Unifying Data, Memory, and Compute Efficiency in LLM training: A Survey
Pith reviewed 2026-06-27 14:10 UTC · model grok-4.3
The pith
LLM training efficiency requires treating data, memory, and compute as one interacting system rather than isolated techniques.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
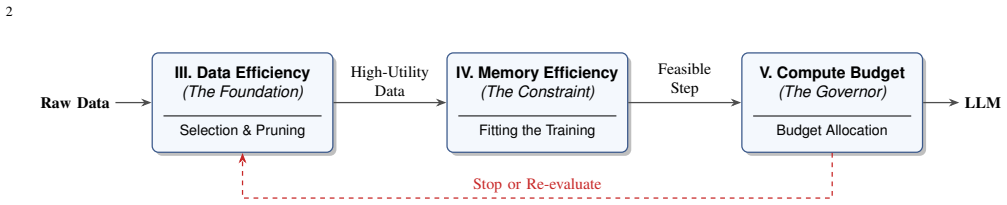
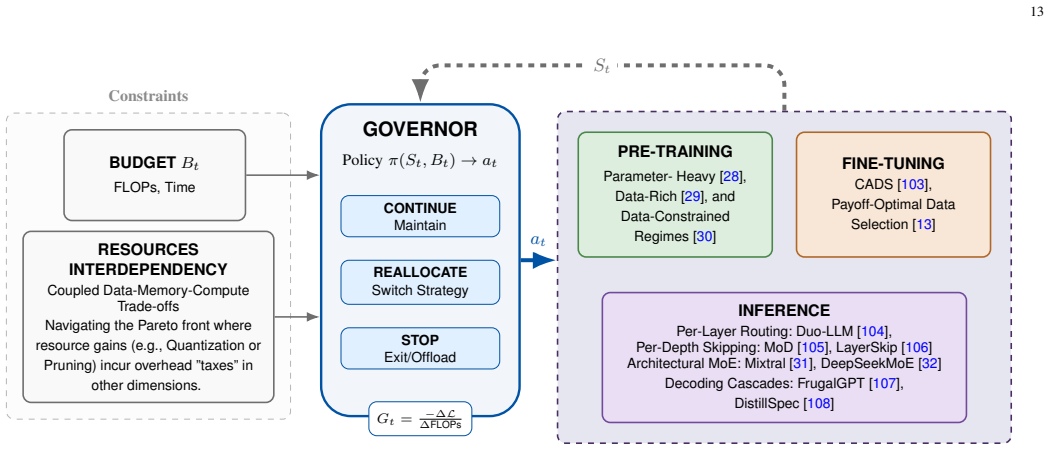
The paper establishes that efficiency in LLM training is best understood through a constraint-centric lens that couples data efficiency, memory efficiency, and compute budget awareness. It shows that different data-quality measures dominate under different regimes, that GPU memory often limits fine-tuning more than raw FLOPs, and that compute-optimal stopping and reallocation rules follow from marginal performance analysis.
What carries the argument
The constraint-centric perspective that treats the three bottlenecks—data, memory, and compute—as an interacting system requiring joint optimization.
If this is right
- Data selection methods must account for the specific task objective and resource budget rather than seeking universal high-quality subsets.
- Memory optimization in fine-tuning succeeds only when weight storage, optimizer states, and activation memory are reduced together.
- Compute should be halted or shifted once marginal gains drop below a threshold set by the available budget.
- Training and inference processes need explicit accounting for finite FLOP limits in their design.
Where Pith is reading between the lines
- Adaptive training systems could monitor current resource use in real time and switch data or optimization strategies on the fly.
- Hardware designs might prioritize balanced improvements in memory capacity and bandwidth alongside raw compute units.
- The framework points to testing whether joint optimization produces measurable gains on particular hardware setups compared with sequential, one-component-at-a-time approaches.
Load-bearing premise
The body of reviewed literature supplies enough evidence that data-quality notions change across regimes and that GPU memory is the dominant bottleneck that must be addressed through joint optimization of multiple components.
What would settle it
A side-by-side experiment that measures final model performance when data selection, memory techniques, and compute allocation are optimized jointly versus when each is chosen independently while holding total data volume, memory capacity, and FLOP budget fixed.
