Revisiting LLM Adaptation for 3D CT Report Generation: A Study of Scaling and Diagnostic Priors
Pith reviewed 2026-06-27 03:17 UTC · model grok-4.3
The pith
Freezing large LLMs and training only lightweight layers with diagnostic priors outperforms full fine-tuning for 3D CT report generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For LLMs of approximately 1B parameters and larger, freezing the LLM and training only a lightweight projection layer that conditions on multi-label diagnostic classification logits produces higher-quality reports from 3D CT volumes than full fine-tuning, with stronger out-of-domain generalization and substantially lower computational cost.
What carries the argument
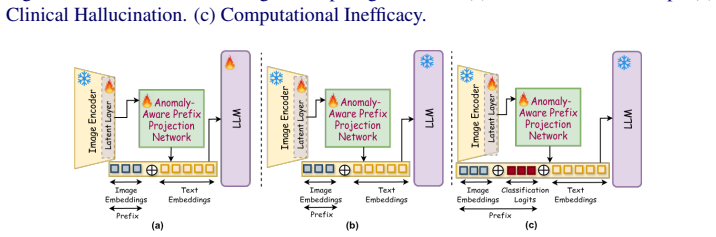
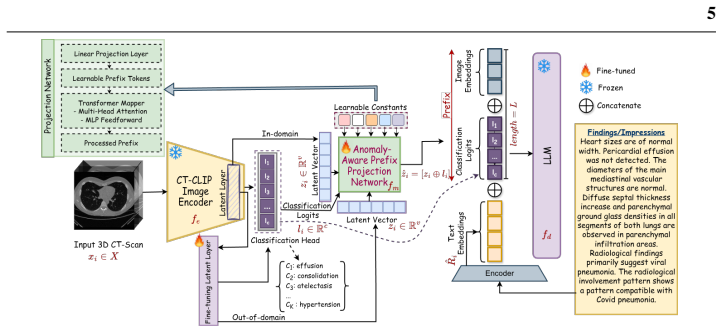
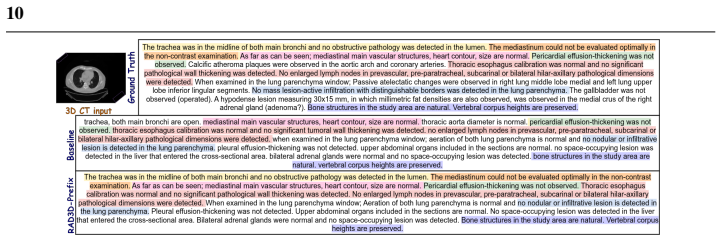
RAD3D-Prefix, a lightweight diagnostic-prior conditioning framework that combines image embeddings with multi-label diagnostic classification logits while the LLM remains frozen.
If this is right
- Fine-tuning the full LLM benefits smaller models most.
- Freezing larger LLMs reduces overfitting on limited medical data.
- RAD3D-Prefix achieves higher scores on automatic metrics and clinical reader evaluations than comparable baselines.
- The approach maintains strong performance on data from different distributions.
- Training requires substantially fewer parameters than full fine-tuning or other efficient methods.
Where Pith is reading between the lines
- The same conditioning strategy could extend to report generation from other 3D modalities such as MRI.
- Diagnostic priors might reduce hallucinations across additional medical text-generation settings.
- Lower parameter counts could make such systems practical in hospitals with limited GPU resources.
- Combining the frozen-LLM approach with even larger base models may further improve results without raising training costs.
Load-bearing premise
The multi-label diagnostic classification logits accurately capture and preserve critical clinical details without introducing classification errors or biases that affect the reports.
What would settle it
If a reader study or error analysis finds that reports produced with the diagnostic logits contain more clinically significant mistakes traceable to upstream classification errors than reports from fully fine-tuned models, the performance advantage would be falsified.
