ProbMoE: Differentiable Probabilistic Routing for Mixture-of-Experts
Pith reviewed 2026-06-28 15:56 UTC · model grok-4.3
The pith
ProbMoE makes MoE expert routing differentiable by modeling selection as inference over subset distributions and using exact marginal probabilities for gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
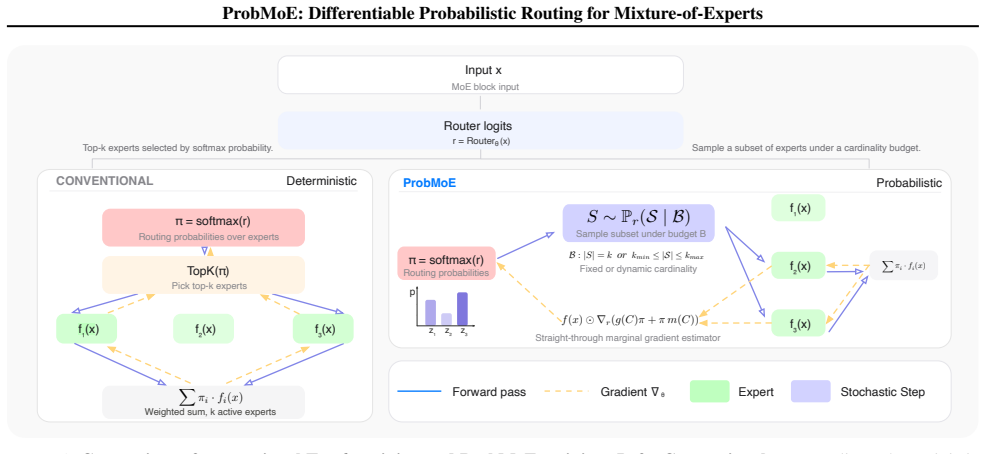
ProbMoE models expert selection as a distribution over cardinality-constrained expert subsets and formulates routing as probabilistic inference in this discrete subset space. ProbMoE Exact-k routing samples k-expert subsets in the forward pass, and the backward pass uses gradients through each expert's exact marginal probability as a tractable surrogate for the true gradient. ProbMoE naturally generalizes to a dynamic-k routing setting, where both training and inference constrain the routing cardinality to the same predefined range, allowing adaptive expert allocation per token. Across benchmarks and model backbones, ProbMoE Exact-k achieves strong performance compared to competitive baselin
What carries the argument
The exact marginal probability of each expert computed from the distribution over cardinality-constrained subsets, used as the surrogate gradient signal in the backward pass.
If this is right
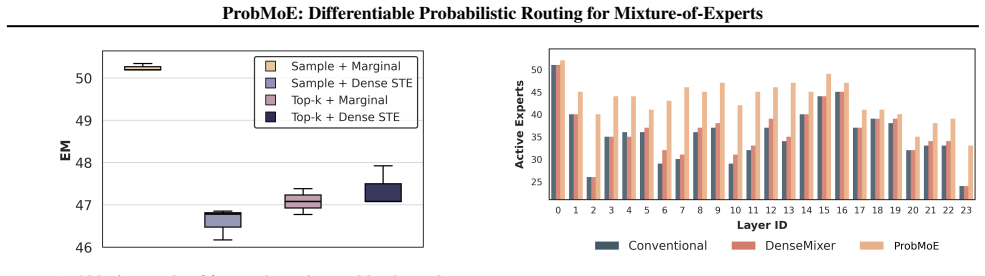
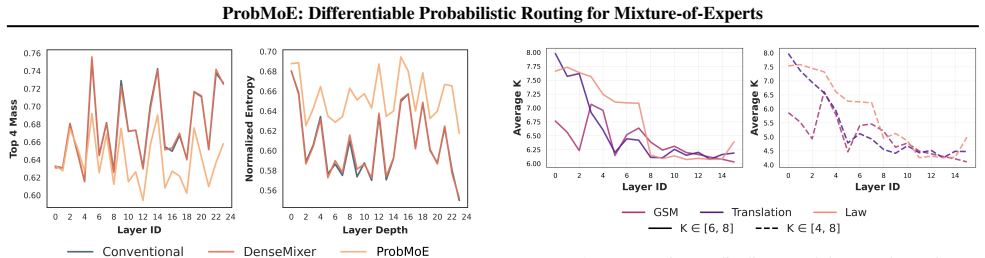
- Exact-k routing matches or exceeds baseline accuracy while raising expert utilization and routing diversity.
