5ting at SemEval-2026 Task 8: Strong End-to-End Multi-Turn RAG via LLM-Based Reranking and Faithfulness Control
Pith reviewed 2026-06-30 10:03 UTC · model grok-4.3
The pith
A multi-turn RAG system pairs dense retrieval and query merging with LLM reranking and evidence-constrained generation to reach competitive task scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
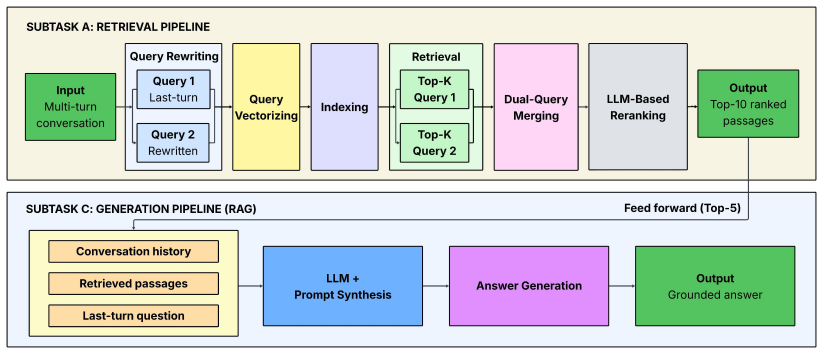
The 5ting system combines BGE-M3 dense retrieval with FAISS indexing, dual-query merged retrieval, and LLM-based reranking, followed by role-separated generation constrained to retrieved evidence. The retriever achieved nDCG@5 = 0.4719 in Task A, while the end-to-end system ranked in Task C with a harmonic score of 0.5597 and RL_F = 0.7692.
What carries the argument
LLM-based reranking followed by role-separated generation constrained to retrieved evidence, which limits output to passages supplied by the retriever.
If this is right
- Dual-query merging improves coverage of evolving user intents across conversation turns.
- Evidence-constrained generation lowers the rate of unsupported statements in multi-turn answers.
- Role separation between retrieval and generation steps maintains consistency when context drifts.
- The measured nDCG@5 and RL_F values indicate the pipeline meets the task criteria for relevance and faithfulness.
Where Pith is reading between the lines
- If the reranker is the main contributor, swapping it into other retrieval pipelines could raise their scores without retraining the entire stack.
- Testing the same pipeline on conversations longer than those in the SemEval data would show whether dual-query merging scales or saturates.
- Measuring how often the constrained generator still cites passages that the reranker down-ranked would quantify any hidden selection bias.
Load-bearing premise
The assumption that LLM-based reranking and evidence-constrained generation will reliably improve faithfulness without introducing new biases or errors from the reranker itself.
What would settle it
A side-by-side run in which removing the LLM reranker raises the faithfulness score or in which the constrained generator still produces claims absent from the retrieved evidence.
Figures
read the original abstract
We introduce 5ting, our system for the SemEval2026 Task 8 (MTRAGEval), which evaluates multi-turn Retrieval Augmented Generation (RAG) systems. Multi turn RAG involves context drift, under specification, and hallucination risk. Our system combines BGE-M3 dense retrieval with FAISS indexing, dual-query merged retrieval, and LLM based reranking, followed by role separated generation constrained to retrieved evidence. The retriever achieved nDCG@5 = 0.4719 in Task A, while the end to end system ranked in Task C with a harmonic score of 0.5597 and RL_F = 0.7692.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes the 5ting system submitted to SemEval-2026 Task 8 (MTRAGEval) for evaluating multi-turn Retrieval Augmented Generation. The pipeline combines BGE-M3 dense retrieval with FAISS indexing, dual-query merged retrieval, LLM-based reranking, and role-separated generation constrained to retrieved evidence. It reports a retriever nDCG@5 of 0.4719 on Task A and an end-to-end harmonic score of 0.5597 with RL_F of 0.7692 on Task C.
Significance. If the scores are reproducible and the components contribute as claimed, the work provides a competitive baseline for multi-turn RAG systems that attempt to mitigate context drift and hallucination via reranking and evidence constraints. As a shared-task system description, its value lies in the concrete ranking achieved rather than in novel theoretical contributions; however, the absence of component-level analysis limits insight into which elements drive the reported faithfulness control.
major comments (2)
- [Abstract / Results] Abstract and results section: the central claim that LLM-based reranking and evidence-constrained generation produce 'strong' end-to-end performance with faithfulness control rests on aggregate Task C scores (harmonic 0.5597, RL_F 0.7692) without any ablation (with vs. without reranker; with vs. without evidence constraint) or direct faithfulness metric (e.g., hallucination rate or citation accuracy). This makes it impossible to verify that the highlighted components are net positive rather than neutral.
- [Abstract] Abstract: no baselines, implementation details, or error analysis are supplied for the reported nDCG@5 = 0.4719 or the Task C metrics, so the robustness and statistical significance of the ranking cannot be assessed from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our shared-task system description. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the central claim that LLM-based reranking and evidence-constrained generation produce 'strong' end-to-end performance with faithfulness control rests on aggregate Task C scores (harmonic 0.5597, RL_F 0.7692) without any ablation (with vs. without reranker; with vs. without evidence constraint) or direct faithfulness metric (e.g., hallucination rate or citation accuracy). This makes it impossible to verify that the highlighted components are net positive rather than neutral.
Authors: We agree the manuscript provides only aggregate end-to-end scores without ablations or supplementary faithfulness metrics such as hallucination rate. As a SemEval system paper prepared under shared-task deadlines, our priority was delivering a working pipeline rather than component-wise experiments. The task-defined RL_F of 0.7692 serves as the primary faithfulness signal. We will revise the abstract to describe the results as 'competitive' rather than 'strong' and add a limitations paragraph explicitly noting the lack of ablations. revision: partial
-
Referee: [Abstract] Abstract: no baselines, implementation details, or error analysis are supplied for the reported nDCG@5 = 0.4719 or the Task C metrics, so the robustness and statistical significance of the ranking cannot be assessed from the manuscript.
