ReQuest: Rethinking-based Question-Aware Frame Selection for Long-Form Video QA
Pith reviewed 2026-07-03 16:43 UTC · model grok-4.3
The pith
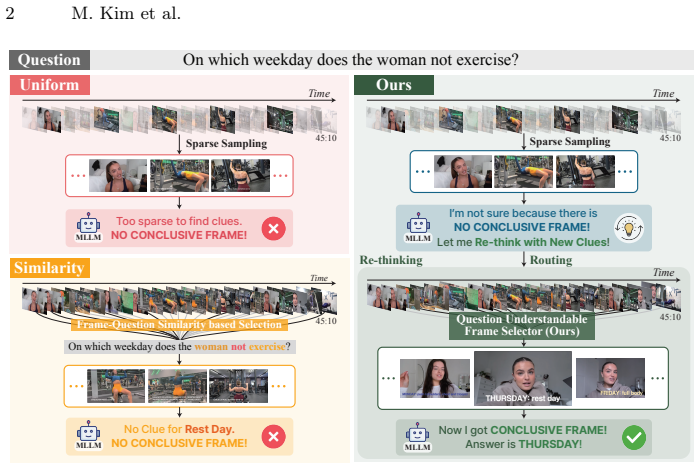
A question-aware keyframe selector improves long-form video QA accuracy without modifying the underlying multimodal model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
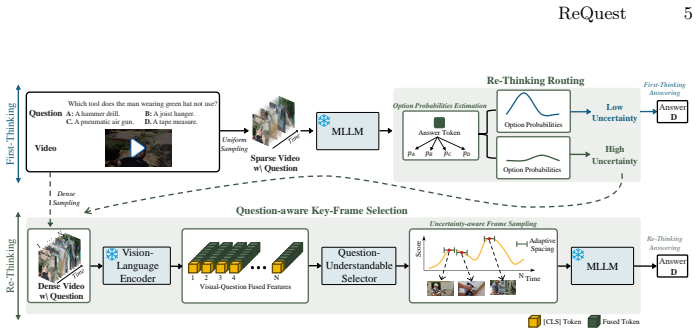
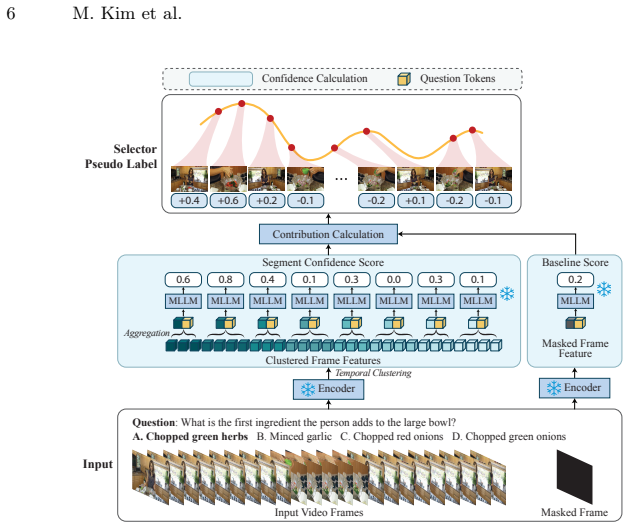
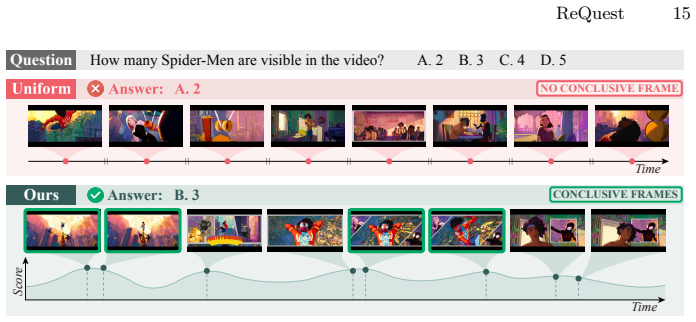
ReQuest integrates a lightweight question-aware selector distilled from MLLM-generated supervision, Re-thinking Routing that triggers additional inference only when the model is uncertain with a length-adaptive criterion, and uncertainty-guided adaptive non-maximum suppression that selects temporally diverse frames while adjusting spacing based on question difficulty, to improve long-video QA performance without modifying the underlying MLLM.
