QuasiMoTTo: Quasi-Monte Carlo Test-Time Scaling
Pith reviewed 2026-07-02 15:15 UTC · model grok-4.3
The pith
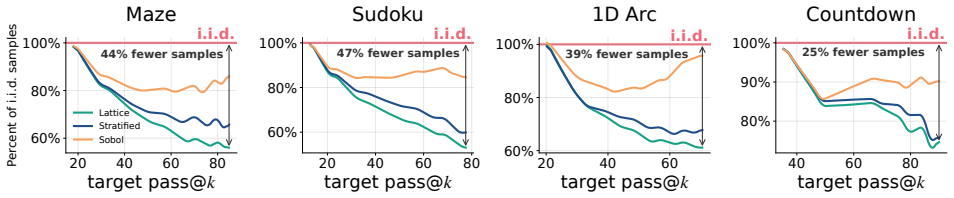
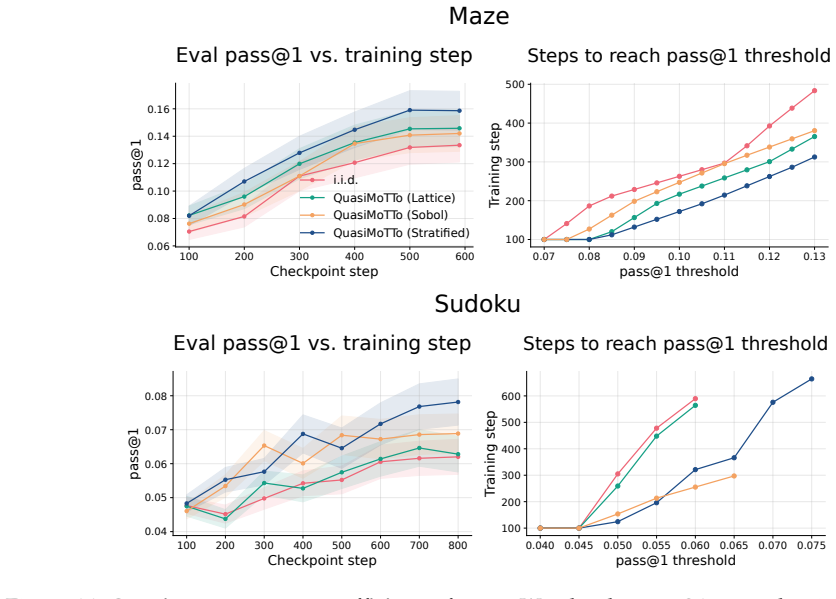
Quasi-Monte Carlo sampling matches independent sampling accuracy with 25-47 percent fewer samples on reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
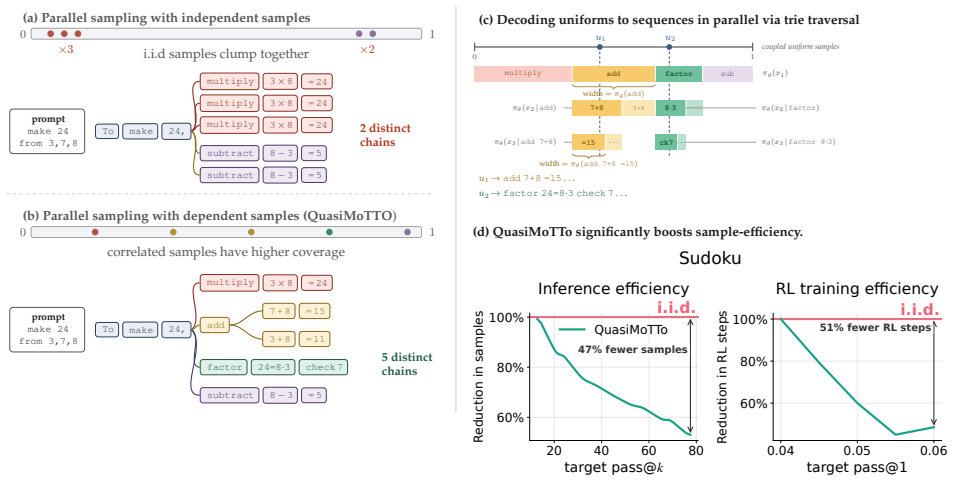
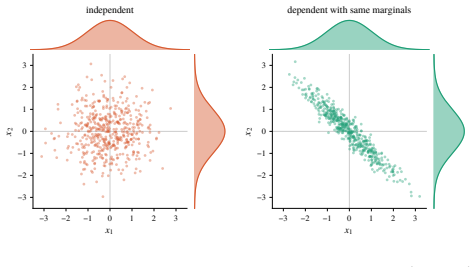
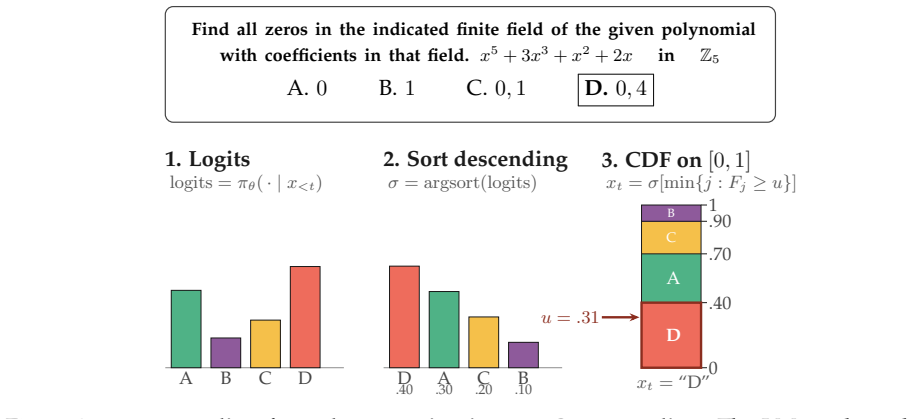
