Enhancing LLM-Based Neural Network Generation: Few-Shot Prompting and Efficient Validation for Automated Architecture Design
Pith reviewed 2026-05-16 19:04 UTC · model grok-4.3
The pith
Three examples in few-shot prompts let LLMs generate the most balanced neural architectures for vision tasks while a simple hash check speeds validation by 100 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
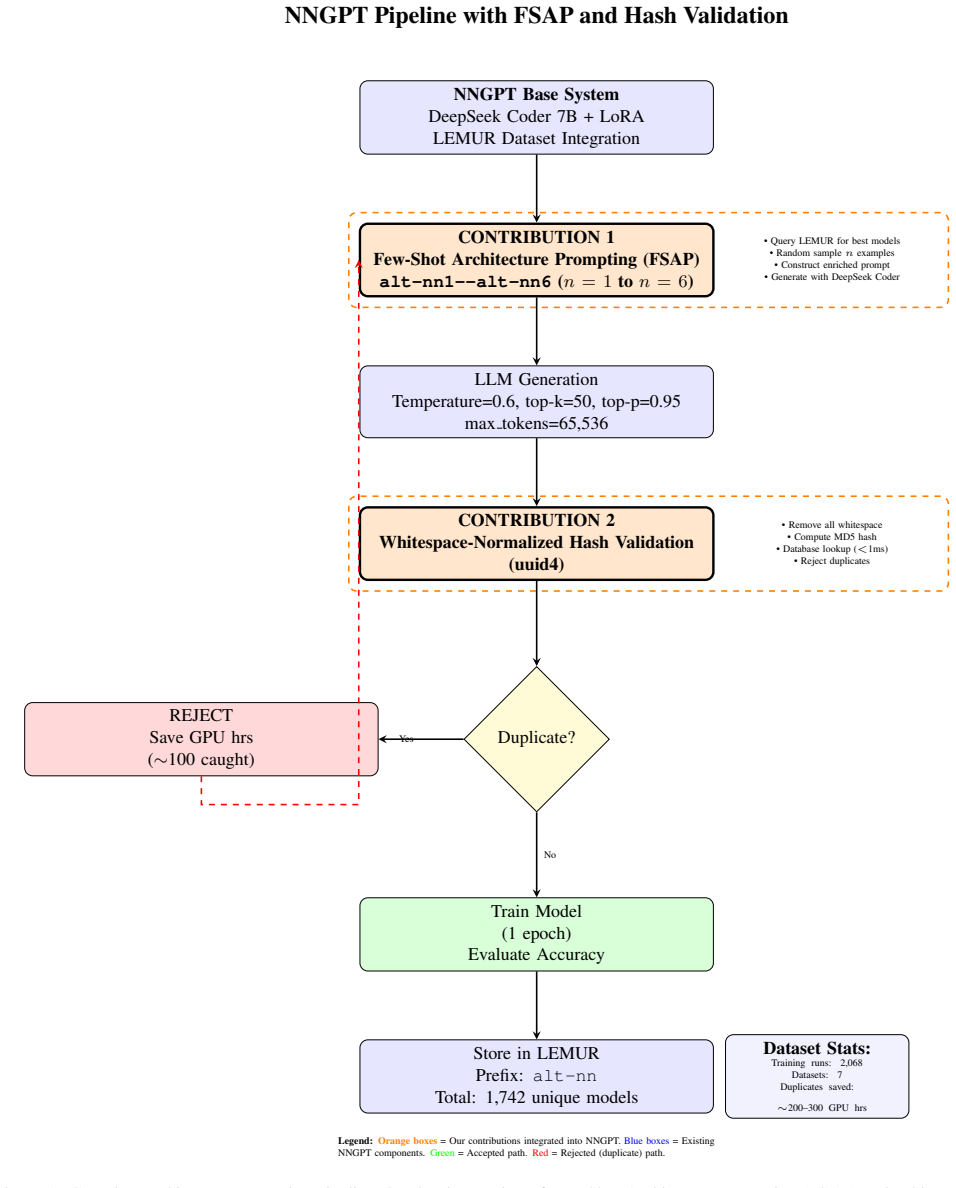
Few-Shot Architecture Prompting with exactly three supporting examples optimally balances architectural diversity and task-specific focus for vision networks, while Whitespace-Normalized Hash Validation deduplicates generated code 100 times faster than AST parsing and prevents redundant training, enabling efficient large-scale generation of 1900 unique architectures across seven heterogeneous benchmarks with a dataset-balanced evaluation method.
