Ouroboros-Spatial: Closing the Data-Model Loop for Spatial Reasoning
Pith reviewed 2026-06-27 10:24 UTC · model grok-4.3
The pith
Ouroboros-Spatial lets an MLLM act as both question proposer and solver so that its own confidence scores steer the next round of spatial QA generation, co-evolving the training distribution with model ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
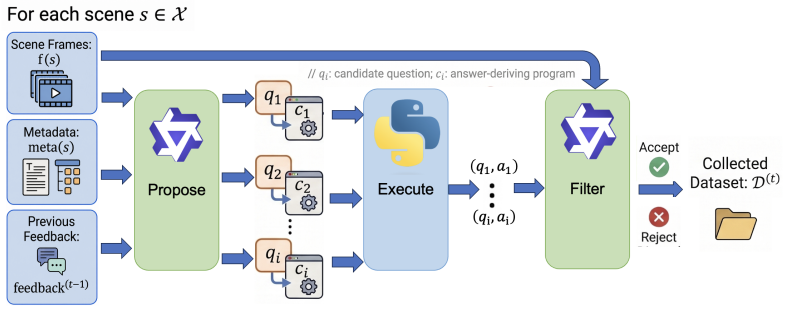
Ouroboros-Spatial is a self-evolving training framework in which the model simultaneously serves as a frozen proposer that generates spatial question-answer pairs plus executable code from 3D scene metadata and raw video frames, and as a learnable solver that is fine-tuned on the accepted samples; the solver’s per-sample prediction confidence is then fed back to the proposer so that subsequent questions are better calibrated to the solver’s present capabilities, thereby reducing redundant trivial examples and filtering ambiguous samples with limited learning value.
What carries the argument
The closed-loop feedback mechanism in which the solver’s per-sample prediction confidence is used as a difficulty signal to guide the frozen proposer’s generation of new spatial QA pairs.
If this is right
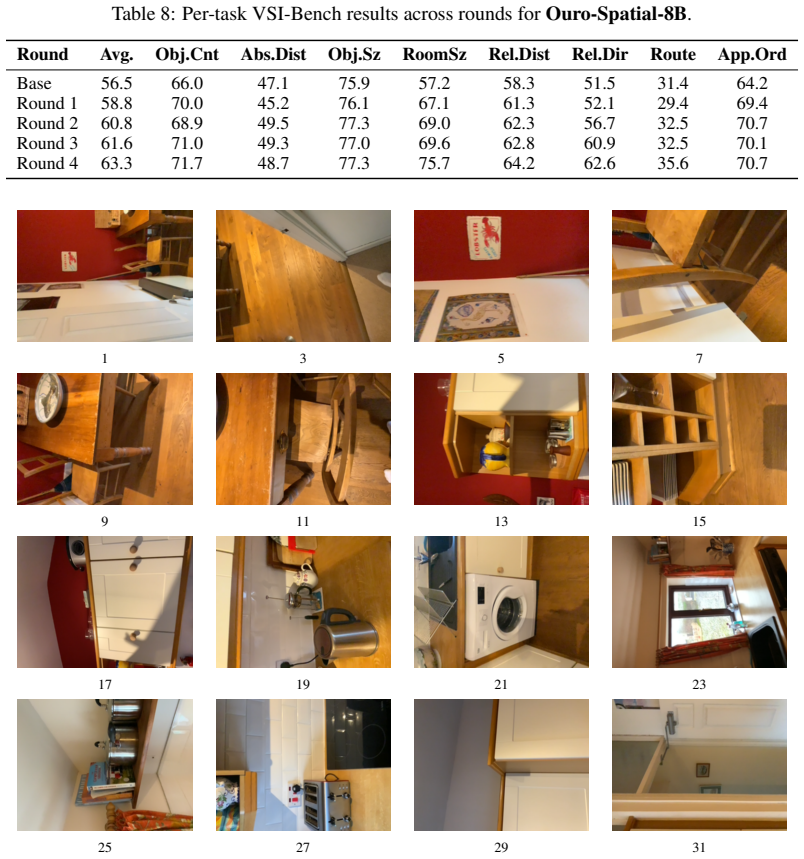
- The same volume of generated data yields absolute gains of 9.9 points for the 4B model and 6.8 points for the 8B model on VSI-Bench.
