ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
Pith reviewed 2026-06-26 09:03 UTC · model grok-4.3
The pith
ReNIO reweights negative student trajectories using student-to-teacher probability ratios to improve on-policy LLM distillation without final-answer labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
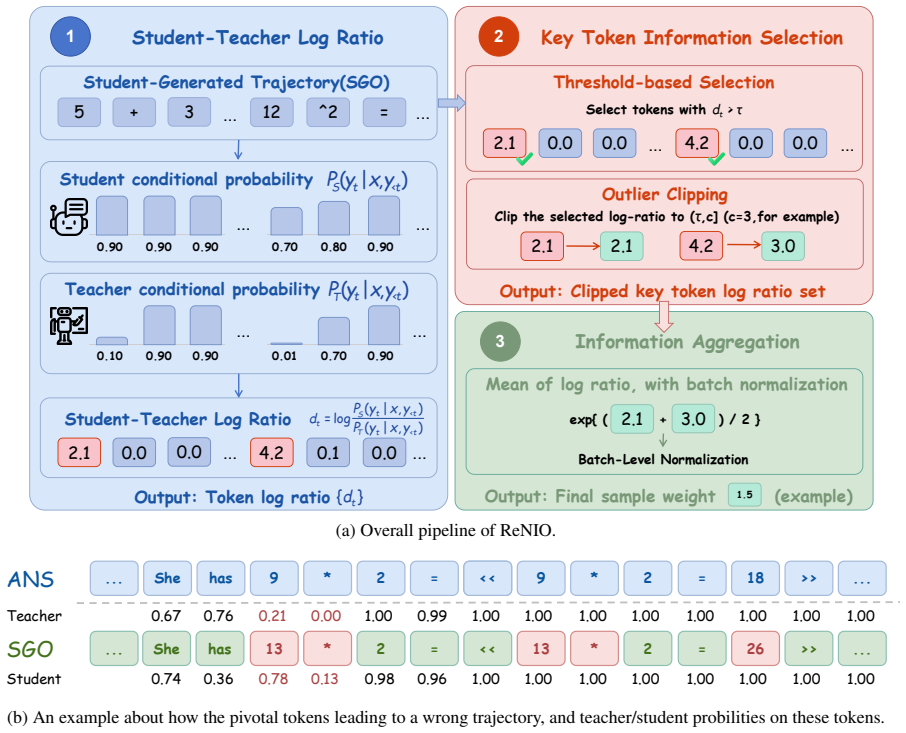
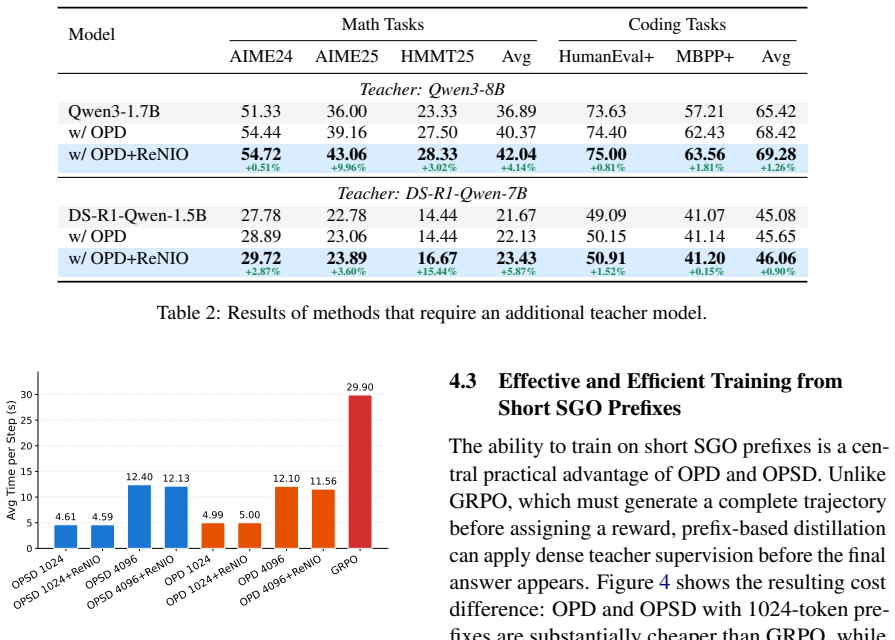
ReNIO identifies pivotal tokens that steer reasoning traces toward errors by comparing student and teacher token probabilities, then aggregates those ratios into a normalized per-sample weight that automatically assigns higher importance to likely negative trajectories; the resulting weighted on-policy distillation improves both standard OPD and on-policy self-distillation across mathematical reasoning and code tasks.
