errors at speaker turns or interruptions might decrease if the mechanism generalizes well.
- Pairing the attention with an external language model could compound the gains on conversational data.
Load-bearing premise
Turn-changing information is reliably available and the cross-attention can extract useful interactions between the two speakers without adding noise or alignment errors.
What would settle it
An ablation on Switchboard that removes the cross-attention component and finds equal or higher word error rate than the full model would falsify the performance gain.
Figures

read the original abstract
We present an end-to-end speech recognition model that learns interaction between two speakers based on the turn-changing information. Unlike conventional speech recognition models, our model exploits two speakers' history of conversational-context information that spans across multiple turns within an end-to-end framework. Specifically, we propose a speaker-specific cross-attention mechanism that can look at the output of the other speaker side as well as the one of the current speaker for better at recognizing long conversations. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end ASR model for two-party conversations that incorporates turn-changing information via a speaker-specific cross-attention mechanism. This allows the model to attend to both the current speaker's and the other speaker's conversational histories across multiple turns within a single E2E framework. The authors evaluate the approach on the Switchboard corpus and claim it outperforms standard end-to-end speech recognition models.
Significance. If the performance gains can be substantiated, the work would provide a concrete method for injecting multi-speaker conversational context into E2E ASR, addressing a limitation of models that treat speakers independently. This could be relevant for improving recognition in long, interactive dialogues where cross-speaker dependencies matter.
major comments (2)
- Abstract: The central empirical claim that the model 'outperforms standard end-to-end speech recognition models' on Switchboard is stated without any quantitative results, baseline definitions, architecture diagram, training details, error bars, or statistical tests, rendering the claim impossible to assess from the given text.
- Abstract (paragraph describing the speaker-specific cross-attention): No information is supplied on whether turn boundaries are ground-truth or detected, how speaker histories are aligned across turns, or any regularization to mitigate misalignment or noise in the cross-attention outputs; this assumption is load-bearing for the claimed benefit over standard E2E models.
minor comments (1)
- Abstract, final sentence: the phrasing 'for better at recognizing long conversations' is grammatically awkward and should be revised for clarity (e.g., 'to better recognize long conversations').
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: Abstract: The central empirical claim that the model 'outperforms standard end-to-end speech recognition models' on Switchboard is stated without any quantitative results, baseline definitions, architecture diagram, training details, error bars, or statistical tests, rendering the claim impossible to assess from the given text.
Authors: The abstract provides a high-level summary of the contribution as is conventional. Quantitative results, baseline definitions, architecture descriptions, and training details are all included in the body of the manuscript. We agree that adding a brief mention of the key performance improvement to the abstract would make the central claim easier to assess at a glance and are willing to do so. revision: partial
-
Referee: Abstract (paragraph describing the speaker-specific cross-attention): No information is supplied on whether turn boundaries are ground-truth or detected, how speaker histories are aligned across turns, or any regularization to mitigate misalignment or noise in the cross-attention outputs; this assumption is load-bearing for the claimed benefit over standard E2E models.
Authors: The abstract summarizes the approach at a high level. The full manuscript specifies that turn boundaries are taken from the corpus annotations, describes how speaker histories are aligned across turns, and details the cross-attention implementation. These elements are presented in the methods section. revision: no
Circularity Check
No circularity: empirical model proposal with no derivation chain
full rationale
The paper proposes a speaker-specific cross-attention architecture for two-party ASR and reports empirical results on Switchboard. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. The central claim rests on experimental comparison rather than any reduction to inputs by construction, so no circular steps exist.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption End-to-end neural ASR training on audio-transcript pairs is sufficient to learn useful representations
Reference graph
Works this paper leans on
-
[1]
Introduction Contextual information plays an important role in automatic speech recognition (ASR), especially in processing a long con- versation since semantically related words, or phrases often re- occur across sentences. Typically, a long contextual information is only modeled in the language model (LM) which is trained only on text data separately [1...
-
[2]
Related work Several recent studies have considered to incorporate the con- text information within a end-to-end speech recognizer [11, 12]. In contrast with our method which uses a conversational-context information for processing a long two-speaker conversation, their methods use distinct phrases (i.e. play a song) with an attention mechanism in specific...