- Both improved models outperform a wide range of strong open-source and proprietary baselines across six spatial-reasoning benchmarks.
- Training requires an order of magnitude fewer examples than recent large-scale statically curated datasets.
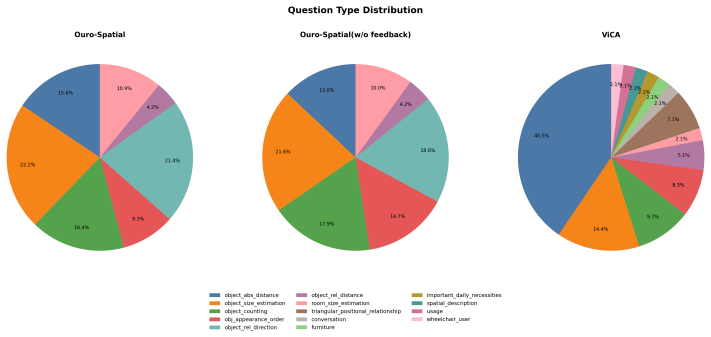
- The training distribution automatically sheds trivial and ambiguous samples as the solver improves.
Where Pith is reading between the lines
- The same proposer-solver loop could be applied to other multimodal reasoning domains such as temporal or causal inference without requiring new human-curated seeds.
- Continuous deployment versions could keep the proposer active after initial training, allowing the model to keep generating and filtering its own practice data from new video streams.
- If the confidence signal proves robust, the method reduces reliance on large human-annotated spatial datasets and shifts curation effort toward designing the initial 3D metadata sources.
Load-bearing premise
The per-sample prediction confidence produced by the solver serves as a reliable and unbiased signal of learning value that can safely guide the frozen proposer to generate more useful questions without systematically discarding valuable examples or introducing self-reinforcing biases in the data distribution.
What would settle it
Replace the solver’s actual confidence scores with random values of the same distribution and retrain; if the resulting models show no accuracy advantage over a control trained on the same volume of uniformly sampled questions, the claimed value of the feedback signal is refuted.
Figures


read the original abstract
Spatial reasoning remains a persistent challenge for multimodal large language models (MLLMs). Existing approaches largely rely on large-scale, statically curated datasets, where all training samples are treated uniformly regardless of the model's evolving capabilities. This static paradigm is inherently data-inefficient: training capacity is often spent on samples that are either trivial or overly difficult for the model at its current stage. To address this limitation, we propose Ouroboros-Spatial, a self-evolving training framework in which the model plays dual roles as a proposer and a solver. In each iteration, a frozen proposer generates spatial question-answer (QA) pairs from 3D scene metadata and raw video frames, together with executable code for deriving reliable ground truth. A learnable solver is then fine-tuned on the accepted samples, and its per-sample prediction confidence is used as a difficulty signal. This signal is fed back to the proposer in the next iteration, guiding it to generate questions better matched to the solver's current capabilities. Through this closed-loop design, the training distribution co-evolves with model ability, reducing redundant trivial examples while filtering out ambiguous or uninformative samples with limited learning value. Across six spatial reasoning benchmarks, Ouroboros-Spatial substantially improves Qwen3-VL-4B and Qwen3-VL-8B while using an order of magnitude fewer training examples than recent large-scale curated datasets. On VSI-Bench, it yields absolute gains of 9.9 and 6.8 points for the 4B and 8B models, respectively, enabling both to outperform a wide range of strong open-source and proprietary baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Ouroboros-Spatial, a self-evolving closed-loop framework for spatial reasoning in MLLMs. A frozen proposer generates spatial QA pairs from 3D scene metadata and video frames together with executable code for ground truth; a learnable solver is fine-tuned on accepted samples; and the solver's per-sample prediction confidence is fed back as a difficulty signal to steer the proposer toward questions better matched to the solver's current capabilities. The approach is claimed to improve Qwen3-VL-4B and Qwen3-VL-8B across six benchmarks while using an order of magnitude fewer examples than prior large-scale datasets, with absolute gains of 9.9 and 6.8 points on VSI-Bench.
