NAVI-Orbital: First In-Orbit Demonstration of a Zero-Shot Vision-Language Model for Autonomous Earth Observation
Pith reviewed 2026-06-27 21:45 UTC · model grok-4.3
The pith
A vision-language model achieved the first in-orbit autonomous multi-modal inference on a LEO spacecraft without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
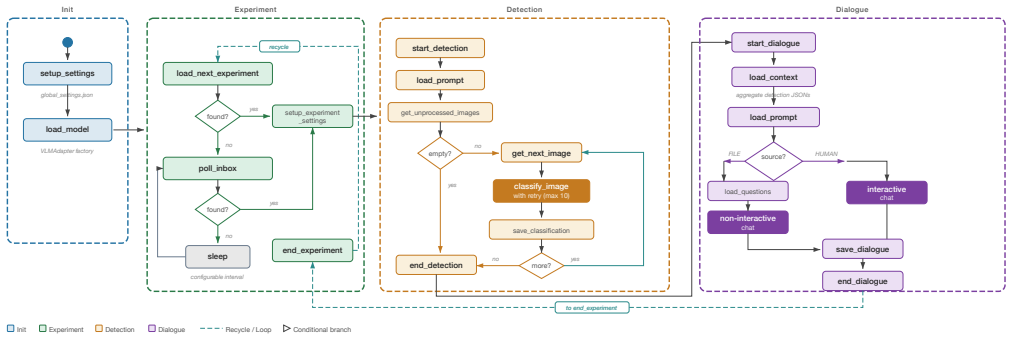
NAVI-Orbital achieved the first in-orbit demonstration of a vision-language model performing autonomous multi-modal inference entirely onboard a spacecraft. The system uses Gemma 3 to classify each captured scene, produce text descriptions of content and feature relationships, and handle operator dialogue via natural language, all orchestrated by a LangGraph state machine and executed on satellite-class hardware with hardware-accelerated inference and no fine-tuning.
What carries the argument
The NAVI-Orbital software system that runs a local vision-language model (Gemma 3) coordinated by a graph-based state machine (LangGraph) for detection and dialogue agents.
If this is right
- Satellites can perform semantic compression of imagery in orbit rather than downlinking raw data.
- Re-tasking of observation systems becomes possible through natural-language prompts instead of coded command sequences.
- Foundation models can execute zero-shot inference on newly acquired Earth imagery using only satellite-class edge hardware.
- Autonomous multi-modal analysis reduces the need for continuous human-in-the-loop processing of Earth observation data.
Where Pith is reading between the lines
- Similar onboard language models could enable satellites to prioritize or discard observations based on content before any downlink occurs.
- The same architecture might support closed-loop autonomy where scene descriptions trigger immediate sensor re-pointing or mode changes.
- Extending the approach to multi-satellite constellations could allow coordinated semantic sharing of observations across platforms.
Load-bearing premise
The Gemma 3 model produces reliable classifications and descriptions on uncorrected YAM-9 imagery from the flight instrument with no fine-tuning or domain adaptation.
What would settle it
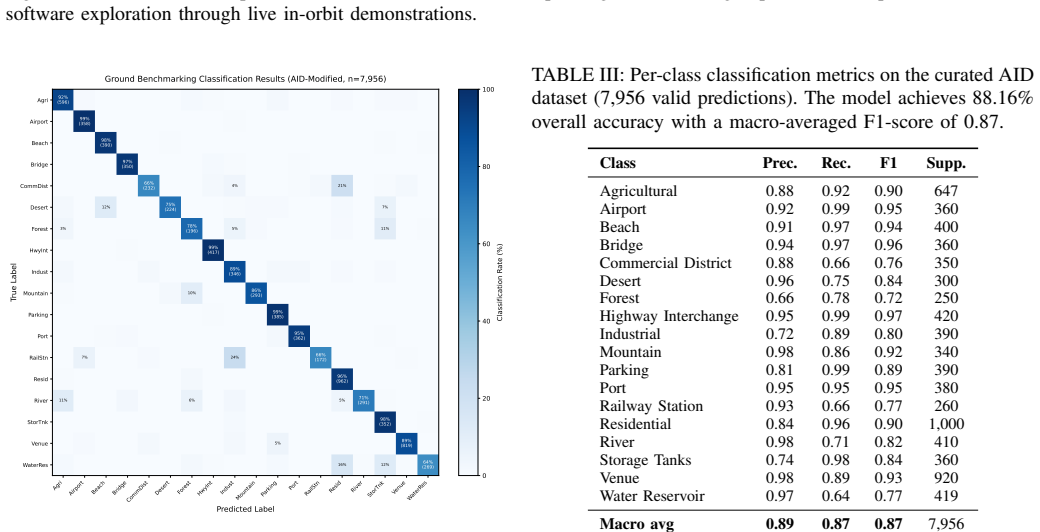
Systematic evaluation of the in-orbit outputs against independent ground-truth labels on the same YAM-9 captures showing accuracy well below the 88 percent ground benchmark would falsify the claim of reliable onboard performance.