Figures


read the original abstract
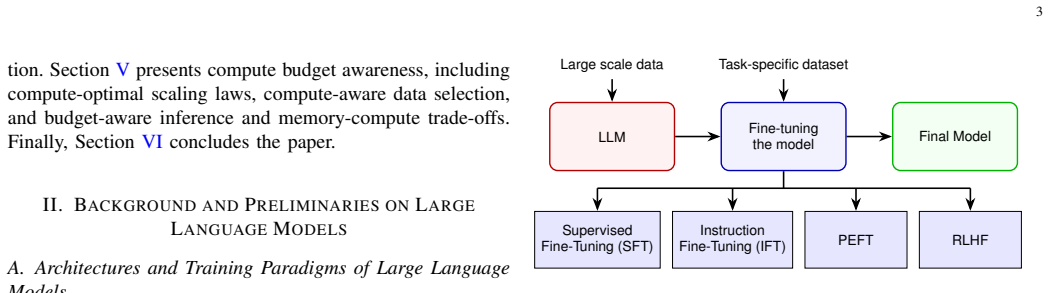
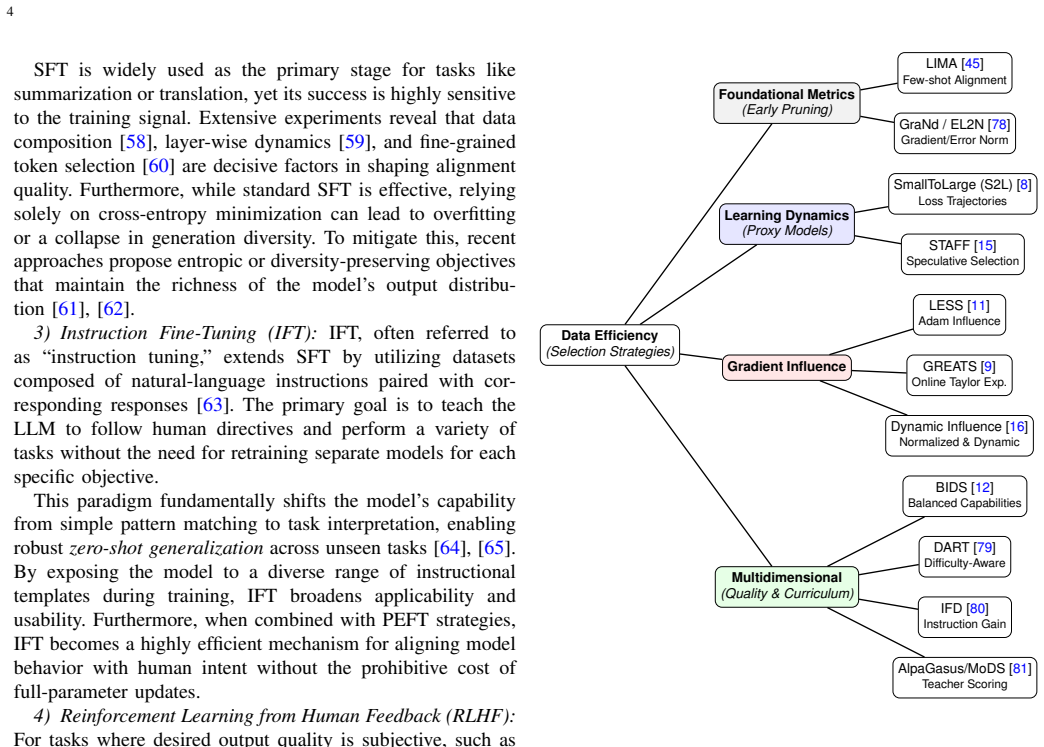
Resource constraints increasingly determine what can be trained, fine-tuned, and deployed in large language models (LLMs), yet efficiency is often studied through isolated techniques rather than as an interacting system of limits. This survey adopts a constraint-centric perspective and organizes recent progress around three coupled bottlenecks: data efficiency (what to train on), memory efficiency (how to fit training), and compute budget awareness (when and where to spend FLOPs). On the data axis, we review selection and pruning methods that maximize learning per token, ranging from scalable proxy signals based on learning dynamics to gradient- and influence-based scoring, as well as difficulty-aware and curriculum-style strategies. We highlight emerging evidence that different notions of good data dominate in different regimes, implying that optimal subsets depend on the task objective and resource budget rather than being universal. On the systems side, we show that GPU memory, not raw compute, is often the dominant bottleneck in fine-tuning, and that effective scaling requires jointly reducing weight storage, optimizer states, and activation memory rather than optimizing any single component in isolation. Beyond memory, we frame training and inference as compute-governed processes in which optimization, data selection, and decoding must explicitly account for finite FLOP budgets. We review evidence for compute-optimal allocation and stopping rules, where computation should be halted or reallocated once marginal performance gains fall below a budget-dependent threshold. Together, these results unify compute-aware data selection, scaling laws, and adaptive inference under a common principle of resource-conditioned decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey on LLM training efficiency that adopts a constraint-centric view, organizing the literature around three interacting bottlenecks: data efficiency (via selection, pruning, proxy signals, gradient/influence scoring, and curriculum strategies), memory efficiency (joint reduction of weights, optimizer states, and activations, noting GPU memory as the dominant fine-tuning bottleneck), and compute budget awareness (compute-optimal allocation, scaling laws, and stopping rules based on marginal gains). The central claim is that optimal strategies are regime- and budget-dependent rather than universal, unifying these areas under resource-conditioned decision-making.
Significance. If the coverage is comprehensive and the summaries of evidence accurate, the survey offers a useful organizing framework that could shift the field from isolated efficiency techniques toward holistic, interacting-system analyses. It draws on existing literature to highlight regime-dependent data quality and joint memory optimizations, providing a reference point for researchers balancing task objectives against resource constraints.
minor comments (2)
- [Abstract] Abstract: the single long paragraph is dense and would benefit from explicit subsection headings or bullets for the three axes (data, memory, compute) to improve scannability for readers.