Significance. If the results hold after proper validation, the framework could meaningfully advance data-efficient training for multimodal models by dynamically co-evolving the training distribution with model ability rather than relying on static curated datasets. The use of executable code to derive ground truth is a concrete strength that helps bound circularity and supports reliable labels.
major comments (2)
- [Abstract] Abstract: The central claim that solver per-sample prediction confidence is a reliable, unbiased difficulty signal for guiding the proposer rests on untested assumptions (calibration for spatial QA, correlation with actual learning gain, and absence of self-reinforcing bias). No calibration plots, correlation analysis with held-out learning gain, or ablation isolating confidence-based selection from random/heuristic selection is described.
- [Abstract] Abstract: Reported benchmark gains (e.g., +9.9 / +6.8 on VSI-Bench) are presented without any information on experimental controls, statistical significance testing, number of runs, or validation that the executable ground-truth code produces correct labels across the generated distribution; this information is load-bearing for assessing whether the closed loop actually delivers the claimed data efficiency.
minor comments (1)
- [Abstract] The abstract would benefit from a concise statement of the number of iterations and the precise acceptance criterion used to filter samples.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical validation of the confidence-based difficulty signal and experimental rigor. We agree these elements are important for substantiating the closed-loop claims and will revise the manuscript accordingly by adding the requested analyses and details.
read point-by-point responses
-
Referee: The central claim that solver per-sample prediction confidence is a reliable, unbiased difficulty signal for guiding the proposer rests on untested assumptions (calibration for spatial QA, correlation with actual learning gain, and absence of self-reinforcing bias). No calibration plots, correlation analysis with held-out learning gain, or ablation isolating confidence-based selection from random/heuristic selection is described.
Authors: We acknowledge the validity of this critique. The manuscript currently presents performance improvements as supporting evidence for the signal's utility but does not include direct validation. In the revised version we will add: (1) calibration plots of solver confidence on held-out spatial QA samples, (2) correlation analysis between per-sample confidence and subsequent learning gain on a held-out set, and (3) an ablation comparing confidence-guided selection against random and heuristic baselines. These will appear in a new subsection under Experiments. revision: yes
-
Referee: Reported benchmark gains (e.g., +9.9 / +6.8 on VSI-Bench) are presented without any information on experimental controls, statistical significance testing, number of runs, or validation that the executable ground-truth code produces correct labels across the generated distribution; this information is load-bearing for assessing whether the closed loop actually delivers the claimed data efficiency.