Figures



read the original abstract
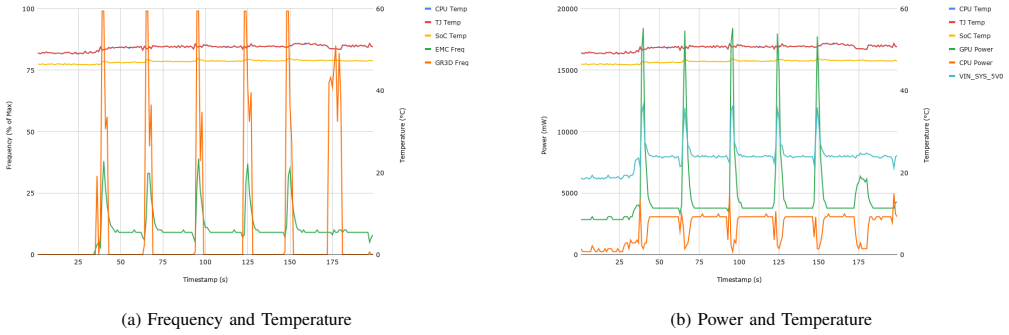
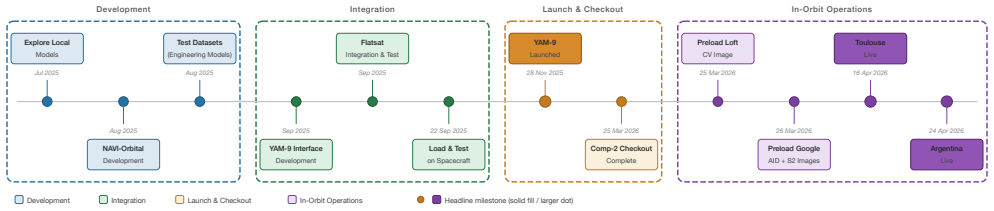
As Earth Observation data generation outpaces downlink bandwidth and human-in-the-loop processing, a widening gap has emerged between onboard collection and actionable ground intelligence. This paper presents NAVI-Orbital, a software system deployed on a Low Earth Orbit (LEO) spacecraft. On April 16, 2026, NAVI-Orbital achieved what is, to the authors' knowledge, the first in-orbit demonstration of a vision-language model performing autonomous multi-modal inference entirely onboard. NAVI-Orbital uses a local vision-language model (Gemma 3) to classify each captured scene, produce a text description of its content and the relationships between its features, and respond to operator follow-up via natural-language dialogue. The system is re-tasked through plain-English prompts in place of conventional command sequences, and is orchestrated by a graph-based state machine (LangGraph) coordinating dedicated agents for detection and dialogue. Results across ground benchmarking (88.16% accuracy on the 7,960-image curated AID benchmark), Flatsat validation, and live in-orbit captures of newly acquired, previously unseen Earth imagery (including uncorrected YAM-9 imagery, processed onboard with hardware-accelerated GPU inference and no fine-tuning for the flight instrument) demonstrate the feasibility of running foundation models on satellite-class edge computers to invert the conventional acquire-then-downlink-everything bandwidth profile through semantic compression of Earth observations in-orbit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NAVI-Orbital, a software system deployed on a LEO spacecraft that runs the Gemma 3 vision-language model for onboard autonomous multi-modal inference on Earth observation imagery. It claims the first such in-orbit demonstration on April 16, 2026, in which the model classifies scenes, generates text descriptions of content and feature relationships, and supports natural-language re-tasking via a LangGraph-orchestrated agent system, with supporting results of 88.16% accuracy on the 7,960-image AID benchmark plus flatsat validation and live in-orbit captures of uncorrected YAM-9 imagery processed with hardware-accelerated inference and no fine-tuning.
