SPOT-E: Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs
Pith reviewed 2026-06-26 17:48 UTC · model grok-4.3
The pith
SPOT-E shapes answer entropy with visual spotlights to improve evidence grounding in frozen VLMs at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that answer-span prediction entropy supplies usable internal feedback for test-time visual interventions in frozen VLMs, and that an entropy-shaping objective equipped with low-entropy anchors resolves the ambiguity between evidence-grounded low entropy and shortcut-induced low entropy, thereby producing optimized question-conditioned spotlights that raise performance on evidence-intensive tasks.
What carries the argument
The entropy-shaping objective with low-entropy anchors, realized as GRPO-optimized question-conditioned visual spotlights inside the SPOT-E plug-and-play procedure.
If this is right
- SPOT-E produces consistent performance gains across multiple benchmarks and different VLM families.
- The method increases robustness when input images undergo visual corruptions.
- No retraining of the base VLM is required because optimization occurs at test time per instance.
- The approach supplies a verification mechanism that the highlighted visual evidence is actually used by the model.
Where Pith is reading between the lines
- The same entropy-shaping principle could be tested on other localized-feature tasks such as fine-grained classification or medical image reading.
- Per-instance spotlight optimization may combine with existing open-loop visual interventions to produce additive gains.
- Internal uncertainty signals might serve as a general supervisory cue for attention mechanisms in multimodal models beyond VLMs.
Load-bearing premise
That answer-span prediction entropy supplies an unambiguous internal signal separating evidence-grounded confidence from shortcut collapse and that the entropy-shaping objective with low-entropy anchors reliably resolves the ambiguity.
What would settle it
A set of instances where models reach low entropy via shortcuts rather than evidence; if SPOT-E then fails to raise grounding accuracy or selects non-evidence regions, the claim is falsified.
Figures

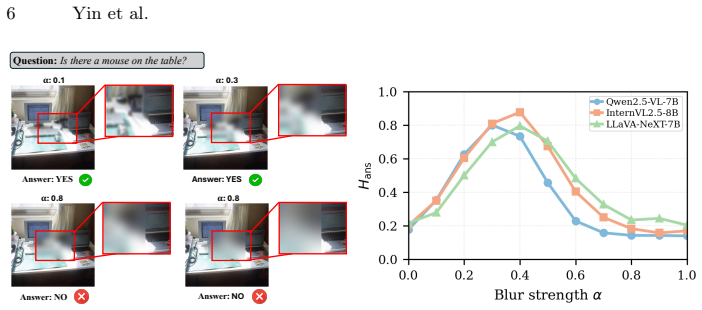

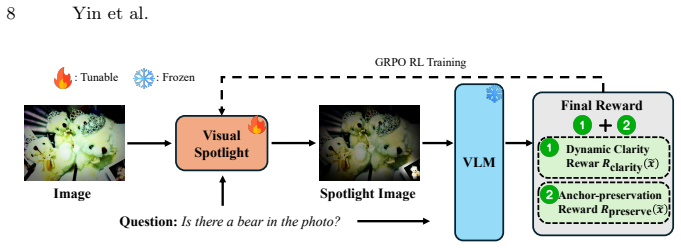
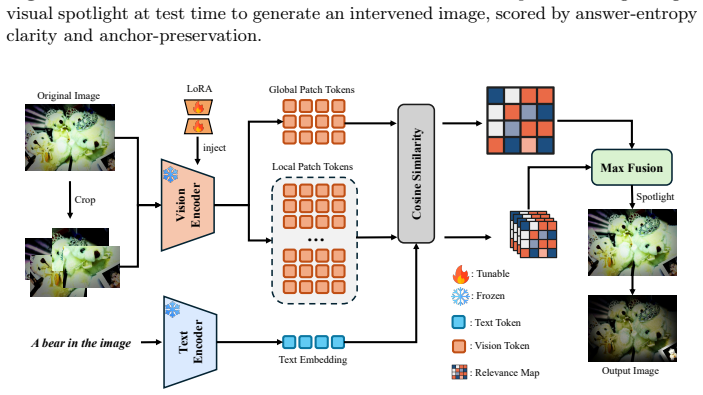
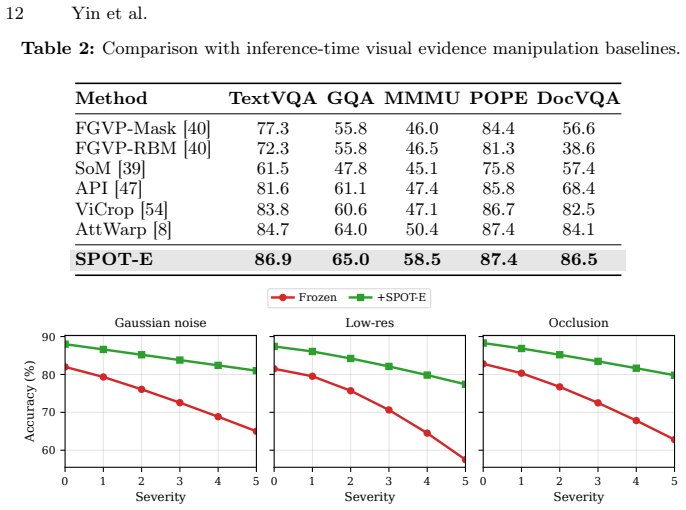
read the original abstract
Vision-language models (VLMs) often underperform on evidence intensive tasks because decisive visual evidence are small, localized, and easy to overlook, leading to failures in evidence readout even when high-level reasoning is intact. Prior inference-time visual interventions can improve grounding without retraining, but they are largely open-loop and lack a mechanism to verify whether highlighted evidence is actually used. We study answer-span prediction entropy as a model-internal feedback signal and show that naive entropy minimization is ambiguous, since low entropy may arise from evidence-grounded confidence or shortcut collapse. To resolve this