Beyond Accuracy: Evaluating Efficiency, Robustness and Explainability in Deep Learning for Malaria Diagnosis
Pith reviewed 2026-06-28 23:24 UTC · model grok-4.3
The pith
Lightweight deep learning models match heavier ones in malaria diagnosis accuracy on the NLM-Malaria dataset with no statistically significant differences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
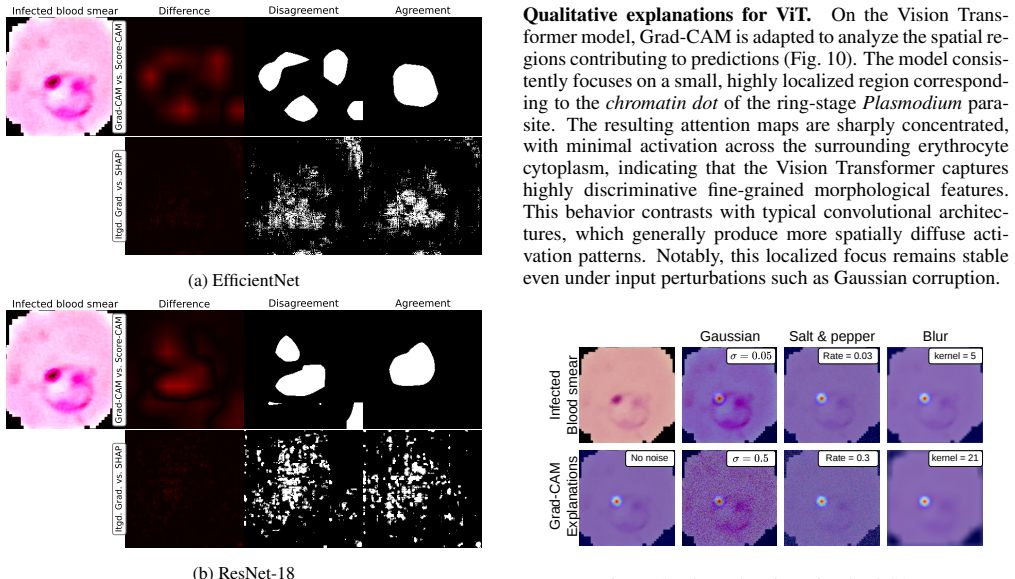
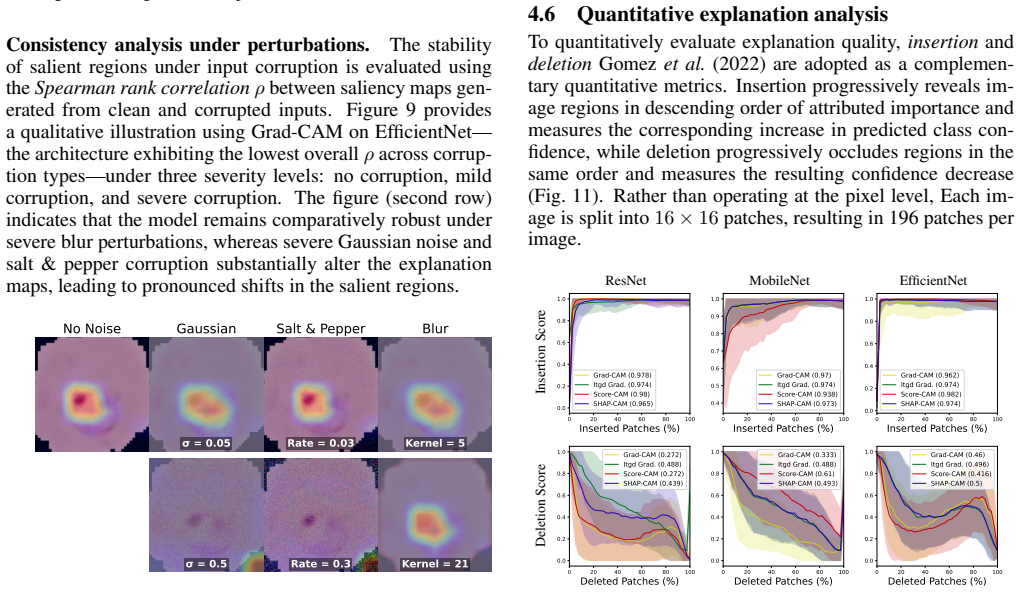
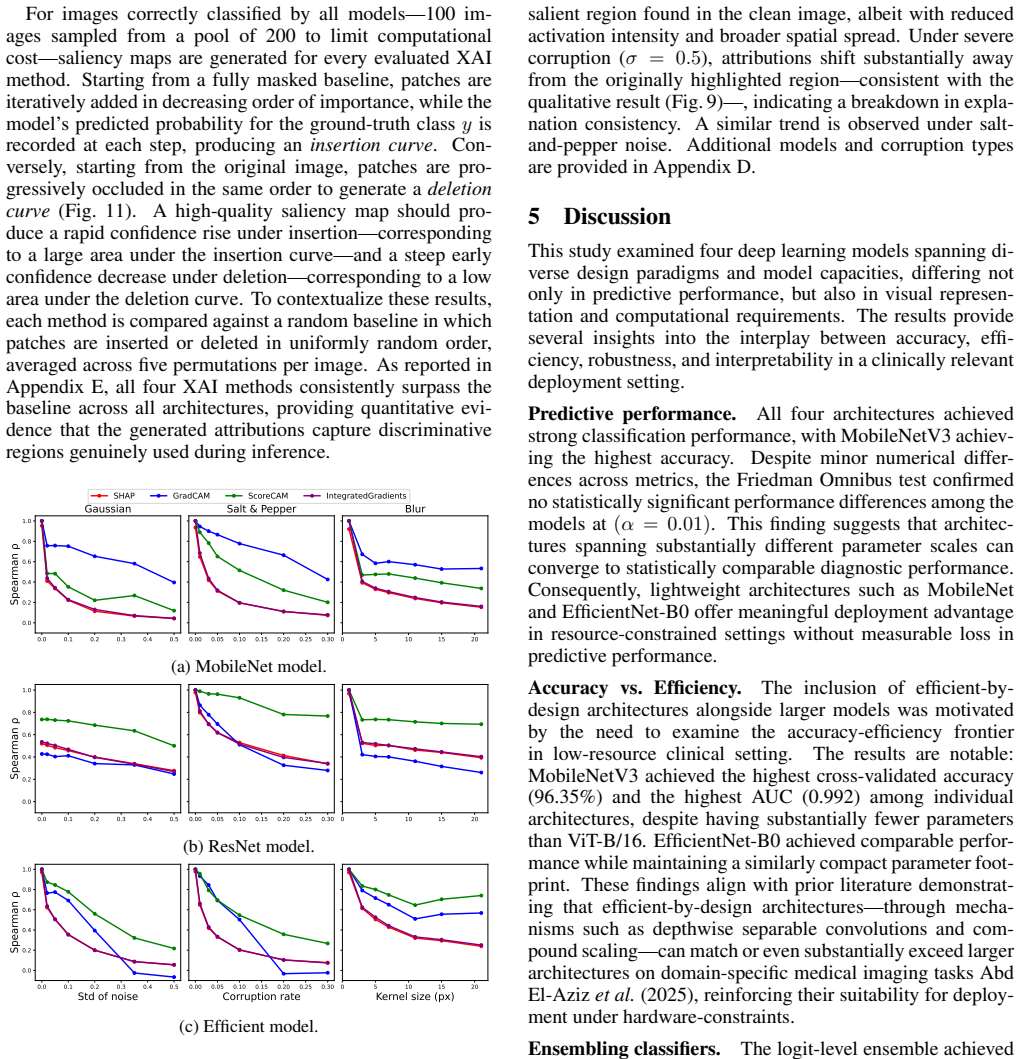