-
[3]
Model In this section, we first review conversational-context aware end-to-end speech recognition model [7, 9, 10]. We then present our proposed cross-attention end-to-end speech recog- nition model for processing two speaker conversations. 3.1. Encoder for history of the utterances The key idea of the conversational-context aware end-to-end speech recogni...
-
[4]
Cross-Attention End-to-End ASR for Two-Party Conversations
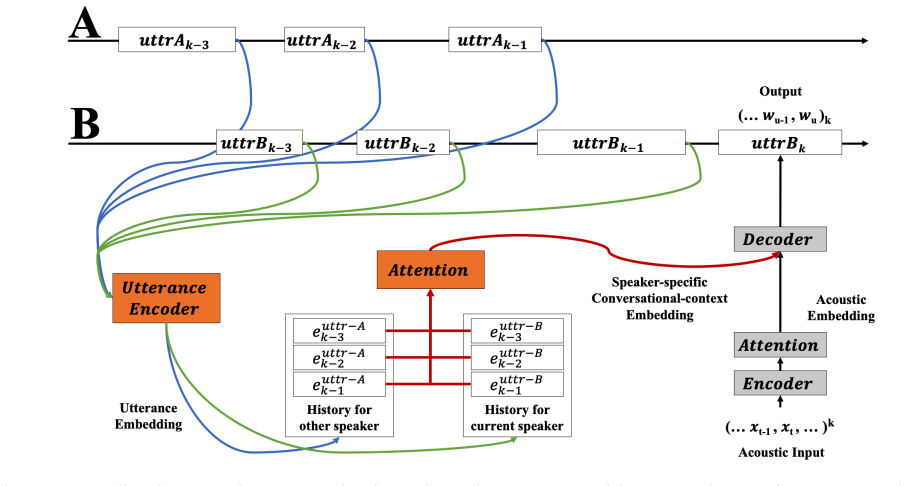
previous word embedding ( eu−1 w ), and additionally 3) conversational-context embedding (ek c ): ek a =Encoder(xk) (1) wk u∼Decoder(ek c,e k w,e k a) (2) arXiv:1907.10726v1 [eess.AS] 24 Jul 2019 Figure 1: Overall architecture of our proposed end-to-end speech recognition model using speaker-specific conversational-context embedding generated from the utte...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[5]
Experiments 4.1. Datasets We trained our model on 300 hours of two-party conversational speech corpus, the Switchboard LDC corpus (97S62), and tested on the HUB5 Eval 2000 LDC corpora (LDC2002S09, LDC2002T43). In Section 5, we show separate results for the CallHome English (CH) and Switchboard (SWB) sets. We de- note the number of utterances, the number o...
work page 2000
-
[6]
with the beam size 10. We adjusted the score by adding a length penalty since the model has a small bias for shorter ut- terances. The final score is normalized with a length penalty 0.1. The models are implemented using the PyTorch deep learn- ing library [40], and ESPnet toolkit [19, 33, 41]
-
[7]
Results The Table 2 summarizes the results of our baseline and pro- posed model, Attention and matchLSTM, with various number of utterance history. The Baseline is our base- line which is trained on isolated utterances without using Table 2: Comparison of word error rates (WER) on Switchboard 300h with standard end-to-end speech recognition models and our...
-
[8]
Conclusions We have introduced an end-to-end speech recognizer with speaker-specific cross-attention mechanism for two-party con- versations. Unlike conventional speech recognition models, our model generates output tokens conditioning on two speakers’ Figure 2: The attention weights over utterance-history of the speaker A (top) and the speaker B (bottom) ...