What carries the argument
ReQuest pipeline performing uncertainty-driven, question-adaptive keyframe selection via a distilled selector, rethinking routing, and adaptive non-maximum suppression.
If this is right
- Experiments on Video-MME, MLVU, and LongVideoBench show consistent accuracy gains.
- Gains are particularly strong in medium and long video regimes.
- Computational cost remains competitive with baseline sampling.
- The method works without fine-tuning or altering the base MLLM.
Where Pith is reading between the lines
- The same selection logic could apply to other long-context video tasks like summarization or event detection.
- Lowering dependence on uniform sampling may reduce cases where critical evidence is skipped in extended videos.
- Evaluating ReQuest across additional MLLM families would test whether the distilled selector transfers without retraining.
Load-bearing premise
The lightweight question-aware selector distilled from MLLM-generated supervision accurately captures question intent and model uncertainty without introducing systematic bias or requiring per-model retraining.
What would settle it
Running ReQuest versus uniform sampling on Video-MME and observing no accuracy gain or a large rise in compute cost would show the claimed benefits do not hold.
Figures

read the original abstract
Recent multimodal large language models (MLLMs) have substantially advanced video understanding, yet long-form video QA remains challenging under fixed input token budgets, where uniform sampling can be inefficient for evidence localization. We propose ReQuest , an uncertainty-driven, question-adaptive keyframe selection pipeline that aligns question intent with relevant video content through selective computation. ReQuest integrates (i) a lightweight question-aware selector distilled from MLLM-generated supervision, (ii) Re-thinking Routing that triggers additional inference only when the model is uncertain with a length-adaptive criterion, and (iii) uncertainty-guided adaptive non-maximum suppression that selects temporally diverse frames while adjusting spacing based on question difficulty. As a plug-andplay method, ReQuest improves long-video QA without modifying or fine-tuning the underlying MLLM. Experiments on Video-MME, MLVU, and LongVideoBench demonstrate consistent accuracy gains with competitive computational cost, with particularly strong improvements in medium and long video regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReQuest, a plug-and-play pipeline for question-aware keyframe selection in long-form video QA with MLLMs. It combines (i) a lightweight selector distilled from MLLM-generated supervision, (ii) rethinking routing that triggers extra inference only under a length-adaptive uncertainty criterion, and (iii) uncertainty-guided adaptive NMS for temporally diverse frames. Experiments on Video-MME, MLVU, and LongVideoBench report consistent accuracy gains (especially in medium/long regimes) at competitive compute cost, without modifying or fine-tuning the base MLLM.
Significance. If the generality claim holds, the work offers a practical route to better evidence localization under fixed token budgets. The distillation-based selector and uncertainty-driven routing are potentially reusable strengths; the multi-benchmark evaluation with emphasis on longer videos is a positive feature.
major comments (2)
- [§3.1–3.2] §3.1–3.2: The assertion that the distilled selector is model-agnostic and requires no per-model retraining is load-bearing for the plug-and-play claim, yet supervision is generated by the target MLLM itself; this risks embedding model-specific uncertainty patterns. Cross-model transfer experiments (e.g., selector trained on one MLLM evaluated on another) are needed to substantiate generality.
