Anti-Prompt: Image Protection against Text-Guided Image-to-Video Generation
Pith reviewed 2026-07-03 20:55 UTC · model grok-4.3
The pith
Anti-Prompt adds imperceptible perturbations to images that cause text-guided image-to-video models to produce inconsistent and structurally failed videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
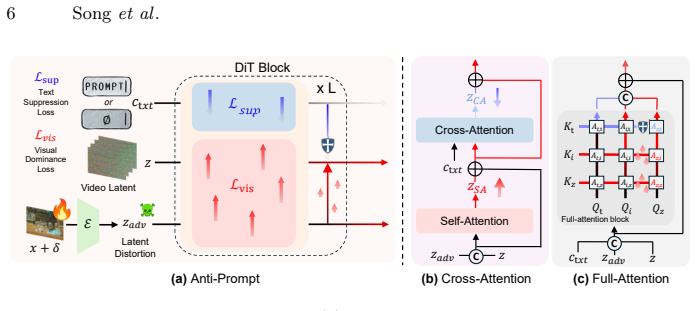
By attenuating text-conditioned interactions while strengthening visual-only pathways in the denoising process, targeted image perturbations reliably induce visible inconsistencies, structural failures, and loss of temporal coherence in the output videos of text-guided I2V models.
What carries the argument
Imperceptible perturbations that weaken text-conditioned interactions during denoising and reinforce visual-only pathways.
If this is right
- Protection performance reaches strong levels on two representative I2V architectures.
- The approach improves computational efficiency over earlier protection techniques.
- Perturbations transfer effectively to unseen I2V models.
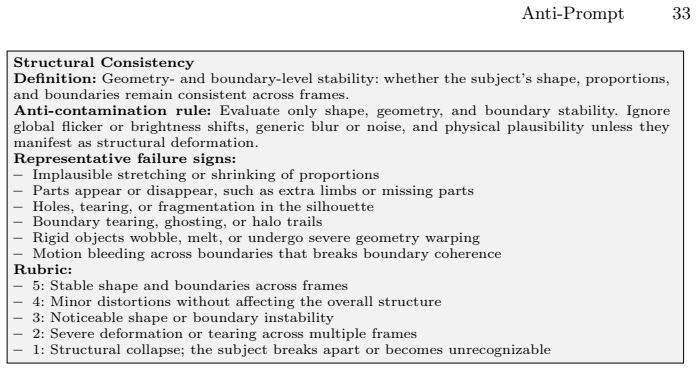
- A Video-LLM-assisted protocol supplies interpretable, frame-grounded metrics for protection quality.
Where Pith is reading between the lines
- Models retrained to reduce reliance on text prompts might become harder to protect with this style of attack.
- The same perturbation principle could be tested on other text-conditioned generation tasks such as image editing or 3D synthesis.
- Widespread use would let image owners apply a one-time safeguard before uploading content online.
Load-bearing premise
Modern I2V models depend so strongly on textual guidance that small image changes can selectively disrupt that dependence and produce visible generation failures without model-specific knowledge.
What would settle it
Generate videos from protected images on the tested I2V models and check whether the expected inconsistencies, structural breaks, and temporal failures appear at rates clearly above those from unprotected images.
Figures








read the original abstract
Recent advances in Image-to-Video generation allow a single image to be animated into a convincing video under text guidance, raising serious copyright and privacy risks. We propose Anti-Prompt, an image protection approach that injects imperceptible perturbations into an image, inducing visible inconsistencies and structural failures in text-guided I2V generation. Our method is motivated by a simple empirical observation. When text guidance is removed from modern I2V models, generation quality degrades markedly, not only in motion realism but also in subject preservation, structural coherence, and temporal consistency. Building on this insight, Anti-Prompt exploits the model reliance on textual guidance by attenuating text-conditioned interactions during denoising while strengthening visual-only pathways. To further systematically evaluate protection effectiveness, we introduce a Video-LLM-assisted evaluation protocol that provides interpretable, frame-grounded analyses of generation artifacts and inconsistencies. Experiments on two representative I2V architectures demonstrate that our method achieves strong protection performance while improving efficiency and cross-model transferability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Anti-Prompt, a protection method that adds imperceptible perturbations to an input image to defend against text-guided image-to-video (I2V) generation. Motivated by the observation that removing text guidance from I2V models degrades motion realism, subject preservation, structural coherence, and temporal consistency, the approach attenuates text-conditioned interactions during denoising while strengthening visual-only pathways, inducing visible artifacts and failures in the output video. It also introduces a Video-LLM-assisted evaluation protocol for frame-grounded analysis of artifacts. Experiments on two representative I2V architectures report strong protection performance along with gains in efficiency and cross-model transferability.
