JointHOI: Jointly Generating Contact Maps Enhances Hand Object Interaction Generation
Pith reviewed 2026-07-03 16:20 UTC · model grok-4.3
The pith
A single diffusion model jointly generates 3D hand-object motions and their evolving contact maps from text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
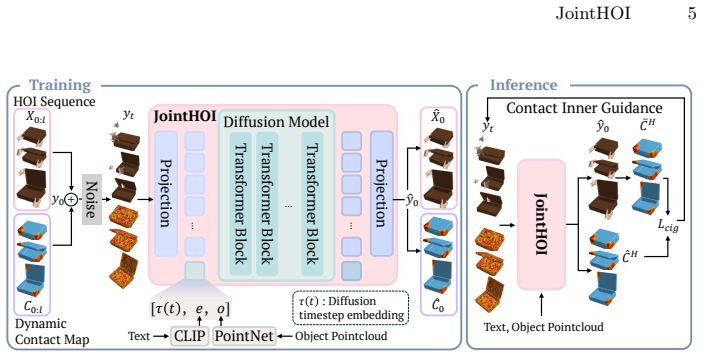
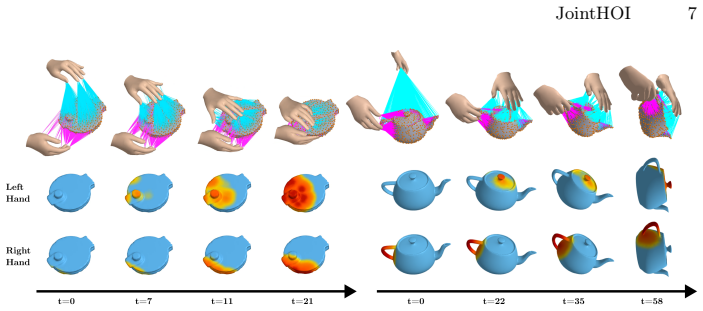
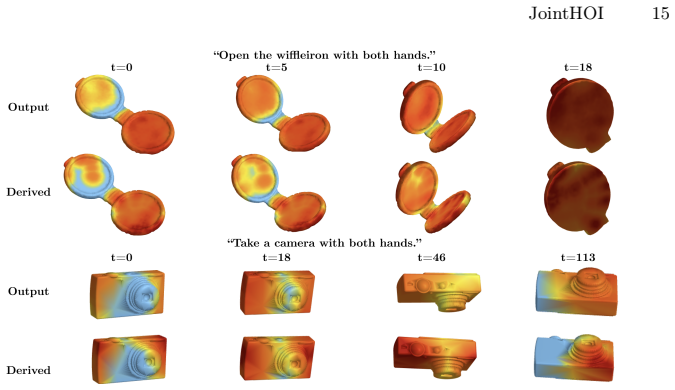
JointHOI is a single-stage diffusion framework that jointly generates 3D hand-object motion and dynamic, distance-based contact maps from text. Treating contact as an auxiliary modality lets the model learn the coupling between contact and motion during training. Contact-guided sampling at inference then enforces consistency between the generated contact maps and the geometry implied by the motion, improving temporal stability while reducing penetration and floating.
What carries the argument
Joint generation of 3D hand-object motion and distance-based contact maps inside one diffusion model, followed by contact-guided sampling that enforces geometric consistency at inference.
If this is right
- Joint training directly embeds contact-motion relationships in the learned distribution.
- Contact-guided sampling improves physical plausibility without requiring multi-stage pipelines or external grasp priors.
- Dynamic distance-based maps capture temporally evolving contacts rather than fixed cues.
