Chameleon: Style-Content Disentangled Framework for Cross-Domain Object Compositing
Pith reviewed 2026-06-28 17:50 UTC · model grok-4.3
The pith
A new paired dataset and two-stage training framework let diffusion models preserve foreground identity while matching background style across domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
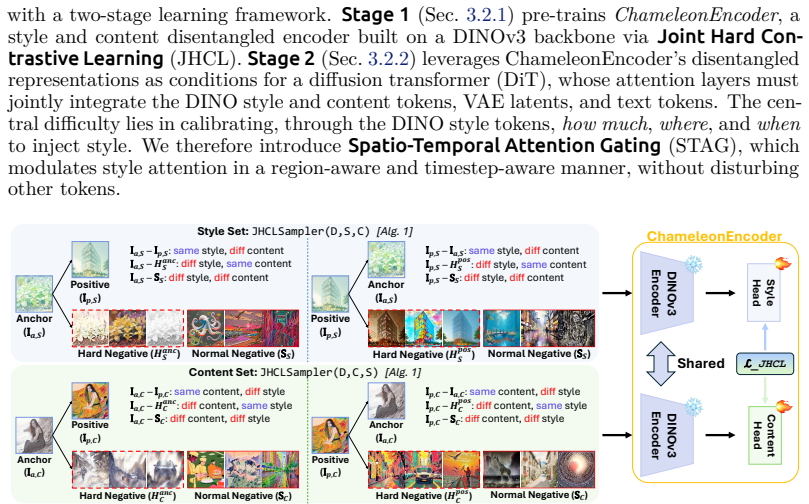
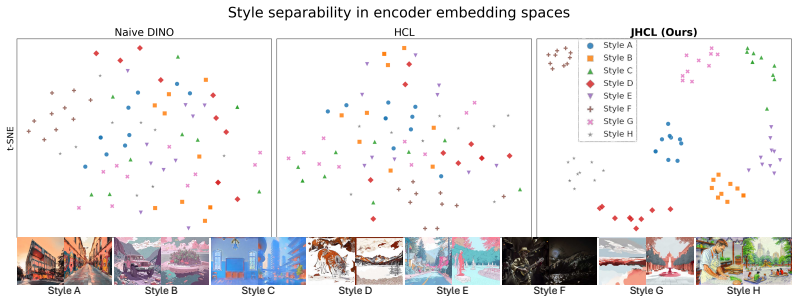
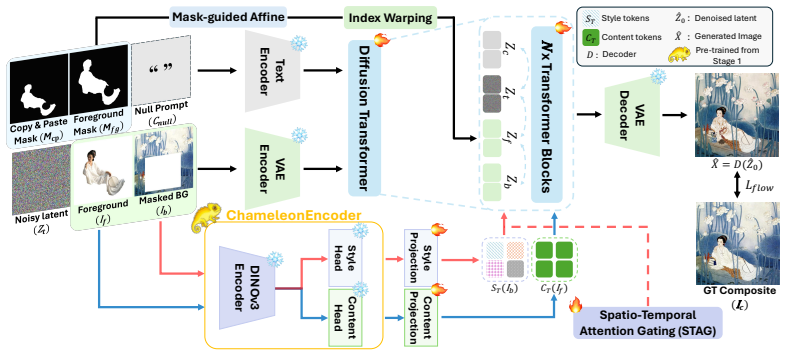
Chameleon is a two-stage framework: the first stage trains an encoder with Joint Hard Contrastive Learning to separate style and content representations from the new ChameleonDataset; the second stage inserts Spatio-Temporal Attention Gating into a diffusion transformer so that style tokens are injected adaptively across space and diffusion steps, producing composites that are both compositionally plausible and stylistically faithful.
What carries the argument
The ChameleonEncoder trained via Joint Hard Contrastive Learning to produce disentangled style and content vectors, together with the Spatio-Temporal Attention Gating module that regulates how those style tokens influence the diffusion transformer.