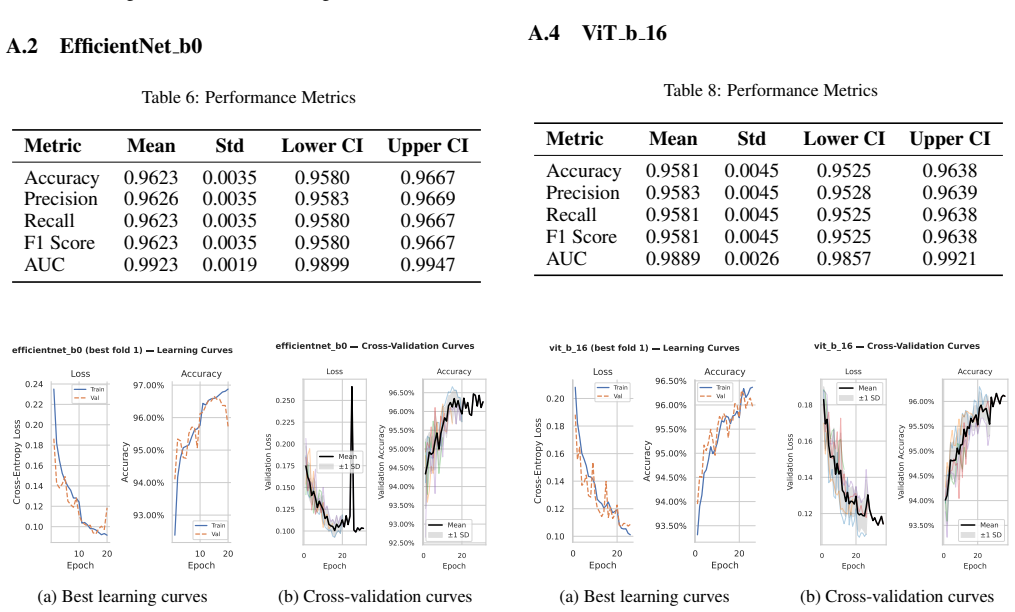
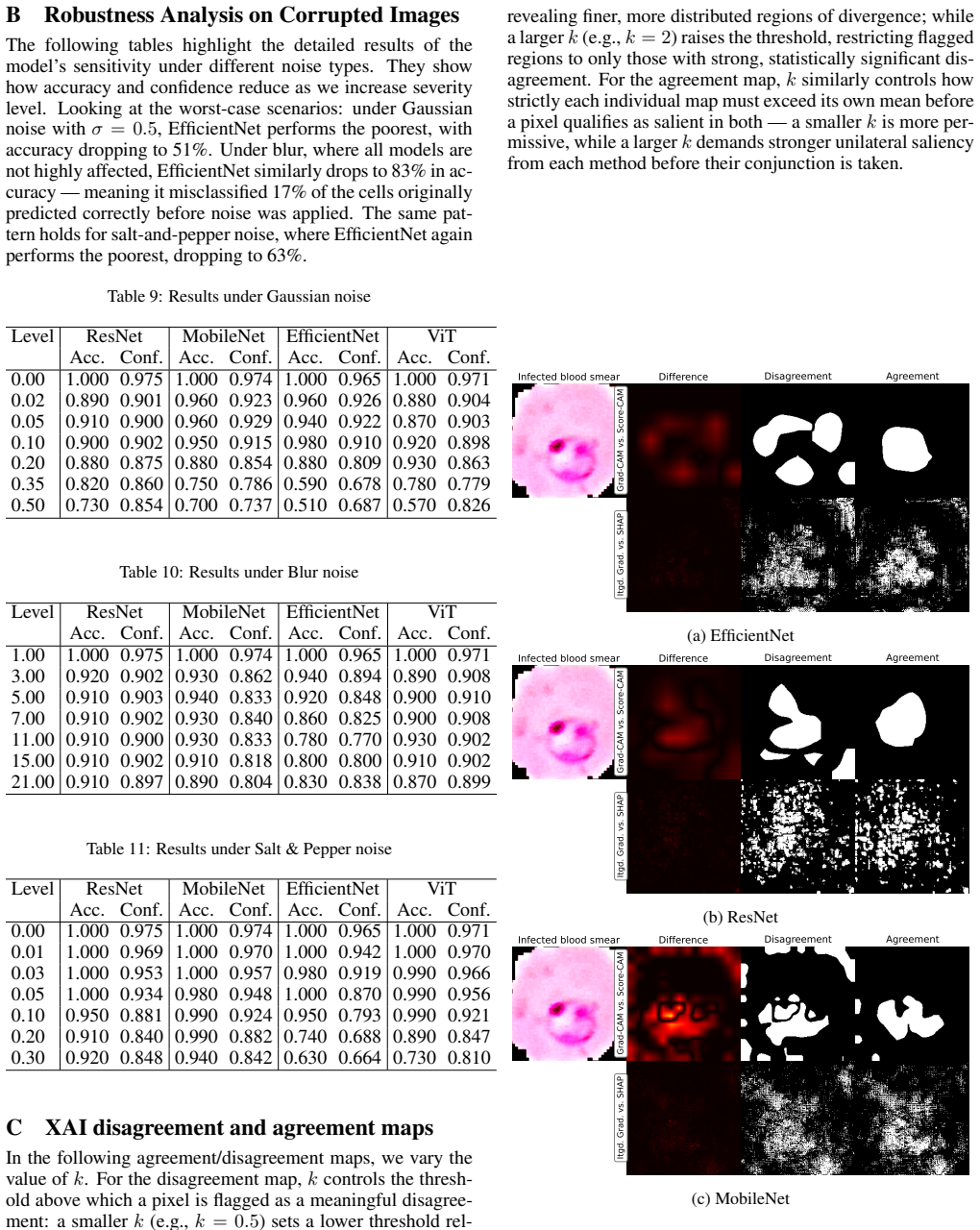
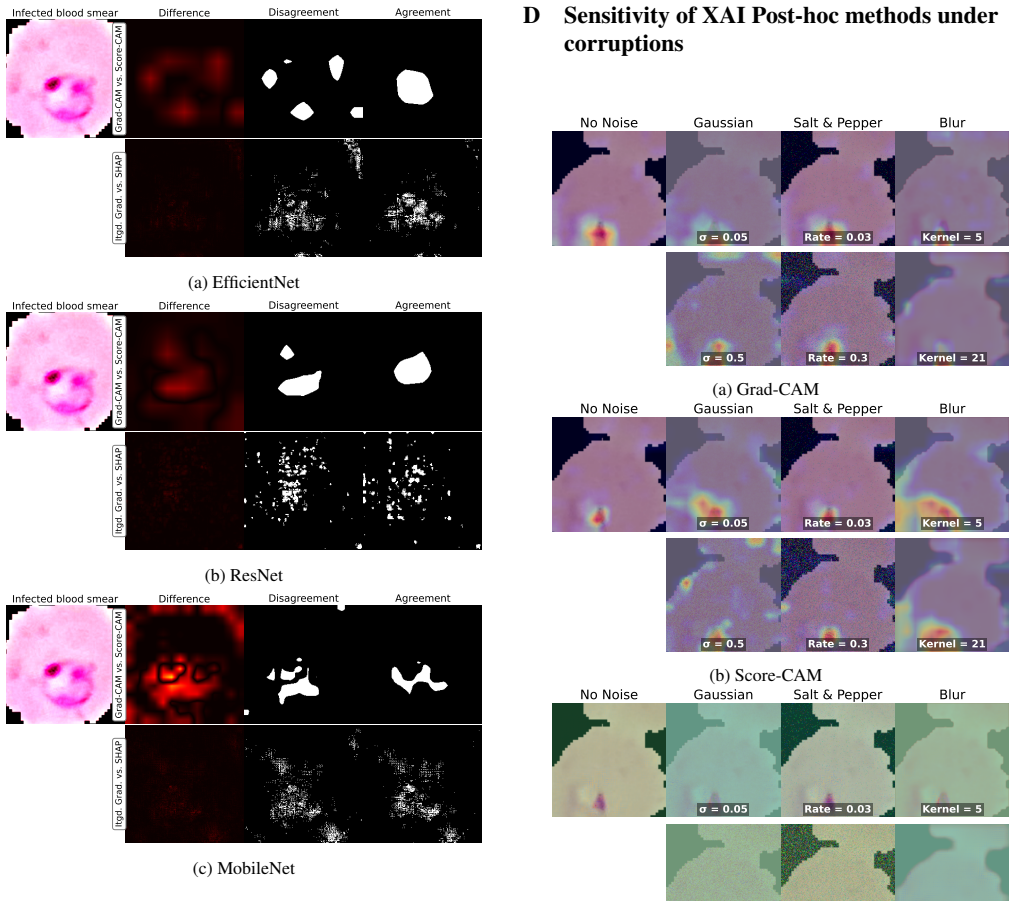
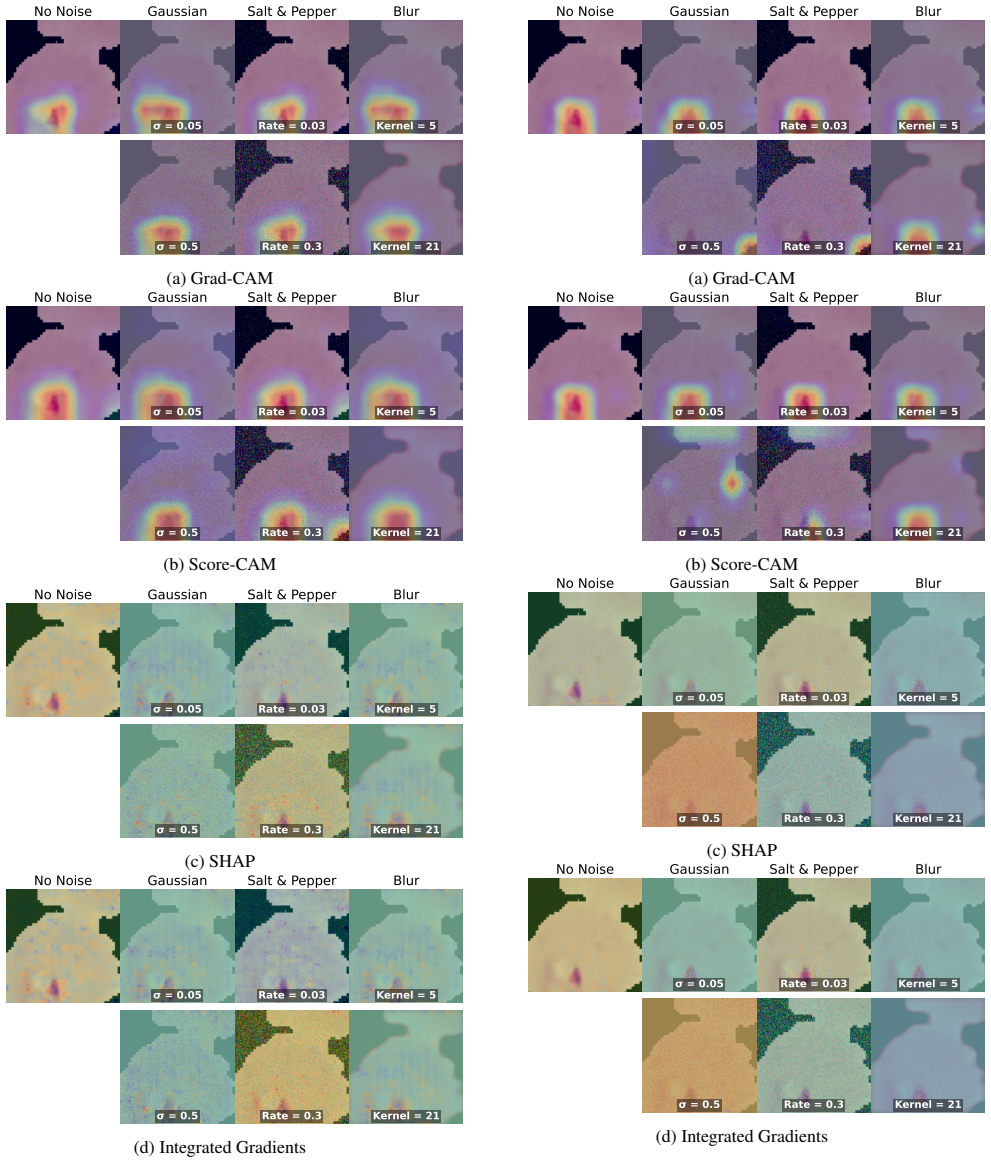
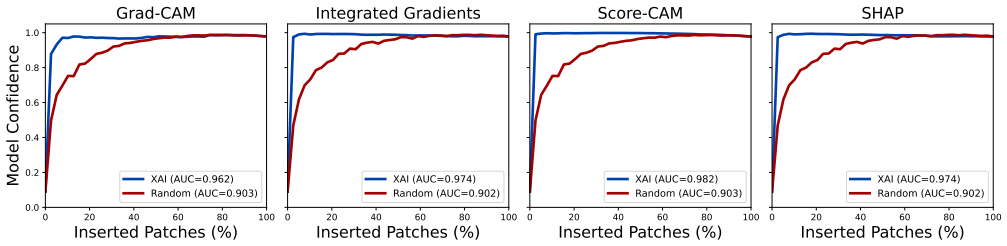
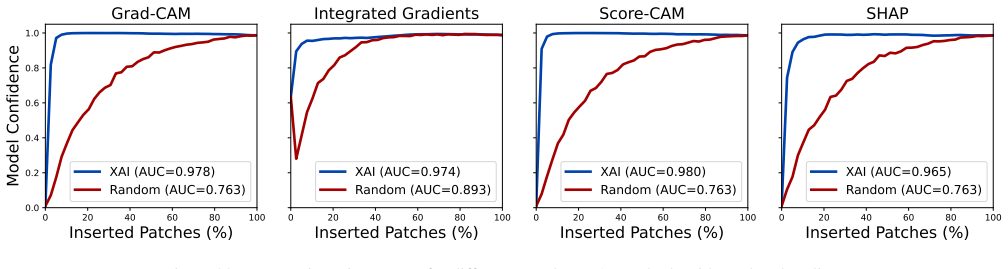