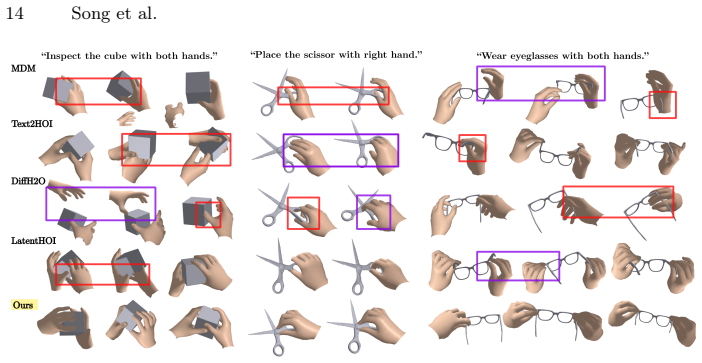
- The same single-stage model shows measurable gains in both text adherence and physical metrics on GRAB and ARCTIC.
Where Pith is reading between the lines
- The auxiliary-modality pattern could transfer to full-body or multi-object interaction generation.
- Contact maps might act as an editable intermediate layer for post-generation correction of specific contacts.
- Accelerating the diffusion sampling while retaining the contact guidance could support real-time interactive use.
Load-bearing premise
Jointly modeling contact maps as an auxiliary modality during training will produce contact predictions usable at inference to enforce geometric consistency without new artifacts.
What would settle it
An experiment that measures whether contact-guided sampling fails to reduce measured penetration or floating relative to an identical model trained without the contact maps.
Figures

read the original abstract
Text driven hand object interaction (HOI) generation is gaining attention for immersive applications and robotics, yet producing physically plausible interactions remains challenging. Even when individual motions appear natural, small contact errors can cause conspicuous artifacts such as floating and interpenetration. Prior methods mitigate these issues using explicit contact cues or implicit grasp priors, but typically rely on multi stage pipelines and fail to model temporally evolving contact. We present JointHOI, a single stage diffusion framework that jointly generates 3D hand object motion and dynamic, distance based contact maps from text. By treating contact as an auxiliary inner modality, joint generation enables the model to learn contact motion coupling during training. At inference, contact guided sampling enforces consistency between generated contact maps and motion implied geometry, improving temporal stability and reducing penetration and floating. Experiments on GRAB and ARCTIC demonstrate consistent improvements in text adherence and physical plausibility over prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce JointHOI, a single-stage text-conditioned diffusion model that jointly generates 3D hand-object motion sequences and dynamic distance-based contact maps; at inference, contact-guided sampling is used to enforce geometric consistency between the predicted contacts and the motion-implied distances, yielding improved temporal stability and fewer penetration/floating artifacts on the GRAB and ARCTIC benchmarks.
Significance. If the joint distribution over motion and contact maps is sufficiently tight to support effective guidance without new artifacts, the single-stage formulation would simplify current multi-stage HOI pipelines while directly addressing a core failure mode (contact errors). Reproducible code or explicit equations for the joint forward process and guidance operator would strengthen the contribution.
major comments (2)
- [Method (joint diffusion and inference)] The central claim that contact-guided sampling remains single-stage and artifact-free rests on the learned joint distribution tightly coupling contact predictions to motion geometry. No equations are supplied for the joint forward diffusion process, the auxiliary loss weighting between motion and contact modalities, or the precise form of the guidance operator (gradient, classifier-free, or projection), making it impossible to verify that guidance does not collapse into an implicit multi-stage procedure at test time.
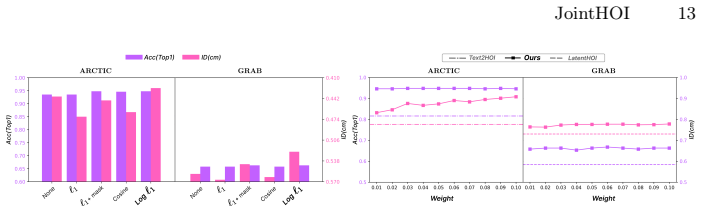
- [Experiments] Experiments section: without reported ablations that isolate the contribution of the auxiliary contact modality (e.g., joint vs. motion-only diffusion) and without quantitative metrics on contact accuracy versus penetration/floating reduction, the claimed improvements over prior methods cannot be assessed as load-bearing.
minor comments (2)
- [Abstract / §3] The distance metric underlying the 'distance-based contact maps' is never defined (Euclidean, signed, thresholded?).