If this is right
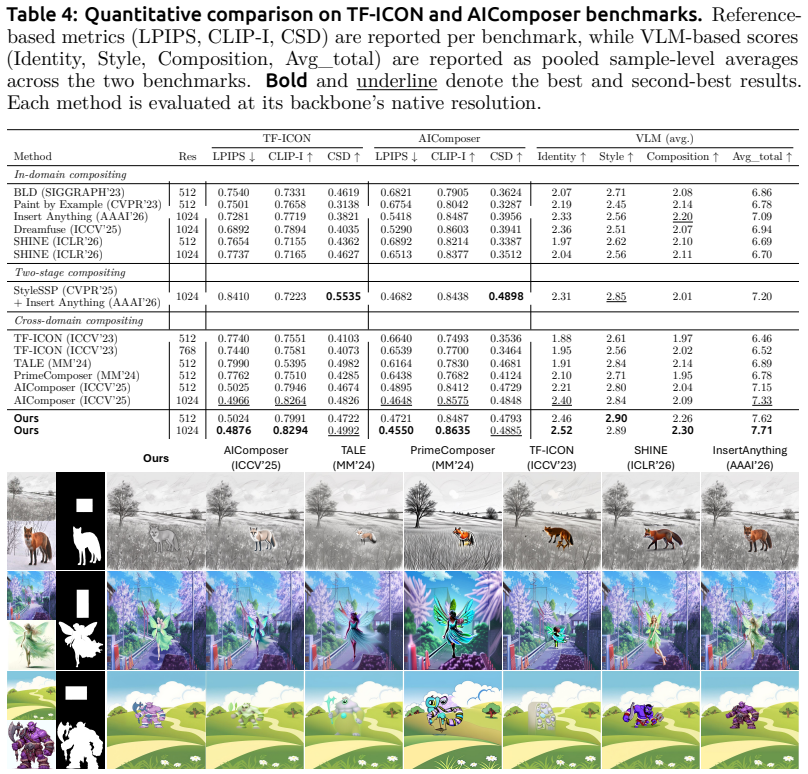
- The method improves both compositional plausibility and stylistic fidelity over prior in-domain, cross-domain, sequential, and commercial compositing approaches.
- Stylization moves beyond tone-level alignment to full domain matching while still preserving foreground object identity.
- Training-based solutions become feasible where only training-free strategies were previously used.
- The same encoder and gating components can be applied to both same-domain and different-domain foreground-background pairs.
Where Pith is reading between the lines
- The temporal component of the gating mechanism may support extensions to video or animation compositing with minimal additional changes.
- The dataset construction pipeline could be reused or adapted for other synthesis tasks that lack paired training data across visual domains.
- The disentanglement-plus-gating pattern might transfer to other conditional generation settings where one factor must be held fixed while another is altered.
Load-bearing premise
The synthetic paired images created by the dataset pipeline contain style-content separations and domain shifts that are representative of real photographs and artworks.
What would settle it
Running the trained model on a collection of manually collected real-world cross-domain pairs never seen during dataset construction and finding that composite plausibility and style-matching scores fall to or below the level of existing training-free baselines.