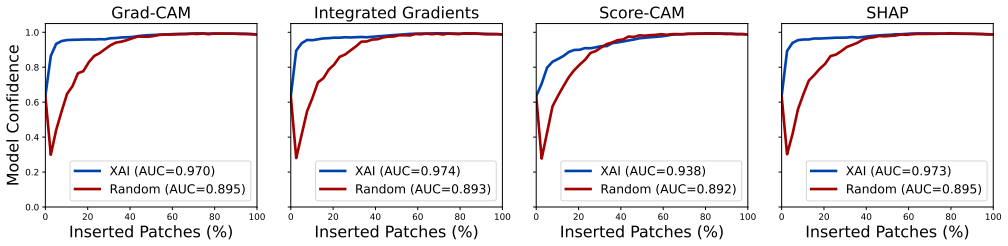
Lightweight, efficient-by-design models match their heavier counterparts in predictive performance on the NLM-Malaria dataset, with the Friedman test confirming no statistically significant differences. CAM-based XAI methods consistently localize diagnostically relevant regions, whereas fine-grained attribution methods produce less targeted explanations particularly with heavier backbones. Robustness tests under three image corruption types show model confidence degrades faster than accuracy, offering a potential signal for human review, yet no XAI method remains robust as explanation quality drops at corruption levels plausible in clinical settings even when predictions stay accurate.