What carries the argument
Few-Shot Architecture Prompting (FSAP) with variable shot counts combined with Whitespace-Normalized Hash Validation for fast deduplication
Load-bearing premise
Observed differences in generated architecture quality across different numbers of prompt examples are caused by the example count itself rather than random variation in LLM sampling, training runs, or data splits.
What would settle it
Re-running the full set of experiments with fixed random seeds, identical training hyperparameters, and deterministic LLM sampling to check whether performance gaps between one-shot through six-shot regimes disappear.
Figures

read the original abstract
Automated neural network architecture design remains a significant challenge in computer vision. Task diversity and computational constraints require both effective architectures and efficient search methods. Large Language Models (LLMs) present a promising alternative to computationally intensive Neural Architecture Search (NAS), but their application to architecture generation in computer vision has not been systematically studied, particularly regarding prompt engineering and validation strategies. Building on the task-agnostic NNGPT/LEMUR framework, this work introduces and validates two key contributions for computer vision. First, we present Few-Shot Architecture Prompting (FSAP), the first systematic study of the number of supporting examples (n = 1, 2, 3, 4, 5, 6) for LLM-based architecture generation. We find that using n = 3 examples best balances architectural diversity and context focus for vision tasks. Second, we introduce Whitespace-Normalized Hash Validation, a lightweight deduplication method (less than 1 ms) that provides a 100x speedup over AST parsing and prevents redundant training of duplicate computer vision architectures. In large-scale experiments across seven computer vision benchmarks (MNIST, CIFAR-10, CIFAR-100, CelebA, ImageNette, SVHN, Places365), we generated 1,900 unique architectures. We also introduce a dataset-balanced evaluation methodology to address the challenge of comparing architectures across heterogeneous vision tasks. These contributions provide actionable guidelines for LLM-based architecture search in computer vision and establish rigorous evaluation practices, making automated design more accessible to researchers with limited computational resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Few-Shot Architecture Prompting (FSAP) as a systematic study of the number of in-context examples (n=1 to 6) for LLM-based generation of computer-vision architectures, concluding that n=3 optimally balances diversity and task focus. It also proposes Whitespace-Normalized Hash Validation for sub-millisecond deduplication that yields a claimed 100x speedup over AST parsing. Large-scale experiments generate 1,900 unique architectures and evaluate them on seven heterogeneous vision benchmarks (MNIST through Places365) using a dataset-balanced protocol.
Significance. If the central empirical ranking survives statistical controls, the work supplies concrete, actionable prompting guidelines for LLM-driven architecture search in vision and a lightweight deduplication primitive that materially reduces wasted training cycles. The scale of the reported generation (1,900 architectures) and the emphasis on cross-task comparability are strengths that could influence practical NAS pipelines with limited compute.
major comments (2)
- [Abstract and experimental results] Abstract and experimental results section: the claim that n=3 'best balances architectural diversity and context focus' rests on single-generation runs per prompting regime. No error bars, repeated LLM sampling seeds, temperature sweeps, or hypothesis testing (t-test/ANOVA) are reported, despite the stochasticity of both LLM decoding and network training. This leaves the observed accuracy ordering vulnerable to uncontrolled random variation rather than to the number of shots.
- [§3 and §4] §3 (methodology) and §4 (experiments): training protocols, optimizer settings, data splits, and number of independent training runs per architecture are not specified. Without these details the performance differences across n values cannot be attributed to prompting strategy rather than to hyper-parameter or split noise.
minor comments (2)
- [§4] The description of the dataset-balanced evaluation methodology is too brief; a concrete formula or pseudocode would clarify how accuracies are aggregated across tasks with different class counts and image resolutions.
- [Figures and tables] Table or figure captions should explicitly state the number of independent trials and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve reproducibility and statistical transparency.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results section: the claim that n=3 'best balances architectural diversity and context focus' rests on single-generation runs per prompting regime. No error bars, repeated LLM sampling seeds, temperature sweeps, or hypothesis testing (t-test/ANOVA) are reported, despite the stochasticity of both LLM decoding and network training. This leaves the observed accuracy ordering vulnerable to uncontrolled random variation rather than to the number of shots.
Authors: We acknowledge that each prompting regime (n=1 to 6) was evaluated from single LLM generation runs to keep the overall experiment tractable at the reported scale of 1,900 architectures. The n=3 result is supported by its consistent ranking across all seven heterogeneous benchmarks under a dataset-balanced protocol. In the revision we will (i) explicitly state the single-run limitation, (ii) add training-run error bars for the final reported accuracies where additional compute permits, and (iii) include a brief discussion of why full multi-seed LLM sampling and formal hypothesis testing were not performed. We do not claim statistical significance beyond the observed cross-benchmark pattern. revision: partial
-
Referee: [§3 and §4] §3 (methodology) and §4 (experiments): training protocols, optimizer settings, data splits, and number of independent training runs per architecture are not specified. Without these details the performance differences across n values cannot be attributed to prompting strategy rather than to hyper-parameter or split noise.
