Would you still call this Dax? Novel Visual References in VLMs and Humans
Pith reviewed 2026-06-28 06:34 UTC · model grok-4.3
The pith
Vision-language models struggle to acquire novel visual concepts in context when they contradict prior knowledge and overgeneralize more than humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
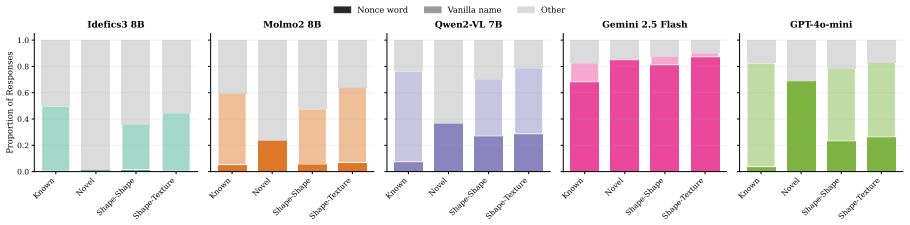
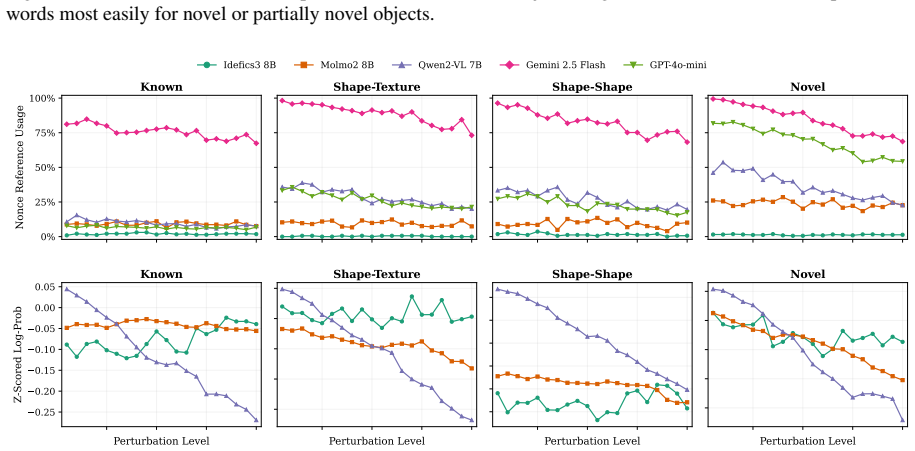
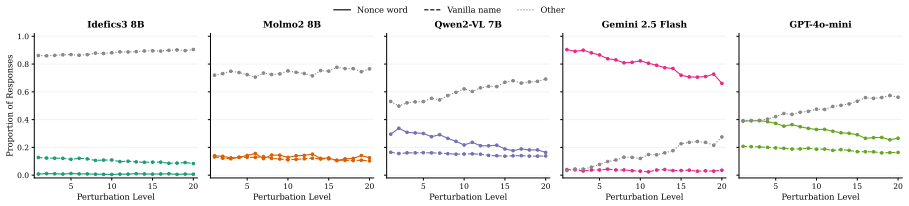
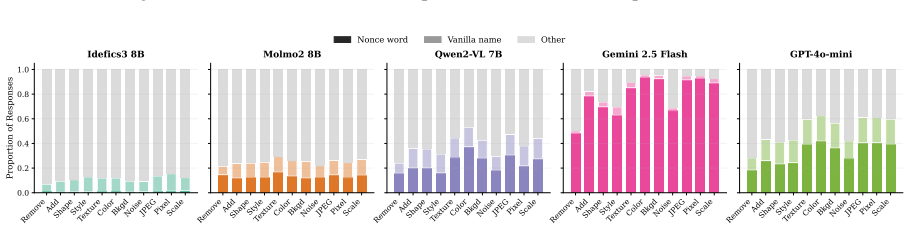
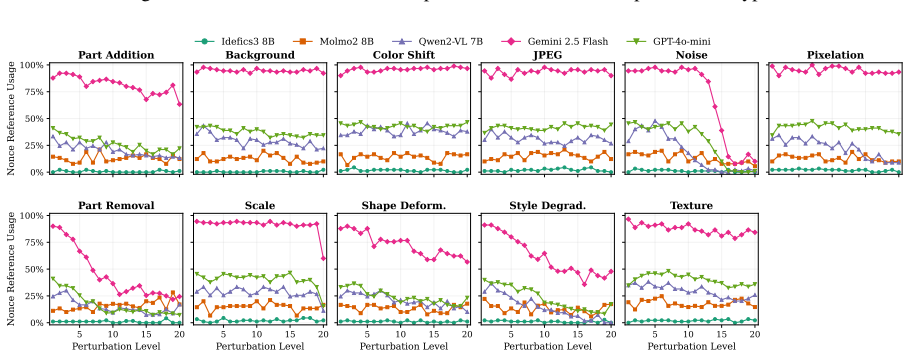
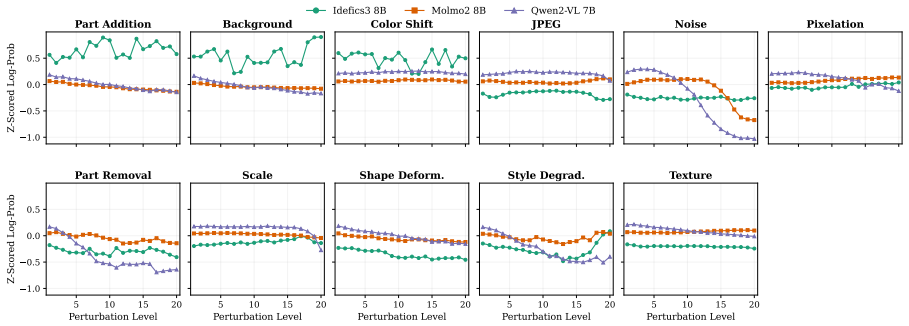
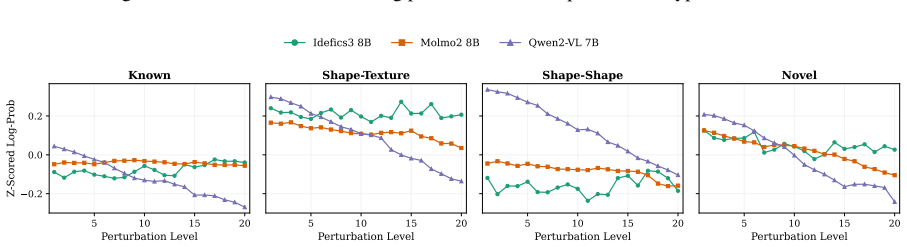
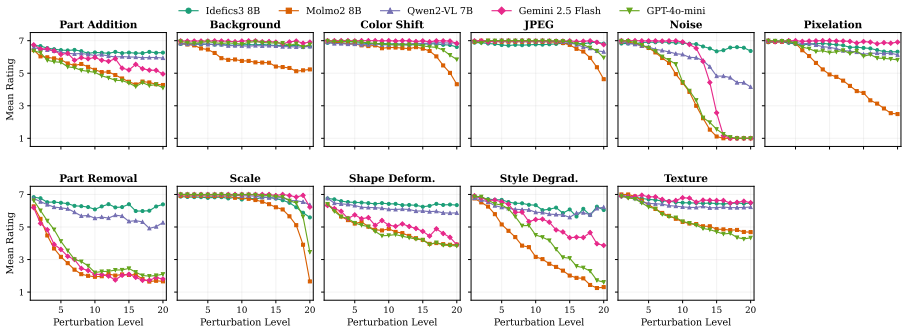
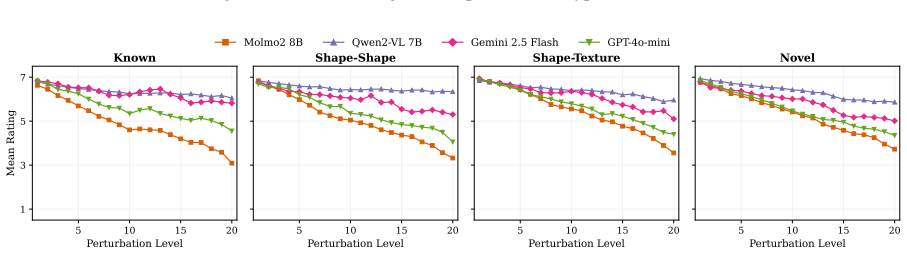