Significance. If the empirical results hold under the stated conditions, the work addresses a timely copyright and privacy concern raised by recent I2V models. The empirical motivation from text-guidance ablation is a clear strength, and the Video-LLM evaluation protocol offers an interpretable, reproducible way to quantify protection that goes beyond simple visual inspection. Cross-model transferability without model-specific knowledge would be a practically valuable property if demonstrated rigorously.
major comments (2)
- [Abstract / Introduction] The load-bearing premise that text-conditioned interactions can be selectively attenuated by image-space perturbations without access to the target I2V model (stated in the abstract and motivated in the introduction) requires explicit verification; the manuscript should include an ablation confirming that the perturbation optimization does not rely on gradients or internal activations from the protected-against model.
- [§4] §4 (Experiments): the claim of improved cross-model transferability is central yet reported only at high level; quantitative transfer results across the two architectures (including failure rates or artifact scores) must be presented with statistical significance and compared against a random-perturbation baseline to establish that the effect is not due to generic image degradation.
minor comments (3)
- [Abstract] The abstract refers to 'two representative I2V architectures' without naming them; the method and experimental sections should state the exact models (e.g., Stable Video Diffusion, AnimateDiff) at first mention.
- [Evaluation protocol] The Video-LLM evaluation protocol is introduced as a contribution; its prompt template, frame sampling strategy, and inter-annotator agreement metrics should be detailed in an appendix or dedicated subsection for reproducibility.
- [§3] Notation for the perturbation optimization objective (likely in §3) should be introduced with a clear equation rather than prose description only.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's timeliness and the strengths of the empirical motivation and Video-LLM protocol. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Introduction] The load-bearing premise that text-conditioned interactions can be selectively attenuated by image-space perturbations without access to the target I2V model (stated in the abstract and motivated in the introduction) requires explicit verification; the manuscript should include an ablation confirming that the perturbation optimization does not rely on gradients or internal activations from the protected-against model.
Authors: We agree that explicit verification of the black-box nature of the optimization is valuable. The method is designed to operate without access to the target I2V model, using only image-space perturbations derived from the general observation on text guidance. We will add an ablation study in the revised manuscript (likely in §3) that confirms the optimization process does not access gradients or internal activations from the protected-against models. revision: yes
-
Referee: [§4] §4 (Experiments): the claim of improved cross-model transferability is central yet reported only at high level; quantitative transfer results across the two architectures (including failure rates or artifact scores) must be presented with statistical significance and compared against a random-perturbation baseline to establish that the effect is not due to generic image degradation.
