GraphInfer-Bench: Benchmarking LLM's Inference Capability on Graphs
Pith reviewed 2026-06-27 10:39 UTC · model grok-4.3
The pith
No LLM method family matches plain GNNs on neighborhood graph inference tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
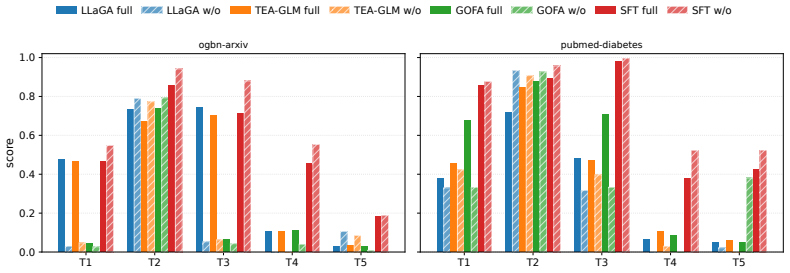
GraphInfer-Bench shows that no evaluated LLM family closes the inference gap: graph-token alignment works on some description tasks but fails comparisons, frontier LLMs lead among LLM methods on outlier detection and community partition yet lag on masked-node prediction, Graph2Text SFT is strongest on description but trails frontier models on comparison, and plain GNNs match or beat every LLM-based result across the board.
What carries the argument
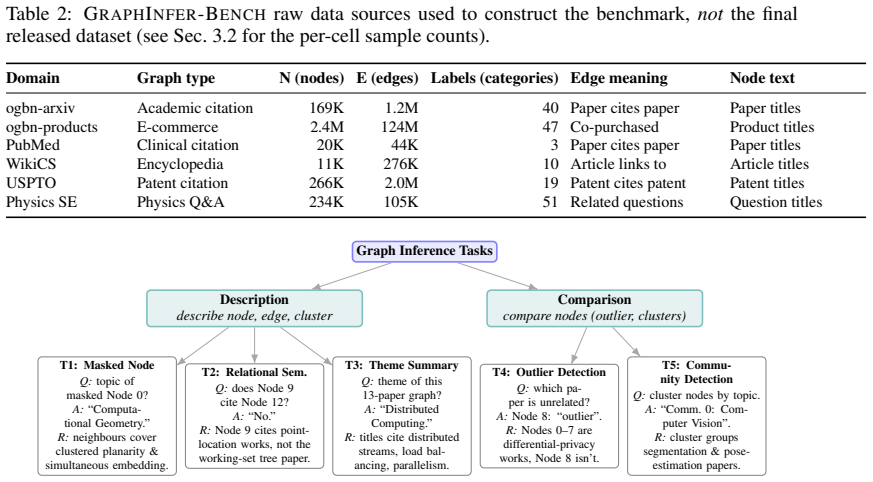
GraphInfer-Bench, a collection of five tasks (relational description, theme description, outlier detection, community partition, masked-node prediction) where ground truth lives only in collective neighborhood structure.
If this is right
- Graph-token alignment partially solves relational and theme description but collapses on comparison tasks.
- Frontier closed-source LLMs lead LLM-based methods on outlier detection and community partition yet remain weaker on masked-node prediction.
- Graph2Text supervised fine-tuning is the strongest LLM approach on description tasks but falls behind frontier LLMs on comparison tasks.
- Plain GNNs produce the largest performance margin over LLM methods on community detection.
Where Pith is reading between the lines
- The persistent gap suggests that current LLM architectures may lack built-in mechanisms for neighborhood aggregation that GNN layers supply directly.
- The benchmark tasks could serve as a testbed for hybrid models that route structural computation through GNN layers before language generation.
- If the quality screen truly isolates neighborhood inference, similar construction methods could be applied to other graph domains such as molecular or citation networks.
Load-bearing premise
The five tasks are built so that correct answers cannot be found in any single node or along any path, and the quality-control protocol ensures this property holds.
What would settle it
An LLM-based method achieving higher accuracy than the best GNN baseline on community partition or masked-node prediction within the released GraphInfer-Bench data would falsify the central result.