-
[9]
Acknowledgments We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research. This work also used the Bridges system, which is supported by NSF award number ACI-1445606, at the Pittsburgh Supercom- puting Center (PSC)
-
[10]
Recurrent neural network based language model,
T. Mikolov, M. Karafi ´at, L. Burget, J. ˇCernock`y, and S. Khu- danpur, “Recurrent neural network based language model,” in Eleventh Annual Conference of the International Speech Commu- nication Association, 2010
work page 2010
-
[11]
Context dependent recurrent neural network language model
T. Mikolov and G. Zweig, “Context dependent recurrent neural network language model.” SLT, vol. 12, pp. 234–239, 2012
work page 2012
-
[12]
Larger-Context Language Modelling
T. Wang and K. Cho, “Larger-context language modelling,” arXiv preprint arXiv:1511.03729, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Document Context Language Models
Y . Ji, T. Cohn, L. Kong, C. Dyer, and J. Eisenstein, “Document context language models,” arXiv preprint arXiv:1511.03962 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Dialog context language modeling with re- current neural networks,
B. Liu and I. Lane, “Dialog context language modeling with re- current neural networks,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2017, pp. 5715–5719
work page 2017
-
[15]
Session-level lan- guage modeling for conversational speech,
W. Xiong, L. Wu, J. Zhang, and A. Stolcke, “Session-level lan- guage modeling for conversational speech,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2764–2768
work page 2018
-
[16]
Dialog-context aware end-to-end speech recognition,
S. Kim and F. Metze, “Dialog-context aware end-to-end speech recognition,” SLT, 2018
work page 2018
-
[17]
Situation informed end-to-end asr for chime-5 challenge,
S. Kim, S. Dalmia, and F. Metze, “Situation informed end-to-end asr for chime-5 challenge,” CHiME5 workshop, 2018
work page 2018
-
[18]
Acoustic-to-word models with conversa- tional context information,
S. Kim and F. Metze, “Acoustic-to-word models with conversa- tional context information,” NAACL, 2019
work page 2019
-
[19]
Gated embeddings in end-to- end speech recognition for conversational-context fusion,
S. Kim, S. Dalmia, and F. Metze, “Gated embeddings in end-to- end speech recognition for conversational-context fusion,” ACL, 2019
work page 2019
-
[20]
Deep context: end-to-end contextual speech recognition
G. Pundak, T. N. Sainath, R. Prabhavalkar, A. Kannan, and D. Zhao, “Deep context: end-to-end contextual speech recogni- tion,” arXiv preprint arXiv:1808.02480, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Contextual Speech Recognition with Difficult Negative Training Examples
U. Alon, G. Pundak, and T. N. Sainath, “Contextual speech recog- nition with difficult negative training examples,” arXiv preprint arXiv:1810.12170, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[22]
Switchboard-1 release 2 ldc97s62,
J. Godfrey and E. Holliman, “Switchboard-1 release 2 ldc97s62,” Linguistic Data Consortium, Philadelphia, vol. LDC97S62, 1993
work page 1993
-
[23]
Switchboard: Telephone speech corpus for research and development,
J. J. Godfrey, E. C. Holliman, and J. McDaniel, “Switchboard: Telephone speech corpus for research and development,” in Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on , vol. 1. IEEE, 1992, pp. 517–520
work page 1992
-
[24]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine trans- lation by jointly learning to align and translate,” arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[25]
End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results
J. Chorowski, D. Bahdanau, K. Cho, and Y . Bengio, “End-to- end continuous speech recognition using attention-based recurrent NN: First results,” arXiv preprint arXiv:1412.1602, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Attention-based models for speech recognition,
J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Ben- gio, “Attention-based models for speech recognition,” in Ad- vances in Neural Information Processing Systems, 2015, pp. 577– 585
work page 2015
-
[27]
W. Chan, N. Jaitly, Q. V . Le, and O. Vinyals, “Listen, attend and spell,” arXiv preprint arXiv:1508.01211, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Joint ctc-attention based end- to-end speech recognition using multi-task learning,
S. Kim, T. Hori, and S. Watanabe, “Joint ctc-attention based end- to-end speech recognition using multi-task learning,” in Acous- tics, Speech and Signal Processing (ICASSP), 2017 IEEE Inter- national Conference on. IEEE, 2017, pp. 4835–4839
work page 2017
-
[29]
Glove: Global vectors for word representation,
J. Pennington, R. Socher, and C. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , 2014, pp. 1532–1543
work page 2014
-
[30]
Enrich- ing word vectors with subword information,