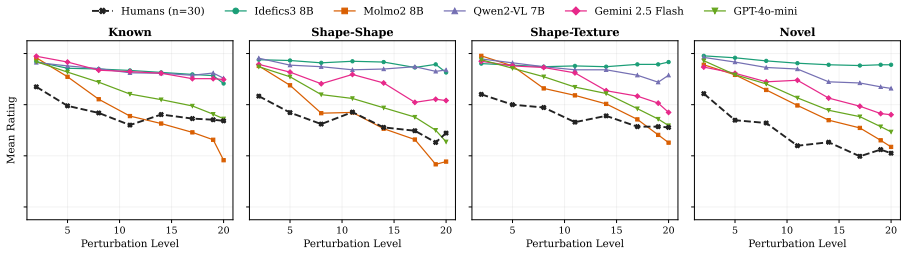
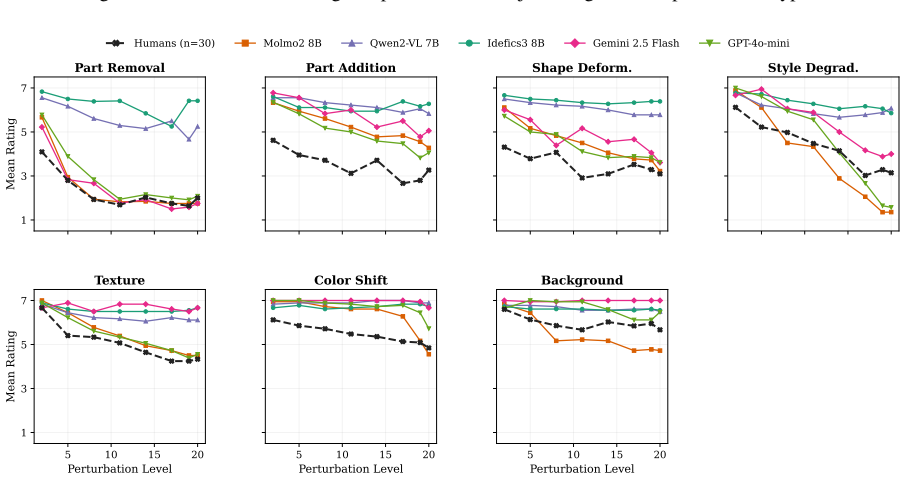
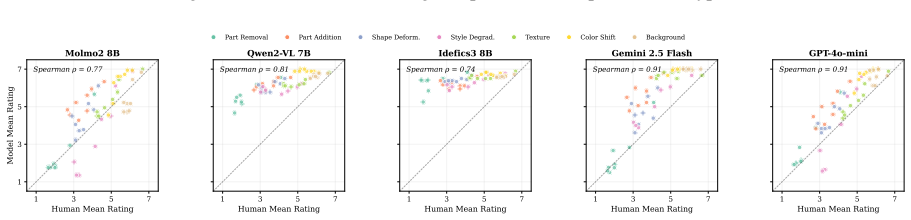
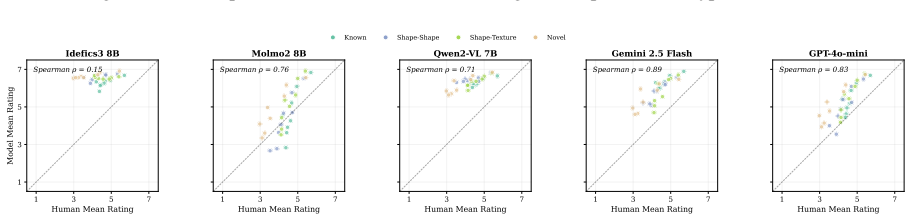
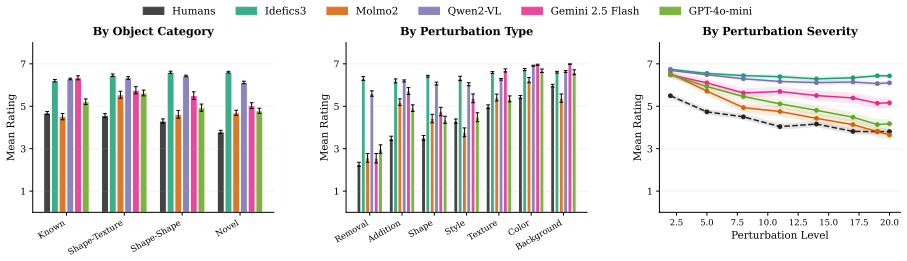
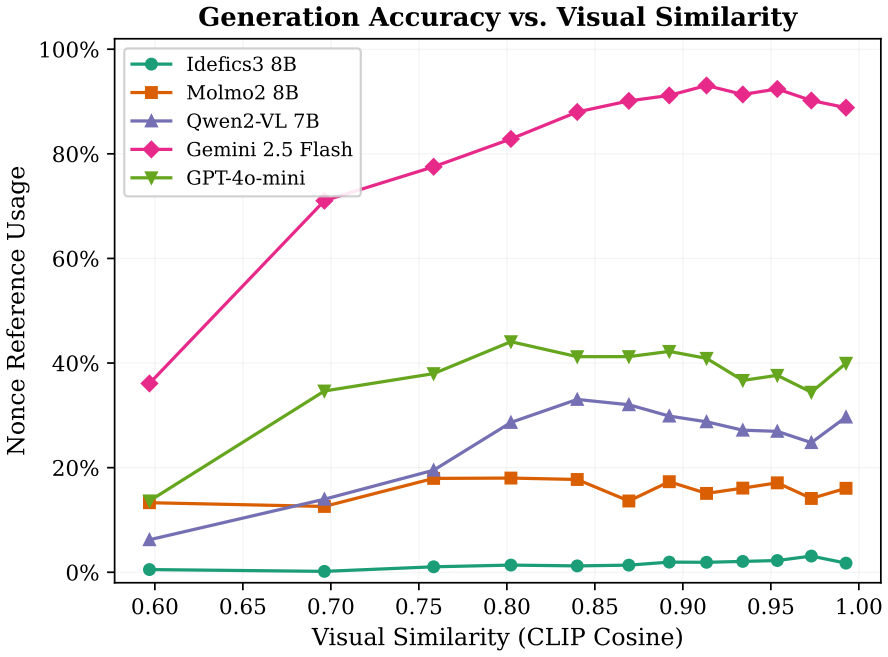
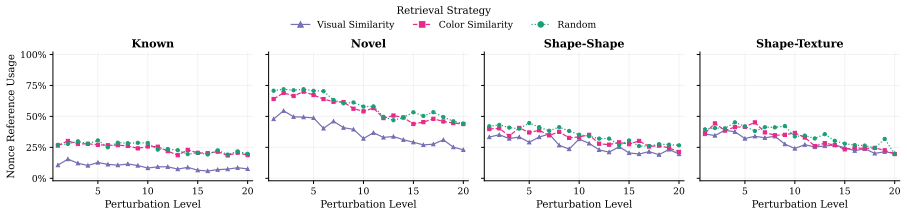
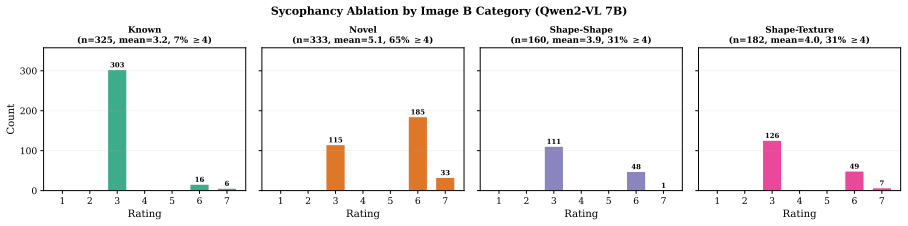
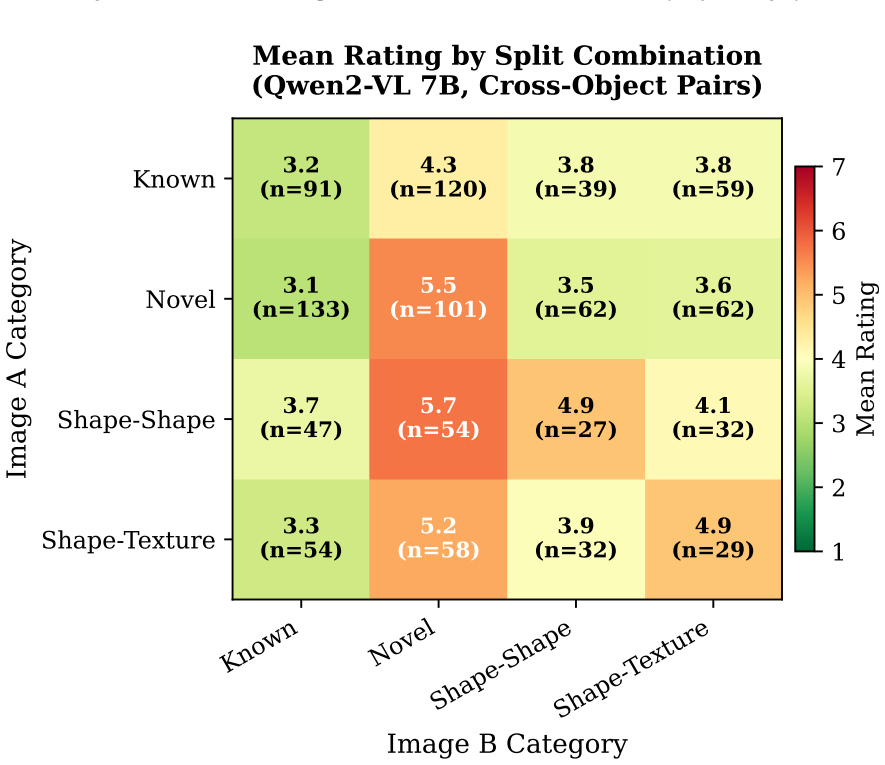
The authors claim that vision-language models struggle to acquire novel concepts in-context when they contradict prior knowledge, and while models and humans show correlated sensitivity to visual perturbations, models significantly overgeneralize, extending learned labels to stimuli that humans reject, as shown through evaluations on the NVRD dataset.