Figures



read the original abstract
Graph analysis underlies many applications whose answers cannot be looked up in a single record or retrieved along a path: laundering rings, drug repurposing, user preference, and scientific theme are all inferred from a node together with its neighbourhood. We introduce GraphInfer-Bench, a benchmark for whether LLMs can perform this graph inference: producing an open-ended answer that no single node supports and no path retrieves. Existing graph-QA protocols cannot test this capability: algorithm simulation, node classification, single-node description, KG-QA, and GraphRAG all admit answers retrievable from one node or along a path. GraphInfer-Bench defines five tasks along Description (what a region is) and Comparison (how regions differ), each constructed so the ground truth lives in no single node. The release contains 42,000 samples across six real-world graphs, produced automatically and screened by a four-layer quality-control protocol. We evaluate four method families against the same tasks: graph-token alignment models, zero-shot frontier closed-source LLMs, Graph2Text supervised fine-tuning, and plain GNNs as a structural reference. No method family closes the gap. Graph-token alignment partially handles description tasks (relational, theme) but collapses on comparison tasks. Frontier LLMs lead on outlier detection and community partition among LLM-based methods but lag on masked-node prediction. Graph2Text SFT is the strongest LLM-based method on the description side yet falls behind frontier LLMs on comparison. Across every task, plain GNNs match or beat the strongest LLM-based row, with the largest margin on community detection. GraphInfer-Bench surfaces graph inference as an open capability gap rather than a property of any one architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GraphInfer-Bench, a benchmark with 42,000 samples on five tasks (relational, theme, outlier detection, community partition, masked-node prediction) across six graphs. Tasks are constructed so ground truth requires neighborhood aggregation, not single-node lookup or path retrieval. Evaluations of graph-token alignment, frontier LLMs, Graph2Text SFT, and GNNs show no LLM family closes the gap, with GNNs matching or exceeding LLM performance, particularly on community detection.
Significance. Should the benchmark tasks genuinely demand multi-node inference as claimed, the result that plain GNNs outperform LLM-based methods would establish graph inference as an open problem for LLMs, providing a clear baseline and motivating research into better graph reasoning capabilities in language models.
major comments (2)
- [Abstract] Abstract: The headline result that 'plain GNNs match or beat the strongest LLM-based row' is stated without any numerical metrics, error bars, or statistical tests; the abstract supplies only qualitative ordering, preventing verification of the claimed margins (e.g., largest on community detection).
- [Abstract] Abstract: The four-layer quality-control protocol is asserted to ensure 'ground truth lives in no single node' and 'no path retrieves', yet no formal predicate, exhaustive path-enumeration procedure, or concrete sample traces are provided to demonstrate that neighborhood aggregation is indispensable rather than surface properties.
minor comments (1)
- [Abstract] Abstract: The task names (e.g., 'relational, theme') are introduced without brief definitions or references to their construction details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will incorporate revisions to improve clarity and verifiability while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result that 'plain GNNs match or beat the strongest LLM-based row' is stated without any numerical metrics, error bars, or statistical tests; the abstract supplies only qualitative ordering, preventing verification of the claimed margins (e.g., largest on community detection).
Authors: We agree that the abstract would benefit from quantitative support for the headline claim. The full manuscript already reports exact performance metrics, standard deviations across multiple runs, and task-specific margins in Tables 2-4, with the largest gap on community partition. In revision we will condense key numerical results (including approximate margins) and a note on statistical comparisons into the abstract to enable direct verification without altering the qualitative ordering. revision: yes
-
Referee: [Abstract] Abstract: The four-layer quality-control protocol is asserted to ensure 'ground truth lives in no single node' and 'no path retrieves', yet no formal predicate, exhaustive path-enumeration procedure, or concrete sample traces are provided to demonstrate that neighborhood aggregation is indispensable rather than surface properties.
Authors: The four-layer protocol and its rationale are detailed in the Benchmark Construction section, which specifies the checks used to confirm that answers cannot be obtained from a single node or a simple path. To strengthen the presentation, we will add an explicit formal predicate for the required neighborhood-aggregation property, a high-level description of the path-enumeration verification step, and one or two concrete sample traces (with node/edge annotations) either in the main text or as supplementary material. This addresses the request for more rigorous demonstration while remaining consistent with the existing construction. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivation chain
full rationale
The paper introduces GraphInfer-Bench as an empirical evaluation suite across five tasks on real graphs, reports direct performance numbers for four method families, and draws comparative conclusions from those measurements. No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or self-citation load-bearing steps appear in the reported methodology or results. The central claim (no LLM family closes the gap to GNNs) rests on tabulated accuracies rather than any reduction to prior self-referential constructs, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Certain inferences on real-world graphs require information aggregated from a node's neighborhood rather than contained in any single node or path.
