Aqua Boundary-Saliency Attention Module for Lightweight Underwater Salient Instance Segmentation Detection Transformer
Pith reviewed 2026-06-27 20:12 UTC · model grok-4.3
The pith
Embedding underwater boundary and saliency cues into DINOv2 features lets a compact DETR match state-of-the-art segmentation accuracy at real-time speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
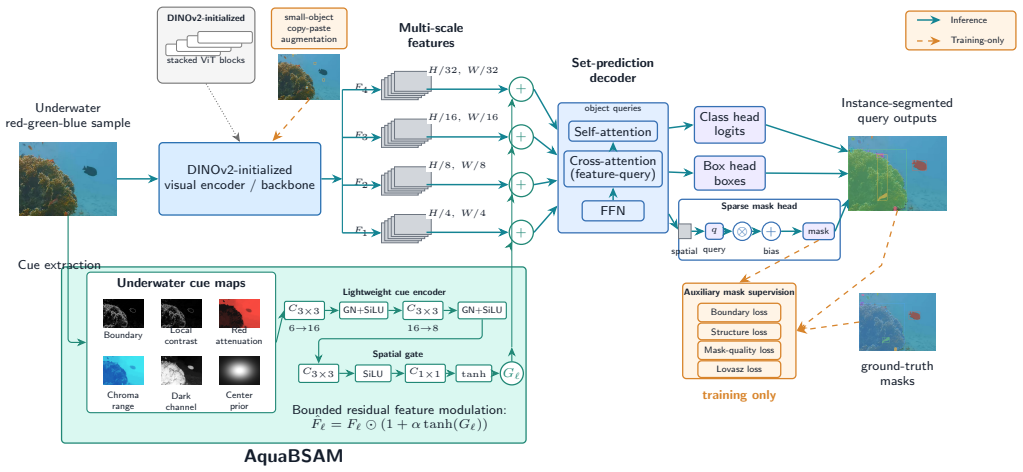
The central claim is that the AquaBSAM module successfully embeds the listed underwater cues into DINOv2-initialized multi-scale features via bounded residual modulation, enabling the compact LUSIS-DETR framework to deliver competitively leading performance on underwater instance segmentation without reliance on large foundation models, prompt generation, or auxiliary modalities, while supporting real-time inference.
What carries the argument
Aqua Boundary-Saliency Attention Module (AquaBSAM), which integrates boundary, contrast, attenuation, chroma, dark-channel, and center-prior cues into DINOv2 multi-scale features through bounded residual modulation.
If this is right
- The method reduces dependence on large foundation models or extra modalities for underwater tasks.
- Auxiliary training techniques improve results without affecting inference latency.
- The framework supports real-time operation suitable for underwater robotic perception.
- Results hold across both category-aware and salient-instance evaluation protocols on four datasets.
Where Pith is reading between the lines
- The cue-embedding strategy could be tested on other degraded visual domains such as fog or low-light scenes.
- Bounded residual modulation might serve as a general pattern for injecting domain knowledge into vision transformers.
- Replacing DINOv2 with alternative backbones could further tune the accuracy-speed trade-off.
Load-bearing premise
The listed underwater cues can be embedded into the DINOv2 features via bounded residual modulation in a way that produces the reported performance gains.
What would settle it
An ablation that disables AquaBSAM entirely and then re-measures mask quality and instance discrimination on UIIS, UIIS10K, USIS10K, and USIS16K; absence of a clear performance drop would falsify the module's contribution.