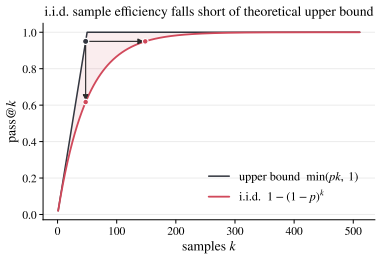
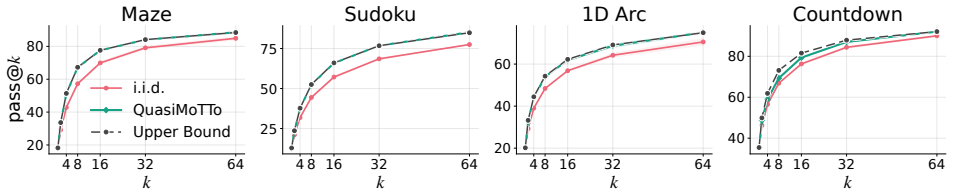
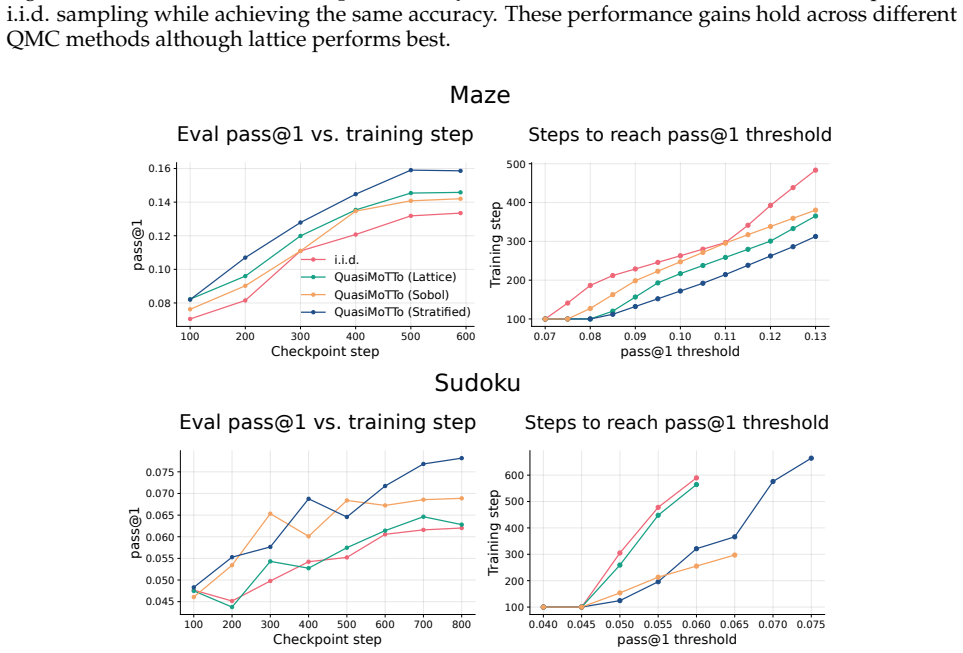
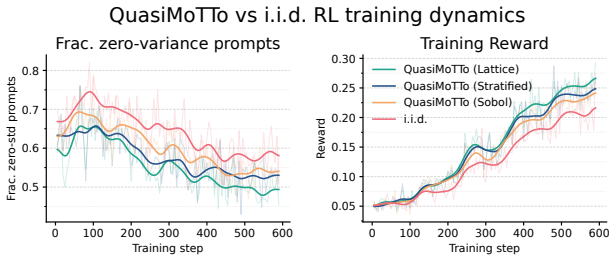
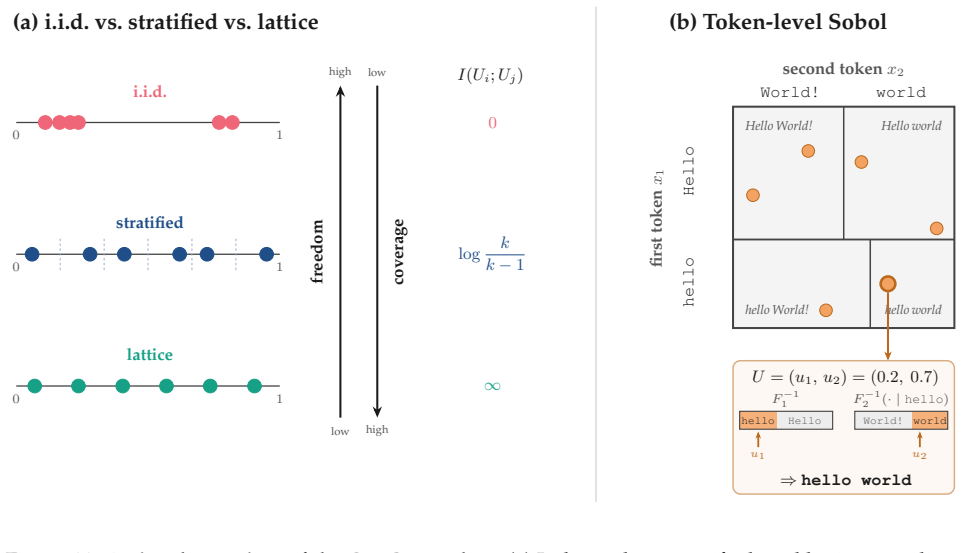
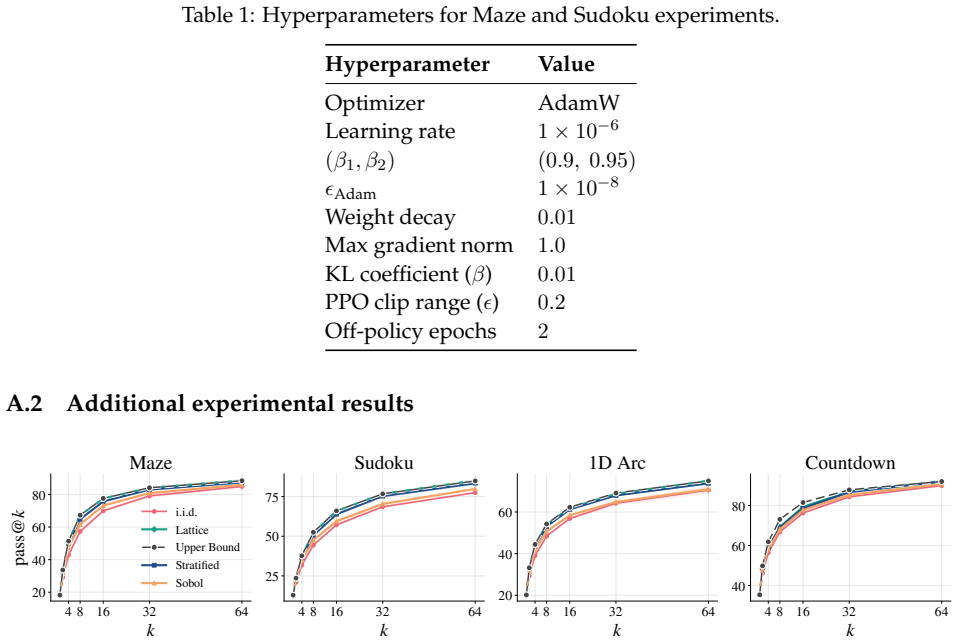
QuasiMoTTo reparameterizes autoregressive sampling as inverse-CDF sampling and draws the underlying uniforms with quasi-Monte Carlo sequences. The resulting batch is correlated yet each sample stays marginally distributed exactly according to the language model. This property lets the batch serve unchanged for pass@k evaluation and for policy-gradient updates. The lower redundancy produces higher coverage, which saturates an upper bound on pass@k that any marginal-preserving sampler must obey. Empirically the approach matches i.i.d. pass@k accuracy with 25-47 percent fewer samples and matches i.i.d. GRPO performance with 50 percent fewer training steps.