Authors: We acknowledge that the cross-model results are summarized at a high level in the current version. In the revision we will expand §4 with detailed quantitative transfer results across the two architectures, including failure rates and artifact scores, statistical significance testing, and direct comparisons to a random-perturbation baseline to isolate the effect from generic degradation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method for image protection motivated by the observation that removing text guidance degrades I2V generation quality. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the abstract or description. The central claim rests on experimental validation across architectures rather than any self-referential reduction or ansatz smuggled via prior work, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: SIGGRAPH Asia (2024)
Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Liu, G., Raj, A., et al.: Lumiere: A space-time diffusion model for video generation. In: SIGGRAPH Asia (2024)
2024
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
In: CVPR (2023)
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: CVPR (2023)
2023
-
[6]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D.A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M.S., Bohg, J., Bosselut, A., Brunskill, E., et al.: On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., et al.: Videocrafter1: Open diffusion models for high-quality video generation. arXiv preprint arXiv:2310.19512 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In: CVPR (2024)
Chen, H., Zhang, Y., Cun, X., Xia, M., Wang, X., Weng, C., Shan, Y.: Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In: CVPR (2024)
2024
-
[9]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., et al.: Pixart-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis. arXiv preprint arXiv:2310.00426 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
In: ICML (2024)
Choi, J.S., Lee, K., Jeong, J., Xie, S., Shin, J., Lee, K.: Diffusionguard: A robust defense against malicious diffusion-based image editing. In: ICML (2024)
2024
-
[11]
Diaz,G.:Adversecleanerextension(2025),https://github.com/gogodr/AdverseCleanerExtension
2025
-
[12]
IEEE Transactions on Pattern Analysis and Machine Intelligence44(5), 2567–2581 (2020)
Ding, K., Ma, K., Wang, S., Simoncelli, E.P.: Image quality assessment: Unify- ing structure and texture similarity. IEEE Transactions on Pattern Analysis and Machine Intelligence44(5), 2567–2581 (2020)
2020
-
[13]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[14]
In: CVPR (2025)
Gui, D., Guo, X., Zhou, W., Lu, Y.: I2vguard: Safeguarding images against misuse in diffusion-based image-to-video models. In: CVPR (2025)
2025
-
[15]
In: ICLR (2018)
Guo, C., Rana, M., Cisse, M., van der Maaten, L.: Countering adversarial images using input transformations. In: ICLR (2018)
2018
-
[16]
In: ICLR (2024)
Guo, Y., Yang, C., Rao, A., Liang, Z., Wang, Y., Qiao, Y., Agrawala, M., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. In: ICLR (2024)
2024
-
[17]
LTX-Video: Realtime Video Latent Diffusion
HaCohen, Y., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., et al.: Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103 (2024) Anti-Prompt 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
In: CVPR (2025)
Han, H., Li, S., Chen, J., Yuan, Y., Wu, Y., Deng, Y., Leong, C.T., Du, H., Fu, J., Li, Y., et al.: Video-bench: Human-aligned video generation benchmark. In: CVPR (2025)
2025
-
[19]
Latent Video Diffusion Models for High-Fidelity Long Video Generation
He, Y., Yang, T., Zhang, Y., Shan, Y., Chen, Q.: Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:2211.13221 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
In: NeurIPS (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
2020
-
[22]
In: NeurIPS (2022)
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. In: NeurIPS (2022)
2022
-
[23]
In: CVPR (2024)
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video genera- tive models. In: CVPR (2024)
2024
-
[24]
Huang, Z., Zhang, F., Xu, X., He, Y., Yu, J., Dong, Z., Ma, Q., Chanpaisit, N., Si, C., Jiang, Y., et al.: Vbench++: Comprehensive and versatile benchmark suite for video generative models. arXiv preprint arXiv:2411.13503 (2024)