Significance. If the in-orbit performance claims are substantiated with quantitative metrics, the work would demonstrate the practical feasibility of running foundation models on satellite-class hardware for semantic compression of EO data, potentially shifting the conventional acquire-downlink paradigm toward onboard actionable intelligence and natural-language mission re-tasking.
major comments (2)
- [Results section] Results section: The manuscript reports an 88.16% accuracy figure for the curated AID benchmark but supplies no corresponding quantitative metrics (accuracy, success rate, confusion matrix, or ground-truth comparison) for the live in-orbit YAM-9 imagery processed by Gemma 3; this absence directly undermines evaluation of the central zero-shot generalization claim to uncorrected flight-instrument data under radiation and thermal conditions.
- [Abstract and Results section] Abstract and Results section: The claims of 'successful in-orbit captures' and 'processed onboard' are presented without any definition of success criteria, error analysis, or controls for the flight data, leaving the feasibility demonstration unverifiable despite the explicit mention of no fine-tuning for the YAM-9 sensor.
minor comments (2)
- [Methods] The exact version or checkpoint of 'Gemma 3' should be specified (e.g., parameter count, release date) to allow reproducibility of the zero-shot setup.
- [Abstract] Clarify whether the April 16, 2026 date refers to an actual flight event or a planned demonstration, given the manuscript's submission context.
Simulated Author's Rebuttal
We thank the referee for their constructive comments regarding the evaluation of the in-orbit demonstration. We respond to each major comment below.
read point-by-point responses
-
Referee: [Results section] Results section: The manuscript reports an 88.16% accuracy figure for the curated AID benchmark but supplies no corresponding quantitative metrics (accuracy, success rate, confusion matrix, or ground-truth comparison) for the live in-orbit YAM-9 imagery processed by Gemma 3; this absence directly undermines evaluation of the central zero-shot generalization claim to uncorrected flight-instrument data under radiation and thermal conditions.
Authors: We acknowledge that the manuscript provides no quantitative metrics (accuracy, success rate, confusion matrix, or ground-truth comparison) for the live in-orbit YAM-9 imagery. Unlike the curated AID benchmark, these captures represent newly acquired, previously unseen Earth imagery for which ground-truth labels are unavailable. The demonstration centers on operational feasibility of zero-shot inference under flight conditions (hardware-accelerated execution with no fine-tuning), evidenced by successful completion of inference and description generation. We will revise the Results section to explicitly note this limitation, state the nature of the available evidence, and incorporate any qualitative operational indicators or logs from the April 16, 2026 demonstration. revision: yes
-
Referee: [Abstract and Results section] Abstract and Results section: The claims of 'successful in-orbit captures' and 'processed onboard' are presented without any definition of success criteria, error analysis, or controls for the flight data, leaving the feasibility demonstration unverifiable despite the explicit mention of no fine-tuning for the YAM-9 sensor.