Figures

read the original abstract
Underwater instance segmentation integrates pixel-level mask prediction and instance-level discrimination for marine resource exploration, ecological monitoring, and underwater robotic perception. Recent prompt-based and auxiliary-modality methods improve mask quality, but their reliance on large foundation models, prompt generation, or extra modality estimation complicates efficient deployment. This work introduces Lightweight Underwater Salient Instance Segmentation Detection Transformer (LUSIS-DETR), a compact detection-transformer framework built around the Aqua Boundary-Saliency Attention Module (AquaBSAM). AquaBSAM embeds underwater boundary, contrast, attenuation, chroma, dark-channel, and center-prior cues into DINOv2-initialized multi-scale features through bounded residual modulation, while auxiliary mask supervision and small-object copy-paste are training-only. Extensive evaluation on four recent underwater instance segmentation datasets, UIIS, UIIS10K, USIS10K, and USIS16K, shows competitively leading performance against previous state-of-the-art works across category-aware and salient-instance protocols. TensorRT half-precision (FP16) benchmarking on an NVIDIA T4 graphics processing unit (GPU) achieves 4.31-6.34 milliseconds (ms) latency, supporting real-time inference under an accessible reproduction setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LUSIS-DETR, a compact detection-transformer for underwater salient instance segmentation, centered on the AquaBSAM module. AquaBSAM embeds boundary, contrast, attenuation, chroma, dark-channel, and center-prior cues into DINOv2-initialized multi-scale features via bounded residual modulation; auxiliary mask supervision and small-object copy-paste are used only at training time. The central claim is that this yields competitively leading results on UIIS, UIIS10K, USIS10K, and USIS16K under both category-aware and salient-instance protocols, together with TensorRT FP16 latency of 4.31-6.34 ms on an NVIDIA T4 GPU, while avoiding large foundation models or extra modalities.
Significance. If the reported performance gains are shown to arise from the AquaBSAM cue modulation rather than the DINOv2 backbone, and if the quantitative results are supplied, the work would offer a practical route to real-time underwater instance segmentation on modest hardware, addressing deployment difficulties of prompt-based or auxiliary-modality approaches.
major comments (2)
- [Abstract] Abstract: the claim of 'competitively leading performance' on four datasets is asserted without any quantitative metrics, baseline tables, ablation results, or statistical comparisons, leaving the central empirical claim unsupported by visible evidence.
- [Abstract] Abstract: the positioning of LUSIS-DETR as avoiding large foundation models is contradicted by the explicit use of DINOv2-initialized features; without an ablation isolating the contribution of AquaBSAM from the DINOv2 backbone, the novelty and efficiency arguments rest on an untested separation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and have revised the manuscript to incorporate quantitative support and clarify the role of DINOv2.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'competitively leading performance' on four datasets is asserted without any quantitative metrics, baseline tables, ablation results, or statistical comparisons, leaving the central empirical claim unsupported by visible evidence.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised version, we have added specific metrics (e.g., mAP under category-aware and salient-instance protocols on UIIS, UIIS10K, USIS10K, and USIS16K, plus FP16 latency on T4) directly into the abstract, with explicit pointers to the corresponding tables and ablations in Sections 4 and 5. revision: yes
-
Referee: [Abstract] Abstract: the positioning of LUSIS-DETR as avoiding large foundation models is contradicted by the explicit use of DINOv2-initialized features; without an ablation isolating the contribution of AquaBSAM from the DINOv2 backbone, the novelty and efficiency arguments rest on an untested separation.