What carries the argument
The student-to-teacher probability ratio at selected tokens, aggregated into a normalized sample weight that upweights negative trajectories.
If this is right
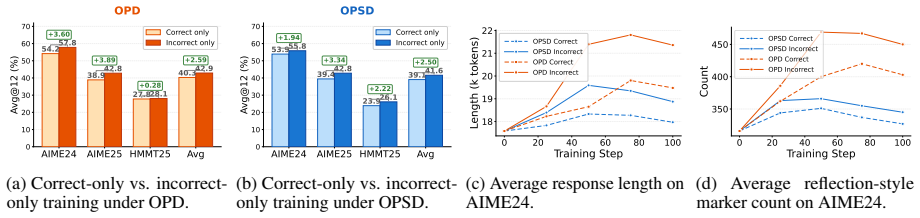
- Incorrect-only training yields longer traces and stronger reflection than correct-only training.
- The weighting works for both ordinary on-policy distillation and on-policy self-distillation.
- Relative gains reach 8.90 percent on Qwen3-1.7B and 10.00 percent on R1-Distill-Qwen-7B for mathematical reasoning.
- Prefix-conditioned probability ratios suffice, so the method keeps the training efficiency of on-policy distillation over full-rollout methods.
Where Pith is reading between the lines
- The same ratio signal might surface useful negative examples in non-reasoning generation tasks where final-answer verification is expensive.
- If the ratio correlates with specific error categories, it could be used to diagnose recurring failure modes without manual inspection.
- Extending the weighting to multi-turn dialogues would test whether negative-trajectory emphasis remains helpful when context grows longer.
Load-bearing premise
The student-to-teacher probability ratio at early tokens can reliably flag trajectories that will end in error without ever observing the final answer.
What would settle it
Run the same on-policy training loop with and without the ReNIO weights on the same set of student rollouts and measure whether accuracy on held-out math benchmarks stays flat or drops.
Figures

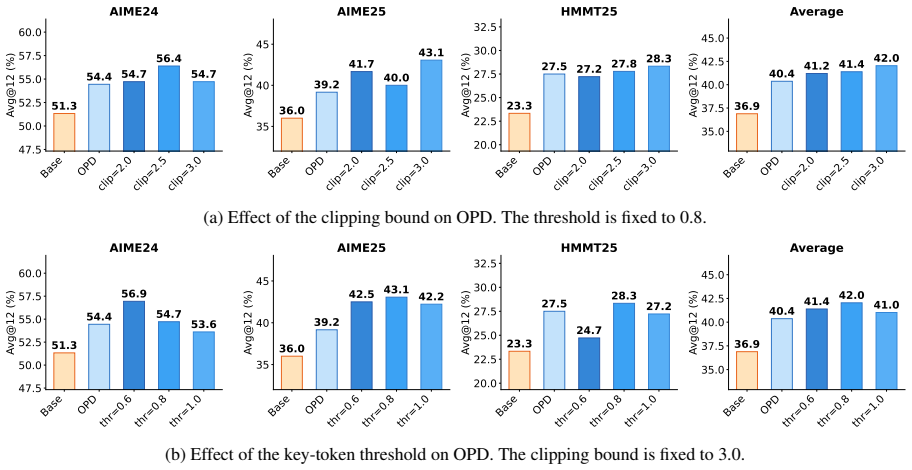
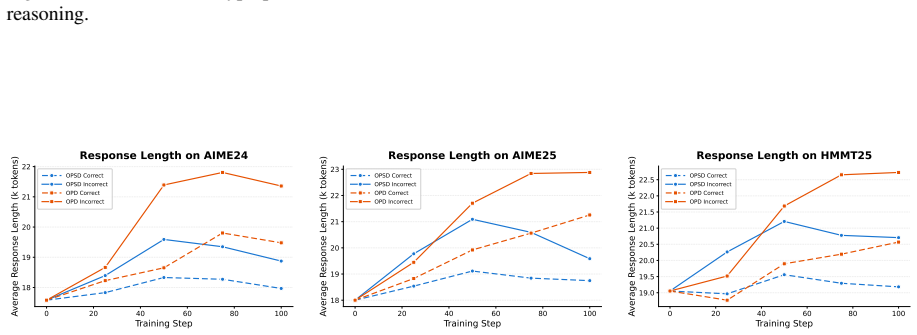
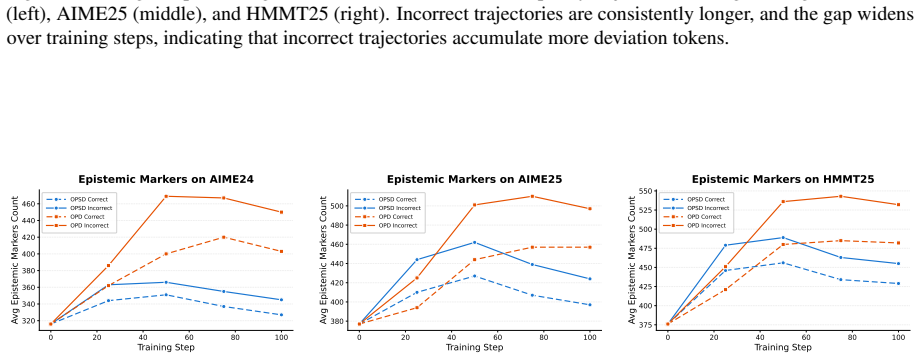

read the original abstract
On-policy distillation (OPD) improves LLM reasoning by training a student model on its own generated outputs, but standard OPD treats all student-generated outputs (SGOs) equally regardless of their informativeness. We observe a consistent asymmetry in controlled filtering experiments: in both OPD and on-policy self distillation (OPSD), training