What Does the Weight Norm Control in Grokking? Logit-Scale Mediation under Cross-Entropy
Pith reviewed 2026-06-27 00:41 UTC · model grok-4.3
The pith
Weight norm affects grokking delay only by setting the logit scale that controls softmax saturation under cross-entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
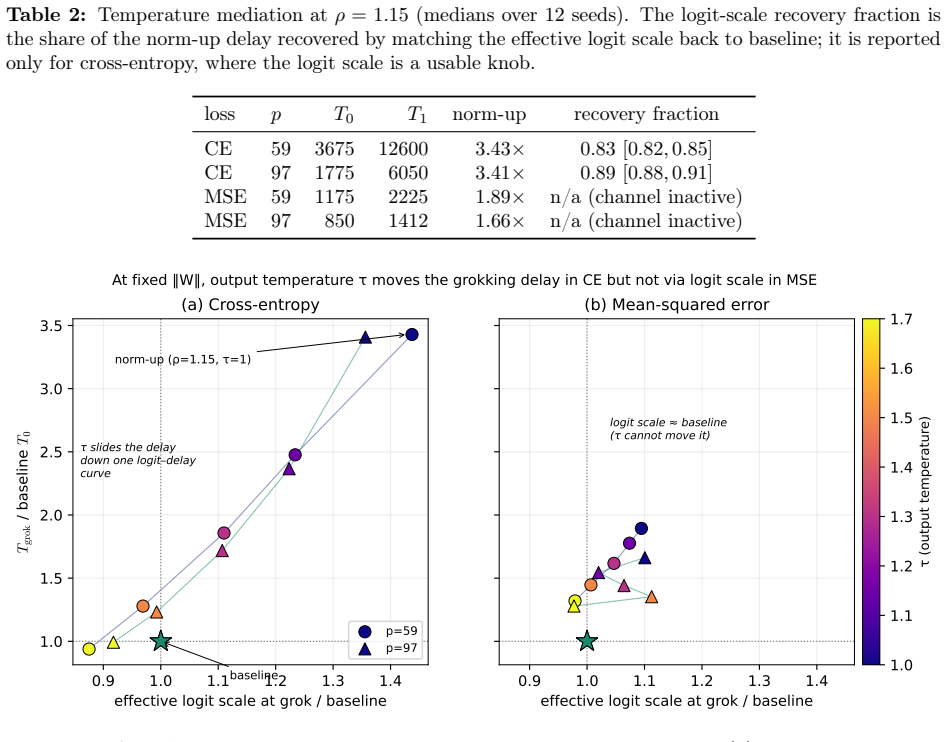
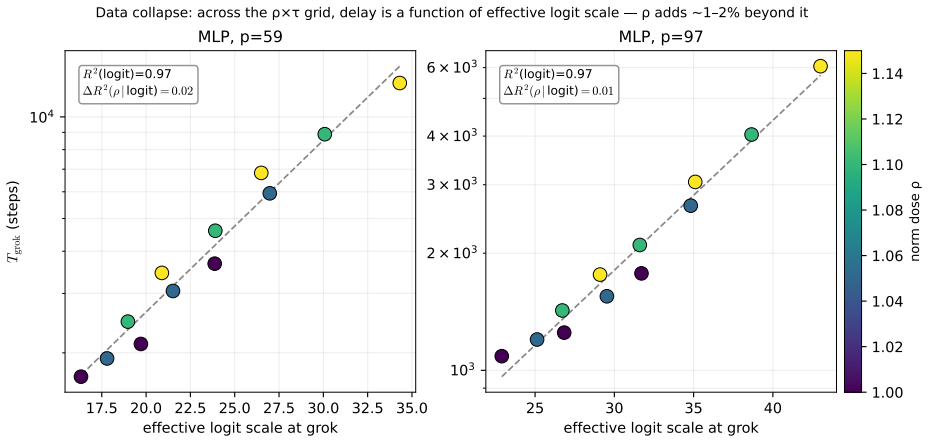
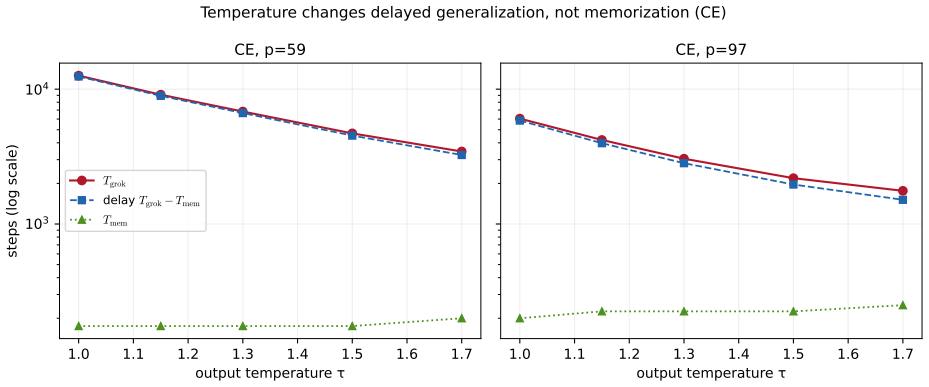
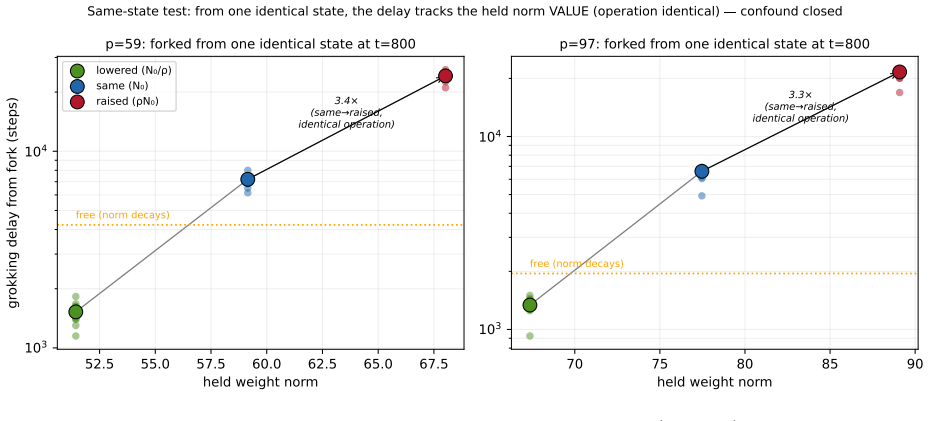
Across a grid of norms and temperatures the grokking delay collapses onto the logit scale alone (R2 = 0.97), with the norm adding 1-2% beyond it. Matching the effective logit scale back to baseline recovers about 85% of the delay at two moduli. The effect is loss-dependent: under mean-squared error the logit scale is pinned and the norm acts through a different route. A memorization control, a float64 softmax-collapse audit, and a no-LayerNorm transformer all point to the same channel. Forking arms from one identical state show the delay follows the held norm value and not the clamp operation itself.
What carries the argument
Logit-scale mediation: the effective scale of the output logits before the softmax, which determines saturation and thereby the timing of the memorization-to-generalization transition.
If this is right
- Under cross-entropy the weight norm functions mainly as an upstream controller of logit magnitude rather than acting directly on generalization.
- Temperature rescaling can be used to slide grokking timing across the range normally produced by norm changes.
- The mediation disappears under mean-squared error because the logit scale becomes fixed by the loss itself.
- The forking-arm result rules out the clamp operation as a source of the observed timing shifts.
Where Pith is reading between the lines
- Interventions that directly modulate output scale (temperature, final-layer scaling) may offer finer control over generalization timing than weight-norm penalties.