Figures
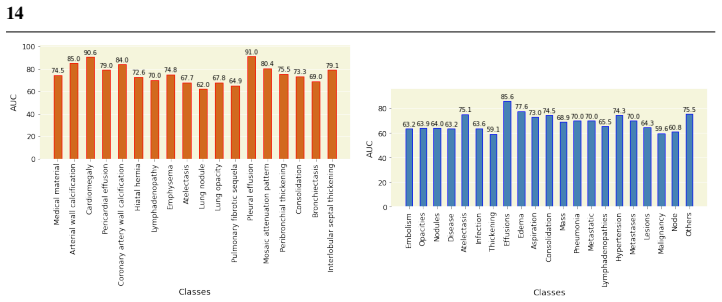




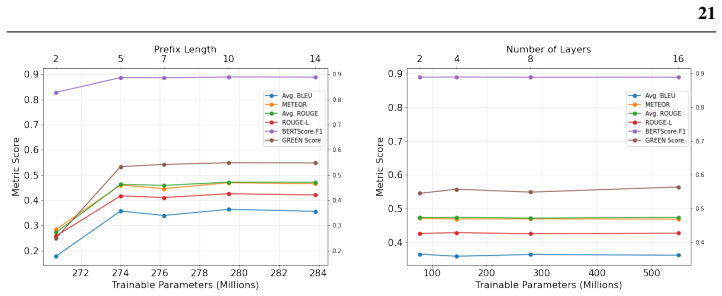
read the original abstract
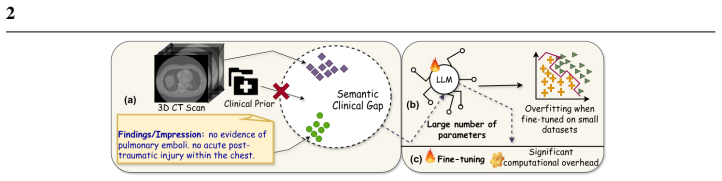
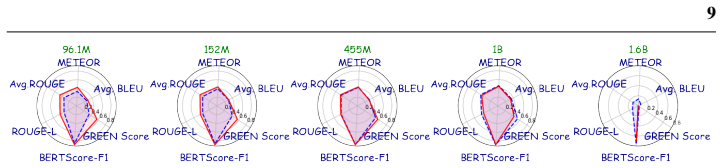
Recent advances in multimodal learning, including large language models (LLMs) and vision-language models (VLMs), have demonstrated strong adaptability to natural images. However, extending their use to the medical domain, particularly for volumetric (3D) images, is challenging due to high computational complexity, volumetric dependencies and the semantic gap between visual features and clinical terminology. Naively fine-tuning LLMs on limited medical data often leads to overfitting and clinical hallucination, where linguistic fluency is prioritized over clinical factuality. In this study, we investigate parameter-efficient adaptation strategies for volumetric CT report generation and introduce RAD3D-Prefix, a lightweight diagnostic-prior conditioning framework that minimizes the need for extensive parameter training. This module integrates image embeddings with multi-label diagnostic classification logits, preserving critical clinical details while bridging the semantic gap. By keeping the LLM frozen, our method requires minimal trainable parameters and mitigates the risk of overfitting on small, domain-specific datasets. Through a systematic study spanning LLMs from 96.1M to 1.6B parameters, we find that fine-tuning is most beneficial for smaller LLMs, whereas freezing larger (~1B+ LLMs and training only lightweight projection layers provides a superior trade-off between performance, generalization, and computational efficiency. Across multiple automatic metrics and a clinical reader study, RAD3D-Prefix outperforms comparable parameter-efficient baselines and demonstrates strong out-of-domain generalization while using substantially fewer trainable parameters than fully fine-tuned alternatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates parameter-efficient adaptation of LLMs for 3D CT radiology report generation. It introduces RAD3D-Prefix, a lightweight module that concatenates image embeddings with multi-label diagnostic classification logits to condition a frozen LLM, thereby minimizing trainable parameters and overfitting risk. Through scaling experiments on models ranging from 96.1M to 1.6B parameters, the central claim is that full fine-tuning benefits smaller LLMs while freezing larger (~1B+) LLMs and training only projection layers with the diagnostic prior yields superior performance, generalization, and efficiency trade-offs versus baselines, supported by automatic metrics and a clinical reader study.