ambiguity, we introduce low-entropy anchors and an entropy-shaping objective that reduces answer uncertainty while preserving baseline high-confidence tokens. We instantiate this principle in SPOT-E, a plug-and-play test-time method that produces question-conditioned spotlights, optimized per instance via light-weight tuning based on Group Relative Policy Optimization (GRPO). Across all benchmarks and different VLM families, SPOT-E yields consistent gains and improved robustness under visual corruptions. Code is publicly available at: https://github.com/YinBo0927/SPOT-E
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SPOT-E, a plug-and-play test-time method for frozen VLMs that treats answer-span prediction entropy as a model-internal feedback signal. It identifies ambiguity in naive entropy minimization (evidence-grounded confidence vs. shortcut collapse), introduces low-entropy anchors plus an entropy-shaping objective, and optimizes question-conditioned visual spotlights per instance via lightweight GRPO tuning. The central claim is that this yields consistent gains across benchmarks and VLM families together with improved robustness under visual corruptions.
Significance. If the mechanism and results hold, the work supplies a reproducible, training-free inference-time intervention that directly targets evidence readout failures in VLMs. Public code release strengthens the contribution for the community.
major comments (2)
- [Abstract] Abstract: the claim that low-entropy anchors plus the entropy-shaping objective resolve the stated ambiguity (low entropy from grounded evidence vs. shortcut collapse) is load-bearing for the central contribution, yet the manuscript supplies no controlled comparison isolating whether optimized spotlights increase evidence use versus enabling new low-entropy shortcuts.
- [Abstract] Abstract: the assertion of 'consistent gains across all benchmarks and different VLM families' and 'improved robustness under visual corruptions' is presented without reference to specific quantitative deltas, baseline comparisons, ablation results, or verification that the entropy objective resolves ambiguity, leaving the empirical support for the strongest claim unassessable from the provided text.
minor comments (1)
- The abstract introduces GRPO-based optimization but does not specify the reward formulation, number of optimization steps, or how the spotlight parameterization is constrained.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We agree that the abstract should more explicitly reference the supporting experiments and will revise it to improve clarity and assessability of the claims. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that low-entropy anchors plus the entropy-shaping objective resolve the stated ambiguity (low entropy from grounded evidence vs. shortcut collapse) is load-bearing for the central contribution, yet the manuscript supplies no controlled comparison isolating whether optimized spotlights increase evidence use versus enabling new low-entropy shortcuts.