Figures




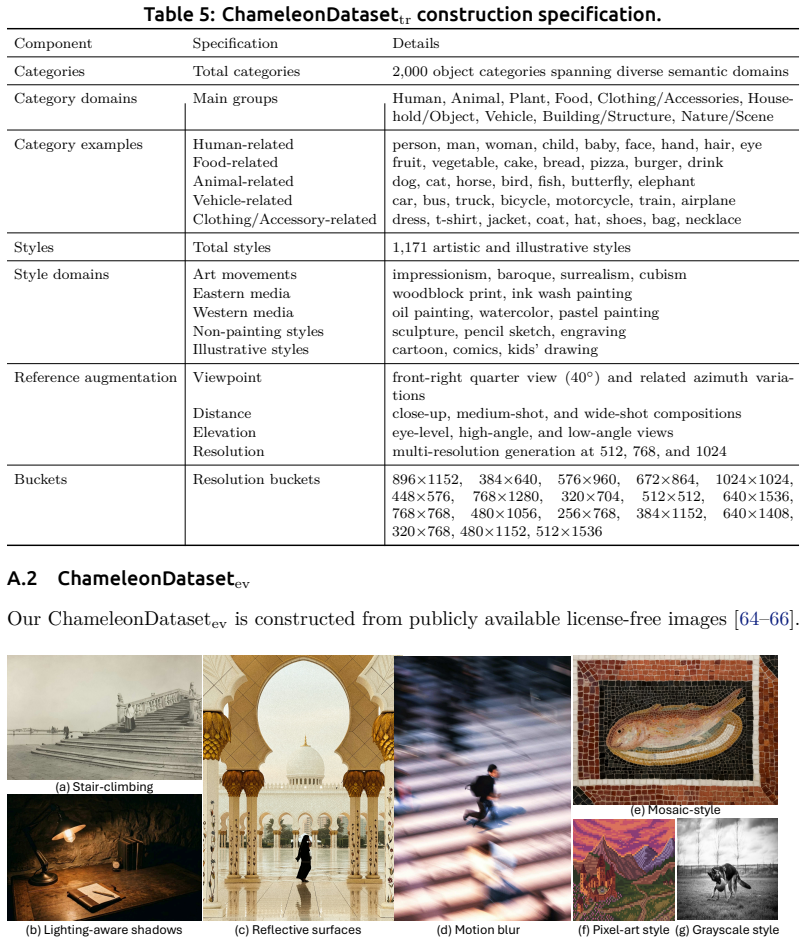


read the original abstract
Image compositing aims to seamlessly insert a foreground object into a background image, and recent advances in diffusion models have significantly enhanced the quality, especially when the foreground and background images come from the same domain (e.g., natural images). However, cross-domain compositing, where the foreground and background come from different domains, is relatively underexplored and remains challenging because the model must preserve the foreground object's identity while stylizing it to match the background domain. Existing cross-domain compositing approaches largely rely on training-free blending and refinement strategies. This is partly due to the lack of large-scale paired datasets for cross-domain compositing, limiting the development of training-based solutions. As a result, they are limited to tone-level alignment and often produce style-inconsistent or overstylized results. To overcome such limitations, we construct ChameleonDataset, the first large-scale training dataset for cross-domain compositing, with a comprehensive evaluation benchmark, built through a scalable data construction pipeline. Building on this, we propose Chameleon, a novel two-stage training-based cross-domain compositing framework. In the first stage, we propose Joint Hard Contrastive Learning (JHCL) to train ChameleonEncoder, which effectively disentangles style and content representations. In the second stage, we introduce Spatio-Temporal Attention Gating (STAG) into a diffusion transformer for effective stylization, adaptively regulating how style tokens from the first-stage encoder are injected across spatial and temporal dimensions. Our method outperforms state-of-the-art in-domain and cross-domain compositing models, sequential pipelines and commercial models, achieving improvements in both compositional plausibility and stylistic fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ChameleonDataset, the first large-scale paired training dataset for cross-domain object compositing built via a scalable construction pipeline, along with the Chameleon framework. This consists of a first-stage Joint Hard Contrastive Learning (JHCL) procedure to train a ChameleonEncoder that disentangles style and content representations, followed by a second-stage diffusion transformer augmented with Spatio-Temporal Attention Gating (STAG) to adaptively inject style tokens. The central claim is that this two-stage approach outperforms prior in-domain and cross-domain compositing methods, sequential pipelines, and commercial tools on both compositional plausibility and stylistic fidelity.