- The survey would be strengthened by an explicit limitations or scope section clarifying which sub-areas of LLM efficiency (e.g., pre-training vs. fine-tuning, specific model scales) receive primary coverage versus lighter treatment.
Simulated Author's Rebuttal
We thank the referee for the constructive summary of the manuscript and for the positive evaluation of its significance as an organizing framework. The recommendation for minor revision is noted. No specific major comments were provided in the report.
Circularity Check
No significant circularity: survey organizes external literature without derivations or self-referential predictions
full rationale
This is a survey paper that reviews and synthesizes existing work on data, memory, and compute efficiency in LLM training. It adopts an organizing perspective drawn from the cited literature rather than advancing new equations, fitted parameters, or predictions. No load-bearing steps reduce by construction to the paper's own inputs, self-citations, or ansatzes; all reviewed techniques and evidence are external. The central claim that optimal choices depend on task and budget is presented as an organizing principle from the body of work, not a testable derivation internal to this manuscript.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Available: https://arxiv.org/abs/2401.00625
[Online]. Available: https://arxiv.org/abs/2401.00625
-
[3]
Palm: Scaling language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlinet al., “Palm: Scaling language modeling with pathways,”Journal of Machine Learning Research, vol. 24, pp. 11 324–11 436, 2023
2023
-
[4]
From words to watts: Benchmarking the energy costs of large language model inference,
S. Samsiet al., “From words to watts: Benchmarking the energy costs of large language model inference,” in2023 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 2023, pp. 1–9
2023
-
[5]
How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference,
N. Jeghamet al., “How hungry is ai? benchmarking energy, water, and carbon footprint of llm inference,”arXiv preprint arXiv:2505.09598, 2025
arXiv 2025
-
[6]
Green ai: exploring carbon footprints, mitigation strategies, and trade offs in large language model training,
V . Liu and Y . Yin, “Green ai: exploring carbon footprints, mitigation strategies, and trade offs in large language model training,”Discover Artificial Intelligence, vol. 4, no. 1, p. 49, 2024
2024
-
[7]
Data-centric green artificial intelligence: A survey,
S. Salehi and A. Schmeink, “Data-centric green artificial intelligence: A survey,”IEEE Transactions on Artificial Intelligence, vol. 5, no. 5, pp. 1973–1989, 2023
1973
-
[8]
Beyond neural scaling laws: beating power law scaling via data pruning,
B. Sorscher, R. Geirhos, S. Shekhar, S. Ganguli, and A. S. Morcos, “Beyond neural scaling laws: beating power law scaling via data pruning,” inProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 19 523–19 536
2022
-
[9]
Smalltolarge (s2l): Scalable data selection for fine-tuning large language models by summarizing training loss trajectories of small models,
Y . Yang, S. Mishra, J. Chiang, and B. Mirzasoleiman, “Smalltolarge (s2l): Scalable data selection for fine-tuning large language models by summarizing training loss trajectories of small models,” inProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024, paper 1
2024
-
[10]