Authors: We acknowledge that an explicit controlled comparison isolating evidence utilization versus shortcut formation would strengthen the mechanistic claim. The manuscript provides supporting evidence via ablations of the entropy-shaping objective versus naive minimization (showing differential behavior on evidence-intensive tasks), but does not include a direct isolation experiment such as occlusion-based evidence metrics. We will add such an analysis in the revision. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'consistent gains across all benchmarks and different VLM families' and 'improved robustness under visual corruptions' is presented without reference to specific quantitative deltas, baseline comparisons, ablation results, or verification that the entropy objective resolves ambiguity, leaving the empirical support for the strongest claim unassessable from the provided text.
Authors: We will revise the abstract to incorporate specific quantitative deltas (e.g., average improvements across benchmarks), explicit references to the relevant tables, figures, and ablation sections in the main text, and a concise statement on how the experiments support resolution of the ambiguity. This will make the empirical support directly assessable from the abstract. revision: yes
Circularity Check
No circularity: method uses external optimization signal without self-referential reduction
full rationale
The paper presents SPOT-E as a plug-and-play test-time procedure that optimizes question-conditioned spotlights via GRPO on an entropy-shaping objective with low-entropy anchors. No equations, derivations, or fitted parameters are shown that reduce any claimed prediction or result to the inputs by construction. The abstract explicitly distinguishes the proposed objective from naive entropy minimization and invokes an external RL-style optimizer rather than any self-fit or self-citation chain. The central empirical claim (consistent gains across benchmarks) is therefore not forced by definitional equivalence or load-bearing self-reference; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[2]
Advances in neural information processing systems35, 25005–25017 (2022)
Bar, A., Gandelsman, Y., Darrell, T., Globerson, A., Efros, A.: Visual prompt- ing via image inpainting. Advances in neural information processing systems35, 25005–25017 (2022)
2022
-
[3]
arXiv preprint arXiv:2407.21787 (2024)
Brown, B., Juravsky, J., Ehrlich, R., Clark, R., Le, Q.V., Ré, C., Mirhoseini, A.: Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787 (2024)
Pith/arXiv arXiv 2024
-
[4]
Advances in Neural Information Processing Sys- tems34, 15395–15407 (2021)
Carter, B., Jain, S., Mueller, J.W., Gifford, D.: Overinterpretation reveals image classification model pathologies. Advances in Neural Information Processing Sys- tems34, 15395–15407 (2021)
2021
-
[5]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, A., Yao, Y., Chen, P.Y., Zhang, Y., Liu, S.: Understanding and improving visual prompting: A label-mapping perspective. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19133–19143 (2023)
2023
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[7]
arXiv preprint arXiv:2507.06261 (2025)
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2510.09741 (2025)
Dalal, D., Vashishtha, G., Mishra, U., Kim, J., Kanda, M., Ha, H., Lazebnik, S., Ji, H., Jain, U.: Constructive distortion: Improving mllms with attention-guided image warping. arXiv preprint arXiv:2510.09741 (2025)
Pith/arXiv arXiv 2025
-
[9]
Nature Machine In- telligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine In- telligence2(11), 665–673 (2020)
2020
-
[10]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guan, T., Liu, F., Wu, X., Xian, R., Li, Z., Liu, X., Wang, X., Chen, L., Huang, F., Yacoob, Y., et al.: Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14375–14385 (2024)
2024
-
[11]
In: International conference on machine learning
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: International conference on machine learning. pp. 1321–1330. PMLR (2017)
2017
-
[12]
arXiv preprint arXiv:1610.02136 (2016)
Hendrycks, D., Gimpel, K.: A baseline for detecting misclassified and out-of- distribution examples in neural networks. arXiv preprint arXiv:1610.02136 (2016)
Pith/arXiv arXiv 2016
-
[13]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[14]
