Seeing Before Reasoning: Decoupling Perception and Reasoning for Shortcut-Resilient Multimodal On-Policy Self-Distillation
Pith reviewed 2026-06-26 21:10 UTC · model grok-4.3
The pith
ViGOS decouples visual description from reasoning in on-policy self-distillation so an image-only teacher can supervise perception before a privileged teacher handles reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
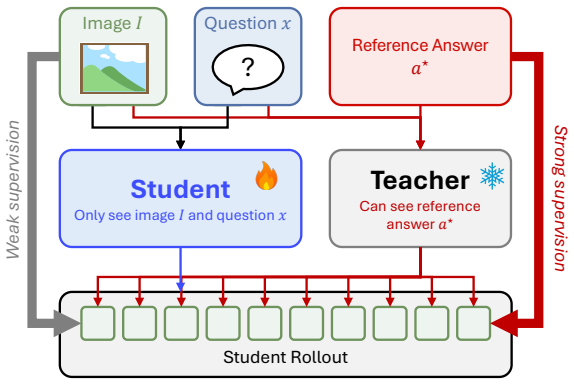
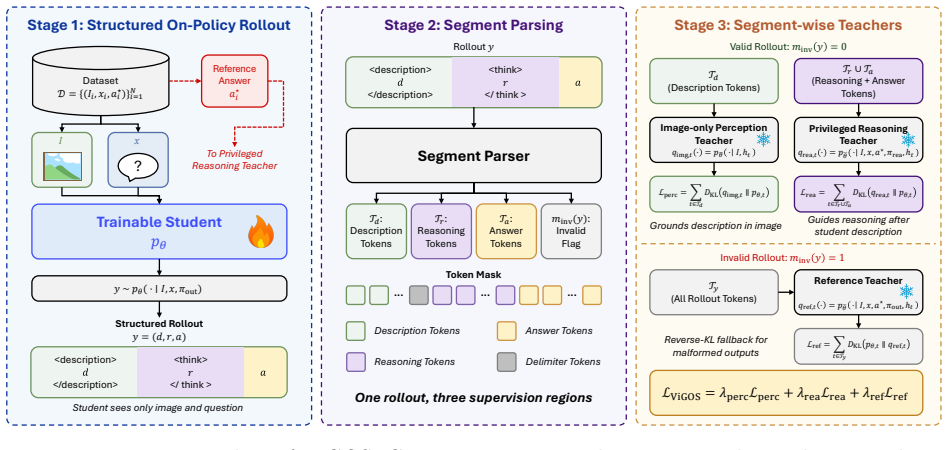
ViGOS trains MLLMs by first requiring the student to write a visual description supervised by an image-only perception teacher, then supervising the reasoning and final answer with a privileged reasoning teacher on the same student prefix, using a reference teacher only for invalid rollouts to recover output format.
What carries the argument
Two-stage rollout supervision that assigns an image-only perception teacher to the visual description step and a privileged reasoning teacher to the subsequent reasoning step.
If this is right
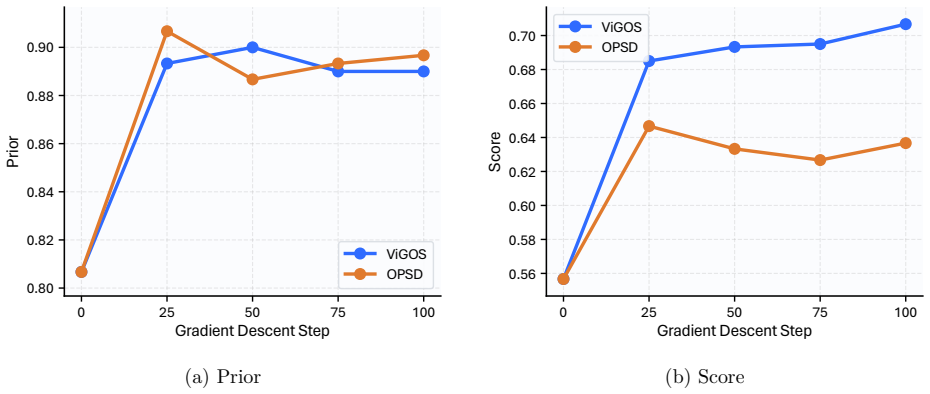
- ViGOS retains the performance benefits of OPSD across general vision-language, expert reasoning, visual math, spatial grounding, and visual-language-prior benchmarks.