Authors: We agree that these details are necessary. The revised manuscript will report: three independent runs with mean and standard deviation, statistical significance via paired t-tests (p < 0.01 on VSI-Bench gains), explicit controls (static dataset baselines and random selection), and expanded ground-truth validation including manual inspection of 500 generated QA pairs plus automated checks for code execution errors across the full distribution. These elements will be added to Section 4 and the supplementary material. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents an iterative self-evolving framework in which a frozen proposer generates QA pairs with code-derived ground truth and a learnable solver is fine-tuned, with its per-sample confidence used only as a heuristic signal to steer subsequent generation. No equations, self-citations, or definitional steps are shown that reduce the reported benchmark gains to the input data or to the confidence signal by construction. The central claims (absolute gains of 9.9/6.8 points on VSI-Bench with far fewer examples) are empirical and externally falsifiable on held-out benchmarks. This satisfies the default expectation of a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://deepmind.google/models/ model-cards/gemini-3-1-pro/
Gemini 3.1 pro - model card, 2026. URL https://deepmind.google/models/ model-cards/gemini-3-1-pro/
2026
-
[2]
URL https://qwen.ai/blog?id= qwen3.5
Qwen3.5: Towards native multimodal agents, 2026. URL https://qwen.ai/blog?id= qwen3.5
2026
-
[3]
Emre Can Acikgoz, Cheng Qian, Jonas Hübotter, Heng Ji, Dilek Hakkani-Tür, and Gokhan Tur. Tool-r0: Self-evolving llm agents for tool-learning from zero data.arXiv preprint arXiv:2602.21320, 2026
arXiv 2026
-
[4]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
Pith/arXiv arXiv 2025
-
[5]
ARKitScenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yair Feigelstock, Xu Fu, Yasutaka Furukawa, Aviv Goldberger, Binyamin Gottfried, Ran Halperin, et al. ARKitScenes: A diverse real-world dataset for 3d indoor scene understanding using mobile RGB-D data. InNeurIPS Datasets and Benchmarks Track, 2021. URLhttps://arxiv.org/abs/2111.08897
Pith/arXiv arXiv 2021
-
[6]
Seed2.0 model card: Towards intelligence frontier for real-world complexity
ByteDance Seed. Seed2.0 model card: Towards intelligence frontier for real-world complexity. Technical report, ByteDance, 2025. URL https://lf3-static.bytednsdoc.com/ obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model% 20Card.pdf
2025
-
[7]
Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025
Zhongang Cai, Ruisi Wang, Chenyang Gu, Fanyi Pu, Junxiang Xu, et al. Scaling spatial intelligence with multimodal foundation models.arXiv preprint arXiv:2511.13719, 2025. URL https://arxiv.org/abs/2511.13719
arXiv 2025
-
[8]
Meng Cao, Xingyu Li, Xue Liu, Ian Reid, and Xiaodan Liang. Spatialdreamer: Incentivizing spatial reasoning via active mental imagery.arXiv preprint arXiv:2512.07733, 2025. URL https://arxiv.org/abs/2512.07733
arXiv 2025
-
[9]
Meng Cao, Haokun Lin, Haoyuan Li, Haoran Tang, Rongtao Xu, Dong An, Xue Liu, Ian Reid, and Xiaodan Liang. Seeing through imagination: Learning scene geometry via implicit spatial world modeling.arXiv preprint arXiv:2512.01821, 2025. URL https://arxiv.org/abs/ 2512.01821
arXiv 2025
-
[10]
Thinking with spatial code for physical-world video reasoning.arXiv preprint arXiv:2603.05591, 2026
Jieneng Chen, Wenxin Ma, Ruisheng Yuan, Yunzhi Zhang, Jiajun Wu, and Alan Yuille. Thinking with spatial code for physical-world video reasoning.arXiv preprint arXiv:2603.05591, 2026. URLhttps://arxiv.org/abs/2603.05591
arXiv 2026
-
[11]
Self- questioning language models.arXiv preprint arXiv:2508.03682, 2025
Lili Chen, Mihir Prabhudesai, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. Self- questioning language models.arXiv preprint arXiv:2508.03682, 2025. URL https://arxiv. org/abs/2508.03682. 10