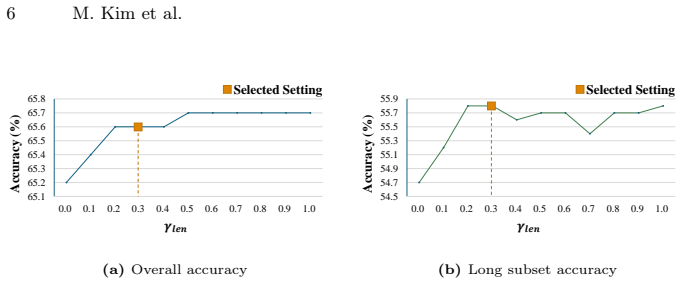
- [§4.3, Table 3] §4.3, Table 3: The reported gains on long-video subsets are presented without error bars, multiple random seeds, or statistical tests; given that the rethinking-routing threshold is itself length-adaptive and tuned on the same benchmarks, it is unclear whether the improvements exceed what could arise from hyper-parameter search alone.
minor comments (2)
- [Figure 2] Figure 2: The diagram of the adaptive NMS spacing rule would benefit from an explicit formula relating question difficulty to frame spacing.
- [§2] §2: Related-work discussion of prior frame-selection methods omits recent token-pruning techniques that also operate at inference time; a brief comparison would clarify the novelty of the uncertainty criterion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§3.1–3.2] §3.1–3.2: The assertion that the distilled selector is model-agnostic and requires no per-model retraining is load-bearing for the plug-and-play claim, yet supervision is generated by the target MLLM itself; this risks embedding model-specific uncertainty patterns. Cross-model transfer experiments (e.g., selector trained on one MLLM evaluated on another) are needed to substantiate generality.
Authors: The plug-and-play claim refers to the absence of any modification or fine-tuning to the base MLLM itself during deployment. We acknowledge that generating supervision from the target MLLM can embed model-specific patterns and that the selector therefore requires per-MLLM training. The manuscript does not claim zero-cost transfer across arbitrary MLLMs. We will revise §3.1–3.2 to explicitly state the scope of the claim and note that cross-model transfer experiments were not conducted. revision: partial
-
Referee: [§4.3, Table 3] §4.3, Table 3: The reported gains on long-video subsets are presented without error bars, multiple random seeds, or statistical tests; given that the rethinking-routing threshold is itself length-adaptive and tuned on the same benchmarks, it is unclear whether the improvements exceed what could arise from hyper-parameter search alone.
Authors: We agree that error bars and statistical tests would strengthen the results. The length-adaptive threshold follows a deterministic rule based on video duration categories (detailed in §3.3) and was not re-tuned per benchmark. Gains appear consistently across three distinct benchmarks. Due to the computational expense of large MLLMs, only single runs are reported. We will add a limitations paragraph acknowledging this and the potential for hyper-parameter effects. revision: partial
Circularity Check
No significant circularity; method is self-contained plug-in
full rationale
The paper describes an engineering pipeline (question-aware selector distilled from MLLM supervision, rethinking routing, adaptive NMS) evaluated on public benchmarks (Video-MME, MLVU, LongVideoBench). No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The distillation step uses external MLLM outputs as supervision but does not reduce any claimed result to its own inputs by construction; performance claims rest on empirical gains rather than definitional equivalence. This matches the default expectation of a non-circular applied method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (2023)
2023
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Chen, L., Wei, X., Li, J., Dong, X., Zhang, P., Zang, Y., Chen, Z., Duan, H., Tang, Z., Yuan, L., et al.: Sharegpt4video: Improving video understanding and generation with better captions. vol. 37, pp. 19472–19495 (2024)
2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024)
2024
-
[6]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., et al.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
In: European Conference on Computer Vision
Fan, Y., Ma, X., Wu, R., Du, Y., Li, J., Gao, Z., Li, Q.: Videoagent: A memory- augmented multimodal agent for video understanding. In: European Conference on Computer Vision. pp. 75–92. Springer (2024)
2024
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. arXiv preprint arXiv:2405.21075 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
He, B., Li, H., Jang, Y.K., Jia, M., Cao, X., Shah, A., Shrivastava, A., Lim, S.N.: Ma-lmm: Memory-augmented large multimodal model for long-term video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13504–13514 (2024)