What carries the argument
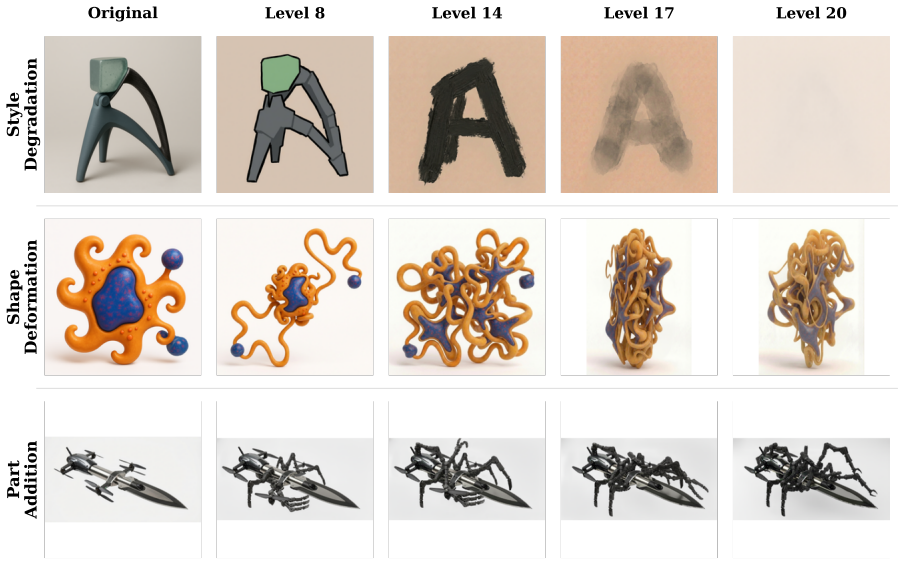
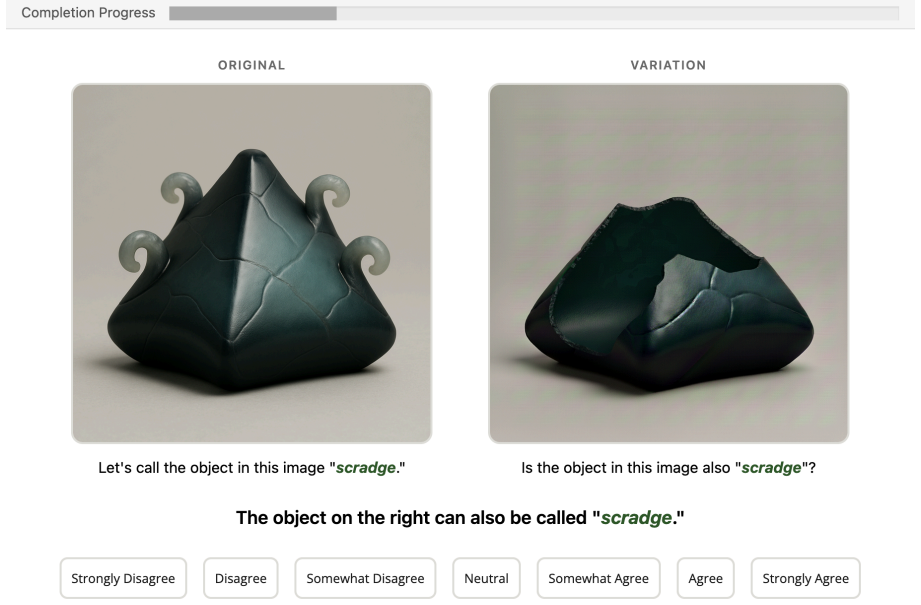
The Novel Visual References Dataset (NVRD), a set of entirely novel visual concepts constructed from scratch with increasing perturbations to measure in-context acquisition and generalization boundaries.
If this is right
- Models will underperform on acquiring labels for new objects that clash with pre-trained knowledge.
- Sensitivity to visual perturbations will correlate between models and humans, yet models will accept a wider range of variants.
- NVRD provides a benchmark for testing visual concept learning that avoids familiar objects.
- In-context adaptation in VLMs faces limits when new information directly conflicts with existing representations.
Where Pith is reading between the lines
- Training methods may need explicit ways to override or compartmentalize conflicting prior knowledge during in-context updates.
- Real-world uses like robotics or interactive systems could face repeated failures when encountering truly new objects.
- The gap might narrow if models incorporate uncertainty estimates that better match human rejection thresholds.
- Extending the approach to video or multimodal sequences could reveal whether the overgeneralization pattern holds over time.
Load-bearing premise
The constructed concepts in NVRD genuinely contradict models' pre-training and the human judgments form a reliable baseline for comparison.
What would settle it
A test where models acquire the novel labels in context and restrict them to exactly the same perturbed images that humans accept would falsify the overgeneralization claim.
Figures






read the original abstract
Vision-language models (VLMs), like human learners, are frequently exposed to new visual concepts, but how they map novel visual references to language after exposure remains largely underexplored, particularly when those references contradict prior knowledge from pre-training. To study this, we present the Novel Visual References Dataset (NVRD): 19,176 images spanning 90 visual concepts across different levels of visual novelty, each with up to 20 increasingly perturbed versions of the original object to probe generalization. Unlike prior work on visual augmentations of familiar concepts, NVRD comprises entirely novel, open-ended stimuli constructed from scratch, mirroring how humans encounter genuinely new concepts. We evaluate 3 open- and 2 closed-source models alongside 2,400 human judgments for direct human-model comparison, and find that (i) models struggle to acquire novel concepts in-context when they contradict prior knowledge, and (ii) while models and humans show correlated sensitivity to visual perturbations, models significantly overgeneralize, extending learned labels to stimuli that humans reject. We contribute NVRD as a corpus and benchmark for research on visual concept learning in both humans and machines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Novel Visual References Dataset (NVRD) comprising 19,176 images across 90 visual concepts, each with up to 20 perturbed versions, constructed as entirely novel stimuli. It evaluates three open-source and two closed-source VLMs against 2,400 human judgments on in-context learning of these concepts, reporting that models struggle to acquire novel concepts contradicting prior knowledge and that models overgeneralize relative to humans despite correlated sensitivity to visual perturbations.