Significance. If the empirical claims hold after addressing validation gaps, the work would offer actionable insights into LLM scaling for medical volumetric data, emphasizing diagnostic priors for semantic bridging and parameter efficiency. The systematic size sweep and reader study provide concrete evidence for the efficiency claims.
major comments (1)
- [Methods (RAD3D-Prefix) and Results] The claim that RAD3D-Prefix (image embeddings + multi-label diagnostic logits) provides a superior trade-off for ~1B+ LLMs rests on the logits accurately capturing clinical details without propagating errors. No section reports the upstream classifier's per-class precision/recall or error rate on the report-generation test split, and no ablation holds projection layers fixed while removing the logits component. This is load-bearing for the central scaling and generalization claims.
minor comments (2)
- [Abstract] Abstract supplies no dataset sizes, specific metric values, exclusion criteria, or error analysis, hindering immediate assessment of empirical robustness.
- [Abstract] The invented term RAD3D-Prefix is used without an explicit component breakdown or diagram reference on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The concern regarding validation of the diagnostic logits component is well-taken and directly relevant to the central claims about RAD3D-Prefix. We address it below and commit to revisions that strengthen the evidence.
read point-by-point responses
-
Referee: [Methods (RAD3D-Prefix) and Results] The claim that RAD3D-Prefix (image embeddings + multi-label diagnostic logits) provides a superior trade-off for ~1B+ LLMs rests on the logits accurately capturing clinical details without propagating errors. No section reports the upstream classifier's per-class precision/recall or error rate on the report-generation test split, and no ablation holds projection layers fixed while removing the logits component. This is load-bearing for the central scaling and generalization claims.
Authors: We agree that explicit reporting of the upstream multi-label classifier's performance on the report-generation test split is necessary to substantiate that the logits provide reliable clinical priors without substantial error propagation. The current manuscript does not include per-class precision, recall, or F1 scores for this classifier on the held-out test data, nor does it contain an ablation that isolates the logits contribution while holding the projection layers fixed. In the revised version we will add: (1) a dedicated subsection reporting the classifier's per-class and macro-averaged metrics on the test split, and (2) an ablation experiment that compares RAD3D-Prefix against an otherwise identical configuration using only image embeddings (projection layers fixed). These additions will allow readers to directly assess the incremental value and potential error contribution of the diagnostic logits. revision: yes
Circularity Check
No circularity: empirical comparisons rest on independent experimental results
full rationale
The paper reports an empirical study comparing LLM fine-tuning strategies and the RAD3D-Prefix module on 3D CT report generation tasks. All load-bearing claims (superior trade-offs for freezing larger LLMs, out-of-domain generalization, parameter efficiency) are justified by automatic metrics, ablation tables, and a clinical reader study rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-definitional loops, fitted-input predictions, or self-citation chains appear in the provided text; the diagnostic-logit component is an external input whose accuracy is assumed but not derived from the paper's own results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parameter-efficient adaptation of frozen LLMs can bridge the semantic gap between volumetric image features and clinical terminology without overfitting on small medical datasets
invented entities (1)
-
RAD3D-Prefix
no independent evidence
Reference graph
Works this paper leans on
-
[1]
METEOR: An automatic metric for MT eval- uation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT eval- uation with improved correlation with human judgments. In Jade Goldstein, Alon Lavie, Chin-Yew Lin, and Clare V oss, editors,Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Sum- marization, pages 65–72, Ann Arbor, Michi...