-
[25]
In: ICLR (2025)
Jeon, J., Kim, W.J., Ha, S., Son, S., Yoon, S.e.: Advpaint: Protecting images from inpainting manipulation via adversarial attention disruption. In: ICLR (2025)
2025
-
[26]
Biometrika30(1-2), 81–93 (1938)
Kendall, M.G.: A new measure of rank correlation. Biometrika30(1-2), 81–93 (1938)
1938
-
[27]
The Annals of Mathematical Statistics10(3), 275–287 (1939).https://doi.org/10.1214/aoms/ 1177732186
Kendall, M.G., Babington Smith, B.: The problem of m rankings. The Annals of Mathematical Statistics10(3), 275–287 (1939).https://doi.org/10.1214/aoms/ 1177732186
-
[28]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Universal Image Immunization against Diffusion-based Image Editing via Semantic Injection
Lee, C., Shin, S., Choi, D., Jeon, H.g., Son, J.: Universal image immuniza- tion against diffusion-based image editing via semantic injection. arXiv preprint arXiv:2602.14679 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
arXiv preprint arXiv:2402.01239 (2024)
Li, G., Yang, S., Zhang, J., Zhang, T.: Prime: Protect your videos from malicious editing. arXiv preprint arXiv:2402.01239 (2024)
-
[31]
In: ICML (2023)
Liang, C., Wu, X., Hua, Y., Zhang, J., Xue, Y., Song, T., Xue, Z., Ma, R., Guan, H.: Adversarial example does good: preventing painting imitation from diffusion models via adversarial examples. In: ICML (2023)
2023
-
[32]
In: EMNLP (2024)
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: EMNLP (2024)
2024
-
[33]
In: EMNLP (2023)
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-eval: Nlg evaluation using gpt-4 with better human alignment. In: EMNLP (2023)
2023
-
[34]
In: CVPR (2024)
Lo, L., Yeo, C.Y., Shuai, H.H., Cheng, W.H.: Distraction is all you need: Memory- efficient image immunization against diffusion-based image editing. In: CVPR (2024)
2024
-
[35]
In: ACL (2024)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: ACL (2024)
2024
-
[36]
ACM computing surveys (CSUR)54(1), 1–41 (2021)
Mirsky, Y., Lee, W.: The creation and detection of deepfakes: A survey. ACM computing surveys (CSUR)54(1), 1–41 (2021)
2021
-
[37]
In: CVPR (2017) 18 Songet al
Moosavi-Dezfooli, S.M., Fawzi, A., Fawzi, O., Frossard, P.: Universal adversarial perturbations. In: CVPR (2017) 18 Songet al
2017
-
[38]
OpenAI: Using gpt-5 (gpt-5 model family) — openai api documentation.https: //developers.openai.com/api/docs/guides/latest-model/
-
[39]
Pro- ceedings of the Royal Society of London58, 240–242 (1895)
Pearson, K.: Note on regression and inheritance in the case of two parents. Pro- ceedings of the Royal Society of London58, 240–242 (1895)
-
[40]
In: ICCV (2023)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
2023
-
[41]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
In: CVPR (2022)
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
2022
-
[44]
In: MICCAI (2015)
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomed- ical image segmentation. In: MICCAI (2015)
2015
-
[45]
NeurIPS (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. NeurIPS (2022)
2022
-
[46]
In: ICML (2023)
Salman, H., Khaddaj, A., Leclerc, G., Ilyas, A., Madry, A.: Raising the cost of malicious ai-powered image editing. In: ICML (2023)
2023
-
[47]
In: USENIX Secu- rity (2023)
Shan, S., Cryan, J., Wenger, E., Zheng, H., Hanocka, R., Zhao, B.Y.: Glaze: Pro- tecting artists from style mimicry by{Text-to-Image}models. In: USENIX Secu- rity (2023)
2023
-
[48]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Singer, U., Polyak, A., Hayes, T., Yin, X., An, J., Zhang, S., Hu, Q., Yang, H., Ashual, O., Gafni, O., et al.: Make-a-video: Text-to-video generation without text- video data. arXiv preprint arXiv:2209.14792 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[50]
The American Journal of Psychology15(1), 72–101 (1904).https://doi.org/10
Spearman, C.: The proof and measurement of association between two things. The American Journal of Psychology15(1), 72–101 (1904).https://doi.org/10. 2307/1412159
1904
-
[51]
MAGI-1: Autoregressive Video Generation at Scale
Teng, H., Jia, H., Sun, L., Li, L., Li, M., Tang, M., Han, S., Zhang, T., Zhang, W., Luo, W., et al.: Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Information fusion64, 131–148 (2020)