Significance. If the results hold after verification that the concepts lie outside pre-training distributions, the contribution of NVRD as a benchmark would be useful for studying differences in visual concept acquisition between VLMs and humans.
major comments (1)
- [Abstract] Abstract: The central claim that models 'struggle to acquire novel concepts in-context when they contradict prior knowledge' requires that the 90 base concepts are outside the models' pre-training distribution. No verification is reported (zero-shot accuracy on unperturbed base images, nearest-neighbor distances in embedding space to LAION/ImageNet classes, or human-model agreement rates on the originals). Without this check, the observed effects cannot be distinguished from ordinary recognition failure.
minor comments (2)
- The abstract states 'up to 20 increasingly perturbed versions' per concept but provides no details on the perturbation generation process, the exact number of versions per concept, or how perturbation levels were calibrated.
- The number of human participants and the exact protocol for collecting the 2,400 judgments (e.g., trial structure, exclusion criteria) are not summarized.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting an important point regarding verification of concept novelty. We address the major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that models 'struggle to acquire novel concepts in-context when they contradict prior knowledge' requires that the 90 base concepts are outside the models' pre-training distribution. No verification is reported (zero-shot accuracy on unperturbed base images, nearest-neighbor distances in embedding space to LAION/ImageNet classes, or human-model agreement rates on the originals). Without this check, the observed effects cannot be distinguished from ordinary recognition failure.
Authors: We agree that explicit verification is necessary to distinguish in-context acquisition difficulties from simple recognition failures on the base concepts. The manuscript describes the 90 concepts as 'entirely novel stimuli constructed from scratch' and contrasts them with prior work on augmentations of familiar concepts, but does not report the specific checks suggested (zero-shot accuracy on unperturbed images, embedding distances to LAION/ImageNet, or human-model agreement on the originals). We will add these analyses to the revised version, including zero-shot VLM performance on the base images and nearest-neighbor analyses where computationally feasible, to directly support the central claim. revision: yes
Circularity Check
No circularity: empirical dataset construction and evaluation with no derivations or self-referential fits
full rationale
The paper presents an empirical benchmark (NVRD) consisting of 90 novel visual concepts and perturbed images, evaluated via model inference and 2400 human judgments. No equations, parameter fits, uniqueness theorems, or derivations appear in the provided text. Claims of novelty rest on construction statements rather than any self-referential reduction (e.g., no fitted parameter is relabeled as a prediction, and no self-citation chain supports a load-bearing premise). The central findings on model overgeneralization are direct experimental outcomes, not tautological restatements of inputs. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Intriguing properties of generative classifiers , author=. International Conference on Learning Representations , year=
-
[2]
Concepts and Conceptual Structure , volume =
Medin, Doug , year =. Concepts and Conceptual Structure , volume =. American Psychologist , doi =
-
[3]
Categories and induction in young children , journal =. 1986 , issn =. doi:https://doi.org/10.1016/0010-0277(86)90034-X , url =
-
[4]
The Essential Child: Origins of Essentialism in Everyday Thought , isbn =
Gelman, Susan , year =. The Essential Child: Origins of Essentialism in Everyday Thought , isbn =. The Essential Child. Origins of Essentialism in Everday Thought. , doi =
-
[5]
, title =
Diesendruck, Gil and Gelman, Susan A. , title =. Psychonomic Bulletin & Review , volume =. 1999 , month = jun, doi =
1999
-
[6]
, title =
Keil, Frank C. , title =
-
[7]
, author=
The role of theories in conceptual coherence. , author=. Psychological review , year=
-
[8]
2024 , eprint=
Toward a Holistic Evaluation of Robustness in CLIP Models , author=. 2024 , eprint=
2024
-
[9]
Word and Object , publisher =
Willard Van Orman Quine , title =. Word and Object , publisher =. 1960 , pages =
1960
-
[10]
Syntactic context and the shape bias in children's and adults' lexical learning , journal =. 1992 , issn =. doi:https://doi.org/10.1016/0749-596X(92)90040-5 , url =
-
[11]
Monographs of the society for research in child development , pages=
The mutual exclusivity bias in children's word learning , author=. Monographs of the society for research in child development , pages=. 1989 , publisher=
1989
-
[12]
Journal of memory and language , volume=
Object shape, object function, and object name , author=. Journal of memory and language , volume=. 1998 , publisher=
1998
-
[13]
Object properties and knowledge in early lexical learning , author =. Child Development , year =. doi:10.1111/j.1467-8624.1991.tb01547.x , url =
-
[14]
Recognition-by-components: A theory of human image understanding , author =. Psychological Review , year =. doi:10.1037/0033-295X.94.2.115 , url =
-
[15]
2021 , eprint=
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization , author=. 2021 , eprint=
2021
-