Greats: Online selection of high-quality data for llm training in every iteration,
J. T. Wang, T. Wu, D. Song, P. Mittal, and R. Jia, “Greats: Online selection of high-quality data for llm training in every iteration,” in Proceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 131 197–131 223
2024
-
[11]
Disentangling the roles of representation and selection in data prun- ing,
Y . Du, Y . Song, H. M. Wong, D. Ignatev, A. Gatt, and D. Nguyen, “Disentangling the roles of representation and selection in data prun- ing,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 16 791–16 809
2025
-
[12]
Less: Se- lecting influential data for targeted instruction tuning,
M. Xia, S. Malladi, S. Gururangan, S. Arora, and D. Chen, “Less: Se- lecting influential data for targeted instruction tuning,” inProceedings of the 41st International Conference on Machine Learning (ICML), vol. 235, no. 2221, 2024, pp. 54 104 – 54 132
2024
-
[13]
Improving influence-based instruction tuning data selection for balanced learning of diverse capa- bilities,
Q. Dai, D. Zhang, J. W. Ma, and H. Peng, “Improving influence-based instruction tuning data selection for balanced learning of diverse capa- bilities,” inFindings of the Association for Computational Linguistics: EMNLP, 2025, pp. 7079–7102
2025
-
[14]
Compute-constrained data selection,
J. Yin and A. M. Rush, “Compute-constrained data selection,” in The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[15]
Llm data selection and utilization via dynamic bi-level optimization,
Y . Yu, K. Han, H. Zhou, Y . Tang, K. Huang, Y . Wang, and D. Tao, “Llm data selection and utilization via dynamic bi-level optimization,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[16]
Staff: Speculative coreset selection for task-specific fine-tuning,
X. Zhang, J. Zhai, S. Ma, C. Shen, T. Li, W. Jiang, and Y . Liu, “Staff: Speculative coreset selection for task-specific fine-tuning,” in The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[17]
Dynamic data selection with normalized gradient-based influence approximation for targeted fine-tuning of llms,
Z. Wang, Q. Zhu, F. Mi, Y . Wang, H. Wang, and L. Shang, “Dynamic data selection with normalized gradient-based influence approximation for targeted fine-tuning of llms,”Knowledge-Based Systems, vol. 327, p. 114144, 2025
2025
-
[18]
Training large neural networks with constant memory using a new execution algorithm,
M. Pudipeddi, Bharadwaj andkzet al., “Training large neural networks with constant memory using a new execution algorithm,” inarXiv preprint arXiv:2002.05645, 2020
arXiv 2002
-
[19]
Mini- batch coresets for memory-efficient language model training on data mixtures,
D. Nguyen, W. Yang, R. Anand, Y . Yang, and B. Mirzasoleiman, “Mini- batch coresets for memory-efficient language model training on data mixtures,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[20]
Addax: Utilizing zeroth-order gradients to improve memory efficiency and performance of sgd for fine-tuning language models,
Z. Li, Y . Deng, X. Zhang, M. Razaviyayn, P. Zhong, and V . Mirrokni, “Addax: Utilizing zeroth-order gradients to improve memory efficiency and performance of sgd for fine-tuning language models,” inThe Thir- teenth International Conference on Learning Representations (ICLR), 2025. 19
2025
-
[21]
Hift: A hierarchical full parameter fine-tuning strategy,