Significance. If the empirical claims hold after proper validation, the work would be significant for the field: it supplies the first large-scale training resource for an underexplored task and demonstrates a training-based alternative to existing training-free blending strategies. The explicit provision of a comprehensive evaluation benchmark is a concrete strength that could support future reproducible comparisons.
major comments (2)
- [ChameleonDataset construction pipeline] ChameleonDataset construction pipeline (abstract and §3): the description states that the pipeline produces paired style-content examples but supplies no details on how domain gaps, lighting conditions, texture statistics, or foreground-mask quality are controlled or validated against real-world imagery. This is load-bearing for the generalization claim that JHCL and STAG learn domain-invariant content rather than synthetic artifacts.
- [Abstract / Results] Abstract and results claims: the statement that the method 'outperforms state-of-the-art ... achieving improvements in both compositional plausibility and stylistic fidelity' is presented without any quantitative metrics, ablation tables, error bars, dataset statistics, or validation protocol. Because the central contribution is empirical, the absence of these elements prevents assessment of whether the data support the outperformance claim.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated the scale of ChameleonDataset (number of pairs, domains covered) and the precise evaluation metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major point below.
read point-by-point responses
-
Referee: [ChameleonDataset construction pipeline] ChameleonDataset construction pipeline (abstract and §3): the description states that the pipeline produces paired style-content examples but supplies no details on how domain gaps, lighting conditions, texture statistics, or foreground-mask quality are controlled or validated against real-world imagery. This is load-bearing for the generalization claim that JHCL and STAG learn domain-invariant content rather than synthetic artifacts.
Authors: Section 3 describes the scalable pipeline used to generate the paired examples. We agree that additional explicit discussion of controls for domain gaps, lighting, texture statistics, and mask quality, along with any validation steps against real imagery, would strengthen the manuscript. We will expand this section accordingly. revision: yes
-
Referee: [Abstract / Results] Abstract and results claims: the statement that the method 'outperforms state-of-the-art ... achieving improvements in both compositional plausibility and stylistic fidelity' is presented without any quantitative metrics, ablation tables, error bars, dataset statistics, or validation protocol. Because the central contribution is empirical, the absence of these elements prevents assessment of whether the data support the outperformance claim.
Authors: The experiments section contains quantitative comparisons, ablations, and evaluation protocols. We acknowledge that the abstract does not reference specific metrics and that clearer presentation of error bars and dataset statistics would aid assessment. We will revise the abstract to include key quantitative results and ensure the results section explicitly highlights these elements. revision: yes
Circularity Check
No circularity: empirical claims rest on dataset construction and benchmark comparisons
full rationale
The paper introduces ChameleonDataset via a scalable pipeline and proposes JHCL for style-content disentanglement plus STAG gating in a diffusion transformer. All performance claims are empirical outperformance on in-domain/cross-domain benchmarks against baselines and commercial models. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. The central results are falsifiable via external data and do not reduce to author-defined inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing ChatGPT Images 2.0
OpenAI. Introducing ChatGPT Images 2.0. https://openai.com/index/ introducing-chatgpt-images-2-0/ , April 2026. Accessed: 2026-05-07
2026
-
[2]
Gemini 3.1 flash image (nano banana 2)
Google DeepMind. Gemini 3.1 flash image (nano banana 2). https://deepmind. google/models/gemini-image/, 2026. Model ID: gemini-3.1-flash-image-preview. 10
2026
-
[3]
Objectstitch: Object compositing with diffusion model