What carries the argument
Joint benchmarking of four models across efficiency, robustness to three image corruptions, and post-hoc explainability via CAM and fine-grained attribution methods.
If this is right
- Lightweight models support deployment in resource-constrained settings without loss of predictive performance.
- CAM-based methods are preferable over fine-grained attribution for producing targeted explanations of malaria predictions.
- Monitoring model confidence can flag images for human review when corruption may be present.
- Explanation reliability must be separately validated because it can fail while accuracy holds under realistic image noise.
Where Pith is reading between the lines
- Clinical rollout would benefit from additional tests on locally collected images to verify the performance equivalence holds outside the NLM-Malaria set.
- Pairing lightweight models with confidence thresholds could create a practical human-in-the-loop workflow for malaria screening.
- Developing training techniques that preserve explanation quality under common degradations like blur or noise would strengthen reliability for real-world use.
Load-bearing premise
The NLM-Malaria dataset together with the three chosen corruption types sufficiently represent the variability and noise encountered in actual clinical malaria diagnosis workflows in resource-constrained settings.
What would settle it
A new collection of blood-smear images from field clinics showing either a statistically significant accuracy gap favoring heavier models or stable XAI performance under the same corruption types.
Figures




read the original abstract
Malaria remains a leading cause of mortality in sub-Saharan Africa, where scarce diagnostic infrastructure makes timely, accurate diagnosis particularly challenging. While deep learning offers a compelling path toward automated malaria screening, clinical adoption is hindered by computational cost and opacity in decision-making. This work benchmarks four deep learning models spanning a wide range of designed design architectures and model capacities on the NLM-Malaria dataset, jointly evaluating predictive performance, robustness, and post-hoc explainability. We find that lightweight, efficient-by-design models match their heavier counterparts in predictive performance, and the Friedman test confirms no statistically significant performance differences. CAM-based XAI methods consistently localize diagnostically relevant regions, while fine-grained attribution methods produce less targeted explanations, particularly with heavier backbones. Robustness evaluation under three types of image corruption further reveals that model confidence degrades faster than accuracy, providing a practical signal for human review. However, no XAI method is robust to corruption, with explanation reliability degrading at noise levels plausible in clinical practice, even when predictions remain accurate. These findings support the deployment of lightweight architectures for malaria diagnosis in resource-constrained settings, while highlighting the vulnerability of post-hoc explanations as an important consideration for responsible clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks four deep learning models spanning a range of architectures and capacities on the NLM-Malaria dataset for automated malaria diagnosis. It jointly assesses predictive performance (accuracy and Friedman test for statistical significance), robustness under three types of image corruption, and post-hoc explainability via CAM-based methods versus fine-grained attribution techniques. Central claims are that lightweight efficient-by-design models match heavier counterparts with no statistically significant performance differences, CAM methods consistently localize diagnostically relevant regions while fine-grained methods are less targeted (especially on heavier backbones), model confidence degrades faster than accuracy under corruption (providing a human-review signal), and no XAI method remains robust to corruption even at noise levels where predictions stay accurate. These results are invoked to support deployment of lightweight models in resource-constrained settings while flagging XAI vulnerabilities for responsible clinical use.