Y . Liu, Y . Zhang, Q. Li, T. Liu, S. Feng, D. Wang, Y . Zhang, and H. Sch ¨utze, “Hift: A hierarchical full parameter fine-tuning strategy,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 18 266–18 287
2024
-
[22]
Badam: A memory efficient full parameter optimization method for large language models,
Q. Luo, H. Yu, and X. Li, “Badam: A memory efficient full parameter optimization method for large language models,” inProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[23]
Galore: Memory-efficient llm training by gradient low-rank projec- tion,
J. Zhao, Z. Zhang, B. Chen, Z. Wang, A. Anandkumar, and Y . Tian, “Galore: Memory-efficient llm training by gradient low-rank projec- tion,” inProceedings of the 41st International Conference on Machine Learning (ICML), vol. 235, no. 2528, 2024, pp. 61 121–61 143
2024
-
[24]
Zeroth- order fine-tuning of llms in random subspaces,
Z. Yu, P. Zhou, S. Wang, J. Li, M. Tian, and H. Huang, “Zeroth- order fine-tuning of llms in random subspaces,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025, pp. 4475–4485
2025
-
[25]
Enhancing zeroth- order fine-tuning for language models with low-rank structures,
Y . Chen, Y . Zhang, L. Cao, K. Yuan, and Z. Wen, “Enhancing zeroth- order fine-tuning for language models with low-rank structures,” in The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[26]
Flashattention: Fast and memory-efficient exact attention with io-awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “Flashattention: Fast and memory-efficient exact attention with io-awareness,” inProceed- ings of the 36th Conference on Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 16 344–16 359
2022
-
[27]
Adazeta: Adaptive zeroth-order tensor-train adaption for memory- efficient large language models fine-tuning,
Y . Yang, K. Zhen, E. Banijamali, A. Mouchtaris, and Z. Zhang, “Adazeta: Adaptive zeroth-order tensor-train adaption for memory- efficient large language models fine-tuning,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024
2024
-
[28]
Direct quantized training of language models with stochastic rounding,
K. Zhao, T. Tabaru, K. Kobayashi, T. Honda, M. Yamazaki, and Y . Tsu- ruoka, “Direct quantized training of language models with stochastic rounding,” inAsian Conference on Machine Learning (ACML), 2025
2025
-
[29]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
Pith/arXiv arXiv 2001
-
[30]
Training compute-optimal large language models,
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. d. L. Casas, L. A. Hendricks, J. Welbl, A. Clarket al., “Training compute-optimal large language models,” inProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), 2022
2022
-
[31]
Scaling data-constrained language models,
N. Muennighoff, A. Rush, B. Barak, T. Le Scao, N. Tazi, A. Piktus, S. Pyysalo, T. Wolf, and C. A. Raffel, “Scaling data-constrained language models,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 50 358– 50 376
2023
-
[32]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bam- ford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand, G. Lengyel, G. Bour, G. Lample, L. R. Lavaud, L. Saulnier, M.-A. Lachaux, P. Stock, S. Subramanian, S. Yang, S. Antoniak, T. L. Scao, T. Gervet, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mixtral of experts,”arXiv pre...