Yizhi Song, Zhifei Zhang, Zhe Lin, Scott Cohen, Brian Price, Jianming Zhang, Soo Ye Kim, and Daniel Aliaga. Objectstitch: Object compositing with diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18310–18319, 2023
2023
-
[4]
Thinking outside the bbox: Uncon- strained generative object compositing
Gemma Canet Tarrés, Zhe Lin, Zhifei Zhang, Jianming Zhang, Yizhi Song, Dan Ruta, Andrew Gilbert, John Collomosse, and Soo Ye Kim. Thinking outside the bbox: Uncon- strained generative object compositing. In European Conference on Computer Vision , pages 476–495. Springer, 2024
2024
-
[5]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems , 33:6840–6851, 2020
2020
-
[6]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Er- mon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[7]
Anydoor: Zero-shot object-level image customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 6593–6602, 2024
2024
-
[8]
Dreamfuse: Adaptive image fusion with diffusion transformer
Junjia Huang, Pengxiang Yan, Jiyang Liu, Jie Wu, Zhao Wang, Yitong Wang, Liang Lin, and Guanbin Li. Dreamfuse: Adaptive image fusion with diffusion transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 17292–17301, 2025
2025
-
[9]
Poisson image editing
Patrick Pérez, Michel Gangnet, and Andrew Blake. Poisson image editing. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2 , pages 577–582. 2003
2003
-
[10]
A closed-form solution to natural image matting
Anat Levin, Dani Lischinski, and Yair Weiss. A closed-form solution to natural image matting. IEEE transactions on pattern analysis and machine intelligence , 30(2):228– 242, 2007
2007
-
[11]
Tf-icon: Diffusion-based training- free cross-domain image composition
Shilin Lu, Yanzhu Liu, and Adams Wai-Kin Kong. Tf-icon: Diffusion-based training- free cross-domain image composition. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 2294–2305, 2023
2023
-
[12]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 6038–6047, 2023
2023
-
[13]
Tale: Training-free cross-domain image composition via adaptive latent manipulation and energy-guided optimization
Kien T Pham, Jingye Chen, and Qifeng Chen. Tale: Training-free cross-domain image composition via adaptive latent manipulation and energy-guided optimization. In Pro- ceedings of the 32nd ACM International Conference on Multimedia , pages 3160–3169, 2024
2024
-
[14]
Aicomposer: Any style and content image composition via feature integration
Haowen Li, Zhenfeng Fan, Zhang Wen, Zhengzhou Zhu, and Yunjin Li. Aicomposer: Any style and content image composition via feature integration. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 16840–16850, 2025
2025
-
[15]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text com- patible image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Om- mer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10684–10695, 2022
2022
-
[17]
Arbitrary style transfer in real-time with adaptive in- stance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive in- stance normalization. In Proceedings of the IEEE international conference on computer vision, pages 1501–1510, 2017. 11
2017
-
[18]
Contrastive learning with hard negative samples
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples. arXiv preprint arXiv:2010.04592 , 2020
-
[19]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 18392–18402, 2023
2023
-
[21]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Compositing digital images
Thomas Porter and Tom Duff. Compositing digital images. In Proceedings of the 11th annual conference on Computer graphics and interactive techniques , pages 253–259, 1984
1984
-
[23]
A multiresolution spline with application to image mosaics
Peter J Burt and Edward H Adelson. A multiresolution spline with application to image mosaics. ACM Transactions on Graphics (ToG) , 2(4):217–236, 1983
1983
-
[24]
Paint by example: Exemplar-based image editing with diffusion models
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18381–18391, 2023
2023
-
[25]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[26]
Image style transfer using convolutional neural networks
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 2414–2423, 2016
2016
-
[27]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large- scale image recognition. arXiv preprint arXiv:1409.1556 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International confer- ence on machine learning , pages 8748–8763. PmLR, 2021
2021
-
[29]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 16000–16009, 2022
2022
-
[30]