arXiv 2025
-
[12]
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, and Jonathan Tremblay. Spacetools: Tool-augmented spatial reasoning via double interactive rl.arXiv preprint arXiv:2512.04069, 2025. URL https://arxiv.org/abs/2512.04069
Pith/arXiv arXiv 2025
-
[13]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025. URL https://arxiv.org/abs/2510.18632
arXiv 2025
-
[14]
Self-play fine-tuning converts weak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. InInternational Conference on Machine Learning, 2024. URLhttps://arxiv.org/abs/2401.01335
Pith/arXiv arXiv 2024
-
[15]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[16]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuan-Jing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346–355, 2024
2024
-
[17]
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Peihao Wang, Huaizhi Qu, Shijie Zhou, et al. VLM-3R: Vision-language models augmented with instruction-aligned 3D reconstruction.arXiv preprint arXiv:2505.20279, 2025. URL https://arxiv.org/abs/2505.20279
Pith/arXiv arXiv 2025
-
[19]
URLhttps://arxiv.org/abs/2508.07407
-
[20]
Visuospatial cognitive assistant.arXiv preprint arXiv:2505.12312, 2025
Qi Feng. Visuospatial cognitive assistant.arXiv preprint arXiv:2505.12312, 2025. URL https://arxiv.org/abs/2505.12312
arXiv 2025
-
[21]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[22]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
2024
-
[23]
Xiangjun Gao, Zhensong Zhang, Dave Zhenyu Chen, Songcen Xu, Long Quan, Eduardo Pérez- Pellitero, and Youngkyoon Jang. Map2thought: Explicit 3d spatial reasoning via metric cognitive maps.arXiv preprint arXiv:2601.11442, 2026. URL https://arxiv.org/abs/2601.11442
arXiv 2026
-
[24]
Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
Yicheng He, Chengsong Huang, Zongxia Li, Jiaxin Huang, and Yonghui Yang. Visplay: Self-evolving vision-language models from images.arXiv preprint arXiv:2511.15661, 2025
arXiv 2025
-
[25]
R-zero: Self-evolving reasoning llm from zero data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. In The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025, 2025
2025
-
[26]
Language self-play for data-free training.arXiv preprint arXiv:2509.07414, 2025
Jakub Grudzien Kuba, Mengting Gu, Qi Ma, Yuandong Tian, Vijai Mohan, and Jason Chen. Language self-play for data-free training.arXiv preprint arXiv:2509.07414, 2025
arXiv 2025
-
[27]
Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024. 11
Pith/arXiv arXiv 2024
-
[28]
Imagine while reasoning in space: Multimodal visualization-of-thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli ´c, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought. In International Conference on Machine Learning, pages 36340–36364. PMLR, 2025
2025
-
[29]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi- perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500, 2025
arXiv 2025
-
[30]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[31]
Zongxia Li, Hongyang Du, Chengsong Huang, Xiyang Wu, Lantao Yu, Yicheng He, Jing Xie, Xiaomin Wu, Zhichao Liu, Jiarui Zhang, and Fuxiao Liu. MM-Zero: Self-evolving multi- model vision language models with zero data.arXiv preprint arXiv:2603.09206, 2026. URL https://arxiv.org/abs/2603.09206
arXiv 2026
-
[32]
Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
arXiv 2025
-
[33]
Diving into self- evolving training for multimodal reasoning
Wei Liu, Junlong Li, Xiwen Zhang, Fan Zhou, Yu Cheng, and Junxian He. Diving into self- evolving training for multimodal reasoning. InInternational Conference on Machine Learning, pages 38842–38856. PMLR, 2025
2025
-
[34]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025. URLhttps://arxiv.org/abs/2511.15722
arXiv 2025
-
[35]