- [Method] Notation for the contact map representation (per-vertex, per-joint, or voxelized) should be introduced explicitly before the joint diffusion equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify the technical details of JointHOI. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Method (joint diffusion and inference)] The central claim that contact-guided sampling remains single-stage and artifact-free rests on the learned joint distribution tightly coupling contact predictions to motion geometry. No equations are supplied for the joint forward diffusion process, the auxiliary loss weighting between motion and contact modalities, or the precise form of the guidance operator (gradient, classifier-free, or projection), making it impossible to verify that guidance does not collapse into an implicit multi-stage procedure at test time.
Authors: We acknowledge that the submitted manuscript omitted explicit equations for the joint forward process, loss weighting, and guidance operator. The revised version will add a dedicated methods subsection presenting the joint diffusion (motion and contact maps noised together in one forward process), the auxiliary loss term and its weighting, and the precise contact-guided sampling operator (a gradient-based consistency enforcement at inference). This formulation remains single-stage because the model is trained end-to-end on the joint distribution and the guidance uses only the learned model without additional trained components or separate stages. We will also release code upon acceptance to support reproducibility. revision: yes
-
Referee: [Experiments] Experiments section: without reported ablations that isolate the contribution of the auxiliary contact modality (e.g., joint vs. motion-only diffusion) and without quantitative metrics on contact accuracy versus penetration/floating reduction, the claimed improvements over prior methods cannot be assessed as load-bearing.
Authors: We agree that the current experimental section would benefit from additional controls. The revised manuscript will include an ablation comparing the full joint model against a motion-only diffusion baseline to isolate the auxiliary contact modality. We will also report quantitative contact accuracy metrics (e.g., contact map precision) alongside their correlation with measured reductions in penetration depth and floating distance on GRAB and ARCTIC. These results will be added to the Experiments section and tables. revision: yes
Circularity Check
No significant circularity; empirical modeling choice with no load-bearing derivations or self-referential reductions.
full rationale
The paper describes JointHOI as a diffusion-based generative model that jointly produces hand-object motion and distance-based contact maps from text, with contact-guided sampling applied at inference. No mathematical derivations, equations, or parameter-fitting steps are presented that reduce a claimed prediction to its own inputs by construction. No self-citations are used to justify uniqueness theorems or to import ansatzes. The approach is framed as an architectural and training choice whose benefits are demonstrated empirically on external datasets (GRAB, ARCTIC), rendering the chain self-contained without circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems37, 61872–61911 (2024)
Bachmann, R., Kar, O.F., Mizrahi, D., Garjani, A., Gao, M., Griffiths, D., Hu, J., Dehghan, A., Zamir, A.: 4m-21: An any-to-any vision model for tens of tasks and modalities. Advances in Neural Information Processing Systems37, 61872–61911 (2024)
work page 2024
-
[2]
Presence: teleoperators & virtual environments15(1), 1–15 (2006)
Burns, E., Razzaque, S., Panter, A.T., Whitton, M.C., McCallus, M.R., Brooks Jr, F.P.: The hand is more easily fooled than the eye: Users are more sensitive to visual interpenetration than to visual-proprioceptive discrepancy. Presence: teleoperators & virtual environments15(1), 1–15 (2006)
work page 2006
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Byung-Ki, K., Dai, Q., Hyoseok, L., Luo, C., Oh, T.H.: Jointdit: Enhancing rgb-depth joint modeling with diffusion transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 25261–25271 (2025)
work page 2025
-
[4]