Emerging properties in self-supervised vision transform- ers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bo- janowski, and Armand Joulin. Emerging properties in self-supervised vision transform- ers. In Proceedings of the IEEE/CVF international conference on computer vision , pages 9650–9660, 2021
2021
-
[31]
Splicing vit features for semantic appearance transfer
Narek Tumanyan, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Splicing vit features for semantic appearance transfer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10748–10757, 2022
2022
-
[32]
Deformable one-shot face stylization via dino semantic guidance
Yang Zhou, Zichong Chen, and Hui Huang. Deformable one-shot face stylization via dino semantic guidance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 7787–7796, 2024
2024
-
[33]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Erasedraw: Learning to insert objects by erasing them from images
Alper Canberk, Maksym Bondarenko, Ege Ozguroglu, Ruoshi Liu, and Carl Vondrick. Erasedraw: Learning to insert objects by erasing them from images. In European Conference on Computer Vision , pages 144–160. Springer, 2024
2024
-
[35]
Styletokenizer: Defining image style by a single instance for controlling diffusion models
Wen Li, Muyuan Fang, Cheng Zou, Biao Gong, Ruobing Zheng, Meng Wang, Jingdong Chen, and Ming Yang. Styletokenizer: Defining image style by a single instance for controlling diffusion models. In European Conference on Computer Vision , pages 110–
-
[36]
The artbench dataset: Bench- marking generative models with artworks
Peiyuan Liao, Xiuyu Li, Xihui Liu, and Kurt Keutzer. The artbench dataset: Bench- marking generative models with artworks. arXiv preprint arXiv:2206.11404 , 2022
-
[37]
Human-art: A ver- satile human-centric dataset bridging natural and artificial scenes
Xuan Ju, Ailing Zeng, Jianan Wang, Qiang Xu, and Lei Zhang. Human-art: A ver- satile human-centric dataset bridging natural and artificial scenes. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 618–629, 2023
2023
-
[38]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Liang- hao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts. arXiv preprint arXiv:2511.16719 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report. arXiv preprint arXiv:2508.02324 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved seman- tic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with con- trastive predictive coding. arXiv preprint arXiv:1807.03748 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Omnistyle: Filtering high quality style transfer data at scale
Ye Wang, Ruiqi Liu, Jiang Lin, Fei Liu, Zili Yi, Yilin Wang, and Rui Ma. Omnistyle: Filtering high quality style transfer data at scale. In Proceedings of the Computer Vision and Pattern Recognition Conference , pages 7847–7856, 2025
2025
-
[44]
Diffusest: Unleashing the capability of the dif- fusion model for style transfer
Ying Hu, Chenyi Zhuang, and Pan Gao. Diffusest: Unleashing the capability of the dif- fusion model for style transfer. In Proceedings of the 6th ACM International Conference on Multimedia in Asia , pages 1–1, 2024
2024
-
[45]
Structure- preserving zero-shot image editing via stage-wise latent injection in diffusion models
Dasol Jeong, Donggoo Kang, Jiwon Park, Hyebean Lee, and Joonki Paik. Structure- preserving zero-shot image editing via stage-wise latent injection in diffusion models. arXiv preprint arXiv:2504.15723 , 2025
-
[46]
Measuring style similarity in diffusion models
Gowthami Somepalli, Anubhav Gupta, Kamal Gupta, Shramay Palta, Micah Goldblum, Jonas Geiping, Abhinav Shrivastava, and Tom Goldstein. Measuring style similarity in diffusion models. arXiv preprint arXiv:2404.01292 , 2024
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 586–595, 2018
2018
-
[48]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. In Proceedings of the 2021 conference on empirical methods in natural language processing , pages 7514–7528, 2021. 13
2021
-
[49]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12268–12290, 2024
2024
-
[50]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned benchmark for personalized image generation. arXiv preprint arXiv:2406.16855 , 2024
-
[51]
EditVerse: Unifying Image and Video Editing and Generation with In-Context Learning
Xuan Ju, Tianyu Wang, Yuqian Zhou, He Zhang, Qing Liu, Nanxuan Zhao, Zhifei Zhang, Yijun Li, Yuanhao Cai, Shaoteng Liu, et al. Editverse: Unifying image and video editing and generation with in-context learning. arXiv preprint arXiv:2509.20360 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022