Authors: The abstract is length-constrained; the body of the paper details the BGE-M3 + FAISS pipeline, dual-query merging, LLM reranking, and role-separated generation. No official task baselines were released for direct comparison, and we did not conduct statistical significance tests or error analysis. We will expand the methods and results sections with additional implementation specifics and a brief note on the absence of significance testing. revision: partial
- We cannot supply ablation results or additional direct faithfulness metrics because these experiments were not performed during the shared-task timeline.
Circularity Check
No circularity: purely empirical shared-task results with no derivations or self-referential claims
full rationale
The paper describes a RAG pipeline for SemEval-2026 Task 8 and reports aggregate empirical metrics (nDCG@5, harmonic score, RL_F) on an external benchmark. No equations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the provided text. All performance numbers are direct outputs of running the described system on the task data; nothing reduces to its own inputs by construction. This is the expected non-finding for a competition system paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transactions of the Association for Computational Linguistics , volume =
Evaluating Correctness and Faithfulness of Instruction-Following Models for Question Answering , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , url =. 2307.16877 , archivePrefix =
-
[3]
2020 , organization =
Dalton, Jeffrey and Xiong, Chenyan and Callan, Jamie , booktitle =. 2020 , organization =
2020
-
[4]
2024 , eprint =
Retrieval-Augmented Generation for Large Language Models: A Survey , author =. 2024 , eprint =
2024
-
[5]
Billion-Scale Similarity Search with
Johnson, Jeff and Douze, Matthijs and J. Billion-Scale Similarity Search with. IEEE Transactions on Big Data , volume =. 2019 , publisher =
2019
-
[6]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages =. 2020 , organization =
2020
-
[7]
Katsis, Yannis and Rosenthal, Sara and Fadnis, Kshitij and Gunasekara, Chulaka and Lee, Young-Suk and Popa, Lucian and Shah, Vraj and Zhu, Huaiyu and Contractor, Danish and Danilevsky, Marina , year =. 2501.03468 , archivePrefix =
-
[8]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[9]
2023 , eprint =
Zero-Shot Listwise Document Reranking with a Large Language Model , author =. 2023 , eprint =
2023
-
[10]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =
Exploiting Simulated User Feedback for Conversational Search: Ranking, Rewriting, and Beyond , author =. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2023 , organization =
2023
-
[12]
2026 , organization =
Rosenthal, Sara and Shah, Vraj and Katsis, Yannis and Danilevsky, Marina , booktitle =. 2026 , organization =
2026
-
[13]
Sun, Weiwei and Yan, Lingyong and Ma, Xinyu and Wang, Shuaiqiang and Ren, Pengjie and Chen, Zhumin and Yin, Dawei and Ren, Zhaochun , booktitle =. Is. 2023 , organization =
2023
-
[14]
Proceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM) , pages =
Question Rewriting for Conversational Question Answering , author =. Proceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM) , pages =. 2021 , organization =
2021
-
[15]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[17]
2024 , eprint =
Liu, Zihan and Ping, Wei and Roy, Rajarshi and Xu, Peng and Lee, Chankyu and Shoeybi, Mohammad and Catanzaro, Bryan , booktitle =. 2024 , eprint =
2024
-
[20]
2023 , eprint=
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze! , author=. 2023 , eprint=
2023
-
[21]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. https://arxiv.org/abs/2402.03216 BGE M3 -embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation . In Findings of the Association for Computational Linguistics: ACL 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. https://arxiv.org/abs/2312.10997 Retrieval-augmented generation for large language models: A survey . Preprint, arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Jeff Johnson, Matthijs Douze, and Herv \'e J \'e gou. 2019. Billion-scale similarity search with GPU s. IEEE Transactions on Big Data, 7(3):535--547
2019
-
[24]
Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lucian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, and Marina Danilevsky. 2025. https://doi.org/10.1162/TACL.a.19 mtrag: A multi-turn conversational benchmark for evaluating retrieval-augmented generation systems . Transactions of the Association for Computational Lingui...
- [25]
- [26]
-
[27]
Paul Owoicho, Ivan Sekuli \'c , Mohammad Aliannejadi, Jeffrey Dalton, and Fabio Crestani. 2023. Exploiting simulated user feedback for conversational search: Ranking, rewriting, and beyond. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 632--642. ACM
2023
-
[28]
Ronak Pradeep, Sahel Sharifymoghaddam, and Jimmy Lin. 2023. https://arxiv.org/abs/2312.02724 Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze! Preprint, arXiv:2312.02724
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [29]
-
[30]
Sara Rosenthal, Vraj Shah, Yannis Katsis, and Marina Danilevsky. 2026 b . SemEval -2026 task 8: MTRAGEval : Evaluating multi-turn RAG conversations. In Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026), San Diego, California. Association for Computational Linguistics
2026
-
[31]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. https://arxiv.org/abs/2304.09542 Is ChatGPT good at search? investigating large language models as re-ranking agents . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computati...
-
[32]
Svitlana Vakulenko, Shayne Longpre, Zhucheng Tu, and Raviteja Anantha. 2021. Question rewriting for conversational question answering. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining (WSDM), pages 355--363. ACM
2021
-
[33]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. https://doi.org/10.18653/v1/2024.acl-long.642 Improving text embeddings with large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897--11916, Bangkok, Thailand. Association f...
-
[34]
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024. https://doi.org/10.1145/3626772.3657813 A setwise approach for effective and highly efficient zero-shot ranking with large language models . In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.