2024
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, K., Gao, F., Nie, X., Zhou, P., Tran, S., Neiman, T., Wang, L., Shah, M., Hamid, R., Yin, B., et al.: M-llm based video frame selection for efficient video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13702–13712 (2025)
2025
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Jin, P., Takanobu, R., Zhang, W., Cao, X., Yuan, L.: Chat-univi: Unified visual representation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13700–13710 (2024)
2024
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, M., Kim, H.B., Moon, J., Choi, J., Kim, S.T.: Do you remember? dense video captioning with cross-modal memory retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13894–13904 (2024)
2024
-
[13]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kim, M., Kim, H.B., Moon, J., Choi, J., Kim, S.T.: Hicm2: Hierarchical com- pact memory modeling for dense video captioning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 4293–4301 (2025)
2025
-
[14]
IEEE Access (2024)
Kim, W., Choi, C., Lee, W., Rhee, W.: An image grid can be worth a video: Zero-shot video question answering using a vlm. IEEE Access (2024)
2024
-
[15]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024) ReQuest 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
In: International conference on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International conference on machine learning. pp. 12888–12900. PMLR (2022)
2022
-
[17]
Science China Information Sciences 68(10), 200102 (2025)
Li, K., He, Y., Wang, Y., Li, Y., Wang, W., Luo, P., Wang, Y., Wang, L., Qiao, Y.: Videochat: Chat-centric video understanding. Science China Information Sciences 68(10), 200102 (2025)
2025
-
[18]
In: European Conference on Computer Vision
Li, Y., Wang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large language models. In: European Conference on Computer Vision. pp. 323–340. Springer (2025)
2025
-
[19]
In: Proceedings of the 2024 conference on empirical methods in natural language processing
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 conference on empirical methods in natural language processing. pp. 5971–5984 (2024)
2024
-
[20]
arXiv preprint arXiv:2310.19773 (2023)
Lin, K., Ahmed, F., Li, L., Lin, C.C., Azarnasab, E., Yang, Z., Wang, J., Liang, L., Liu, Z., Lu, Y., et al.: Mm-vid: Advancing video understanding with gpt-4v (ision). arXiv preprint arXiv:2310.19773 (2023)
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, S., Zhang, C.L., Zhao, C., Ghanem, B.: End-to-end temporal action detection with 1b parameters across 1000 frames. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18591–18601 (2024)
2024
-
[22]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Liu, S., Zhao, C., Xu, T., Ghanem, B.: Bolt: Boost large vision-language model without training for long-form video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3318–3327 (2025)
2025
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4122–4134 (2025)
2025
-
[24]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Maaz, M., Rasheed, H., Khan, S., Khan, F.: Video-chatgpt: Towards detailed video understanding via large vision and language models. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12585–12602 (2024)
2024
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Min, J., Buch, S., Nagrani, A., Cho, M., Schmid, C.: Morevqa: Exploring modular reasoning models for video question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13235–13245 (2024)
2024
-
[26]
In: Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)
Park,J.,Ranasinghe,K.,Kahatapitiya,K.,Ryu,W.,Kim,D.,Ryoo,M.S.:Toomany frames, not all useful: Efficient strategies for long-form video qa. In: Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 3569–3588 (2026)
2026
-
[27]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
2021
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ren, S., Yao, L., Li, S., Sun, X., Hou, L.: Timechat: A time-sensitive multi- modal large language model for long video understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14313–14323 (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sarfraz, S., Murray, N., Sharma, V., Diba, A., Van Gool, L., Stiefelhagen, R.: Temporally-weighted hierarchical clustering for unsupervised action segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11225–11234 (2021)