2005
-
[2]
Elliot Bolton, Abhinav Venigalla, Michihiro Yasunaga, David Hall, Betty Xiong, Tony Lee, Roxana Daneshjou, Jonathan Frankle, Percy Liang, Michael Carbin, et al. Biomedlm: A 2.7 b parameter language model trained on biomedical text.arXiv preprint arXiv:2403.18421, 2024
arXiv 2024
-
[3]
Language models are few-shot learners.Advances in neural information pro- cessing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Pra- fulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information pro- cessing systems, 33:1877–1901, 2020
1901
-
[4]
Zhixuan Chen, Yequan Bie, Haibo Jin, and Hao Chen. Large language model with region-guided referring and grounding for ct report generation.arXiv preprint arXiv:2411.15539, 2024
arXiv 2024
-
[5]
Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
Zhixuan Chen, Yequan Bie, Haibo Jin, and Hao Chen. Large language model with region-guided referring and grounding for ct report generation.IEEE Transactions on Medical Imaging, 2025
2025
-
[6]
Instructblip: towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: towards general-purpose vision-language models with instruction tuning. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[7]
Theo Di Piazza, Carole Lazarus, Olivier Nempont, and Loic Boussel. Ct-agrg: Automated abnormality-guided report generation from 3d chest ct volumes.arXiv preprint arXiv:2408.11965, 2024
arXiv 2024
-
[8]
From images to textual prompts: Zero-shot vi- sual question answering with frozen large language models
Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. From images to textual prompts: Zero-shot vi- sual question answering with frozen large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10867– 10877, 2023. 23
2023
-
[9]
A foundation model utilizing chest ct volumes and radiology reports for supervised-level zero-shot detection of abnormalities.CoRR, 2024
Ibrahim Ethem Hamamci, Sezgin Er, Furkan Almas, Ayse Gulnihan Simsek, Sev- val Nil Esirgun, Irem Dogan, Muhammed Furkan Dasdelen, Bastian Wittmann, Enis Simsar, Mehmet Simsar, et al. A foundation model utilizing chest ct volumes and radiology reports for supervised-level zero-shot detection of abnormalities.CoRR, 2024
2024
-
[10]
Ct2rep: Automated ra- diology report generation for 3d medical imaging
Ibrahim Ethem Hamamci, Sezgin Er, and Bjoern Menze. Ct2rep: Automated ra- diology report generation for 3d medical imaging. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 476–486. Springer, 2024
2024
-
[11]
Generatect: Text-conditional generation of 3d chest ct volumes
Ibrahim Ethem Hamamci, Sezgin Er, Anjany Sekuboyina, Enis Simsar, Alperen Tezcan, Ayse Gulnihan Simsek, Sevval Nil Esirgun, Furkan Almas, Irem Do ˘gan, Muhammed Furkan Dasdelen, et al. Generatect: Text-conditional generation of 3d chest ct volumes. InEuropean Conference on Computer Vision, pages 126–143. Springer, 2024
2024
-
[12]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[13]
Shih-Cheng Huang, Zepeng Huo, Ethan Steinberg, Chia-Chun Chiang, Matthew P Lungren, Curtis P Langlotz, Serena Yeung, Nigam H Shah, and Jason A Fries. In- spect: a multimodal dataset for pulmonary embolism diagnosis and prognosis.arXiv preprint arXiv:2311.10798, 2023
arXiv 2023
-
[14]
Unified language-vision pretraining in LLM with dynamic discrete visual tokenization
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jianchao Tan, Quzhe Huang, Bin CHEN, Chengru Song, dai meng, Di ZHANG, Wenwu Ou, Kun Gai, and Yadong MU. Unified language-vision pretraining in LLM with dynamic discrete visual tokenization. InThe Twelfth International Conference on Learning Represen- tations, 2024. URLhttps://openreview.net/forum?id=FlvtjAB0gl
2024
-
[15]
Vilt: Vision-and-language transformer without convolution or region supervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. InInternational conference on machine learning, pages 5583–5594. PMLR, 2021
2021
-
[16]
Haoran Lai, Zihang Jiang, Qingsong Yao, Rongsheng Wang, Zhiyang He, Xiaodong Tao, Wei Wei, Weifu Lv, and S Kevin Zhou. E3d-gpt: Enhanced 3d visual foundation for medical vision-language model.arXiv preprint arXiv:2410.14200, 2024
arXiv 2024
-
[17]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
2023