What carries the argument
Inverse-CDF reparameterization of autoregressive sampling paired with quasi-Monte Carlo low-discrepancy uniforms.
If this is right
- QuasiMoTTo matches i.i.d. pass@k accuracy with 25-47% fewer samples across four reasoning benchmarks.
- QuasiMoTTo often saturates an upper bound on pass@k that holds for any marginal-preserving sampler.
- QuasiMoTTo matches i.i.d. performance with 50% fewer training steps in GRPO.
- Higher coverage from the correlated samples yields a stronger learning signal per batch.
Where Pith is reading between the lines
- The same reparameterization could be applied to other parallel Monte Carlo tasks in generative modeling where sample overlap is costly.
- Saturation of the pass@k bound implies that further efficiency gains would require samplers that change the marginal distribution itself.
- The approach suggests that independence is not required for trivial parallel scaling once the marginals are preserved.
Load-bearing premise
Reparameterizing autoregressive sampling as inverse-CDF sampling lets quasi-Monte Carlo uniforms produce samples that remain exactly distributed according to the language model while adding useful correlation.
What would settle it
An experiment in which the empirical marginal distribution of QuasiMoTTo samples deviates from the language model or in which the bootstrap-estimated pass@k fails to exceed the i.i.d. curve for the same sample count.
Figures

read the original abstract
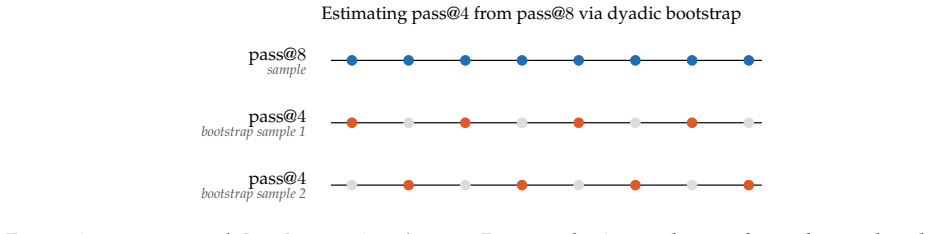
Scaling inference compute, by generating many parallel attempts per problem, is a costly but reliable lever for improving language model capabilities. By default these attempts are generated independently, wasting inference compute on redundant solutions. This waste seems unavoidable. After all, independence is what makes parallel sampling trivial to scale. However, this tradeoff is not fundamental: there is a rich design space of samplers that generate correlated but exact samples entirely in parallel. We explore this design space as an avenue for improving sample efficiency in scaling inference compute and reinforcement learning (RL). Concretely, we introduce QuasiMoTTo, which uses correlated samples as a drop-in replacement for i.i.d. samples. To generate these samples, QuasiMoTTo uses a reparameterization of autoregressive sampling as inverse-CDF sampling and draws the underlying uniforms with quasi-Monte Carlo (QMC); because QMC spreads the uniforms out more evenly than i.i.d., the resulting samples cover the output space with far less redundancy. Even though the batch is correlated, each sample is marginally distributed according to the language model, so we can use the batch for policy-gradient training. Our empirical analysis focuses on understanding how efficiently QuasiMoTTo can turn compute into performance. To evaluate correlated samplers, whose dependence breaks standard pass@k estimators, we first develop an unbiased bootstrap estimator. Across four reasoning benchmarks, QuasiMoTTo matches i.i.d. pass@k accuracy with 25-47% fewer samples. Strikingly, QuasiMoTTo often saturates an upper bound on pass@k that holds for any marginal-preserving sampler. We also apply QuasiMoTTo to policy-gradient RL (GRPO) where it matches i.i.d. performance with 50% fewer training steps. These gains come from higher coverage, which yields a stronger learning signal per batch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QuasiMoTTo, which reparameterizes autoregressive LM sampling as inverse-CDF sampling and replaces i.i.d. uniforms with QMC uniforms to generate correlated samples that remain marginally distributed according to the LM. This is positioned as a drop-in replacement for i.i.d. sampling to reduce redundancy in test-time scaling for reasoning and in GRPO policy gradients. An unbiased bootstrap estimator is developed to handle dependence when computing pass@k. Empirical results claim that QuasiMoTTo matches i.i.d. pass@k accuracy with 25-47% fewer samples across four benchmarks (often saturating a marginal-preserving upper bound) and matches i.i.d. GRPO performance with 50% fewer training steps.