only on incorrect SGOs outperforms training only on correct ones. Our further analysis suggests that models trained on correct-only SGOs tend to generate shorter reasoning traces and show weaker reflection behavior, while incorrect SGOs better preserve exploratory reasoning near the model's capability boundary. To exploit this signal without requiring full answer-containing rollouts, we introduce ReNIO, which Reweights Negative trajectory Importance for LLM On-policy distillation. By using the student-to-teacher probability ratio, ReNIO identifies pivotal tokens leading to wrong reasoning traces and aggregates their information into a normalized sample weight, inherently assigning larger weights to likely negative trajectories without observing the correctness of final-answer. Since Re-NIO only uses prefix-conditioned token probabilities, it preserves OPD's prefix training advantage over full-rollout reinforcement learning. Across both mathematical reasoning and code generation tasks, ReNIO improves both OPD and OPSD, with representative relative gains of up to 8.90% for Qwen3-1.7B and 10.00% for R1-Distill-Qwen-7B on mathematical reasoning benchmarks. Code repo: https://github.com/BDML-lab/ReNIO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReNIO, a reweighting scheme for on-policy distillation (OPD) and on-policy self-distillation (OPSD) of LLMs. It first reports an asymmetry in filtering experiments where training exclusively on incorrect student-generated outputs (SGOs) outperforms training on correct SGOs, attributing this to better preservation of exploratory reasoning. ReNIO then uses aggregated student-to-teacher token probability ratios over prefixes to assign higher normalized weights to likely negative trajectories without observing final-answer correctness, claiming this preserves OPD's prefix-training advantage. Experiments on mathematical reasoning and code generation report relative gains of up to 8.90% (Qwen3-1.7B) and 10.00% (R1-Distill-Qwen-7B) on math benchmarks.