Authors: We agree that these implementation details are necessary for reproducibility. The revised manuscript will expand §3 and §4 to specify: Adam optimizer with learning rate 0.001 and standard weight decay, the exact train/validation/test splits used for each of the seven benchmarks, and that each generated architecture was trained once (to prioritize breadth of 1,900 unique models). These additions will make clear that performance differences are measured under identical training conditions. revision: yes
Circularity Check
No circularity: empirical results from direct architecture generation and benchmarking
full rationale
The paper reports an experimental study generating 1,900 unique architectures via LLM prompting with varying shot counts (n=1..6) and evaluating them on seven vision benchmarks. The central claim that n=3 best balances diversity and context focus is obtained by comparing measured accuracies and diversity metrics across regimes, not by any equation, fitted parameter, or self-citation that reduces the output to the input by construction. The Whitespace-Normalized Hash Validation is introduced as a lightweight implementation with a reported 100x speedup over AST parsing; its correctness is verified by direct timing and deduplication counts rather than derived from prior results. No load-bearing uniqueness theorems, ansatzes smuggled via citation, or renaming of known patterns appear in the described methodology. The evaluation methodology is self-contained against the stated benchmarks and does not invoke external derivations.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of prompt examples n
axioms (1)
- domain assumption LLMs can generate syntactically valid and trainable neural network code from few-shot prompts
Forward citations
Cited by 2 Pith papers
-
Delta-Based Neural Architecture Search: LLM Fine-Tuning via Code Diffs
Fine-tuned 7B LLMs generating unified diffs for neural architecture refinement achieve 66-75% valid rates and 64-66% mean first-epoch accuracy, outperforming full-generation baselines by large margins while cutting ou...
-
Closed-Loop LLM Discovery of Non-Standard Channel Priors in Vision Models
Closed-loop LLM search with AST-generated examples discovers non-standard channel widths that improve vision model performance over initial architectures on CIFAR-100.
Reference graph
Works this paper leans on
-
[1]
Nada Aboudeshish, Dmitry Ignatov, and Radu Timofte. Augmentgest: Can random data cropping augmentation boost gesture recognition performance?arXiv preprint arXiv:2506.07216, 2025. 3
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared Kaplan, Prafulla Dhariwal, et al. Language mod- els are few-shot learners.Advances in Neural Information Processing Systems (NeurIPS), 33:1877–1901, 2020. 2, 7
work page 1901
-
[3]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Hen- rique Ponde de Oliveira Pinto, Jared Kaplan, and Wojciech Zaremba. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Program Synthesis with Large Language Models
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-AI. DeepSeek-Coder: When the large lan- guage model meets programming.arXiv preprint arXiv:2401.14196, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Saif U Din, Muhammad Ahsan Hussain, Mohsin Ikram, Dmitry Ignatov, and Radu Timofte. Ai on the edge: An automated pipeline for pytorch-to-android deployment and benchmarking.Preprints, 2025. 2
work page 2025
-
[7]
Mohamed Gado, Towhid Taliee, Muhammad Danish Memon, Dmitry Ignatov, and Radu Timofte. Vist-gpt: Ush- ering in the era of visual storytelling with llms?arXiv preprint arXiv:2504.19267, 2025. 2
-
[8]
Lemur neural net- work dataset: Towards seamless automl.arXiv preprint arXiv:2504.10552, 2025
Arash Torabi Goodarzi, Roman Kochnev, Waleed Khalid, Furui Qin, Tolgay Atinc Uzun, Yashkumar Sanjaybhai Dhameliya, Yash Kanubhai Kathiriya, Zofia Antonina Ben- tyn, Dmitry Ignatov, and Radu Timofte. Lemur neural net- work dataset: Towards seamless automl.arXiv preprint arXiv:2504.10552, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[9]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InIn- ternational Conference on Learning Representations (ICLR),
-
[10]
Krunal Jesani, Dmitry Ignatov, and Radu Timofte. Llm as a neural architect: Controlled generation of image cap- tioning models under strict api contracts.arXiv preprint arXiv:2512.14706, 2025. 2
-
[11]
A Retrieval-Augmented Generation Approach to Extracting Algorithmic Logic from Neural Networks
Waleed Khalid, Dmitry Ignatov, and Radu Timofte. A retrieval-augmented generation approach to extracting al- gorithmic logic from neural networks.arXiv preprint arXiv:2512.04329, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[12]
Roman Kochnev, Arash Torabi Goodarzi, Zofia Antonina Bentyn, Dmitry Ignatov, and Radu Timofte. Optuna vs Code Llama: Are LLMs a New Paradigm for Hyperparame- ter Tuning? InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 5664–5674, 2025. 2
work page 2025
-
[13]
Nngpt: Rethinking automl with large language models.arXiv preprint arXiv:2511.20333, 2025
Roman Kochnev, Waleed Khalid, Tolgay Atinc Uzun, Xi Zhang, Yashkumar Sanjaybhai Dhameliya, Furui Qin, Chan- dini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Dmitry Igna- tov, and Radu Timofte. Nngpt: Rethinking automl with large language models.arXiv preprint arXiv:2511.20333, 2025. 1, 2
work page internal anchor Pith review arXiv 2025
-
[14]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. 3
work page 2009
-
[15]
Yann LeCun, L ´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recog- nition.Proceedings of the IEEE, 86(11):2278–2324, 1998. 3
work page 1998
-
[16]
StarCoder: may the source be with you!