Weijian Ma, Shizhao Sun, Tianyu Yu, Ruiyu Wang, Tat-Seng Chua, and Jiang Bian. Thinking with blueprints: Assisting vision-language models in spatial reasoning via structured object representation.arXiv preprint arXiv:2601.01984, 2026. URL https://arxiv.org/abs/ 2601.01984
arXiv 2026
-
[36]
Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. Aimo-2 winning solution: Building state-of-the-art math- ematical reasoning models with openmathreasoning dataset.arXiv preprint arXiv:2504.16891, 2025
arXiv 2025
-
[37]
SpaceR: Reinforcing MLLMs in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. SpaceR: Reinforcing MLLMs in video spatial reasoning.arXiv preprint arXiv:2504.01805, 2025. URLhttps://arxiv.org/abs/2504.01805
Pith/arXiv arXiv 2025
-
[38]
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A Plummer, Ranjay Krishna, et al. Sat: Dynamic spatial aptitude training for multimodal language models.arXiv preprint arXiv:2412.07755, 2024. URLhttps://arxiv.org/abs/2412.07755
arXiv 2024
-
[39]
Openai gpt-5 system card, 2025
Aaditya Singh et al. Openai gpt-5 system card, 2025. URL https://arxiv.org/abs/2601. 03267
2025
-
[40]
Spacevista: All-scale visual spatial reasoning from mm to km.arXiv preprint arXiv:2510.09606, 2025
Peiwen Sun, Shiqiang Lang, Dongming Wu, Yi Ding, Kaituo Feng, Huadai Liu, Zhen Ye, Rui Liu, Yun-Hui Liu, Jianan Wang, et al. Spacevista: All-scale visual spatial reasoning from mm to km.arXiv preprint arXiv:2510.09606, 2025. URLhttps://arxiv.org/abs/2510.09606
Pith/arXiv arXiv 2025
-
[41]
Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montser- rat Gonzalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025. 12
Pith/arXiv arXiv 2025
-
[42]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Pith/arXiv arXiv 2026
-
[43]
Omkar Thawakar, Shravan Venkatraman, Ritesh Thawkar, Abdelrahman Shaker, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, and Fahad Khan. EvoLMM: Self-evolving large multimodal models with continuous rewards.arXiv preprint arXiv:2511.16672, 2025. URLhttps://arxiv.org/abs/2511.16672
Pith/arXiv arXiv 2025
-
[44]
Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. Muirbench: A comprehensive benchmark for robust multi-image understanding.arXiv preprint arXiv:2406.09411, 2024
Pith/arXiv arXiv 2024
-
[45]
Self-improving multimodal reasoning with zero annotation.arXiv preprint arXiv:2601.10094, 2026
Han Wang, Yi Yang, Jingyuan Hu, Minfeng Zhu, and Wei Chen. Self-improving multimodal reasoning with zero annotation.arXiv preprint arXiv:2601.10094, 2026. URL https://arxiv. org/abs/2601.10094
arXiv 2026
-
[46]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. Advances in Neural Information Processing Systems, 37:95095–95169, 2024
2024
-
[47]
Spatial mental modeling from limited views
Qineng Wang, Baiqiao Yin, Pingyue Zhang, et al. Spatial mental modeling from limited views. InarXiv preprint arXiv:2506.21458, 2025. URLhttps://arxiv.org/abs/2506.21458
arXiv 2025
-
[48]
Vision-zero: Scalable vlm self-improvement via strategic gamified self-play
Qinsi Wang, Bo Liu, Tianyi Zhou, Jing Shi, Yueqian Lin, Yiran Chen, Hai Helen Li, Kun Wan, and Wentian Zhao. Vision-zero: Scalable vlm self-improvement via strategic gamified self-play. arXiv preprint arXiv:2509.25541, 2025
arXiv 2025
-
[49]
Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37: 113569–113697, 2024
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, et al. Charxiv: Charting gaps in realistic chart understanding in multimodal llms.Advances in Neural Information Processing Systems, 37: 113569–113697, 2024
2024
-
[50]
Yuxiang Wei, Zhiqing Sun, Emily McMilin, Jonas Gehring, David Zhang, Gabriel Synnaeve, Daniel Fried, Lingming Zhang, and Sida Wang. Toward training superintelligent software agents through self-play swe-rl.arXiv preprint arXiv:2512.18552, 2025
Pith/arXiv arXiv 2025
-
[51]
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-MLLM: Boosting MLLM capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025. URL https://arxiv.org/abs/2505.23747
Pith/arXiv arXiv 2025