Authors: We agree that explicit definitions of success criteria, error analysis, and controls would improve verifiability. We will revise both the Abstract and Results sections to define success as error-free completion of model inference on captured imagery, generation of coherent classifications and descriptions, and successful execution of natural-language re-tasking via the LangGraph agents. The revision will also add a brief error analysis drawn from flight data logs and restate the controls (hardware acceleration and no fine-tuning for the YAM-9 sensor). revision: yes
Circularity Check
No circularity: empirical deployment report with no derivations or fitted predictions
full rationale
The paper is a systems/engineering report of an in-orbit deployment and test of an existing VLM (Gemma 3) with no equations, parameter fitting, or mathematical derivation chain. The central claim is the occurrence of the April 16 2026 demonstration itself, supported by a ground benchmark (88.16% on AID) and qualitative description of in-orbit processing. No step reduces a prediction to its own inputs by construction, and no self-citation is load-bearing for any uniqueness theorem or ansatz. The zero-shot generalization assumption is an unverified empirical premise rather than a circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tackling the satellite downlink bottleneck with federated onboard learning of image compression,
P. G ´omez and G. Meoni, “Tackling the satellite downlink bottleneck with federated onboard learning of image compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW): AI4Space, 2024, pp. 6809–6818
2024
-
[2]
TheΦ-sat-1 mission: The first on- board deep neural network demonstrator for satellite earth observation,
G. Giuffrida, L. Fanucci, G. Meoni, M. Bati ˇc, L. Buckley, A. Dunne, C. van Dijk, M. Esposito, J. Hefele, N. Vercruyssen, G. Furano, M. Pastena, and J. Aschbacher, “TheΦ-sat-1 mission: The first on- board deep neural network demonstrator for satellite earth observation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1– 14, 2022
2022
-
[3]
Gemma Team, “Gemma 3 technical report,” Google DeepMind, Tech. Rep., 2025, arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Open-vocabulary object detection using captions,
A. Zareian, K. D. Rosa, D. H. Hu, and S.-F. Chang, “Open-vocabulary object detection using captions,”2021 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pp. 14 388–14 397, 2021
2021
-
[5]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning (ICML), ser. Proceedings of Machine Learning Research, vol
-
[6]
8748–8763
PMLR, 2021, pp. 8748–8763
2021
-
[7]
Using autonomy flight software to improve science return on Earth Observing One,
S. Chien, R. Sherwood, D. Tran, B. Cichy, G. Rabideau, R. Castano, A. Davies, D. Mandl, S. Frye, B. Trout, S. Shulman, and D. Boyer, “Using autonomy flight software to improve science return on Earth Observing One,”Journal of Aerospace Computing, Information, and Communication (JACIC), pp. 196–216, Apr. 2005
2005
-
[8]
Cloudscout: A deep neural network for on-board cloud detection on hyperspectral images,
G. Giuffrida, L. Diana, F. de Gioia, G. Benelli, G. Meoni, M. Donati, and L. Fanucci, “Cloudscout: A deep neural network for on-board cloud detection on hyperspectral images,”Remote Sensing, vol. 12, no. 14, p. 2205, 2020
2020
-
[9]
Towards global flood mapping onboard low cost satellites with machine learning,
G. Mateo-Garcia, J. Veitch-Michaelis, L. Smith, S. V . Oprea, G. Schu- mann, Y . Gal, A. G. Baydin, and D. Backes, “Towards global flood mapping onboard low cost satellites with machine learning,”Scientific Reports, vol. 11, no. 1, p. 7249, 2021
2021
-
[10]
In-orbit demonstration of a re-trainable machine learning payload for processing optical imagery,
G. Mateo-Garcia, J. Veitch-Michaelis, C. Purcell, N. Longepe, S. Reid, A. Anlind, F. Bruhn, J. Parr, and P. P. Mathieu, “In-orbit demonstration of a re-trainable machine learning payload for processing optical imagery,” Scientific Reports, vol. 13, 2023
2023
-
[11]
Open-source software in space opera- tions,
G. Labr `eche and T. Mladenov, “Open-source software in space opera- tions,”Space Education & Strategic Applications, vol. 4, 2023