Significance. If the central claims hold after validation, ReNIO would provide a label-free mechanism to emphasize informative negative trajectories in on-policy settings, potentially improving distillation efficiency while retaining the computational advantages of prefix-conditioned training over full-rollout RL. The public code repository is a clear strength for reproducibility.
major comments (3)
- [Method (ReNIO definition)] The core weighting construction (student-to-teacher log-probability ratio aggregated over the prefix and normalized into a sample weight) is presented as identifying 'pivotal tokens leading to wrong reasoning traces,' yet no correlation study, ablation against ground-truth outcome labels, or control for confounders (length bias, token rarity, teacher calibration) is reported; this assumption is load-bearing for the claim that ReNIO assigns larger weights to negative trajectories without final-answer observation.
- [Experiments] The reported relative gains (8.90% for Qwen3-1.7B, 10.00% for R1-Distill-Qwen-7B) are stated without dataset sizes, number of evaluation seeds, error bars, or statistical significance tests, preventing assessment of whether the improvements are reliable or could be explained by variance.
- [Analysis and Experiments] The asymmetry observation (incorrect SGOs outperform correct SGOs) is used to motivate the method, but the paper does not show that the probability-ratio weights recover this asymmetry or outperform a simple length- or entropy-based baseline that would also favor longer exploratory traces.
minor comments (2)
- [Method] Notation for the normalized sample weight (e.g., how the aggregation and normalization are exactly defined) should be presented with an explicit equation rather than prose description.
- [Experiments] The abstract and results section should clarify whether the same hyper-parameters and training budgets were used for all compared methods (standard OPD, OPSD, ReNIO variants).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below. Where the concerns identify gaps in validation or reporting, we will revise the manuscript accordingly to strengthen the presentation of ReNIO.
read point-by-point responses
-
Referee: [Method (ReNIO definition)] The core weighting construction (student-to-teacher log-probability ratio aggregated over the prefix and normalized into a sample weight) is presented as identifying 'pivotal tokens leading to wrong reasoning traces,' yet no correlation study, ablation against ground-truth outcome labels, or control for confounders (length bias, token rarity, teacher calibration) is reported; this assumption is load-bearing for the claim that ReNIO assigns larger weights to negative trajectories without final-answer observation.
Authors: The probability-ratio construction is motivated by the fact that divergence from the teacher occurs precisely where the student begins to depart from higher-quality reasoning; because the teacher is the stronger model, such divergence is expected to mark the onset of error. We did not include post-hoc correlation or confounder controls in the original submission. We will add a dedicated analysis subsection that (i) reports Spearman correlation between ReNIO weights and ground-truth outcome labels on held-out trajectories, (ii) ablates length and entropy as alternative weightings, and (iii) checks sensitivity to teacher calibration. These additions will directly test the load-bearing assumption. revision: yes
-
Referee: [Experiments] The reported relative gains (8.90% for Qwen3-1.7B, 10.00% for R1-Distill-Qwen-7B) are stated without dataset sizes, number of evaluation seeds, error bars, or statistical significance tests, preventing assessment of whether the improvements are reliable or could be explained by variance.
Authors: We agree that these statistical details are necessary. All experiments used three independent random seeds; the underlying test sets are the standard GSM8K (1,319 examples) and MATH (5,000 examples) splits. We will revise the experimental section to report mean and standard deviation across seeds, include error bars in all tables and figures, and add paired t-test p-values for the reported relative gains. revision: yes
-
Referee: [Analysis and Experiments] The asymmetry observation (incorrect SGOs outperform correct SGOs) is used to motivate the method, but the paper does not show that the probability-ratio weights recover this asymmetry or outperform a simple length- or entropy-based baseline that would also favor longer exploratory traces.