2021
-
[30]
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., et al.: Longvu: Spatiotemporal adaptive compression for long video-language understanding. arXiv preprint arXiv:2410.17434 (2024) 18 M. Kim et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Sun, H., Lu, S., Wang, H., Chen, Q.G., Xu, Z., Luo, W., Zhang, K., Li, M.: Mdp3: A training-free approach for list-wise frame selection in video-llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24090–24101 (2025)
2025
-
[32]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tang, X., Qiu, J., Xie, L., Tian, Y., Jiao, J., Ye, Q.: Adaptive keyframe sampling for long video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29118–29128 (2025)
2025
-
[33]
In: European Conference on Computer Vision
Wang, X., Zhang, Y., Zohar, O., Yeung-Levy, S.: Videoagent: Long-form video understanding with large language model as agent. In: European Conference on Computer Vision. pp. 58–76. Springer (2024)
2024
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Z., Yu, S., Stengel-Eskin, E., Yoon, J., Cheng, F., Bertasius, G., Bansal, M.: Videotree: Adaptive tree-based video representation for llm reasoning on long videos. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3272–3283 (2025)
2025
-
[35]
In: European Conference on Computer Vision
Weng, Y., Han, M., He, H., Chang, X., Zhuang, B.: Longvlm: Efficient long video understanding via large language models. In: European Conference on Computer Vision. pp. 453–470. Springer (2024)
2024
-
[36]
Advances in Neural Information Processing Systems37, 28828–28857 (2024)
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context in- terleaved video-language understanding. Advances in Neural Information Processing Systems37, 28828–28857 (2024)
2024
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ye, J., Wang, Z., Sun, H., Chandrasegaran, K., Durante, Z., Eyzaguirre, C., Bisk, Y., Niebles, J.C., Adeli, E., Fei-Fei, L., et al.: Re-thinking temporal search for long- form video understanding. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8579–8591 (2025)
2025
-
[38]
Advances in Neural Information Processing Systems36, 76749–76771 (2023)
Yu, S., Cho, J., Yadav, P., Bansal, M.: Self-chained image-language model for video localization and question answering. Advances in Neural Information Processing Systems36, 76749–76771 (2023)
2023
-
[39]
arXiv preprint arXiv:2410.03226 (2024)
Yu, S., Jin, C., Wang, H., Chen, Z., Jin, S., Zuo, Z., Xu, X., Sun, Z., Zhang, B., Wu, J., et al.: Frame-voyager: Learning to query frames for video large language models. arXiv preprint arXiv:2410.03226 (2024)
-
[40]
In: International Conference on Learning Representations
Zeng, X., Li, K., Wang, C., Li, X., Jiang, T., Yan, Z., Li, S., Shi, Y., Yue, Z., Wang, Y., et al.: Timesuite: Improving mllms for long video understanding via grounded tuning. In: International Conference on Learning Representations. vol. 2025, pp. 38057–38081 (2025)
2025
-
[41]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhai, X., Mustafa, B., Kolesnikov, A., Beyer, L.: Sigmoid loss for language image pre- training. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 11975–11986 (2023)
2023
-
[42]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Zhang, C., Lu, T., Islam, M.M., Wang, Z., Yu, S., Bansal, M., Bertasius, G.: A simple llm framework for long-range video question-answering. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 21715–21737 (2024)
2024
-
[43]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, S., Yang, J., Yin, J., Luo, Z., Luan, J.: Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22056–22065 (2025)
2025
-
[45]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
ReQuest 19 In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., et al.: Mlvu: Benchmarking multi-task long video understanding. ReQuest 19 In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13691–13701 (2025)
2025
-
[47]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zou, B., Yang, C., Qiao, Y., Quan, C., Zhao, Y.: Language-aware visual seman- tic distillation for video question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27113–27123 (2024) ReQuest 1 ReQuest: Rethinking-based Question-Aware Frame Selection for Long-Form Video QA Supplementary Material The video...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.