Significance. If the empirical findings hold under broader validation, the work is significant for medical imaging AI by demonstrating that efficiency need not trade off against accuracy on this task and by providing a practical robustness signal via confidence. The joint evaluation of efficiency, robustness, and explainability addresses a real gap in clinical translation literature. Explicit use of the Friedman test and the observation that confidence drops precede accuracy loss are concrete strengths that could inform deployment protocols. The paper does not ship machine-checked proofs or parameter-free derivations, but the multi-metric benchmark itself is a useful contribution if the dataset and corruptions prove representative.
major comments (1)
- [Abstract] Abstract and deployment recommendation: the claim that results 'support the deployment of lightweight architectures for malaria diagnosis in resource-constrained settings' is load-bearing for the paper's applied conclusion, yet rests on NLM-Malaria plus three unspecified corruptions being representative of field conditions (variable staining, microscope artifacts, lighting, demographics in sub-Saharan Africa). No external validation set or comparison to real clinical images from target settings is described, so equivalence, robustness ordering, and XAI degradation findings could be benchmark-specific artifacts.
minor comments (2)
- [Abstract] The abstract refers to 'three types of image corruption' without naming them or their parameters; this detail should appear in the abstract or first paragraph of the methods section for immediate clarity.
- The description of CAM versus fine-grained attribution would benefit from a brief statement of the exact methods and backbones used (e.g., Grad-CAM on ResNet vs. MobileNet) rather than generic labels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, particularly on the generalizability of our deployment claims. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and deployment recommendation: the claim that results 'support the deployment of lightweight architectures for malaria diagnosis in resource-constrained settings' is load-bearing for the paper's applied conclusion, yet rests on NLM-Malaria plus three unspecified corruptions being representative of field conditions (variable staining, microscope artifacts, lighting, demographics in sub-Saharan Africa). No external validation set or comparison to real clinical images from target settings is described, so equivalence, robustness ordering, and XAI degradation findings could be benchmark-specific artifacts.
Authors: We agree this is a substantive limitation. The NLM-Malaria dataset is a standard but controlled benchmark from a single source and does not capture the full spectrum of real-world clinical variability (e.g., staining inconsistencies, microscope artifacts, lighting conditions, or demographic differences across sub-Saharan Africa). Our three synthetic corruption types are approximations rather than direct matches to field data, and no external validation on target clinical images was performed. Thus, the observed model equivalence, robustness orderings, and XAI degradation patterns could indeed be benchmark-specific. We cannot claim direct support for deployment without further evidence. In revision we will (1) qualify the abstract claim to 'These findings indicate the potential suitability of lightweight architectures for malaria diagnosis in resource-constrained settings, subject to additional validation on diverse clinical data' and (2) add an explicit limitations paragraph in the discussion reiterating the benchmark-specific nature of the results and calling for external validation. This constitutes a partial revision, as new external datasets cannot be introduced without additional data collection. revision: partial
Circularity Check
Purely empirical benchmarking with no derivations or self-referential reductions
full rationale
The paper conducts direct experimental comparisons of four DL models on the NLM-Malaria dataset, measuring accuracy, Friedman-test significance, robustness to three image corruptions, and post-hoc XAI localization quality. No equations, parameter fits, or predictive derivations appear; claims follow immediately from reported metrics without reduction to prior results by construction. No self-citations serve as load-bearing uniqueness theorems or ansatzes. The evaluation chain is self-contained against external benchmarks and contains no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Salvador Garc ´ıa, Alberto Fern ´andez, Juli ´an Luengo, and Francisco Herrera. Advanced nonparametric tests for mul- tiple comparisons in the design of experiments in computa- tional intelligence and data mining: Experimental analysis of power.Information sciences, 180(10):2044–2064,
2044
-
[3]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and pertur- bations.arXiv preprint arXiv:1903.12261,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[4]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco An- dreetto, and Hartwig Adam. Mobilenets: Efficient con- volutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Cuong Manh Nguyen and Truong-Son Hy. Efficient deep learning for medical imaging: Bridging the gap between high-performance ai and clinical deployment.arXiv preprint arXiv:2602.00910,
-
[6]
World Health Organization,
World Health Organization.Global technical strategy for malaria 2016-2030. World Health Organization,
2016
-
[7]
Wojciech Samek, Thomas Wiegand, and Klaus-Robert M¨uller. Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models.arXiv preprint arXiv:1708.08296,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.