Pith/arXiv arXiv 2024
-
[33]
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu, Z. Xie, Y . K. Li, P. Huang, F. Luo, C. Ruan, Z. Sui, and W. Liang, “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 1280–1297
2024
-
[34]
Not all tokens are what you need for pretraining,
Z. Lin, Z. Gou, Y . Gong, X. Liu, Y . Shen, R. Xu, C. Lin, Y . Yang, J. Jiao, N. Duan, and W. Chen, “Not all tokens are what you need for pretraining,” inProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[35]
Fast inference from transformers via speculative decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transformers via speculative decoding,” inProceedings of the 40th International Conference on Machine Learning (ICML), no. 795, 2023, pp. 19 274–19 286
2023
-
[36]
Accelerating large language model decoding with speculative sam- pling,
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sam- pling,”arXiv preprint arXiv:2302.01318, 2023
Pith/arXiv arXiv 2023
-
[37]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proceedings of the 31th Conference on Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[38]
Efficient estimation of word representations in vector space,
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” inThe First International Conference on Learning Representations (ICLR), 2013
2013
-
[39]
Mm1: methods, analysis and insights from multimodal llm pre-training,
B. McKinzie, Z. Gan, J.-P. Fauconnier, S. Dodge, B. Zhang, P. Dufter, D. Shah, X. Du, F. Peng, A. Belyiet al., “Mm1: methods, analysis and insights from multimodal llm pre-training,” inEuropean Conference on Computer Vision (ECCV), 2024, pp. 304–323
2024
-
[40]
Pythia: A suite for analyzing large language models across training and scaling,
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raffet al., “Pythia: A suite for analyzing large language models across training and scaling,” inProceedings of the 40th International Conference on Machine Learning (ICML), no. 102, 2023, pp. 2397–2430
2023
-
[41]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[42]
Stacking your transformers: A closer look at model growth for efficient llm pre-training,
W. Du, T. Luo, Z. Qiu, Z. Huang, Y . Shen, R. Cheng, Y . Guo, and J. Fu, “Stacking your transformers: A closer look at model growth for efficient llm pre-training,” inProceedings of the 38th Conference on Neural Information Processing Systems (NeurIPS), vol. 37, 2024, pp. 10 491–10 540
2024
-
[43]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 10 088–10 115
2023
-
[44]
Safety-tuned llamas: Lessons from im- proving the safety of large language models that follow instructions,
F. Bianchi, M. Suzgun, G. Attanasio, P. R ¨ottger, D. Jurafsky, T. Hashimoto, and J. Zou, “Safety-tuned llamas: Lessons from im- proving the safety of large language models that follow instructions,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[45]
Olmo: Accelerating the science of language models,
D. Groeneveld, I. Beltagy, E. Walsh, A. Bhagia, R. Kinney, O. Tafjord, A. Jha, H. Ivison, I. Magnusson, Y . Wanget al., “Olmo: Accelerating the science of language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 15 789–15 809
2024
-
[46]
Lima: Less is more for alignment,
C. Zhou, P. Liu, P. Xu, S. Iyer, J. Sun, Y . Mao, X. Ma, A. Efrat, P. Yu, L. Yuet al., “Lima: Less is more for alignment,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 55 006–55 021
2023
-
[47]
Amuro & char: Analyzing the relationship between pre-training and fine-tuning of large language models,
K. Sun and M. Dredze, “Amuro & char: Analyzing the relationship between pre-training and fine-tuning of large language models,” in Proceedings of the 10th Workshop on Representation Learning for NLP (RepL4NLP), 2025, pp. 131–151
2025
-
[48]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning,
A. Aghajanyan, S. Gupta, and L. Zettlemoyer, “Intrinsic dimensionality explains the effectiveness of language model fine-tuning,” inProceed- ings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021, pp. 7319–7328
2021
-
[49]
Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.-M. Chan, W. Chenet al., “Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models,”arXiv preprint arXiv:2203.06904, 2022
arXiv 2022
-
[50]
Compacter: Ef- ficient low-rank hypercomplex adapter layers,
R. Karimi Mahabadi, J. Henderson, and S. Ruder, “Compacter: Ef- ficient low-rank hypercomplex adapter layers,” inProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 1022–1035