Authors: The asymmetry is presented as empirical motivation rather than a direct empirical claim about ReNIO weights. To close this gap we will add two new figures: one showing the mean ReNIO weight for correct versus incorrect SGOs (thereby recovering the asymmetry), and a second comparing ReNIO against length-based and entropy-based reweighting baselines on the same OPD/OPSD setups. These comparisons will demonstrate that the probability-ratio weighting yields larger gains than the simpler alternatives. revision: yes
Circularity Check
No significant circularity; method is a heuristic weighting defined from ratios with empirical gains
full rationale
The paper defines ReNIO's sample weights directly via aggregation of student-to-teacher token probability ratios over prefixes, then reports empirical gains on benchmarks. This construction does not reduce any claimed prediction or result to its inputs by definition, nor does it invoke self-citations, uniqueness theorems, or fitted parameters renamed as predictions. The observation that incorrect SGOs outperform correct ones is presented as motivation from filtering experiments, and the proxy is offered as an operational choice without requiring final-answer labels. No load-bearing step equates the output performance to the input definition. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
ArXiv , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. ArXiv , year=
-
[9]
ArXiv , year=
OpenThoughts: Data Recipes for Reasoning Models , author=. ArXiv , year=
-
[10]
2025 , url=
Qwen3 Technical Report , author=. 2025 , url=
2025
-
[11]
ArXiv , year=
The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning , author=. ArXiv , year=
-
[12]
2026 , url=
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? , author=. 2026 , url=
2026
-
[13]
2026 , url=
Scaling Reasoning Efficiently via Relaxed On-Policy Distillation , author=. 2026 , url=
2026
-
[14]
NIPS Deep Learning and Representation Learning Workshop , year=
Distilling the Knowledge in a Neural Network , author=. NIPS Deep Learning and Representation Learning Workshop , year=
-
[15]
Proceedings of the 12th International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. Proceedings of the 12th International Conference on Learning Representations , year=
-
[16]
Manuscript , year=
Fast and Effective On-Policy Distillation from Reasoning Prefixes , author=. Manuscript , year=
-
[17]
arXiv preprint arXiv:2603.07079 , year=
Entropy-Aware On-Policy Distillation of Language Models , author=. arXiv preprint arXiv:2603.07079 , year=
-
[19]
arXiv preprint arXiv:2604.14084 , year=
TIP: Token Importance in On-Policy Distillation , author=. arXiv preprint arXiv:2604.14084 , year=
-
[20]
2026 , url=
The Many Faces of On-Policy Distillation: Pitfalls, Mechanisms, and Fixes , author=. 2026 , url=
2026
-
[21]
arXiv preprint arXiv:2605.17497 , year=
Self-Supervised On-Policy Distillation for Reasoning Language Models , author=. arXiv preprint arXiv:2605.17497 , year=
-
[22]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[23]
Thinking Machines Lab: Connectionism , year =
Kevin Lu and Thinking Machines Lab , title =. Thinking Machines Lab: Connectionism , year =
-
[24]
2026 , url=
Understanding Reasoning in LLMs through Strategic Information Allocation under Uncertainty , author=. 2026 , url=
2026
-
[25]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[26]
American Invitational Mathematics Examination (AIME) 2024 , author=
2024
-
[27]
American Invitational Mathematics Examination (AIME) 2025 , author=
2025
-
[28]
2026 , eprint=
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs , author=. 2026 , eprint=
2026
-
[29]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
2023
-
[30]
International Conference on Learning Representations , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. International Conference on Learning Representations , year=
-
[31]
ArXiv , year=
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs , author=. ArXiv , year=
-
[32]
Nature , year=
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning , author=. Nature , year=
-
[33]
Li and Y
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y.K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =
2024
-
[34]
2025 , url=