Significance. If the marginal-preservation claim holds exactly and the bootstrap estimator is unbiased, the work demonstrates a concrete way to improve coverage and sample efficiency in parallel inference without sacrificing correctness or introducing bias in RL gradients. The bootstrap estimator itself is a useful methodological tool for dependent samplers. The saturation of the upper bound and the GRPO gains are notable if reproducible, but the overall significance hinges on verification that the QMC construction does not perturb the marginals.
major comments (2)
- [Abstract and reparameterization methods] The central claim that 'each sample is marginally distributed according to the language model' after the inverse-CDF + QMC reparameterization is load-bearing for all pass@k and GRPO results. The abstract provides no indication that randomized QMC (random shift, scrambling, or Owen scrambling) is applied; deterministic QMC sequences induce a point-mass distribution on token sequences rather than the target LM marginals. This must be clarified with the precise construction used (e.g., which QMC sequence and randomization layer) in the methods section, as the bootstrap estimator only corrects for dependence and does not restore marginal correctness.
- [Bootstrap estimator development] The unbiasedness of the bootstrap estimator for pass@k under QMC-induced dependence is asserted but not derived in the provided abstract. The estimator must be shown to remain unbiased specifically for the correlation structure produced by the QMC uniforms (not generic dependence), otherwise the 25-47% efficiency numbers cannot be directly compared to i.i.d. baselines.
minor comments (2)
- [Abstract] The four reasoning benchmarks are not named in the abstract; listing them (e.g., GSM8K, MATH, etc.) would improve immediate readability.
- [Methods] Notation for the inverse-CDF transform and the QMC sequence should be introduced with explicit equations early in the methods to make the reparameterization reproducible.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive report. The two major comments highlight important points on marginal preservation and estimator unbiasedness that we address below. We will revise the manuscript to improve clarity and add the requested details.
read point-by-point responses
-
Referee: [Abstract and reparameterization methods] The central claim that 'each sample is marginally distributed according to the language model' after the inverse-CDF + QMC reparameterization is load-bearing for all pass@k and GRPO results. The abstract provides no indication that randomized QMC (random shift, scrambling, or Owen scrambling) is applied; deterministic QMC sequences induce a point-mass distribution on token sequences rather than the target LM marginals. This must be clarified with the precise construction used (e.g., which QMC sequence and randomization layer) in the methods section, as the bootstrap estimator only corrects for dependence and does not restore marginal correctness.
Authors: We agree that explicit clarification is needed. The full manuscript implements randomized QMC via a randomly shifted Sobol sequence (base-2, dimension equal to the maximum sequence length), which ensures each individual uniform is exactly uniform on [0,1] and thus each autoregressive sample is marginally distributed according to the LM. The random shift is drawn once per batch and provides the required marginal correctness while inducing the negative dependence that improves coverage. We will revise the abstract to mention 'randomized quasi-Monte Carlo' and expand the methods section with the precise construction, including the randomization layer and a citation to the RQMC literature. This directly addresses the concern that marginals must be verified independently of the bootstrap. revision: yes
-
Referee: [Bootstrap estimator development] The unbiasedness of the bootstrap estimator for pass@k under QMC-induced dependence is asserted but not derived in the provided abstract. The estimator must be shown to remain unbiased specifically for the correlation structure produced by the QMC uniforms (not generic dependence), otherwise the 25-47% efficiency numbers cannot be directly compared to i.i.d. baselines.