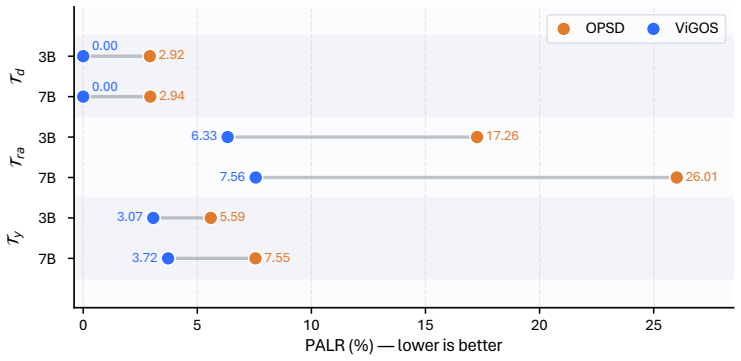
- The method reduces reliance on text shortcuts specifically in settings where privileged targets would otherwise dominate.
- Separate teachers allow the perception step to be grounded directly in image content while reasoning still receives dense token-level targets.
- Invalid rollouts fall back to a reference teacher only for format recovery, preserving the overall training loop.
Where Pith is reading between the lines
- The explicit visual-description step could make it easier to isolate whether errors stem from perception or from reasoning.
- The same separation might apply to other shortcut-prone multimodal settings such as video or audio reasoning.
- Models trained this way could produce reasoning traces that more consistently reference specific visual elements rather than generic language patterns.
Load-bearing premise
An image-only perception teacher can supervise the visual description step without the privileged target leaking influence or creating new failure modes on non-shortcut tasks.
What would settle it
If ViGOS models show no reduction in text-shortcut reliance compared with standard OPSD on visual math or spatial grounding benchmarks, the claim of improved image-grounded behavior would be falsified.
Figures
read the original abstract
On-policy self-distillation (OPSD) trains a model on its own rollouts and uses a frozen copy to provide dense token-level targets conditioned on a reference target. This works well for LLM reasoning, but a direct extension to multimodal large language models (MLLMs) can create a shortcut: the privileged target may guide tokens mainly based on the text reference target rather than the image. We propose ViGOS, a visually grounded OPSD framework for MLLM post-training. The student first writes a visual description and then reasons toward the final answer. For valid rollouts, an image-only perception teacher supervises the description, while a privileged reasoning teacher supervises the reasoning and final answer on the same student prefix. A reference teacher is used only for invalid rollouts to recover the output format. Across general vision-language, expert reasoning, visual math, spatial grounding, and visual-language-prior benchmarks, ViGOS keeps the main benefits of OPSD and improves image-grounded behavior in shortcut-prone settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ViGOS, a visually grounded variant of on-policy self-distillation (OPSD) for multimodal LLMs. The student generates a visual description prefix followed by reasoning; an image-only perception teacher supervises only the description tokens while a privileged reasoning teacher supervises the subsequent tokens on the same prefix, with a reference teacher used solely for invalid rollouts. The central claim is that this decoupling prevents the privileged target from inducing text-based shortcuts, preserves OPSD benefits, and improves image-grounded behavior across general vision-language, expert reasoning, visual math, spatial grounding, and visual-language-prior benchmarks.
Significance. If the empirical results and mechanism validation hold, the dual-teacher separation offers a concrete way to extend OPSD to MLLMs without sacrificing visual grounding. The approach directly targets a known failure mode when privileged targets leak into multimodal rollouts and could generalize to other staged reasoning pipelines. Credit is due for framing the problem explicitly in terms of prefix supervision and for testing across a diverse set of shortcut-prone and non-shortcut benchmarks.
major comments (2)
- [Method] Method description (around the two-teacher construction): the claim that the image-only perception teacher supplies non-leaking supervision on the visual-description prefix while the privileged reasoning teacher acts only on later tokens is load-bearing for the entire shortcut-resilience argument. No details are supplied on how the perception teacher is trained or initialized, how the two losses are weighted or masked, or the precise criterion for declaring a rollout valid/invalid. Without these, it is impossible to verify that the student prefix remains free of privileged leakage or that new failure modes are not introduced on non-shortcut tasks.