- The finding suggests testing whether other regularization effects in transformers are similarly routed through logit saturation rather than through weight magnitudes.
- If the mediation holds, then models trained with different norms but identical effective logit scales should exhibit statistically indistinguishable grokking curves.
Load-bearing premise
Clamping the weight norm while varying temperature cleanly isolates logit-scale effects without introducing other changes to optimization dynamics or model internals.
What would settle it
An experiment that matches logit scale across different clamped norms but still observes a large residual difference in grokking delay would falsify the claim that the scale is the dominant proximal variable.
Figures
read the original abstract
Grokking, the delayed jump from memorization to generalization, is usually tied to the weight norm: a smaller norm generalizes sooner. We ask what the norm actually controls. Holding the weight norm fixed by clamping and varying only an output temperature, we slide the grokking delay across its entire norm-induced range under cross-entropy; matching the effective logit scale back to baseline recovers about 85% of the delay at two moduli. Across a grid of norms and temperatures the delay collapses onto the logit scale alone (R2 = 0.97), with the norm adding 1-2% beyond it. The effect is loss-dependent: under mean-squared error the logit scale is pinned and the norm acts through a different route. A memorization control, a float64 softmax-collapse audit, and a no-LayerNorm transformer point to the same channel. Forking arms from one identical state, the delay follows the held norm value and not the clamp operation, which closes a rescaling-artifact concern. The proximal variable is the logit scale and the softmax saturation it drives; the weight norm is only an upstream handle. All numbers, tables, and figures reproduce from released code and data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under cross-entropy the weight norm influences grokking delay primarily via the effective logit scale and resulting softmax saturation. Clamping the norm and varying temperature slides the delay across its full norm-induced range; across a grid the delay collapses onto logit scale alone (R²=0.97) with norm adding only 1-2%. The effect is loss-dependent (absent under MSE). Controls include a memorization test, float64 softmax audit, no-LayerNorm transformer, and a forking-arms experiment from identical states showing delay tracks the held norm value rather than the clamp. All results are reproducible from released code and data.
Significance. If the mediation result holds, the work clarifies that weight norm is merely an upstream handle rather than the direct cause of delayed generalization, redirecting attention to logit-scale saturation mechanisms. The direct experimental manipulation at fixed norm, high R², multiple orthogonal controls, forking-arms artifact test, and full reproducibility via released code and data are notable strengths that would make this a solid contribution to the grokking literature.
major comments (1)
- [Abstract, forking-arms test] Abstract, forking-arms test: the experiment rules out rescaling artifacts from the clamp itself, but does not directly test whether the joint clamping-plus-temperature intervention alters gradient magnitudes, effective learning rates, or internal activation statistics in ways that could independently affect grokking delay. Because the central claim requires that the intervention cleanly isolates logit-scale effects, this leaves open the possibility that the R²=0.97 collapse is partly driven by correlated side effects rather than logit scale alone.
minor comments (1)
- [Abstract] Abstract: the statement that matching logit scale recovers 'about 85% of the delay at two moduli' would be clearer if the specific moduli and the exact matching procedure were stated.
Simulated Author's Rebuttal
We thank the referee for the positive overall assessment and for identifying this specific concern about whether the joint clamping-plus-temperature intervention cleanly isolates logit-scale effects. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract, forking-arms test] Abstract, forking-arms test: the experiment rules out rescaling artifacts from the clamp itself, but does not directly test whether the joint clamping-plus-temperature intervention alters gradient magnitudes, effective learning rates, or internal activation statistics in ways that could independently affect grokking delay. Because the central claim requires that the intervention cleanly isolates logit-scale effects, this leaves open the possibility that the R²=0.97 collapse is partly driven by correlated side effects rather than logit scale alone.