Kimi K2: Open Agentic Intelligence , author=. 2025 , url=
2025
-
[35]
ArXiv , year=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. ArXiv , year=
-
[36]
2026 , eprint=
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe , author=. 2026 , eprint=
2026
-
[37]
2026 , eprint=
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting , author=. 2026 , eprint=
2026
-
[38]
2026 , eprint=
Self-Distilled RLVR , author=. 2026 , eprint=
2026
-
[39]
2023 , url=
MiniLLM: On-Policy Distillation of Large Language Models , author=. 2023 , url=
2023
-
[40]
ArXiv , year=
Self-Distillation Enables Continual Learning , author=. ArXiv , year=
-
[41]
ArXiv , year=
Reinforcement Learning via Self-Distillation , author=. ArXiv , year=
-
[42]
Efficient Knowledge Injection in LLMs via Self-Distillation , author=. Trans. Mach. Learn. Res. , year=
-
[43]
ArXiv , year=
On-Policy Context Distillation for Language Models , author=. ArXiv , year=
-
[44]
ArXiv , year=
GATES: Self-Distillation under Privileged Context with Consensus Gating , author=. ArXiv , year=
-
[45]
ArXiv , year=
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation , author=. ArXiv , year=
-
[46]
ArXiv , year=
Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling , author=. ArXiv , year=
-
[47]
DistiLLM: Towards Streamlined Distillation for Large Language Models , author=
-
[48]
2025 , journal=
DistiLLM-2: A Contrastive Approach Boosts the Distillation of LLMs , author=. 2025 , journal=
2025
-
[49]
ArXiv , year=
From Correction to Mastery: Reinforced Distillation of Large Language Model Agents , author=. ArXiv , year=
-
[50]
2025 , url=
AdaSwitch: Balancing Exploration and Guidance in Knowledge Distillation via Adaptive Switching , author=. 2025 , url=
2025
-
[51]
2026 , eprint=
A Survey of Inductive Reasoning for Large Language Models , author=. 2026 , eprint=
2026
-
[52]
2026 , eprint=
A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems , author=. 2026 , eprint=
2026
-
[53]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[54]
Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. 2024. https://openreview.net/forum?id=3zKtaqxLhW On-policy distillation of language models: Learning from self-generated mistakes . In Proceedings of the 12th International Conference on Learning Representations
2024
-
[55]
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stańczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. 2023. https://api.semanticscholar.org/CorpusID:263610088 On-policy distillation of language models: Learning from self-generated mistakes . In International Conference on Learning Representations
2023
-
[56]
Kimi Team Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Haochen Ding, Meng xiao Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, and 149 others. 2025. https://api.semanticscholar.org/CorpusID:280323540 Kimi k2: Open agentic intelligence
2025
-
[57]
Kedi Chen, Dezhao Ruan, Yuhao Dan, Yaoting Wang, Siyu Yan, Xuecheng Wu, Yinqi Zhang, Qin Chen, Jie Zhou, Liang He, Biqing Qi, Linyang Li, Qipeng Guo, Xiaoming Shi, and Wei Zhang. 2026. https://arxiv.org/abs/2510.10182 A survey of inductive reasoning for large language models . Preprint, arXiv:2510.10182
Pith/arXiv arXiv 2026
-
[58]
DeepSeek-AI. 2025. https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning . Preprint, arXiv:2501.12948
Pith/arXiv arXiv 2025
-
[59]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 179 others. 2025. https://api.semanticscholar.org/CorpusID:275789950 Deepseek-r1 incentivizes reasoning in llms through rein...
2025
-
[60]
Jasper Dekoninck, Nikola Jovanović, Tim Gehrunger, Kári Rögnvaldsson, Ivo Petrov, Chenhao Sun, and Martin Vechev. 2026. https://arxiv.org/abs/2605.00674 Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms
Pith/arXiv arXiv 2026
-
[61]
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. https://api.semanticscholar.org/CorpusID:259164722 Minillm: On-policy distillation of large language models
2023
-
[62]
Etash Kumar Guha, Ryan Marten, Sedrick Scott Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean-Pierre Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Ben Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, and 31 others. 2025. https://api.semanticscholar.org/CorpusID:27915447...