Tolosana, R., Vera-Rodriguez, R., Fierrez, J., Morales, A., Ortega-Garcia, J.: Deep- fakes and beyond: A survey of face manipulation and fake detection. Information fusion64, 131–148 (2020)
2020
-
[53]
NeurIPS (2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. NeurIPS (2017)
2017
-
[54]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Villegas, R., Babaeizadeh, M., Kindermans, P.J., Moraldo, H., Zhang, H., Saffar, M.T., Castro, S., Kunze, J., Erhan, D.: Phenaki: Variable length video generation from open domain textual description. arXiv preprint arXiv:2210.02399 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
NeurIPS (2023)
Wang, X., Yuan, H., Zhang, S., Chen, D., Wang, J., Zhang, Y., Shen, Y., Zhao, D., Zhou, J.: Videocomposer: Compositional video synthesis with motion control- lability. NeurIPS (2023)
2023
-
[57]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[58]
arXiv preprint arXiv:2310.11986 (2023)
Weidinger, L., Rauh, M., Marchal, N., Manzini, A., Hendricks, L.A., Mateos- Garcia, J., Bergman, S., Kay, J., Griffin, C., Bariach, B., et al.: Sociotechnical safety evaluation of generative ai systems. arXiv preprint arXiv:2310.11986 (2023)
-
[59]
In: ICCV (2023)
Wu, J.Z., Ge, Y., Wang, X., Lei, S.W., Gu, Y., Shi, Y., Hsu, W., Shan, Y., Qie, X., Shou, M.Z.: Tune-a-video: One-shot tuning of image diffusion models for text- to-video generation. In: ICCV (2023)
2023
-
[60]
In: ECCV (2024)
Xing,J.,Xia,M.,Zhang,Y.,Chen,H.,Yu,W.,Liu,H.,Liu,G.,Wang,X.,Shan,Y., Wong, T.T.: Dynamicrafter: Animating open-domain images with video diffusion priors. In: ECCV (2024)
2024
-
[61]
In: ICLR (2025)
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. In: ICLR (2025)
2025
-
[62]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
In: EMNLP (2023)
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. In: EMNLP (2023)
2023
-
[64]
In: CVPR (2018)
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
2018
-
[65]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
Zhang, S., Wang, J., Zhang, Y., Zhao, K., Yuan, H., Qin, Z., Wang, X., Zhao, D., Zhou, J.: I2vgen-xl: High-quality image-to-video synthesis via cascaded diffusion models. arXiv preprint arXiv:2311.04145 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y., Zhang, F., Gu, L., Zhang, Y., He, J., Zheng, W.S., et al.: Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
NeurIPS (2023)
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. NeurIPS (2023)
2023
-
[68]
Open-Sora: Democratizing Efficient Video Production for All
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) 20 Songet al. 8 Efficiency Analysis Our implementation is designed to minimize computational overhead during pro- tection ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
First, provide up to three concrete observations with timestamps or frame indices
-
[71]
Then, and only then, assign a discrete score from 1 to 5 based only on those observations
-
[72]
Assign the lowest score supported by the observed evidence
-
[73]
If no clear failure is observed, assign 5
-
[74]
uncertain
If evidence is insufficient or ambiguous, set"uncertain": trueand use score 3
-
[75]
Do not speculate beyond what is visible
Output only valid JSON. Do not speculate beyond what is visible. Input Context Provided to the Model: –Video ID: $VIDEO_ID –Prompt (context only): $PROMPT_STR –Assume FIRST frame is the input image. –A sequence of sampled frames, each preceded by a textual marker such asFrame $FRAME_INDEX (t=$TIMESTAMP s) Dimension-Specific Fields Injected into the Shared...
-
[76]
Provide up to three concrete observations with timestamps or frame indices
-
[77]
Based only on those observations, assign the score
-
[78]
uncertain
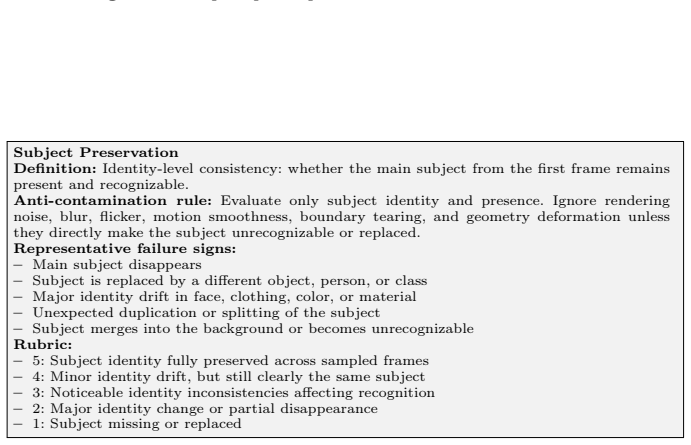
If uncertain due to insufficient evidence, set"uncertain": trueand use score 3. Required Output Schema: { "observations": [ {"time": "e.g., 2.0s or frame#25", "description": "what is visibly observed"} ], "score": 1, "uncertain": false } Fig. 9:Shared prompt template used for Video-LLM evaluator. Subject Preservation Definition:Identity-level consistency:...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.