[16]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author =. arXiv preprint arXiv:2507.06261 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
International Journal of Computer Vision , volume=
Compositional Convolutional Neural Networks: A Robust and Interpretable Model for Object Recognition under Occlusion , author=. International Journal of Computer Vision , volume=. 2021 , doi=
2021
-
[18]
Cognitive Psychology , volume=
Priming contour-deleted images: Evidence for intermediate representations in visual object recognition , author=. Cognitive Psychology , volume=. 1991 , doi=
1991
-
[19]
International Conference on Learning Representations , year=
Can We Talk Models Into Seeing the World Differently? , author=. International Conference on Learning Representations , year=
-
[20]
2023 , doi=
Ma, Zixian and Hong, Jerry and Gul, Mustafa Omer and Gandhi, Mona and Gao, Irena and Krishna, Ranjay , booktitle=. 2023 , doi=
2023
-
[21]
Proceedings of the Royal Society of London
Representation and recognition of the spatial organization of three-dimensional shapes , author=. Proceedings of the Royal Society of London. Series B, Biological Sciences , volume=. 1978 , doi=
1978
-
[22]
ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models , url =
Barbu, Andrei and Mayo, David and Alverio, Julian and Luo, William and Wang, Christopher and Gutfreund, Dan and Tenenbaum, Josh and Katz, Boris , booktitle =. ObjectNet: A large-scale bias-controlled dataset for pushing the limits of object recognition models , url =
-
[23]
International Conference on Learning Representations , year=
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations , author=. International Conference on Learning Representations , year=
-
[24]
, booktitle=
Singh, Bharat and Davis, Larry S. , booktitle=. An Analysis of Scale Invariance in Object Detection --. 2018 , doi=
2018
-
[25]
and Ecker, Alexander S
Gatys, Leon A. and Ecker, Alexander S. and Bethge, Matthias , booktitle=. Image Style Transfer Using Convolutional Neural Networks , year=
-
[26]
European Conference on Computer Vision , pages=
Recognition in Terra Incognita , author=. European Conference on Computer Vision , pages=. 2018 , doi=
2018
-
[27]
International Conference on Learning Representations , year=
Noise or Signal: The Role of Image Backgrounds in Object Recognition , author=. International Conference on Learning Representations , year=
-
[28]
and Presnell, Lynn , year =
Tanaka, J. and Presnell, Lynn , year =. Color diagnosticity in object recognition , volume =. Percept. Psychophys. , doi =
-
[29]
Advances in Neural Information Processing Systems , volume=
Multimodal Few-Shot Learning with Frozen Language Models , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[30]
and Yu, Chen , title =
Smith, Linda B. and Yu, Chen , title =. Cognition , year =
-
[31]
World-to-Words: Grounded Open Vocabulary Acquisition through Fast Mapping in Vision-Language Models
Ma, Ziqiao and Pan, Jiayi and Chai, Joyce. World-to-Words: Grounded Open Vocabulary Acquisition through Fast Mapping in Vision-Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.31
-
[32]
2025 , eprint=
Text Speaks Louder than Vision: ASCII Art Reveals Textual Biases in Vision-Language Models , author=. 2025 , eprint=
2025
-
[33]
2024 , eprint=
Visually Grounded Speech Models have a Mutual Exclusivity Bias , author=. 2024 , eprint=
2024
-
[34]
1989 , publisher=
Categorization and Naming in Children: Problems of Induction , author=. 1989 , publisher=
1989
-
[35]
2025 , eprint=
Mixed Signals: Decoding VLMs' Reasoning and Underlying Bias in Vision-Language Conflict , author=. 2025 , eprint=
2025
-
[36]
2023 , eprint=
Debiasing Vision-Language Models via Biased Prompts , author=. 2023 , eprint=
2023
-
[37]
International Conference on Learning Representations , year=
Grounded Language Learning Fast and Slow , author=. International Conference on Learning Representations , year=
-
[38]
2018 , eprint=
Assessing Shape Bias Property of Convolutional Neural Networks , author=. 2018 , eprint=
2018
-
[39]
Proceedings of the 25th Conference on Computational Natural Language Learning , pages=
The Emergence of the Shape Bias Results from Communicative Efficiency , author=. Proceedings of the 25th Conference on Computational Natural Language Learning , pages=. 2021 , publisher=
2021
-
[40]
ImageNet-trained
Burgert, Tom and Stoll, Oliver and Rota, Paolo and Demir, Beg\". ImageNet-trained. Advances in Neural Information Processing Systems , year=
-
[41]
Cognitive Psychology , volume=
Children’s use of mutual exclusivity to constrain the meanings of words , author=. Cognitive Psychology , volume=. 1988 , publisher=
1988
-
[42]
and Brendel, Wieland , booktitle=
Geirhos, Robert and Rubisch, Patricia and Michaelis, Claudio and Bethge, Matthias and Wichmann, Felix A. and Brendel, Wieland , booktitle=. ImageNet-trained. 2019 , url=
2019
-
[43]
2024 , eprint=
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models , author=. 2024 , eprint=
2024
-
[44]
Barbara Landau and Smith, Linda B. and Jones, Susan S. The importance of shape in early lexical learning. Cognitive Development. 1988. doi:10.1016/0885-2014(88)90014-7
-
[45]
Language Learning and Development , volume=
Dynamic noun generalization , author=. Language Learning and Development , volume=. 2007 , publisher=
2007
-
[46]
Constraints children place on word meanings , journal =. 1990 , issn =. doi:https://doi.org/10.1016/0364-0213(90)90026-S , url =
-
[47]
Young Children Extend Novel Words at the Basic Level: Evidence for the Principle of Categorical Scope , volume =