In: Proceedings of the IEEE/CVF international conference on computer vision
Cao, Z., Radosavovic, I., Kanazawa, A., Malik, J.: Reconstructing hand-object interactions in the wild. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 12417–12426 (2021)
work page 2021
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cha, J., Kim, J., Yoon, J.S., Baek, S.: Text2hoi: Text-guided 3d motion genera- tion for hand-object interaction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1577–1585 (2024)
work page 2024
-
[6]
In: Proceedings of the 42nd International Con- ference on Machine Learning
Chefer, H., Singer, U., Zohar, A., Kirstain, Y., Polyak, A., Taigman, Y., Wolf, L., Sheynin, S.: Videojam: Joint appearance-motion representations for enhanced motion generation in video models. In: Proceedings of the 42nd International Con- ference on Machine Learning. Proceedings of Machine Learning Research, vol. 267, pp. 7595–7616. PMLR (2025)
work page 2025
-
[7]
In: SIGGRAPH Asia 2024 Conference Papers
Christen, S., Hampali, S., Sener, F., Remelli, E., Hodan, T., Sauser, E., Ma, S., Tekin, B.: Diffh2o: Diffusion-based synthesis of hand-object interactions from tex- tual descriptions. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
work page 2024
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Diller, C., Dai, A.: Cg-hoi: Contact-guided 3d human-object interaction generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19888–19901 (2024)
work page 2024
-
[9]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Fan, Z., Taheri, O., Tzionas, D., Kocabas, M., Kaufmann, M., Black, M.J., Hilliges, O.: Arctic: A dataset for dexterous bimanual hand-object manipulation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12943–12954 (2023)
work page 2023
-
[10]
Ghosh,A.,Dabral,R.,Golyanik,V.,Theobalt,C.,Slusallek,P.:Imos:intent-driven full-body motion synthesis for human-object interactions. In: Computer Graphics Forum. vol. 42, pp. 1–12. Wiley Online Library (2023)
work page 2023
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grady, P., Tang, C., Twigg, C.D., Vo, M., Brahmbhatt, S., Kemp, C.C.: Contac- topt: Optimizing contact to improve grasps. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1471–1481 (2021)
work page 2021
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hassan, M., Stapf, S., Rahimi, A., Rezende, P., Haghighi, Y., Brüggemann, D., Katircioglu,I.,Zhang,L.,Chen,X.,Saha,S.,etal.:Gem:Ageneralizableego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22404–22415 (2025)
work page 2025
-
[13]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Huang, M., Chu, F.J., Tekin, B., Liang, K.J., Ma, H., Wang, W., Chen, X., Gleize, P., Xue, H., Lyu, S., et al.: Hoigpt: Learning long-sequence hand-object interac- tion with language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7136–7146 (2025) JointHOI 17
work page 2025
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reason- ing for human grasps generation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11107–11116 (2021)
work page 2021
-
[15]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Karunratanakul, K., Preechakul, K., Aksan, E., Beeler, T., Suwajanakorn, S., Tang, S.: Optimizing diffusion noise can serve as universal motion priors. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 1334–1345 (2024)
work page 2024
-
[16]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[17]
Advances in Neural Information Processing Systems (2025)
Kouzelis, T., Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Boosting generative image modeling via joint image-feature synthesis. Advances in Neural Information Processing Systems (2025)
work page 2025
-
[18]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Krishnan, A., Yan, X., Casser, V., Kundu, A.: Orchid: Image latent diffusion for joint appearance and geometry generation. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 28217–28227 (2025)
work page 2025
-
[19]
Kwon, M., Shin, J., Jung, J., Park, J., Uh, Y.: Jam-flow: Joint audio-motion syn- thesis with flow matching (2025),https://arxiv.org/abs/2506.23552
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, M., Christen, S., Wan, C., Cai, Y., Liao, R., Sigal, L., Ma, S.: Latenthoi: On the generalizable hand object motion generation with latent hand diffusion. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17416–17425 (2025)