Hu, X., Qian, Y., Yu, J., Liu, J., Ji, X., Xu, C., Tang, P., Xu, C., Tang, P., Liu, J., et al.: The landscape of medical agents: A survey (2026)
2026
-
[15]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Q., Dong, X., Zhang, P., Wang, B., He, C., Wang, J., Lin, D., Zhang, W., Yu, N.: Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13418–13427 (2024) 16 Yin et al
2024
-
[16]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[17]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[18]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Jian, P., Wu, J., Sun, W., Wang, C., Ren, S., Zhang, J.: Look again, think slowly: Enhancing visual reflection in vision-language models. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 9262–9281 (2025)
2025
-
[19]
arXiv preprint arXiv:2207.05221 (2022)
Kadavath, S., Conerly, T., Askell, A., Henighan, T., Drain, D., Perez, E., Schiefer, N., Hatfield-Dodds, Z., DasSarma, N., Tran-Johnson, E., et al.: Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 (2022)
Pith/arXiv arXiv 2022
-
[20]
arXiv preprint arXiv:2302.09664 (2023)
Kuhn, L., Gal, Y., Farquhar, S.: Semantic uncertainty: Linguistic invari- ances for uncertainty estimation in natural language generation. arXiv preprint arXiv:2302.09664 (2023)
Pith/arXiv arXiv 2023
-
[21]
arXiv preprint arXiv:2604.23775 (2026)
Li, Q., Yin, B., Huang, W., Liu, R., Zou, B., Yu, R., Ye, J., Yu, W., Wang, X.: Vision-language-action safety: Threats, challenges, evaluations, and mechanisms. arXiv preprint arXiv:2604.23775 (2026)
Pith/arXiv arXiv 2026
-
[22]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023)
2023
-
[23]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[24]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., et al.: Mmbench: Is your multi-modal model an all-around player? In: European conference on computer vision. pp. 216–233. Springer (2024)
2024
-
[25]
arXiv preprint arXiv:2509.26165 (2025)
Liu, Y., Tang, H., Peng, J., Zhang, J., Ji, X., He, Q., Wu, W., Luo, D., Gan, Z., Zhu, J., et al.: Human-mme: A holistic evaluation benchmark for human-centric multimodal large language models. arXiv preprint arXiv:2509.26165 (2025)
arXiv 2025
-
[26]
arXiv preprint arXiv:2310.02255 (2023)
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.W., Galley, M., Gao, J.: Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. arXiv preprint arXiv:2310.02255 (2023)
Pith/arXiv arXiv 2023
-
[27]
In: Findings of the association for computational linguistics: ACL 2022
Masry, A., Do, X.L., Tan, J.Q., Joty, S., Hoque, E.: Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In: Findings of the association for computational linguistics: ACL 2022. pp. 2263–2279 (2022)
2022
-
[28]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Mathew, M., Karatzas, D., Jawahar, C.: Docvqa: A dataset for vqa on document images. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 2200–2209 (2021)
2021
-
[29]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[30]
arXiv preprint arXiv:2402.03300 (2024)
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024)
Pith/arXiv arXiv 2024
-
[31]
Advances in neural information processing systems36, 8634–8652 (2023) Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs 17
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: Lan- guage agents with verbal reinforcement learning. Advances in neural information processing systems36, 8634–8652 (2023) Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs 17
2023
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards vqa models that can read. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8317–8326 (2019)
2019
-
[33]
arXiv preprint arXiv:2408.03314 (2024)
Snell, C., Lee, J., Xu, K., Kumar, A.: Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314 (2024)
Pith/arXiv arXiv 2024
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578 (2024)
2024
-
[35]
arXiv preprint arXiv:2409.12191 (2024)
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
Pith/arXiv arXiv 2024
-
[36]
arXiv preprint arXiv:2203.11171 (2022)
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022)
Pith/arXiv arXiv 2022
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xing, Y., Hu, X., He, Q., Zhang, J., Yan, S., Lu, S., Jiang, Y.G.: Boosting reasoning in large multimodal models via activation replay. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19229–19240 (2026)
2026
-
[38]
Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., Hooi, B.: Can llms express their uncertainty?anempiricalevaluationofconfidenceelicitationinllms.arXivpreprint arXiv:2306.13063 (2023)