Authors: We accept that the original wording could be misinterpreted. DINOv2 serves only as a fixed feature initializer for the multi-scale backbone (analogous to ImageNet-pretrained ResNet in prior DETR variants), while inference remains lightweight and free of prompt-based foundation models or extra modalities. To directly address the isolation concern, we have added an ablation in the revised manuscript that compares the full AquaBSAM-equipped model against a DINOv2-only baseline and a DINOv2+standard attention variant, confirming the performance contribution of the cue-modulation mechanism. revision: yes
Circularity Check
No circularity: empirical benchmarking with no derivation chain
full rationale
The paper introduces LUSIS-DETR and AquaBSAM as an architectural module that embeds listed underwater cues into DINOv2 features via bounded residual modulation. All central claims (leading performance on UIIS/UIIS10K/USIS10K/USIS16K, 4.31-6.34 ms latency) rest on empirical evaluation against prior SOTA under category-aware and salient-instance protocols. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear. The DINOv2 initialization is an explicit design choice, not a hidden tautology that forces the reported gains. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DINOv2 multi-scale features provide a suitable initialization that can be improved by bounded residual modulation with underwater cues
invented entities (2)
-
AquaBSAM
no independent evidence
-
LUSIS-DETR
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: IEEE/CVF International Conference on Computer Vision
S. Lian, H. Li, R. Cong, S. Li, W. Zhang, and S. Kwong, “Watermask: Instance segmentation for underwater imagery,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 1305– 1315, doi: 10.1109/ICCV51070.2023.00126
-
[2]
S. Lian, Z. Zhang, H. Li, W. Li, L. T. Yang, S. Kwong, and R. Cong, “Diving into underwater: Segment anything model guided underwater salient instance segmentation and a large-scale dataset,” inProc. Inter- national Conference on Machine Learning (ICML), 2024, pp. 29 545– 29 559, doi: 10.48550/arXiv.2406.06039
-
[3]
H. Li, S. Lian, Z. Li, R. Cong, C. Li, L. T. Yang, W. Zhang, and S. Kwong, “Advancing marine research: Uwsam framework and uiis10k dataset for precise underwater instance segmentation,”arXiv preprint arXiv:2505.15581, 2025, doi: 10.48550/arXiv.2505.15581
-
[4]
Usis16k: High-quality dataset for underwater salient instance segmentation,
L. Hong, X. Wang, Y . Li, and X. Wang, “Usis16k: High-quality dataset for underwater salient instance segmentation,”arXiv preprint arXiv:2506.19472, 2025, doi: 10.48550/arXiv.2506.19472
-
[5]
Empowering dino represen- tations for underwater instance segmentation via aligner and prompter,
Z. Chen, C. Zhang, H. Fang, and R. Cong, “Empowering dino represen- tations for underwater instance segmentation via aligner and prompter,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 5, pp. 3201–3209, 2026, doi: 10.1609/aaai.v40i5.37314
-
[6]
R. Cong, Z. Yu, H. Fang, H. Sun, and S. Kwong, “Uis-mamba: Exploring mamba for underwater instance segmentation via dynamic tree scan and hidden state weaken,” inProc. 33rd ACM Interna- tional Conference on Multimedia (ACM MM), 2025, pp. 343–352, doi: 10.1145/3746027.3755131
-
[7]
Depth-guided cross- modal fusion network for underwater salient instance segmentation,
S. Zheng, X. Zhou, L. Bao, X. Hu, and J. Zhang, “Depth-guided cross- modal fusion network for underwater salient instance segmentation,” Symmetry, vol. 18, no. 5, p. 799, 2026, doi: 10.3390/sym18050799
-
[8]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,” inAdvances in Neural Information Processing Systems 37, 2024, pp. 21 875–21 911, doi: 10.52202/079017-0688
-
[9]
Rf- detr: Neural architecture search for real-time detection transformers,
I. Robinson, P. Robicheaux, M. Popov, D. Ramanan, and N. Peri, “Rf- detr: Neural architecture search for real-time detection transformers,” inProc. International Conference on Learning Representations (ICLR), 2026, doi: 10.48550/arXiv.2511.09554
-
[10]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision – ECCV 2014, 2014, pp. 740–755, doi: 10.1007/978-3-319-10602-1 48
-
[11]
U-net: Convolutional networks for biomedical image segmentation
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, 2015, pp. 234–241, doi: 10.1007/978-3-319-24574-4 28
-
[12]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 936–944, doi: 10.1109/CVPR.2017.106
-
[13]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted win- dows,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9992–10 002, doi: 10.1109/ICCV48922.2021.00986