Reference graph
Works this paper leans on
-
[1]
Claude Opus 4.7 System Card.https://www.anthropic.com/ claude-opus-4-7-system-card, April 2026
Anthropic. Claude Opus 4.7 System Card.https://www.anthropic.com/ claude-opus-4-7-system-card, April 2026
2026
-
[2]
Kqa pro: A dataset with explicit compositional programs for complex question answering over knowledge base
Shulin Cao, Jiaxin Shi, Liangming Pan, Lunyiu Nie, Yutong Xiang, Lei Hou, Juanzi Li, Bin He, and Hanwang Zhang. Kqa pro: A dataset with explicit compositional programs for complex question answering over knowledge base. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6101–6119, 2022. 9
2022
-
[3]
Graphwiz: An instruction-following lan- guage model for graph computational problems
Nuo Chen, Yuhan Li, Jianheng Tang, and Jia Li. Graphwiz: An instruction-following lan- guage model for graph computational problems. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 353–364, 2024
2024
-
[4]
LLaGA: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang Wang. LLaGA: Large language and graph assistant. InProceedings of the 41st International Conference on Machine Learning (ICML), pages 7809–7823, 2024
2024
-
[5]
Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, 25(2):42–61, 2024
Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. Exploring the potential of large language models (llms) in learning on graphs.ACM SIGKDD Explorations Newsletter, 25(2):42–61, 2024
2024
-
[6]
Talk like a graph: Encoding graphs for large language models.arXiv preprint arXiv:2310.04560, 2023
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. Talk like a graph: Encoding graphs for large language models.arXiv preprint arXiv:2310.04560, 2023
-
[7]
Beyond iid: three levels of generalization for question answering on knowledge bases
Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. Beyond iid: three levels of generalization for question answering on knowledge bases. InProceedings of the web conference 2021, pages 3477–3488, 2021
2021
-
[8]
Jiayan Guo, Lun Du, Hengyu Liu, Mengyu Zhou, Xinyi He, and Shi Han. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and bench- marking.arXiv preprint arXiv:2305.15066, 2023
-
[9]
G-retriever: Retrieval-augmented generation for textual graph un- derstanding and question answering.Advances in Neural Information Processing Systems, 37: 132876–132907, 2024
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-retriever: Retrieval-augmented generation for textual graph un- derstanding and question answering.Advances in Neural Information Processing Systems, 37: 132876–132907, 2024
2024
-
[10]
Systematic integration of biomedical knowledge prioritizes drugs for repurposing.elife, 6:e26726, 2017
Daniel Scott Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, and Sergio E Baranzini. Systematic integration of biomedical knowledge prioritizes drugs for repurposing.elife, 6:e26726, 2017
2017
-
[11]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[12]
Graph chain-of-thought: Augmenting large language models by reasoning on graphs
Bowen Jin, Chulin Xie, Jiawei Zhang, Kashob Kumar Roy, Yu Zhang, Zheng Li, Ruirui Li, Xianfeng Tang, Suhang Wang, Yu Meng, et al. Graph chain-of-thought: Augmenting large language models by reasoning on graphs. InFindings of the Association for Computational Linguistics: ACL 2024, pages 163–184, 2024
2024
-
[13]
Lecheng Kong, Jiarui Feng, Hao Liu, Chengsong Huang, Jiaxin Huang, Yixin Chen, and Muhan Zhang. Gofa: A generative one-for-all model for joint graph language modeling.arXiv preprint arXiv:2407.09709, 2024
-
[14]
Graphs over time: densification laws, shrinking diameters and possible explanations
Jure Leskovec, Jon Kleinberg, and Christos Faloutsos. Graphs over time: densification laws, shrinking diameters and possible explanations. InProceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining, pages 177–187, 2005
2005
-
[15]
Glbench: A comprehensive benchmark for graph with large language models
Yuhan Li, Peisong Wang, Xiao Zhu, Aochuan Chen, Haiyun Jiang, Deng Cai, Victor W Chan, and Jia Li. Glbench: A comprehensive benchmark for graph with large language models. Advances in Neural Information Processing Systems, 37:42349–42368, 2024
2024
-
[16]
Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangx- uan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quanti- zation for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[17]
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks.arXiv preprint arXiv:2310.00149, 2023. 10
-
[18]
Zihan Luo, Xiran Song, Hong Huang, Jianxun Lian, Chenhao Zhang, Jinqi Jiang, Xing Xie, and Hai Jin. Graphinstruct: Empowering large language models with graph understanding and reasoning capability.arXiv preprint arXiv:2403.04483, 2024
-
[19]
Wiki-cs: A wikipedia-based benchmark for graph neural networks,
Péter Mernyei and C ˘at˘alina Cangea. Wiki-cs: A wikipedia-based benchmark for graph neural networks.arXiv preprint arXiv:2007.02901, 2020
-
[20]
Financial fraud detection using graph neural networks: A systematic review.Expert Systems with Applications, 240:122156, 2024
Soroor Motie and Bijan Raahemi. Financial fraud detection using graph neural networks: A systematic review.Expert Systems with Applications, 240:122156, 2024