-
[52]
Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing
Junfei Wu, Jian Guan, Kaituo Feng, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tieniu Tan. Reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[53]
URLhttps://openreview.net/forum?id=yyWeSAsOhs
-
[54]
Chatting with images for introspective visual thinking.arXiv preprint arXiv:2602.11073, 2026
Junfei Wu, Jian Guan, Qiang Liu, Shu Wu, Liang Wang, Wei Wu, and Tienie Tan. Chatting with images for introspective visual thinking.arXiv preprint arXiv:2602.11073, 2026. URL https://arxiv.org/abs/2602.11073
arXiv 2026
-
[55]
xAI. Grok 4. URLhttps://x.ai/news/grok-4. Model announcement
-
[56]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[58]
URLhttps://arxiv.org/abs/2511.05491
-
[59]
Cambrian-S: Towards spatial supersensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-S: Towards spatial supersensing in video. arXiv preprint arXiv:2511.04670, 2025. URLhttps://arxiv.org/abs/2511.04670. 13
Pith/arXiv arXiv 2025
-
[60]
Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
Sihan Yang, Runsen Xu, Yiman Xie, Sizhe Yang, Mo Li, Jingli Lin, Chenming Zhu, Xiaochen Chen, Haodong Duan, Xiangyu Yue, et al. Mmsi-bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025. URL https://arxiv.org/abs/2505. 23764
Pith/arXiv arXiv 2025
-
[61]
Mindjourney: Test-time scaling with world models for spatial reasoning
Yuncong Yang, Jiageng Liu, Zheyuan Zhang, Siyuan Zhou, Reuben Tan, Jianwei Yang, Yilun Du, and Chuang Gan. Mindjourney: Test-time scaling with world models for spatial reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=L2W4wQsNkY
2025
-
[62]
Ziyi Yang, Weizhou Shen, Chenliang Li, Ruijun Chen, Fanqi Wan, Ming Yan, Xiaojun Quan, and Fei Huang. Spell: Self-play reinforcement learning for evolving long-context language models.arXiv preprint arXiv:2509.23863, 2025
arXiv 2025
-
[63]
Scannet++: A high- fidelity dataset of 3d indoor scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high- fidelity dataset of 3d indoor scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[65]
URLhttps://arxiv.org/abs/2401.10020
-
[66]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186, 2025
2025
-
[67]
Zhenrui Yue, Kartikeya Upasani, Xianjun Yang, Suyu Ge, Shaoliang Nie, Yuning Mao, Zhe Liu, and Dong Wang. Dr. zero: Self-evolving search agents without training data.arXiv preprint arXiv:2601.07055, 2026
arXiv 2026
-
[68]
Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
2022
-
[69]
Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026
Zaibin Zhang, Yuhan Wu, Lianjie Jia, Yifan Wang, Zhongbo Zhang, Yijiang Li, Binghao Ran, Fuxi Zhang, Zhuohan Sun, Zhenfei Yin, et al. Think3d: Thinking with space for spatial reasoning.arXiv preprint arXiv:2601.13029, 2026. URL https://arxiv.org/abs/2601. 13029
arXiv 2026
-
[70]
Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025. URL https://arxiv.org/abs/ 2505.03335
Pith/arXiv arXiv 2025
-
[71]
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Weijian Sun, and Zizhuang Wei. Spacemind: Camera-guided modality fusion for spatial reasoning in vision-language models.arXiv preprint arXiv:2511.23075, 2025. URL https://arxiv.org/ abs/2511.23075
arXiv 2025
-
[72]
Xueliang Zhao, Wei Wu, Jian Guan, Zhuocheng Gong, and Lingpeng Kong. Promptcot 2.0: Scaling prompt synthesis for large language model reasoning.arXiv preprint arXiv:2509.19894, 2025
arXiv 2025
-
[73]
Swift:a scal- able lightweight infrastructure for fine-tuning, 2024
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scal- able lightweight infrastructure for fine-tuning, 2024. URL https://arxiv.org/abs/2408. 05517
2024
-
[74]
In centimeters, what is the longest side of the dishwasher?
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 14 A Implementation Details A.1 Difficulty Feedback Prompt Starting from round t≥2 , the proposer’s...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.