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muen- nighoff, Denis Kocetkov, Chenghao Mou, and Leandro von Werra. StarCoder: May the source be with you!arXiv preprint arXiv:2305.06161, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
DARTS: Differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: Differentiable architecture search. InInternational Confer- ence on Learning Representations (ICLR), 2019. 2
work page 2019
-
[18]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of the IEEE International Conference on Computer Vision (ICCV), pages 3730–3738, 2015. 3
work page 2015
-
[19]
Preparation of Fractal-Inspired Computational Architectures for Automated Neural Design Exploration
Yash Mittal, Dmitry Ignatov, and Radu Timofte. Prepara- tion of fractal-inspired computational architectures for ad- vanced large language model analysis.arXiv preprint arXiv:2511.07329, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bis- sacco, Bo Wu, and Andrew Y . Ng. Reading digits in nat- ural images with unsupervised feature learning.NIPS Work- shop on Deep Learning and Unsupervised Feature Learning,
-
[21]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, and Caiming Xiong. CodeGen: An open large language model for code with multi-turn program synthesis.arXiv preprint arXiv:2203.13474, 2023. 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Hieu Pham, Melody Guan, Barret Zoph, Quoc V . Le, and Jeff Dean. Efficient neural architecture search via parameter sharing. InInternational Conference on Machine Learning (ICML), pages 4095–4104, 2018. 2
work page 2018
-
[23]
Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V . Le. Regularized evolution for image classifier architecture search. InProceedings of the AAAI Conference on Artificial Intelligence, pages 4780–4789, 2019. 1, 2
work page 2019
-
[24]
Code Llama: Open Foundation Models for Code
Baptiste Rozi `ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Tan, and Gabriel Synnaeve. Code Llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Bhavya Rupani, Dmitry Ignatov, and Radu Timofte. Explor- ing the collaboration between vision models and llms for en- hanced image classification.Preprints, 2025. 2
work page 2025
-
[26]
Saul Schleimer, Daniel S. Wilkerson, and Alex Aiken. Win- nowing: Local algorithms for document fingerprinting. In Proceedings of the ACM SIGMOD International Conference on Management of Data, pages 76–85. ACM, 2003. 1, 2
work page 2003
-
[27]
Lemur 2: Unlocking neural network diversity for ai.arXiv preprint, 2025
Tolgay Atincand Uzun, Waleed Khalid, Saif U Din, Sai Re- vanth Mulukuledu, Akashdeep Singh, Chandini Vysyaraju, Raghuvir Duvvuri, Avi Goyal, Yashkumar Rajeshbhai Lukhi, Ahsan Hussain, Krunal Jesani, Usha Shrestha, Yash Mittal, Roman Kochnev, Pritam Kadam, Mohsin Ikram, 9 Harsh Rameshbhai Moradiya, Alice Arslanian, Dmitry Igna- tov, and Radu Timofte. Lemur...
work page 2025
-
[28]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Process- ing Systems (NeurIPS), 35:24824–24837, 2022. 1, 2
work page 2022
-
[29]
Places: A 10 million image database for scene recognition
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. InIEEE Transactions on Pattern Anal- ysis and Machine Intelligence (PAMI), pages 1452–1464,
-
[30]
Barret Zoph and Quoc V . Le. Neural architecture search with reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2017. 1, 2 10
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.