Pith/arXiv arXiv 2025
-
[63]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. https://arxiv.org/abs/1503.02531 Distilling the knowledge in a neural network . In NIPS Deep Learning and Representation Learning Workshop
Pith/arXiv arXiv 2015
-
[64]
Wenjin Hou, Shangpin Peng, Weinong Wang, Zheng Ruan, Yue Zhang, Zhenglin Zhou, Mingqi Gao, Yifei Chen, Kaiqi Wang, Hongming Yang, Chengquan Zhang, Zhuotao Tian, Han Hu, Yi Yang, Fei Wu, and Hehe Fan. 2026. https://arxiv.org/abs/2605.03677 Uni-opd: Unifying on-policy distillation with a dual-perspective recipe . Preprint, arXiv:2605.03677
Pith/arXiv arXiv 2026
-
[65]
Jonas Hubotter, Frederike Lubeck, Lejs Deen Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. 2026. https://api.semanticscholar.org/CorpusID:285102353 Reinforcement learning via self-distillation . ArXiv, abs/2601.20802
Pith/arXiv arXiv 2026
-
[66]
Zixuan Ke, Fangkai Jiao, Yifei Ming, Xuan-Phi Nguyen, Austin Xu, Do Xuan Long, Minzhi Li, Chengwei Qin, Peifeng Wang, Silvio Savarese, Caiming Xiong, and Shafiq Joty. 2026. https://arxiv.org/abs/2504.09037 A survey of frontiers in llm reasoning: Inference scaling, learning to reason, and agentic systems . Preprint, arXiv:2504.09037
arXiv 2026
-
[67]
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. 2026 a . https://api.semanticscholar.org/CorpusID:286776340 Why does self-distillation (sometimes) degrade the reasoning capability of llms?
2026
-
[68]
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dongsheng Li, and Yuqing Yang. 2026 b . https://api.semanticscholar.org/CorpusID:286572576 Understanding reasoning in llms through strategic information allocation under uncertainty
2026
-
[69]
Jongwoo Ko, Sara Abdali, Young Jin Kim, Tianyi Chen, and Pashmina Cameron. 2026. https://api.semanticscholar.org/CorpusID:286489350 Scaling reasoning efficiently via relaxed on-policy distillation
2026
-
[70]
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. 2025. Distillm-2: A contrastive approach boosts the distillation of llms. arXiv preprint arXiv:2503.07067
arXiv 2025
-
[71]
Distillm: Towards streamlined distillation for large language models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. Distillm: Towards streamlined distillation for large language models. In Forty-first International Conference on Machine Learning
-
[72]
Kalle Kujanp \"a \"a , Pekka Marttinen, Harri Valpola, and Alexander Ilin. 2024. https://api.semanticscholar.org/CorpusID:274859956 Efficient knowledge injection in llms via self-distillation . Trans. Mach. Learn. Res., 2025
2024
-
[73]
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. 2026. https://arxiv.org/abs/2604.13016 Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe . arXiv preprint arXiv:2604.13016
Pith/arXiv arXiv 2026
-
[74]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. https://openreview.net/forum?id=1qvx610Cu7 Is your code generated by chat GPT really correct? rigorous evaluation of large language models for code generation . In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[75]
Ilya Loshchilov and Frank Hutter. 2019. https://openreview.net/forum?id=Bkg6RiCqY7 Decoupled weight decay regularization . In International Conference on Learning Representations
2019
-
[76]
Kevin Lu and Thinking Machines Lab. 2025. https://doi.org/10.64434/tml.20251026 On-policy distillation . Thinking Machines Lab: Connectionism. Https://thinkingmachines.ai/blog/on-policy-distillation
-
[77]
Yuanjie Lyu, Chengyu Wang, Jun Huang, and Tong Xu. 2025. https://api.semanticscholar.org/CorpusID:281393943 From correction to mastery: Reinforced distillation of large language model agents . ArXiv, abs/2509.14257
arXiv 2025
-
[78]
Jingyu Peng, Maolin Wang, Hengyi Cai, Yuchen Li, Kai Zhang, Shuaiqiang Wang, Dawei Yin, and Xiangyu Zhao. 2025. https://api.semanticscholar.org/CorpusID:286579337 Adaswitch: Balancing exploration and guidance in knowledge distillation via adaptive switching
2025
-
[79]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models
Pith/arXiv arXiv 2024
-
[80]
Idan Shenfeld, Mehul Damani, Jonas H \"u botter, and Pulkit Agrawal. 2026. https://api.semanticscholar.org/CorpusID:285071839 Self-distillation enables continual learning . ArXiv, abs/2601.19897
Pith/arXiv arXiv 2026
-
[81]
Alex Stein, Furong Huang, and Tom Goldstein. 2026. https://api.semanticscholar.org/CorpusID:286001285 Gates: Self-distillation under privileged context with consensus gating . ArXiv, abs/2602.20574
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.