2021
-
[51]
Prefix-tuning: Optimizing continuous prompts for generation,
X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021, pp. 4582– 4597
2021
-
[52]
Bitfit: Sim- ple parameter-efficient fine-tuning for transformer-based masked language-models,
E. Ben-Zaken, S. Ravfogel, and Y . Goldberg, “Bitfit: Sim- ple parameter-efficient fine-tuning for transformer-based masked language-models,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022, pp. 1–9
2022
-
[53]
Lora: Low-rank adaptation of large language models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” inThe Tenth International Conference on Learning Representations (ICLR), 2022
2022
-
[54]
Splitlora: A split parameter-efficient fine-tuning framework for large language models,
Z. Lin, X. Hu, Y . Zhang, Z. Chen, Z. Fang, X. Chen, A. Li, P. Vepakomma, and Y . Gao, “Splitlora: A split parameter-efficient fine-tuning framework for large language models,”arXiv preprint arXiv:2407.00952, 2024
arXiv 2024
-
[55]
Vera: Vector-based random matrix adaptation,
D. J. Kopiczko, T. Blankevoort, and Y . M. Asano, “Vera: Vector-based random matrix adaptation,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[56]
Unipelt: A unified framework for parameter-efficient language model tuning,
Y . Mao, L. Mathias, R. Hou, A. Almahairi, H. Ma, J. Han, S. Yih, and M. Khabsa, “Unipelt: A unified framework for parameter-efficient language model tuning,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022, pp. 6253– 6264. 20
2022
-
[57]
Advancing parameter efficiency in fine- tuning via representation editing,
M. Wu, W. Liu, X. Wang, T. Li, C. Lv, Z. Ling, Z. JianHao, C. Zhang, X. Zheng, and X.-J. Huang, “Advancing parameter efficiency in fine- tuning via representation editing,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 13 445–13 464
2024
-
[58]
Unveiling the secret recipe: A guide for supervised fine-tuning small llms,
A. Pareja, N. S. Nayak, H. Wang, K. Killamsetty, S. Sudalairaj, W. Zhao, S. Han, A. Bhandwaldar, G. Xu, K. Xuet al., “Unveiling the secret recipe: A guide for supervised fine-tuning small llms,” in The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[59]
How abilities in large language models are affected by supervised fine-tuning data composition,
G. Dong, H. Yuan, K. Lu, C. Li, M. Xue, D. Liu, W. Wang, Z. Yuan, C. Zhou, and J. Zhou, “How abilities in large language models are affected by supervised fine-tuning data composition,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024, pp. 177–198
2024
-
[60]
Massive supervised fine-tuning experiments reveal how data, layer, and training factors shape llm alignment quality,
Y . Harada, Y . Yamauchi, Y . Oda, Y . Oseki, Y . Miyao, and Y . Takagi, “Massive supervised fine-tuning experiments reveal how data, layer, and training factors shape llm alignment quality,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025, pp. 22 360–22 381
2025
-
[61]
Token cleaning: Fine-grained data selection for llm supervised fine-tuning,
J. Pang, N. Di, Z. Zhu, J. Wei, H. Cheng, C. Qian, and Y . Liu, “Token cleaning: Fine-grained data selection for llm supervised fine-tuning,” inProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[62]
Entropic distribution matching for supervised fine-tuning of llms: Less overfitting and better diversity,
Z. Li, C. Chen, T. Xu, Z. Qin, J. Xiao, R. Sun, and Z.-Q. Luo, “Entropic distribution matching for supervised fine-tuning of llms: Less overfitting and better diversity,” inNeurIPS 2024 Workshop on Fine- Tuning in Modern Machine Learning: Principles and Scalability, 2024
2024
-
[63]
Preserv- ing diversity in supervised fine-tuning of large language models,
Z. Li, C. Chen, T. Xu, Z. Qin, J. Xiao, Z.-Q. Luo, and R. Sun, “Preserv- ing diversity in supervised fine-tuning of large language models,” in The Thirteenth International Conference on Learning Representations (ICLR), 2025
2025
-
[64]
Cross-task generalization via natural language crowdsourcing instructions,
S. Mishra, D. Khashabi, C. Baral, and H. Hajishirzi, “Cross-task generalization via natural language crowdsourcing instructions,” in Proceedings of the 60th Annual Meeting of the Association for Com- putational Linguistics (ACL), 2022, pp. 3470–3487
2022
-
[65]
Finetuned language models are zero- shot learners,
J. Wei, M. Bosma, V . Y . Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V . Le, “Finetuned language models are zero- shot learners,” inThe Tenth International Conference on Learning Representations (ICLR), 2022