- [Experiments] Experiments and results sections: the strongest claim (maintaining OPSD gains while improving image-grounded behavior) requires evidence that observed improvements are attributable to the decoupling rather than other factors such as rollout filtering or teacher strength. The manuscript supplies no quantitative numbers, ablation tables isolating the perception-teacher component, or comparisons of prefix-only vs. full-sequence supervision, leaving the cross-benchmark assertion unevaluable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the dual-teacher separation in extending OPSD to MLLMs. We address each major comment below. Where details are missing from the current manuscript, we will revise to provide them.
read point-by-point responses
-
Referee: [Method] Method description (around the two-teacher construction): the claim that the image-only perception teacher supplies non-leaking supervision on the visual-description prefix while the privileged reasoning teacher acts only on later tokens is load-bearing for the entire shortcut-resilience argument. No details are supplied on how the perception teacher is trained or initialized, how the two losses are weighted or masked, or the precise criterion for declaring a rollout valid/invalid. Without these, it is impossible to verify that the student prefix remains free of privileged leakage or that new failure modes are not introduced on non-shortcut tasks.
Authors: We agree that the current manuscript does not provide sufficient implementation details on the perception teacher. In the revision we will expand Section 3 to specify: (i) the perception teacher is initialized from a vision-language model and trained solely on image-caption pairs with no text-only reference; (ii) the composite loss applies cross-entropy only to description tokens from the perception teacher and to reasoning tokens from the privileged teacher, with explicit token-level masking; (iii) the two losses are combined with a fixed scalar weight λ=0.5; and (iv) a rollout is declared invalid if it fails format checks or produces inconsistent answers across two reference-teacher samples. These additions will make the non-leakage claim verifiable. revision: yes
-
Referee: [Experiments] Experiments and results sections: the strongest claim (maintaining OPSD gains while improving image-grounded behavior) requires evidence that observed improvements are attributable to the decoupling rather than other factors such as rollout filtering or teacher strength. The manuscript supplies no quantitative numbers, ablation tables isolating the perception-teacher component, or comparisons of prefix-only vs. full-sequence supervision, leaving the cross-benchmark assertion unevaluable.
Authors: We acknowledge the absence of isolating ablations. The revision will add a new subsection with (a) a table reporting exact benchmark scores for the full ViGOS model versus an OPSD baseline and a perception-teacher-only variant, (b) an ablation removing the perception teacher while keeping rollout filtering, and (c) a direct prefix-only vs. full-sequence supervision comparison on the same student prefixes. These results will quantify the contribution of the decoupling independent of filtering or teacher strength. revision: yes
Circularity Check
No circularity: method is a descriptive training procedure with no equations or self-referential derivations
full rationale
The paper describes an empirical training framework (ViGOS) that extends OPSD via a two-teacher split on student-generated prefixes. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claim rests on benchmark results rather than any reduction of outputs to inputs by construction. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self- generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes. InICLR, 2024
2024
-
[2]
Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[3]
Words or vision: Do vision-language models have blind faith in text? InCVPR, pages 3867–3876, 2025
Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi. Words or vision: Do vision-language models have blind faith in text? InCVPR, pages 3867–3876, 2025
2025
-
[4]
Scalable vision language model training via high quality data curation
Hongyuan Dong, Zijian Kang, Weijie Yin, Xiao Liang, Chao Feng, and Jiao Ran. Scalable vision language model training via high quality data curation. InACL, pages 33272–33293, 2025
2025
-
[5]
Wichmann
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
2020
-
[6]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InICLR, 2024
2024
-
[7]
DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645:633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, et al. DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645:633–638, 2025
2025
-
[8]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[9]