Authors: The forking-arms experiment forks models from an identical pre-intervention state and shows that subsequent grokking delay tracks the held norm value rather than any property of the clamping operation. Temperature scaling is a post-activation output adjustment that directly rescales logits without changing internal activations, parameter updates, or gradient flow through the network body. The observed collapse of delay onto logit scale (R²=0.97) across a full grid of clamped norms and temperatures, together with the complete absence of the effect under MSE (where logit scale remains pinned), makes it improbable that unmeasured side effects on gradients or activations are the primary driver; any such confounds would need to correlate almost perfectly with the computed logit scale. The no-LayerNorm control and float64 softmax audit provide further orthogonal support for the same channel. We will add a short clarifying paragraph in the discussion section acknowledging this isolation argument. revision: partial
Circularity Check
No circularity: empirical mediation via direct parameter variation
full rationale
The paper's claims rest on controlled experiments that clamp weight norm while varying output temperature, then measure grokking delay and regress it against logit scale (R²=0.97). No derivation chain, fitted parameter renamed as prediction, or self-citation is invoked to justify the central result; the forking-arms control and code reproducibility provide independent empirical grounding. The analysis is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Softmax saturation and cross-entropy loss depend on the magnitude of input logits
Reference graph
Works this paper leans on
-
[1]
The implicit bias of logit regularization.arXiv preprint arXiv:2602.12039,
Alon Beck, Yohai Bar-Sinai, and Noam Levi. The implicit bias of logit regularization.arXiv preprint arXiv:2602.12039,
- [2]
-
[3]
Kenzo Clauw, Sebastiano Stramaglia, and Daniele Marinazzo
arXiv:2505.20172. Kenzo Clauw, Sebastiano Stramaglia, and Daniele Marinazzo. Information-theoretic progress mea- sures reveal grokking is an emergent phase transition.arXiv preprint arXiv:2408.08944,
-
[4]
Grokking in the ising model.arXiv preprint arXiv:2510.25966,
Karolina Hutchison and David Yevick. Grokking in the ising model.arXiv preprint arXiv:2510.25966,
-
[5]
Ziming Liu, Eric J Michaud, and Max Tegmark
arXiv:2310.06110. Ziming Liu, Eric J Michaud, and Max Tegmark. Omnigrok: Grokking beyond algorithmic data. In International Conference on Learning Representations (ICLR),
- [6]
-
[7]
arXiv:1906.05890. Tiberiu Musat. The geometry of grokking: Norm minimization on the zero-loss manifold.arXiv preprint arXiv:2511.01938,
-
[8]
Progress measures for grokking via mechanistic interpretability
arXiv:2301.05217. Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Gen- eralization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Noa Rubin, Inbar Seroussi, and Zohar Ringel
arXiv:2501.04697. Noa Rubin, Inbar Seroussi, and Zohar Ringel. Grokking as a first order phase transition in two layer networks. InInternational Conference on Learning Representations (ICLR),
-
[10]
Vimal Thilak, Etai Littwin, Shuangfei Zhai, Omid Saremi, Roni Paiss, and Joshua Susskind
arXiv:2310.03789. Vimal Thilak, Etai Littwin, Shuangfei Zhai, Omid Saremi, Roni Paiss, and Joshua Susskind. The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon. arXiv preprint arXiv:2206.04817,
-
[11]
Vikrant Varma, Rohin Shah, Zachary Kenton, János Kramár, and Ramana Kumar
arXiv:2506.05718, PMLR 267:28552–28618. Vikrant Varma, Rohin Shah, Zachary Kenton, János Kramár, and Ramana Kumar. Explaining grokking through circuit efficiency.arXiv preprint arXiv:2309.02390,
-
[12]
Dimensional Criticality at Grokking Across MLPs and Transformers
Ping Wang. Dimensional criticality at grokking across mlps and transformers.arXiv preprint arXiv:2604.16431, 2026a. Ping Wang. Grokking as a dimensional phase transition in neural networks.arXiv preprint arXiv:2604.04655, 2026b. Bojan Žunkovič and Enej Ilievski. Grokking phase transitions in learning local rules with gradient descent.Journal of Machine Le...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.