Pith/arXiv arXiv 2023
-
[39]
arXiv preprint arXiv:2310.11441 (2023)
Yang, J., Zhang, H., Li, F., Zou, X., Li, C., Gao, J.: Set-of-mark prompting un- leashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441 (2023)
Pith/arXiv arXiv 2023
-
[40]
Advances in Neural Information Processing Systems36, 24993–25006 (2023)
Yang, L., Wang, Y., Li, X., Wang, X., Yang, J.: Fine-grained visual prompting. Advances in Neural Information Processing Systems36, 24993–25006 (2023)
2023
-
[41]
arXiv preprint arXiv:2511.17979 (2025)
Yin, B., Hu, X., Zhou, X., Jiang, P.T., Liao, Y., Zhu, J., Zhang, J., Tai, Y., Wang, C., Yan, S.: Fera: Frequency-energy constrained routing for effective diffusion adap- tation fine-tuning. arXiv preprint arXiv:2511.17979 (2025)
arXiv 2025
-
[42]
arXiv preprint arXiv:2605.11882 (2026)
Yin,B.,Li,Q.,Wang,X.:On-policyself-evolutionviafailuretrajectoriesforagentic safety alignment. arXiv preprint arXiv:2605.11882 (2026)
Pith/arXiv arXiv 2026
-
[43]
arXiv preprint arXiv:2601.01966 (2026)
Yin, B., Li, Q., Yu, R., Wang, X.: Refinement provenance inference: Detecting llm- refined training prompts from model behavior. arXiv preprint arXiv:2601.01966 (2026)
arXiv 2026
-
[44]
arXiv preprint arXiv:2509.13240 (2025)
Yin, B., Yang, X., Wang, X.: Don’t forget the nonlinearity: Unlocking activation functions in efficient fine-tuning. arXiv preprint arXiv:2509.13240 (2025)
arXiv 2025
-
[45]
Science China Information Sciences67(12), 220105 (2024)
Yin, S., Fu, C., Zhao, S., Xu, T., Wang, H., Sui, D., Shen, Y., Li, K., Sun, X., Chen, E.: Woodpecker: Hallucination correction for multimodal large language models. Science China Information Sciences67(12), 220105 (2024)
2024
-
[46]
Yin, Z., Sun, Q., Guo, Q., Wu, J., Qiu, X., Huang, X.J.: Do large language models know what they don’t know? In: Findings of the association for Computational Linguistics: ACL 2023. pp. 8653–8665 (2023)
2023
-
[47]
In: European Conference on Computer Vision
Yu, R., Yu, W., Wang, X.: Attention prompting on image for large vision-language models. In: European Conference on Computer Vision. pp. 251–268. Springer (2024)
2024
-
[48]
arXiv preprint arXiv:2604.02029 (2026) 18 Yin et al
Yu, X., Chen, Z., He, Y., Fu, T., Yang, C., Xu, C., Ma, Y., Hu, X., Cao, Z., Xu, J., et al.: The latent space: Foundation, evolution, mechanism, ability, and outlook. arXiv preprint arXiv:2604.02029 (2026) 18 Yin et al
Pith/arXiv arXiv 2026
-
[49]
arXiv preprint arXiv:2602.00471 (2026)
Yu, X., Xu, C., Chen, Z., Yin, B., Yang, C., He, Y., Hu, Y., Zhang, J., Tan, C., Hu, X., et al.: Dual latent memory for visual multi-agent system. arXiv preprint arXiv:2602.00471 (2026)
Pith/arXiv arXiv 2026
-
[50]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, X., Xu, C., Chen, Z., Zhang, Y., Lu, S., Yang, C., Zhang, J., Yan, S., Hu, X.: Visual document understanding and reasoning: A multi-agent collaboration frame- work with agent-wise adaptive test-time scaling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12300–12311 (2026)
2026
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yu, X., Xu, C., Zhang, G., Chen, Z., Zhang, Y., He, Y., Jiang, P.T., Zhang, J., Hu, X., Yan, S.: Vismem: Latent vision memory unlocks potential of vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 31544–31555 (2026)
2026
-
[52]
arXiv preprint arXiv:2509.21789 (2025)
Yu, X., Xu, C., Zhang, G., He, Y., Chen, Z., Xue, Z., Zhang, J., Liao, Y., Hu, X., Jiang, Y.G., et al.: Visual multi-agent system: Mitigating hallucination snowballing via visual flow. arXiv preprint arXiv:2509.21789 (2025)
arXiv 2025
-
[53]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9556–9567 (2024)
2024
-
[54]
In: R0-FoMo: RobustnessofFew-shotandZero-shotLearninginLargeFoundationModels(2023)
Zhang, J., Khayatkhoei, M., Chhikara, P., Ilievski, F.: Visual cropping improves zero-shot question answering of multimodal large language models. In: R0-FoMo: RobustnessofFew-shotandZero-shotLearninginLargeFoundationModels(2023)
2023
-
[55]
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., Smola, A.: Multimodal chain- of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023) Test-Time Entropy Shaping with Visual Spotlights for Frozen VLMs 19 Appendix Overall, the appendix provides complementary support for SPOT-E from four aspects. First, the theoretical discussion c...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.