P. Bojanowski, E. Grave, A. Joulin, and T. Mikolov, “Enrich- ing word vectors with subword information,” Transactions of the Association for Computational Linguistics , vol. 5, pp. 135–146, 2017
work page 2017
-
[31]
Deep contextualized word represen- tations,
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, and L. Zettlemoyer, “Deep contextualized word represen- tations,” in Proc. of NAACL, 2018
work page 2018
-
[32]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre- training of deep bidirectional transformers for language under- standing,” arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Learning Natural Language Inference with LSTM
S. Wang and J. Jiang, “Learning natural language inference with lstm,” arXiv preprint arXiv:1512.08849, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[34]
Machine Comprehension Using Match-LSTM and Answer Pointer
——, “Machine comprehension using match-lstm and answer pointer,” arXiv preprint arXiv:1608.07905, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
O. Vinyals, M. Fortunato, and N. Jaitly, “Pointer networks,” in Advances in Neural Information Processing Systems , 2015, pp. 2692–2700
work page 2015
-
[36]
Improved training of end-to-end attention models for speech recognition,
A. Zeyer, K. Irie, R. Schl ¨uter, and H. Ney, “Improved training of end-to-end attention models for speech recognition,” arXiv preprint arXiv:1805.03294, 2018
-
[37]
Purely sequence-trained neu- ral networks for asr based on lattice-free mmi
D. Povey, V . Peddinti, D. Galvez, P. Ghahremani, V . Manohar, X. Na, Y . Wang, and S. Khudanpur, “Purely sequence-trained neu- ral networks for asr based on lattice-free mmi.” in Interspeech, 2016, pp. 2751–2755
work page 2016
-
[38]
Advances in all-neural speech recognition,
G. Zweig, C. Yu, J. Droppo, and A. Stolcke, “Advances in all-neural speech recognition,” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on . IEEE, 2017, pp. 4805–4809
work page 2017
-
[39]
Hierarchical Multi Task Learning With CTC
R. Sanabria and F. Metze, “Hierarchical multi task learning with ctc,” arXiv preprint arXiv:1807.07104, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Building competitive direct acoustics-to-word models for English conversational speech recognition
K. Audhkhasi, B. Kingsbury, B. Ramabhadran, G. Saon, and M. Picheny, “Building competitive direct acoustics-to-word mod- els for english conversational speech recognition,” arXiv preprint arXiv:1712.03133, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
Acoustic-to-Word Recognition with Sequence-to-Sequence Models
S. Palaskar and F. Metze, “Acoustic-to-word recognition with sequence-to-sequence models,”arXiv preprint arXiv:1807.09597, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Hy- brid ctc/attention architecture for end-to-end speech recognition,
S. Watanabe, T. Hori, S. Kim, J. R. Hershey, and T. Hayashi, “Hy- brid ctc/attention architecture for end-to-end speech recognition,” IEEE Journal of Selected Topics in Signal Processing , vol. 11, no. 8, pp. 1240–1253, 2017
work page 2017
-
[43]
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” in Proceedings of the 23rd international conference on Machine learning . ACM, 2006, pp. 369–376
work page 2006
-
[44]
Very deep convolutional net- works for end-to-end speech recognition,
Y . Zhang, W. Chan, and N. Jaitly, “Very deep convolutional net- works for end-to-end speech recognition,” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Con- ference on. IEEE, 2017, pp. 4845–4849
work page 2017
-
[45]
T. Hori, S. Watanabe, Y . Zhang, and W. Chan, “Advances in joint ctc-attention based end-to-end speech recognition with a deep cnn encoder and rnn-lm,” arXiv preprint arXiv:1706.02737, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
ADADELTA: An Adaptive Learning Rate Method
M. D. Zeiler, “Adadelta: an adaptive learning rate method,” arXiv preprint arXiv:1212.5701, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[47]
On the difficulty of train- ing recurrent neural networks,
R. Pascanu, T. Mikolov, and Y . Bengio, “On the difficulty of train- ing recurrent neural networks,” in International Conference on Machine Learning, 2013, pp. 1310–1318
work page 2013
-
[48]
Sequence to sequence learning with neural networks,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to sequence learning with neural networks,” inAdvances in neural information processing systems, 2014, pp. 3104–3112
work page 2014
-
[49]
Automatic differ- entiation in pytorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differ- entiation in pytorch,” in NIPS-W, 2017
work page 2017
-
[50]
ESPnet: End-to-End Speech Processing Toolkit
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno, N. E. Y . Soplin, J. Heymann, M. Wiesner, N. Chen et al. , “Espnet: End-to-end speech processing toolkit,” arXiv preprint arXiv:1804.00015, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.