work page 2025
-
[21]
In: 2026 International Conference on 3D Vision (3DV)
Li, Z., Li, J., Gao, M., Yang, J., Wang, W., Zheng, F.: Conta-hoi: Towards phys- ically plausible human-object interaction generation via contact-aware modeling. In: 2026 International Conference on 3D Vision (3DV). pp. 946–955. IEEE (2026)
work page 2026
-
[22]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liu, S., Zhou, Y., Yang, J., Gupta, S., Wang, S.: Contactgen: Generative contact modeling for grasp generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20609–20620 (2023)
work page 2023
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, J., Clark, C., Lee, S., Zhang, Z., Khosla, S., Marten, R., Hoiem, D., Kembhavi, A.: Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26439–26455 (2024)
work page 2024
- [24]
-
[25]
Advances in Neural Information Pro- cessing Systems36, 58363–58408 (2023)
Mizrahi, D., Bachmann, R., Kar, O., Yeo, T., Gao, M., Dehghan, A., Zamir, A.: 4m: Massively multimodal masked modeling. Advances in Neural Information Pro- cessing Systems36, 58363–58408 (2023)
work page 2023
-
[26]
Advances in Neural Information Processing Systems38, 31758–31780 (2026)
Pi, H., Cen, Z., Dou, Z., Komura, T.: Coda: Coordinated diffusion noise opti- mization for whole-body manipulation of articulated objects. Advances in Neural Information Processing Systems38, 31758–31780 (2026)
work page 2026
-
[27]
In: 2012 IEEE Symposium on 3D User Interfaces (3DUI)
Prachyabrued, M., Borst, C.W.: Visual interpenetration tradeoffs in whole-hand virtual grasping. In: 2012 IEEE Symposium on 3D User Interfaces (3DUI). pp. 39–42. IEEE (2012)
work page 2012
-
[28]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 652–660 (2017)
work page 2017
-
[29]
arXiv preprint arXiv:2201.02610 (2022)
Romero, J., Tzionas, D., Black, M.J.: Embodied hands: Modeling and capturing hands and bodies together. arXiv preprint arXiv:2201.02610 (2022)
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ron, R., Tevet, G., Sawdayee, H., Bermano, A.: Hoidini: Human-object interaction through diffusion noise optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5739–5749 (2026) 18 Song et al
work page 2026
-
[31]
In: European conference on computer vision
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: Grab: A dataset of whole- body human grasping of objects. In: European conference on computer vision. pp. 581–600. Springer (2020)
work page 2020
-
[32]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=SJ1kSyO2jwu
work page 2023
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang,Z.,Chen,Y.,Jia,B.,Li,P.,Zhang,J.,Zhang,J.,Liu,T.,Zhu,Y.,Liang,W., Huang, S.: Move as you say interact as you can: Language-guided human motion generation with scene affordance. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 433–444 (2024)
work page 2024
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xue, M., Liu, Y., Guo, L., Huang, S., Ding, C.: Guiding human-object interactions with rich geometry and relations. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22714–22723 (2025)
work page 2025
-
[35]
Yu, L., Shi, B., ..., Aghajanyan, A.: Scaling autoregressive multi-modal models: Pretraining and instruction tuning (2023)
work page 2023
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, Q., Zhai, S., Martin, M.A.B., Miao, K., Toshev, A., Susskind, J., Gu, J.: World-consistent video diffusion with explicit 3d modeling. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21685–21695 (2025)
work page 2025
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zhang, W., Dabral, R., Golyanik, V., Choutas, V., Alvarado, E., Beeler, T., Haber- mann, M., Theobalt, C.: Bimart: A unified approach for the synthesis of 3d biman- ual interaction with articulated objects. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27694–27705 (2025)
work page 2025
-
[38]
In: European Conference on Computer Vision
Zhang, Z., Wang, H., Yu, Z., Cheng, Y., Yao, A., Chang, H.J.: Nl2contact: Nat- ural language guided 3d hand-object contact modeling with diffusion model. In: European Conference on Computer Vision. pp. 284–300. Springer (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.