-
[14]
Conditional convolutions for instance segmentation,
Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” inComputer Vision – ECCV 2020, 2020, pp. 282–298, doi: 10.1007/978-3-030-58452-8 17
-
[15]
Y . Fang, S. Yang, X. Wang, Y . Li, C. Fang, Y . Shan, B. Feng, and W. Liu, “Instances as queries,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 6890–6899, doi: 10.1109/ICCV48922.2021.00683
-
[17]
Cascade r-cnn: Delving into high qual- ity object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high qual- ity object detection,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 6154–6162, doi: 10.1109/CVPR.2018.00644
-
[18]
Boundary-preserving mask r-cnn,
T. Cheng, X. Wang, L. Huang, and W. Liu, “Boundary-preserving mask r-cnn,” inComputer Vision – ECCV 2020, 2020, pp. 660–676, doi: 10.1007/978-3-030-58568-6 39
-
[19]
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in Computer Vision – ECCV 2020, 2020, pp. 213–229, doi: 10.1007/978- 3-030-58452-8 13
-
[20]
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 16 965–16 974, doi: 10.1109/CVPR52733.2024.01605
-
[21]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Gird- har, “Masked-attention mask transformer for universal image seg- mentation,” inProc. IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2022, pp. 1280–1289, doi: 10.1109/CVPR52688.2022.00135
-
[22]
In: IEEE/CVF International Conference on Computer Vision
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll ´ar, and R. Girshick, “Segment anything,” inProc. IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 3992–4003, doi: 10.1109/ICCV51070.2023.00371
-
[23]
Y . Xiong, B. Varadarajan, L. Wu, X. Xiang, F. Xiao, C. Zhu, X. Dai, D. Wang, F. Sun, F. Iandola, R. Krishnamoorthi, and V . Chandra, “Efficientsam: Leveraged masked image pretraining for efficient seg- ment anything,” inProc. IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2024, pp. 16 111–16 121, doi: 10.1109/CVPR52733.2024.01525
-
[24]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. J ´egou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “Dinov2: Learning robust visual features with...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2023
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
D. Bolya, C. Zhou, F. Xiao, and Y . J. Lee, “Yolact: Real- time instance segmentation,” inProc. IEEE/CVF International Con- ference on Computer Vision (ICCV), 2019, pp. 9156–9165, doi: 10.1109/ICCV .2019.00925
-
[26]
Solo: Segmenting objects by locations,
X. Wang, T. Kong, C. Shen, Y . Jiang, and L. Li, “Solo: Segmenting objects by locations,” inComputer Vision – ECCV 2020, 2020, pp. 649– 665, doi: 10.1007/978-3-030-58523-5 38
-
[27]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
A. Kirillov, Y . Wu, K. He, and R. Girshick, “Pointrend: Image seg- mentation as rendering,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 9796–9805, doi: 10.1109/CVPR42600.2020.00982
-
[28]
Z. Huang, L. Huang, Y . Gong, C. Huang, and X. Wang, “Mask scoring r-cnn,” inProc. IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2019, pp. 6402–6411, doi: 10.1109/CVPR.2019.00657
-
[29]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
T. Cheng, X. Wang, S. Chen, W. Zhang, Q. Zhang, C. Huang, Z. Zhang, and W. Liu, “Sparse instance activation for real-time in- stance segmentation,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4423–4432, doi: 10.1109/CVPR52688.2022.00439
-
[30]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition
Z. Liu, H. Mao, C.-Y . Wu, C. Feichtenhofer, T. Darrell, and S. Xie, “A convnet for the 2020s,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 11 966–11 976, doi: 10.1109/CVPR52688.2022.01167
-
[31]
M. Berman, A. R. Triki, and M. B. Blaschko, “The lovasz-softmax loss: A tractable surrogate for the optimization of the intersection-over- union measure in neural networks,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 4413– 4421, doi: 10.1109/CVPR.2018.00464
-
[32]
Bipa: Bilevel prompt adaptation for underwater instance segmentation,
L. Ma, H. Zheng, Y . Mao, J. Liu, C. Xu, X. Xue, Y . Wang, X. He, and W. Wang, “Bipa: Bilevel prompt adaptation for underwater instance segmentation,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026, pp. 10 731–10 740
2026
-
[33]
Usis- pgm: Photometric gaussian mixtures for underwater salient in- stance segmentation,
L. Hong, X. Yao, M. Bozkurt, X. Wang, and F. Zhang, “Usis- pgm: Photometric gaussian mixtures for underwater salient in- stance segmentation,”arXiv preprint arXiv:2603.13961, 2026, doi: 10.48550/arXiv.2603.13961
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.