2023
-
[12]
Intuition-1: Toward in-orbit bare soil detection using spectral vegetation indices,
A. M. Wijata, T. Lakota, M. Cwiek, B. Ruszczak, M. Gumiela, L. Tulczyjew, A. Bartoszek, N. Long ´ep´e, K. Smykala, and J. Nalepa, “Intuition-1: Toward in-orbit bare soil detection using spectral vegetation indices,” inIGARSS 2024 - 2024 IEEE International Geoscience and Remote Sensing Symposium, 2024, pp. 1708–1712
2024
-
[13]
Hyperspectral image segmentation for optimal satellite operations: In-orbit deployment of 1d-cnn,
J. A. Justo, D. D. Langer, S. Berg, J. Nieke, R. T. Ionescu, P. G. Kjeldsberg, and T. A. Johansen, “Hyperspectral image segmentation for optimal satellite operations: In-orbit deployment of 1d-cnn,”Remote Sensing, vol. 17, no. 4, p. 642, 2025
2025
-
[14]
Expandable on-board real-time edge computing architecture for luojia3 intelligent remote sensing satellite,
Z. Zhang, Z. Qu, S. Liu, D. Li, J. Cao, and G. Xie, “Expandable on-board real-time edge computing architecture for luojia3 intelligent remote sensing satellite,”Remote Sensing, vol. 14, no. 15, p. 3596, 2022. 16
2022
-
[15]
Flight of dynamic targeting on cognisat-6 - update,
S. Chien, I. Zilberstein, A. Candela, D. Rijlaarsdam, A. Perrocheau, A. Dunne, T. Hendrix, O. C. Grauc, A. G. i Mestrec, M. P. Bovec, O. Aragon, and J. P. Miquel, “Flight of dynamic targeting on cognisat-6 - update,” inProceedings of the 18th International Conference on Space Operations, 2025
2025
-
[16]
Booz allen deploys the power of gen- erative ai in space,
Booz Allen Hamilton, “Booz allen deploys the power of gen- erative ai in space,” August 2024, press Release. Available at https://newsroom.boozallen.com/news-releases/news-release-details/ booz-allen-deploys-power-generative-ai-space/
2024
-
[17]
Space llama: Meta’s open source ai model is heading into orbit,
Meta and Booz Allen Hamilton, “Space llama: Meta’s open source ai model is heading into orbit,” April 2025, meta Newsroom. Available at https://about.fb.com/news/2025/04/ space-llama-metas-open-source-ai-model-heading-into-orbit/
2025
-
[18]
Astrea: Introducing agentic intelligence for orbital thermal autonomy,
A. D. Mousist, “Astrea: Introducing agentic intelligence for orbital thermal autonomy,” 2025. [Online]. Available: https://arxiv.org/abs/ 2509.13380
-
[19]
llama.cpp: Port of facebook’s llama model in c/c++,
G. Gerganov, “llama.cpp: Port of facebook’s llama model in c/c++,”
-
[20]
Available: https://github.com/ggerganov/llama.cpp
[Online]. Available: https://github.com/ggerganov/llama.cpp
-
[21]
8-bit optimizers via block-wise quantization,
T. Dettmers, M. Lewis, S. Shleifer, and L. Zettlemoyer, “8-bit optimizers via block-wise quantization,” in9th International Conference on Learn- ing Representations (ICLR), 2022
2022
-
[22]
U. Kurt, “Which quantization should i use? a unified evaluation of llama.cpp quantization on llama-3.1-8b-instruct,”arXiv preprint arXiv:2601.14277, 2026
-
[23]
Remote- clip: A vision language foundation model for remote sensing,
C. Liu, J. Zhang, K. Chen, M. Wang, Z. Zou, and Z. Shi, “Remote- clip: A vision language foundation model for remote sensing,”IEEE Transactions on Geoscience and Remote Sensing, 2024
2024
-
[24]
Geochat: Grounded large vision-language model for remote sensing,
K. Kuckreja, M. Danish, M. Nasir, A. Das, S. Khan, and F. S. Khan, “Geochat: Grounded large vision-language model for remote sensing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[25]
Co-training vision language models for remote sensing multi-task learning,
Q. Li, S. Ma, J. Luo, Y . Yu, Y . Zhou, F. Wang, X. Lu, X. Wang, X. He, Y . Chen, and X. Yang, “Co-training vision language models for remote sensing multi-task learning,”Remote Sensing, vol. 18, no. 2, p. 222, 2026
2026
-
[26]
Terramind: Large-scale generative multimodality for earth observation,
J. Jakubik, F. Yang, B. Blumenstiel, E. Scheurer, R. Sedona, S. Mauro- giovanni, J. Bosmans, N. Dionelis, V . Marsocci, N. Kopp, R. Ramachan- dran, P. Fraccaro, T. Brunschwiler, G. Cavallaro, J. Bernabe-Moreno, and N. Long´ep´e, “Terramind: Large-scale generative multimodality for earth observation,” inProceedings of the IEEE/CVF International Conference ...