2022
-
[66]
Multitask prompted training enables zero-shot task generalization,
V . Sanh, A. Webson, C. Raffel, S. H. Bach, L. Sutawika, Z. Alyafeai, A. Chaffin, A. Stiegler, T. L. Scao, A. Rajaet al., “Multitask prompted training enables zero-shot task generalization,” inThe Tenth Interna- tional Conference on Learning Representations (ICLR), 2022
2022
-
[67]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” in Proceedings of the 31th Conference on Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[68]
Fine-tuning language models from human preferences,
D. M. Ziegler, N. Stiennon, J. Wu, T. B. Brown, A. Radford, D. Amodei, P. Christiano, and G. Irving, “Fine-tuning language models from human preferences,”arXiv preprint arXiv:1909.08593, 2019
Pith/arXiv arXiv 1909
-
[69]
Prox- imal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[70]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,” inProceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 27 730–27 744
2022
-
[71]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), vol. 36, 2023, pp. 53 728–53 741
2023
-
[72]
Preference ranking optimization for human alignment,
F. Song, B. Yu, M. Li, H. Yu, F. Huang, Y . Li, and H. Wang, “Preference ranking optimization for human alignment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 17, 2024, pp. 18 990– 18 998
2024
-
[73]
Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation,
H. Xu, A. Sharaf, Y . Chen, W. Tan, L. Shen, B. Van Durme, K. Murray, and Y . J. Kim, “Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation,” inProceedings of the 41st International Conference on Machine Learning (ICML), 2024, pp. 55 204 – 55 224
2024
-
[74]
Open problems and fundamental limitations of reinforcement learning from human feedback,
S. Casper, X. Davies, C. Shi, T. K. Gilbert, J. Scheurer, J. Rando, R. Freedman, T. Korbak, D. Lindner, P. Freire, T. Wang, M. Marks, C.-R. Segerie, E. Bıyık, A. Dragan, D. Krueger, D. Sadigh, and D. Hadfield-Menell, “Open problems and fundamental limitations of reinforcement learning from human feedback,”Transactions on Ma- chine Learning Research (TMLR), 2023
2023
-
[75]
H. Qi, Z. Dai, and C. Huang, “Hybrid and unitary fine-tuning of large language models: Methods and benchmarking under resource constraints,”arXiv preprint arXiv:2507.18076, 2025
arXiv 2025
-
[76]
Hybrid fine-tuning in large language model learning for machinery fault diagnosis,
Z. Pang, H. Zhang, and T. Li, “Hybrid fine-tuning in large language model learning for machinery fault diagnosis,” inIEEE 22nd Interna- tional Conference on Industrial Informatics (INDIN), 2024, pp. 1–6
2024
-
[77]
Hybrid fine- tuning of large language models using lora: Enhancing multi-task text classification through knowledge sharing,
A. Beiranvand, M. Sarhadi, and J. Salimi Sartakhti, “Hybrid fine- tuning of large language models using lora: Enhancing multi-task text classification through knowledge sharing,”Journal of Electrical and Computer Engineering Innovations (JECEI), vol. 13, no. 2, pp. 417– 430, 2025
2025
-
[78]
From bottom to top: Extending the potential of parameter efficient fine-tuning,
J. Gu, Z. Wang, Y . Zhang, Z. Zhang, and P. Gong, “From bottom to top: Extending the potential of parameter efficient fine-tuning,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 3488–3500
2024
-
[79]
Deep learning on a data diet: Finding important examples early in training,
M. Paul, S. Ganguli, and G. K. Dziugaite, “Deep learning on a data diet: Finding important examples early in training,” inProceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS), vol. 34, 2021, pp. 20 596–20 607
2021
-
[80]
Dart-math: Difficulty- aware rejection tuning for mathematical problem-solving,
Y . Tong, X. Zhang, R. Wang, R. Wu, and J. He, “Dart-math: Difficulty- aware rejection tuning for mathematical problem-solving,” inProceed- ings of the 38th Conference on Neural Information Processing Systems (NeurIPS), 2024, paper 5
2024
-
[81]
From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,
M. Li, Y . Zhang, Z. Li, J. Chen, L. Chen, N. Cheng, J. Wang, T. Zhou, and J. Xiao, “From quantity to quality: Boosting llm performance with self-guided data selection for instruction tuning,” inProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2024, p. 7602–7635
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.