Vision-R1: Incentivizing reasoning capability in multimodal large language models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-R1: Incentivizing reasoning capability in multimodal large language models. InICLR, 2026
2026
-
[10]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InICML, volume 202, pages 19730–19742, 2023
2023
-
[11]
Vision-SR1: Self-rewarding vision-language model via reasoning decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Zhenwen Liang, Rui Liu, Fuxiao Liu, Jingxi Che, Dian Yu, Jordan Boyd-Graber, Haitao Mi, and Dong Yu. Vision-SR1: Self-rewarding vision-language model via reasoning decomposition. InICLR, 2026
2026
-
[12]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS, 2023
2023
-
[13]
On-policy distillation.Thinking Machines Lab: Connectionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connectionism, 2025
2025
-
[14]
MathVista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR, 2024. 13
2024
-
[15]
Probing visual language priors in VLMs
Tiange Luo, Ang Cao, Gunhee Lee, Justin Johnson, and Honglak Lee. Probing visual language priors in VLMs. InICML, volume 267, pages 41120–41156, 2025. ViLP-F and ViLP-P are the with-fact and pure-question evaluation settings of ViLP
2025
-
[16]
Bardia Safaei, Faizan Siddiqui, Jiacong Xu, Vishal M. Patel, and Shao-Yuan Lo. Filter images first, generate instructions later: Pre-instruction data selection for visual instruction tuning. arXiv preprint arXiv:2503.07591, 2025
arXiv 2025
-
[17]
Language prior is not the only shortcut: A benchmark for shortcut learning in vqa
Qingyi Si, Fandong Meng, Mingyu Zheng, Zheng Lin, Yuanxin Liu, Peng Fu, Yanan Cao, Weiping Wang, and Jie Zhou. Language prior is not the only shortcut: A benchmark for shortcut learning in vqa. InFindings of EMNLP, 2022
2022
-
[18]
Cambrian-1: A fully open, vision-centric exploration of multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, and Saining Xie. Cambrian-1: A fully open, vision-centric exploration of multimodal LLMs. InNeurIPS, volume 37, 2024
2024
-
[19]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base llms.arXiv preprint arXiv:2506.14245, 2025
Pith/arXiv arXiv 2025
-
[20]
RealWorldQA: A benchmark for real-world spatial understanding, 2024
xAI. RealWorldQA: A benchmark for real-world spatial understanding, 2024
2024
-
[21]
Jiaer Xia, Yuhang Zang, Peng Gao, Sharon Li, and Kaiyang Zhou. Visionary-R1: Mitigating shortcuts in visual reasoning with reinforcement learning.arXiv preprint arXiv:2505.14677, 2025
arXiv 2025
-
[22]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[23]
MMSI-bench: A benchmark for multi-image spatial intelligence
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, Dahua Lin, Tai Wang, and Jiangmiao Pang. MMSI-bench: A benchmark for multi-image spatial intelligence. InICLR, 2026
2026
-
[24]
MM-Vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. MM-Vet: Evaluating large multimodal models for integrated capabilities. In ICML, volume 235, pages 57730–57754, 2024
2024
-
[25]
Jiakang Yuan, Tianshuo Peng, Yilei Jiang, Yiting Lu, Renrui Zhang, Kaituo Feng, Chaoyou Fu, Tao Chen, Lei Bai, Bo Zhang, and Xiangyu Yue. MME-reasoning: A comprehensive benchmark for logical reasoning in mllms.arXiv preprint arXiv:2505.21327, 2025
arXiv 2025
-
[26]
Qianhao Yuan, Jie Lou, Xing Yu, Hongyu Lin, Le Sun, Xianpei Han, and Yaojie Lu. Vision- OPD: Learning to See Fine Details for Multimodal LLMs via On-Policy Self-Distillation.arXiv preprint arXiv:2605.18740, 2026
Pith/arXiv arXiv 2026
-
[27]
MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for expert AGI
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. MMMU: A massive multi-discipline multimodal understanding and reasoning benchmark for exp...
2024
-
[28]
MMMU-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. MMMU-pro: A more robust multi-discipline multimodal understanding benchmark. InACL, pages 15134–15186, 2025
2025
-
[29]
MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems? InECCV, pages 169–186, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, and Hongsheng Li. MathVerse: Does your multi-modal LLM truly see the diagrams in visual math problems? InECCV, pages 169–186, 2024
2024
-
[30]
Looking beyond text: Reducing language bias in large vision-language models via multimodal dual-attention and soft-image guidance
Haozhe Zhao, Shuzheng Si, Liang Chen, Yichi Zhang, Maosong Sun, Mingjia Zhang, and Baobao Chang. Looking beyond text: Reducing language bias in large vision-language models via multimodal dual-attention and soft-image guidance. InEMNLP, pages 19666–19690, 2025
2025
-
[31]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 15 A Privileged Answer Leakage Rate This section gives the diagnostic used in Section 2.3 and Section 3.4. The goal is to ask a simple question: wh...
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.