2025
-
[27]
Llm-based multi-agent orchestra- tion: A survey of frameworks, communication protocols, and emerging patterns,
Y . Zhu, L. Liu, J. Yu, and D. Zhang, “Llm-based multi-agent orchestra- tion: A survey of frameworks, communication protocols, and emerging patterns,”Preprints, 2026
2026
-
[28]
Langchain vs. langgraph vs. langsmith: Taxonomies of agentic ai toolchains for end- to-end orchestration,
R. Sapkota, R. Shrestha, M. Rijal, and M. Karkee, “Langchain vs. langgraph vs. langsmith: Taxonomies of agentic ai toolchains for end- to-end orchestration,”TechRxiv, 2025
2025
-
[29]
J. Wang and Z. Duan, “Agent ai with langgraph: A modular framework for enhancing machine translation using large language models,”arXiv preprint arXiv:2412.03801, 2024
-
[30]
Langgraph: Build resilient language agents as graphs,
LangChain Inc., “Langgraph: Build resilient language agents as graphs,”
-
[31]
Available: https://github.com/langchain-ai/langgraph
[Online]. Available: https://github.com/langchain-ai/langgraph
-
[32]
Aid: A benchmark data set for performance evaluation of aerial scene classification,
G.-S. Xia, J. Hu, F. Hu, B. Shi, X. Bai, Y . Zhong, L. Zhang, and X. Lu, “Aid: A benchmark data set for performance evaluation of aerial scene classification,”IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 7, pp. 3965–3981, 2017
2017
-
[33]
ESA WorldCover 10 m 2021 v200,
D. Zanaga, R. Van De Kerchove, D. Daems, W. De Keersmaecker, C. Brockmann, G. Kirches, J. Wevers, O. Cartus, M. Santoro, S. Fritz, M. Lesiv, M. Herold, N. Tsendbazar, P. Xu, F. Ramoino, and O. Arino, “ESA WorldCover 10 m 2021 v200,” 2022
2021
-
[34]
Loft Orbital satellite imagery,
Loft Orbital Inc., “Loft Orbital satellite imagery,” 2026, proprietary satellite imagery provided by Loft Orbital for this study. See https: //www.loftorbital.com
2026
-
[35]
A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
J. White, Q. Fu, S. Hays, M. Sandborn, C. Olea, H. Gilbert, A. El- nashar, J. Spencer-Smith, and D. C. Schmidt, “A prompt pattern catalog to enhance prompt engineering with chatgpt,”arXiv preprint arXiv:2302.11382, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Last updated Jan 16, 2026
NVIDIA-Corporation,Tegrastats Utility, NVIDIA, 2026, nVIDIA Jetson Linux Developer Guide. Last updated Jan 16, 2026. [Online]. Avail- able: https://docs.nvidia.com/jetson/archives/r36.4.4/DeveloperGuide/ AT/JetsonLinuxDevelopmentTools/TegrastatsUtility.html
2026
-
[37]
Last updated Jan 16,
——,Jetson Orin Nano Series, Jetson Orin NX Series and Jetson AGX Orin Series, NVIDIA, 2026, nVIDIA Jetson Linux Developer Guide. Last updated Jan 16,
2026
-
[38]
Available: https://docs.nvidia.com/jetson/ archives/r36.4.4/DeveloperGuide/SD/PlatformPowerAndPerformance/ JetsonOrinNanoSeriesJetsonOrinNxSeriesAndJetsonAgxOrinSeries
[Online]. Available: https://docs.nvidia.com/jetson/ archives/r36.4.4/DeveloperGuide/SD/PlatformPowerAndPerformance/ JetsonOrinNanoSeriesJetsonOrinNxSeriesAndJetsonAgxOrinSeries. html#jetson-agx-orin-series 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.