2022
-
[53]
Primecomposer: Faster progressively combined diffusion for image composition with attention steering
Yibin Wang, Weizhong Zhang, Jianwei Zheng, and Cheng Jin. Primecomposer: Faster progressively combined diffusion for image composition with attention steering. In Proceedings of the 32nd ACM International Conference on Multimedia , pages 10824– 10832, 2024
2024
-
[54]
Shilin Lu, Zhuming Lian, Zihan Zhou, Shaocong Zhang, Chen Zhao, and Adams Wai- Kin Kong. Does flux already know how to perform physically plausible image compo- sition? arXiv preprint arXiv:2509.21278 , 2025
-
[55]
Insert anything: Image insertion via in-context editing in dit
Wensong Song, Hong Jiang, Zongxin Yang, Zheqiao Cheng, Ruijie Quan, and Yi Yang. Insert anything: Image insertion via in-context editing in dit. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 40, pages 9097–9105, 2026
2026
-
[56]
Improved Aesthetic Predictor
Christoph Schuhmann. Improved Aesthetic Predictor. https://github.com/ christophschuhmann/improved-aesthetic-predictor , 2022
2022
-
[57]
FLUX.1 [dev]
Black Forest Labs. FLUX.1 [dev]. https://huggingface.co/black-forest-labs/ FLUX.1-dev, 2024
2024
-
[58]
Seg- ment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Seg- ment anything. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[59]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. In Pro- ceedings of the IEEE/CVF winter conference on applications of computer vision , pages 2149–2159, 2022
2022
-
[60]
Style injection in diffusion: A training- free approach for adapting large-scale diffusion models for style transfer
Jiwoo Chung, Sangeek Hyun, and Jae-Pil Heo. Style injection in diffusion: A training- free approach for adapting large-scale diffusion models for style transfer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 8795– 8805, 2024
2024
-
[61]
Artflow: Unbi- ased image style transfer via reversible neural flows
Jie An, Siyu Huang, Yibing Song, Dejing Dou, Wei Liu, and Jiebo Luo. Artflow: Unbi- ased image style transfer via reversible neural flows. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 862–871, 2021
2021
-
[62]
Styleshot: A snapshot on any style
Junyao Gao, Yanan Sun, Yanchen Liu, Yinhao Tang, Yanhong Zeng, Ding Qi, Kai Chen, and Cairong Zhao. Styleshot: A snapshot on any style. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2025
2025
-
[63]
Csgo: Content-style composition in text-to-image generation
Peng Xing, Haofan Wang, Yanpeng Sun, Qixun Wang, Xu Bai, Hao Ai, Renyuan Huang, and Zechao Li. Csgo: Content-style composition in text-to-image generation. arXiv preprint arXiv:2408.16766 , 2024. 14
-
[64]
Pixabay. Pixabay. https://pixabay.com, 2026
2026
-
[65]
Unsplash
Unsplash. Unsplash. https://unsplash.com, 2026
2026
-
[66]
Pexels. Pexels. https://www.pexels.com, 2026
2026
-
[67]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[68]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research , 21(140): 1–67, 2020. 15 Appendix In this supplementary material, we first provide details of ChameleonDataset in ...
-
[69]
f_seg full image: a clean object-centric reference on a white background
-
[70]
background_image full image : the target scene whose overall style should guide stylization
-
[71]
model_output full image: the final generated/composited result
-
[72]
model_output_crop: the cropped region inside the provided bounding box from the model output
-
[73]
Its white region is resized to the model output resolution before extracting the bounding box
background_mask image: the source used to define the target region. Its white region is resized to the model output resolution before extracting the bounding box. Criterion-specific Image Priority. • For Identity Preservation , focus primarily on the f_seg full image and the model_output_crop. • For Style Transfer Consistency , focus primarily on the backg...
-
[74]
Image A : the original crop image containing the target object and surrounding occluders
-
[75]
Image B: the segmented foreground image of the target object
-
[76]
Task Description
Target label: the semantic category associated with the candidate. Task Description. The filtering objective is to determine whether Image B provides a useful partial observation of the target object under occlusion. The model evaluates whether the remaining visible evidence supports plausible restoration or completion in later stages. Evaluation Rules. • ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.