Authors: The bootstrap estimator is constructed to be unbiased under the specific negative dependence induced by the randomized QMC uniforms. Because marginal correctness is preserved, the pass@k functional has the same expectation as under i.i.d. sampling; the bootstrap then resamples blocks that respect the observed joint structure while remaining unbiased for that expectation. We will add a self-contained derivation in the appendix that explicitly uses the RQMC correlation properties (negative association of the shifted points) rather than generic dependence, confirming that the 25-47% efficiency gains are valid comparisons to i.i.d. baselines. The current empirical numbers already employ this estimator. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces QuasiMoTTo via a reparameterization of autoregressive LM sampling as inverse-CDF sampling driven by QMC uniforms, asserts marginal preservation by the standard properties of that transform, develops a bootstrap estimator to handle dependence for pass@k evaluation, and reports empirical gains on benchmarks plus GRPO. No load-bearing step reduces by the paper's own equations or self-citations to a fitted input, self-defined quantity, or prior author result; the upper bound is stated as holding for any marginal-preserving sampler and the performance numbers are measured against external i.i.d. baselines. The derivation is therefore self-contained against external benchmarks rather than circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rethinking fine-tuning when scaling test-time compute: Limiting confidence improves mathematical reasoning
Feng Chen, Allan Raventos, Nan Cheng, Surya Ganguli, and Shaul Druckmann. Rethinking fine-tuning when scaling test-time compute: Limiting confidence improves mathematical reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley Series in Telecom- munications and Signal Processing. Wiley-Interscience, USA, 2 edition, 2006. ISBN 0471241954
2006
-
[4]
Flashattention: Fast and memory-efficient exact attention with IO-awareness
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher Re. Flashattention: Fast and memory-efficient exact attention with IO-awareness. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
2022
-
[5]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025
2025
-
[6]
CARMS: Categorical-antithetic-REINFORCE multi- sample gradient estimator
Alek Dimitriev and Mingyuan Zhou. CARMS: Categorical-antithetic-REINFORCE multi- sample gradient estimator. InAdvances in Neural Information Processing Systems, volume 34. Curran Associates, Inc., 2021
2021
-
[7]
Stream of search (sos): Learning to search in language
Kanishk Gandhi, Denise H J Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah Goodman. Stream of search (sos): Learning to search in language. InFirst Conference on Language Modeling, 2024
2024
-
[8]
Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STars
Kanishk Gandhi, Ayush K Chakravarthy, Anikait Singh, Nathan Lile, and Noah Goodman. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STars. InSecond Conference on Language Modeling, 2025
2025
-
[9]
Li, Lyle Goodyear, Agam Bhatia, Louise Li, Aditi Bhaskar, Mo- hammed Zaman, and Noah D
Kanishk Gandhi, Michael Y. Li, Lyle Goodyear, Agam Bhatia, Louise Li, Aditi Bhaskar, Mo- hammed Zaman, and Noah D. Goodman. Boxinggym: Benchmarking progress in automated experimental design and model discovery, 2025
2025
-
[10]
Speeding up rl with high- leverage samples
Agastya Goel and Linden Li. Speeding up rl with high- leverage samples. https://www.appliedcompute.com/research/ speeding-up-rl-with-high-leverage-samples, 2026
2026
-
[11]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, page 633–638, 2025
2025
-
[12]
SPIRAL: Learning to Search and Aggregate
Jubayer Ibn Hamid, Ifdita Hasan Orney, Michael Y. Li, Omar Shaikh, Yoonho Lee, Dorsa Sadigh, Chelsea Finn, and Noah Goodman. Spiral: Learning to search and aggregate, 2026. URL https://arxiv.org/abs/2606.23595. 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Polychromic objectives for reinforcement learning
Jubayer Ibn Hamid, Ifdita Hasan Orney, Ellen Xu, Chelsea Finn, and Dorsa Sadigh. Polychromic objectives for reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[14]
Li, Sherry Yang, Chelsea Finn, Emma Brunskill, and Noah D