2024
-
[21]
Communities, modules and large-scale structure in networks.Nature physics, 8(1):25–31, 2012
Mark EJ Newman. Communities, modules and large-scale structure in networks.Nature physics, 8(1):25–31, 2012
2012
-
[22]
OpenAI. GPT-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Bryan Perozzi, Bahare Fatemi, Dustin Zelle, Anton Tsitsulin, Mehran Kazemi, Rami Al-Rfou, and Jonathan Halcrow. Let your graph do the talking: Encoding structured data for llms.arXiv preprint arXiv:2402.05862, 2024
-
[24]
Collective classification in network data.AI magazine, 29(3):93–93, 2008
Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Galligher, and Tina Eliassi- Rad. Collective classification in network data.AI magazine, 29(3):93–93, 2008
2008
-
[25]
Stack Exchange Data Dump
Stack Exchange, Inc. Stack Exchange Data Dump. Internet Archive,https://archive. org/details/stackexchange, 2024. Licensed under CC BY-SA 4.0; Physics Stack Ex- change subset used in this work
2024
-
[26]
The web as a knowledge-base for answering complex ques- tions
Alon Talmor and Jonathan Berant. The web as a knowledge-base for answering complex ques- tions. InProceedings of the 2018 Conference of the North American Chapter of the Associa- tion for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 641–651, 2018
2018
-
[27]
Graphgpt: Graph instruction tuning for large language models
Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 491–500, 2024
2024
-
[28]
Jianheng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, and Jia Li. Grapharena: Evaluating and exploring large language models on graph computation.arXiv preprint arXiv:2407.00379, 2024
-
[29]
Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024
Duo Wang, Yuan Zuo, Fengzhi Li, and Junjie Wu. Llms as zero-shot graph learners: Alignment of gnn representations with llm token embeddings.Advances in neural information processing systems, 37:5950–5973, 2024
2024
-
[30]
Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems, 36:30840–30861, 2023
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems, 36:30840–30861, 2023
2023
-
[31]
Stark: Benchmarking llm retrieval on textual and relational knowledge bases.Advances in Neural Information Process- ing Systems, 37:127129–127153, 2024
Shirley Wu, Shiyu Zhao, Michihiro Yasunaga, Kexin Huang, Kaidi Cao, Qian Huang, Vas- silis N Ioannidis, Karthik Subbian, James Zou, and Jure Leskovec. Stark: Benchmarking llm retrieval on textual and relational knowledge bases.Advances in Neural Information Process- ing Systems, 37:127129–127153, 2024
2024
-
[32]
Graph neural networks in recom- mender systems: a survey.ACM computing surveys, 55(5):1–37, 2022
Shiwen Wu, Fei Sun, Wentao Zhang, Xu Xie, and Bin Cui. Graph neural networks in recom- mender systems: a survey.ACM computing surveys, 55(5):1–37, 2022
2022
-
[33]
arXiv preprint arXiv:2506.05690 , year=
Zhishang Xiang, Chuanjie Wu, Qinggang Zhang, Shengyuan Chen, Zijin Hong, Xiao Huang, and Jinsong Su. When to use graphs in rag: A comprehensive analysis for graph retrieval- augmented generation.arXiv preprint arXiv:2506.05690, 2025
-
[34]
Yilin Xiao, Junnan Dong, Chuang Zhou, Su Dong, Qian-wen Zhang, Di Yin, Xing Sun, and Xiao Huang. Graphrag-bench: Challenging domain-specific reasoning for evaluating graph retrieval-augmented generation.arXiv preprint arXiv:2506.02404, 2025. 11
-
[35]
Crag-comprehensive rag benchmark.Ad- vances in Neural Information Processing Systems, 37:10470–10490, 2024
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze D Gui, Ziran W Jiang, Ziyu Jiang, et al. Crag-comprehensive rag benchmark.Ad- vances in Neural Information Processing Systems, 37:10470–10490, 2024
2024
-
[36]
Language is all a graph needs
Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. Language is all a graph needs. InFindings of the association for computational linguistics: EACL 2024, pages 1955–1973, 2024
2024
-
[37]
The value of semantic parse labeling for knowledge base question answering
Wen-tau Yih, Matthew Richardson, Christopher Meek, Ming-Wei Chang, and Jina Suh. The value of semantic parse labeling for knowledge base question answering. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 201–206, 2016
2016
-
[38]
Gracore: Benchmarking graph comprehension and complex reasoning in large language models
Zike Yuan, Ming Liu, Hui Wang, and Bing Qin. Gracore: Benchmarking graph comprehension and complex reasoning in large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 7925–7948, 2025
2025
-
[39]
Variational rea- soning for question answering with knowledge graph
Yuyu Zhang, Hanjun Dai, Zornitsa Kozareva, Alexander Smola, and Le Song. Variational rea- soning for question answering with knowledge graph. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[40]
Zhongjian Zhang, Xiao Wang, Mengmei Zhang, Jiarui Tan, and Chuan Shi. Toward graph- tokenizing large language models with reconstructive graph instruction tuning. InProceedings of the ACM Web Conference 2026, pages 430–441, 2026. 12 A Limitations GRAPHINFER-BENCHcurrently spans six text-attributed graph domains: academic citations, e- commerce co-purchase...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.