-
[18]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and genera- tion
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and genera- tion. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022. 24
2022
-
[19]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language mod- els
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language mod- els. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[20]
Dtllm-vlt: Diverse text generation for visual language tracking based on llm
Xuchen Li, Xiaokun Feng, Shiyu Hu, Meiqi Wu, Dailing Zhang, Jing Zhang, and Kaiqi Huang. Dtllm-vlt: Diverse text generation for visual language tracking based on llm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 7283–7292, 2024
2024
-
[21]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. As- sociation for Computational Linguistics. URLhttps://aclanthology.org/ W04-1013/
2004
-
[22]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[23]
Renqian Luo, Liai Sun, Yingce Xia, Tao Qin, Sheng Zhang, Hoifung Poon, and Tie- Yan Liu. BioGPT: generative pre-trained transformer for biomedical text generation and mining.Briefings in Bioinformatics, 23(6), 09 2022. ISSN 1477-4054. doi: 10.1093/bib/bbac409. URLhttps://doi.org/10.1093/bib/bbac409. bbac409
-
[24]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog
AI Meta. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog. Retrieved December, 20:2024, 2024
2024
-
[25]
Clipcap: Clip prefix for image captioning.arXiv preprint arXiv:2111.09734, 2021
Ron Mokady, Amir Hertz, and Amit H Bermano. Clipcap: Clip prefix for image captioning.arXiv preprint arXiv:2111.09734, 2021
arXiv 2021
-
[26]
Med-flamingo: a multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. Med-flamingo: a multimodal medical few-shot learner. InMachine Learning for Health (ML4H), pages 353–367. PMLR, 2023
2023
-
[27]
Chaudhari, and Jean-Benoit Delbrouck
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Chris- tian Bluethgen, Arne Edward Michalson Md, Michael Moseley, Curtis Langlotz, Akshay S Chaudhari, and Jean-Benoit Delbrouck. GREEN: Generative radiology report evaluation and error notation. In Yaser Al-Onaizan, Mohit Bansal, and Yun- Nung Chen, editors,Findings of the Associati...
-
[28]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Pierre Isabelle, Eugene Char- niak, and Dekang Lin, editors,Proceedings of the 40th Annual Meeting of the Asso- ciation for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Com...
-
[29]
Zero-shot text-to-image generation
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Rad- ford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. InInter- national conference on machine learning, pages 8821–8831. Pmlr, 2021
2021
-
[30]
Multitask prompted training enables zero-shot task generalization
Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, et al. Multitask prompted training enables zero-shot task generalization. InInternational Confer- ence on Learning Representations, 2021
2021
-
[31]
Yiming Shi, Xun Zhu, Ying Hu, Chenyi Guo, Miao Li, and Ji Wu. Med-2e3: A 2d-enhanced 3d medical multimodal large language model.arXiv preprint arXiv:2411.12783, 2024
arXiv 2024
-
[32]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[33]
R2gengpt: Radiology report generation with frozen llms.Meta-Radiology, 1(3):100033, 2023
Zhanyu Wang, Lingqiao Liu, Lei Wang, and Luping Zhou. R2gengpt: Radiology report generation with frozen llms.Meta-Radiology, 1(3):100033, 2023
2023
-
[34]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35: 24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35: 24824–24837, 2022
2022
-
[35]
Pubmed 2.0.Medical reference services quarterly, 39(4):382–387, 2020
Jacob White. Pubmed 2.0.Medical reference services quarterly, 39(4):382–387, 2020
2020
-
[36]
Bertscore: Evaluating text generation with bert
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. InInternational Conference on Learning Representations, 2019
2019
-
[37]
Xiaoman Zhang, Julián N Acosta, Hong-Yu Zhou, and Pranav Rajpurkar. Uncov- ering knowledge gaps in radiology report generation models through knowledge graphs.arXiv preprint arXiv:2408.14397, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.