Joy He-Yueya, Anikait Singh, Ge Gao, Michael Y. Li, Sherry Yang, Chelsea Finn, Emma Brunskill, and Noah D. Goodman. Giants: Generative insight anticipation from scientific literature, 2026
2026
-
[15]
Stochastic beams and where to find them: The Gumbel-top-k trick for sampling sequences without replacement
Wouter Kool, Herke Van Hoof, and Max Welling. Stochastic beams and where to find them: The Gumbel-top-k trick for sampling sequences without replacement. InProceedings of the 36th International Conference on Machine Learning, 2019
2019
-
[16]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, 2023
2023
-
[17]
Li, Emily B
Michael Y. Li, Emily B. Fox, and Noah D. Goodman. Automated statistical model discovery with language models, 2024
2024
-
[18]
Li, Jubayer Ibn Hamid, Emily B
Michael Y. Li, Jubayer Ibn Hamid, Emily B. Fox, and Noah D. Goodman. Neural garbage collection: Learning to forget while learning to reason, 2026
2026
-
[19]
David J. C. MacKay. Information theory, inference & learning algorithms, 2002
2002
-
[20]
Divide-and-conquer cot: Rl for reducing latency via parallel reasoning, 2026
Arvind Mahankali, Kaiyue Wen, and Tengyu Ma. Divide-and-conquer cot: Rl for reducing latency via parallel reasoning, 2026
2026
-
[21]
Li, and Emily B
Yuzhen Mao, Michael Y. Li, and Emily B. Fox. Simplified sparse attention via gist tokens, 2026
2026
-
[22]
Alexander Novikov, Ngân V ˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Openai o1 system card, 2026
OpenAI. Openai o1 system card, 2026
2026
-
[24]
Poly-epo: Training exploratory reasoning models, 2026
Ifdita Hasan Orney, Jubayer Ibn Hamid, Shreya S Ramanujam, Shirley Wu, Hengyuan Hu, Noah Goodman, Dorsa Sadigh, and Chelsea Finn. Poly-epo: Training exploratory reasoning models, 2026
2026
-
[25]
Owen.Monte Carlo Theory, Methods and Examples
Art B. Owen.Monte Carlo Theory, Methods and Examples. Art Owen, 2013
2013
-
[26]
Learning adaptive parallel reasoning with language models
Jiayi Pan, Xiuyu Li, Long Lian, Charlie Victor Snell, Yifei Zhou, Adam Yala, Trevor Darrell, Kurt Keutzer, and Alane Suhr. Learning adaptive parallel reasoning with language models. In Second Conference on Language Modeling, 2025
2025
-
[27]
Quasi-random multi-sample inference for large language models, 2025
Aditya Parashar, Aditya Vikram Singh, Avinash Amballa, Jinlin Lai, and Benjamin Rozonoyer. Quasi-random multi-sample inference for large language models, 2025
2025
-
[28]
On the distribution of points in a cube and the approximate evaluation of integrals
I.M Sobol’. On the distribution of points in a cube and the approximate evaluation of integrals. USSR Computational Mathematics and Mathematical Physics, 7(4):86–112, 1967. ISSN 0041-5553. doi: https://doi.org/10.1016/0041-5553(67)90144-9. URL https://www.sciencedirect. com/science/article/pii/0041555367901449. 18
-
[29]
Maximum likelihood reinforcement learning, 2026
Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, and Andrea Zanette. Maximum likelihood reinforcement learning, 2026
2026
-
[30]
Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models
Ashwin K. Vijayakumar, Michael Cogswell, Ramprasaath R. Selvaraju, Qing Sun, Stefan Lee, David J. Crandall, and Dhruv Batra. Diverse beam search: Decoding diverse solutions from neural sequence models.CoRR, abs/1610.02424, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Arith- metic sampling: parallel diverse decoding for large language models
Luke Vilnis, Yury Zemlyanskiy, Patrick Murray, Alexandre Passos, and Sumit Sanghai. Arith- metic sampling: parallel diverse decoding for large language models. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[32]
New York, 2010
Larry Wasserman.All of statistics : a concise course in statistical inference. New York, 2010
2010
-
[33]
Yudong Xu, Wenhao Li, Pashootan Vaezipoor, Scott Sanner, and Elias B. Khalil. Llms and the abstraction and reasoning corpus: Successes, failures, and the importance of object-based representations, 2024
2024
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Group sequence policy optimization, 2025
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. 19 A Technical appendices and supplementary material A.1 Experiment Details Maze Countdown ********* *E..*...* *.***.*** *.......* ***.*.*** *...*...* *S*.***** *.*.......
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.