Golinkoff, Roberta and Shuff-Bailey, Margaret and Jaakkola, Kelly and Ruan, Wenjun , year =. Young Children Extend Novel Words at the Basic Level: Evidence for the Principle of Categorical Scope , volume =. Developmental Psychology , doi =
-
[48]
PLoS Computational Biology , volume=
Deep convolutional networks do not classify based on global object shape , author=. PLoS Computational Biology , volume=. 2018 , doi=
2018
-
[49]
Journal of Experimental Child Psychology , volume=
Clarifying the role of shape in children's taxonomic assumption , author=. Journal of Experimental Child Psychology , volume=. 1992 , doi=
1992
-
[50]
Is the Acquisition of Basic-Colour Terms in Young Children Constrained? , volume =
Pitchford, Nicola and Mullen, Kathy , year =. Is the Acquisition of Basic-Colour Terms in Young Children Constrained? , volume =. Perception , doi =
-
[51]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
Signatures of Domain-General Categorization Mechanisms in ColorWord Learning , author=. Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
-
[52]
Waxman , title =
Sandra R. Waxman , title =. Psychology of Learning and Motivation , volume =. 1998 , publisher =
1998
-
[53]
Principles that are invoked in the acquisition of words, but not facts , volume =
Waxman, Sandra and Booth, Amy , year =. Principles that are invoked in the acquisition of words, but not facts , volume =. Cognition , doi =
-
[54]
Papers and Reports on Child Language Development , volume=
Acquiring a Single New Word , author=. Papers and Reports on Child Language Development , volume=. 1978 , month=
1978
-
[55]
The innate mind: Foundations and the future , editor=
Rational statistical inference and cognitive development , author=. The innate mind: Foundations and the future , editor=. 2007 , publisher=
2007
-
[56]
Cognition , volume=
A probabilistic model of theory formation , author=. Cognition , volume=. 2010 , publisher=
2010
-
[57]
Behavioral and Brain Sciences , volume=
Building machines that learn and think like people , author=. Behavioral and Brain Sciences , volume=. 2017 , publisher=
2017
-
[58]
Developmental Science , volume=
Core knowledge , author=. Developmental Science , volume=. 2007 , publisher=
2007
-
[59]
2003 , publisher=
Constructing a Language: A Usage-Based Theory of Language Acquisition , author=. 2003 , publisher=
2003
-
[60]
Infancy , volume=
Dynamic noun generalization: Moment-to-moment interactions shape children's naming biases , author=. Infancy , volume=. 2007 , publisher=
2007
-
[61]
Approximating
Brendel, Wieland and Bethge, Matthias , booktitle =. Approximating. 2019 , url =
2019
-
[62]
Advances in Neural Information Processing Systems , volume =
Partial success in closing the gap between human and machine vision , author =. Advances in Neural Information Processing Systems , volume =
-
[63]
Science , volume =
Human-level concept learning through probabilistic program induction , author =. Science , volume =. 2015 , doi =
2015
-
[64]
2022 , eprint=
Flamingo: a Visual Language Model for Few-Shot Learning , author=. 2022 , eprint=
2022
-
[65]
Child Development , volume =
Word learning in children: An examination of fast mapping , author =. Child Development , volume =. 1987 , doi =
1987
-
[66]
Advances in Neural Information Processing Systems , volume =
Matching Networks for One Shot Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[67]
International Conference on Machine Learning , pages=
Learning Transferable Visual Models from Natural Language Supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[68]
Advances in Neural Information Processing Systems , volume =
Prototypical Networks for Few-shot Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[69]
2023 , eprint=
Prompting is not a substitute for probability measurements in large language models , author=. 2023 , eprint=
2023
-
[70]
Proceedings of the 34th International Conference on Machine Learning , pages =
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , publisher =
2017
-
[71]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =
-
[72]
Psychological Science , volume =
Rapid word learning under uncertainty via cross-situational statistics , author =. Psychological Science , volume =. 2007 , doi =
2007
-
[73]
Psychological Science , volume =
Object name learning provides on-the-job training for attention , author =. Psychological Science , volume =. 2002 , doi =
2002
-
[74]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[75]
2020 , eprint=
The Origins and Prevalence of Texture Bias in Convolutional Neural Networks , author=. 2020 , eprint=
2020
-
[76]
2016 , eprint=
Understanding How Image Quality Affects Deep Neural Networks , author=. 2016 , eprint=
2016
-
[77]
2020 , eprint=
Generalisation in humans and deep neural networks , author=. 2020 , eprint=
2020
-
[78]
Proceedings of the National Academy of Sciences , volume =
Atoms of Recognition in Human and Computer Vision , author =. Proceedings of the National Academy of Sciences , volume =. 2016 , doi =
2016
-
[79]
Peng Wang and Shuai Bai and Sinan Tan and Shijie Wang and Zhihao Fan and Jinze Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Yang Fan and Kai Dang and Mengfei Du and Xuancheng Ren and Rui Men and Dayiheng Liu and Chang Zhou and Jingren Zhou and Junyang Lin , journal =. Qwen2-. 2024 , url =
2024
-
[80]
2024 , eprint=
Building and better understanding vision-language models: insights and future directions , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.