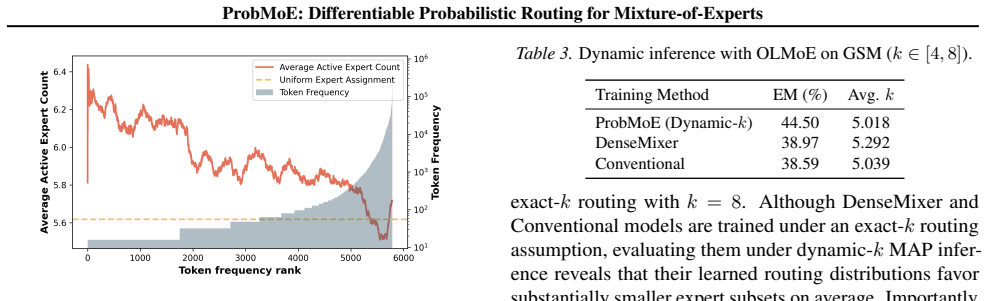
- Dynamic-k routing matches baseline performance yet activates fewer experts on average by adapting cardinality within a fixed range.
- The same probabilistic formulation applies across multiple model backbones and standard MoE benchmarks.
- Both variants keep the cardinality constraint identical at training and inference time.
Where Pith is reading between the lines
- The marginal-probability surrogate may reduce reliance on auxiliary load-balancing losses that are common in current MoE training.
- The subset-distribution view could be applied to other discrete gating or selection mechanisms inside neural networks.
- Measuring gradient variance directly between the marginal surrogate and alternative estimators would quantify how much the method stabilizes training.
- Dynamic cardinality might yield additional efficiency gains when input complexity varies widely across a dataset.
Load-bearing premise
That routing the gradient through each expert's exact marginal probability rather than through the sampled subset gives a low-variance unbiased surrogate for the true discrete selection gradient.
What would settle it
An experiment that replaces the marginal-probability gradient with a direct gradient through the sampled subset (or with REINFORCE) on the same models and benchmarks and measures whether convergence, final performance, or expert balance degrades.
Figures
read the original abstract
Mixture-of-Experts (MoE) models scale by activating only a small subset of experts per token. However, training such models remains challenging because top-$k$ routing is discrete and non-differentiable, requiring gradient estimators for expert selection whose design remains a central open problem. We introduce ProbMoE, a probabilistic routing framework that models expert selection as a distribution over cardinality-constrained expert subsets and formulates routing as probabilistic inference in this discrete subset space. We first propose ProbMoE Exact-$k$ routing, which samples $k$-expert subsets in the forward pass, and the backward pass uses gradients through each expert's exact marginal probability as a tractable surrogate for the true gradient. ProbMoE naturally generalizes to a dynamic-$k$ routing setting, where both training and inference constrain the routing cardinality to the same predefined range, allowing adaptive expert allocation per token. Across benchmarks and model backbones, ProbMoE Exact-$k$ achieves strong performance compared to competitive baselines, with improved expert utilization and routing diversity; ProbMoE Dynamic-$k$ achieves comparable performance with fewer activated experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProbMoE, a probabilistic routing framework for Mixture-of-Experts that treats expert selection as inference over cardinality-constrained subsets. Exact-k routing samples k-expert subsets in the forward pass and routes gradients through each expert's exact marginal probability p_i as a surrogate for the discrete selection gradient; Dynamic-k extends this to allow per-token k within a fixed range. The manuscript claims that both variants achieve strong benchmark performance relative to baselines, with improved expert utilization and routing diversity.
Significance. If the marginal-probability surrogate yields stable, low-bias training dynamics, the approach would supply a more principled and differentiable alternative to existing top-k routing estimators, potentially improving both performance and expert load balancing in large-scale MoE models.
major comments (2)
- [Abstract / §3 (method description)] The central technical claim—that routing the gradient through each expert’s exact marginal probability p_i supplies a tractable and sufficiently accurate surrogate for the true gradient of E[loss | subset]—is load-bearing for all reported results. No derivation or bias bound is supplied showing that the per-expert marginal gradients equal the gradient of the cardinality-constrained expectation; the negative dependence among indicators induced by the exact-k constraint is not addressed.
- [Abstract] The abstract asserts “strong performance … with improved expert utilization” yet supplies neither quantitative tables, ablation results, nor error bars. Without these data the empirical support for the surrogate’s effectiveness cannot be evaluated.
minor comments (1)
- [§3] Notation for the marginal probability p_i and the sampling distribution over subsets should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. Below we provide point-by-point responses to the major comments. We propose revisions where they strengthen the presentation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract / §3 (method description)] The central technical claim—that routing the gradient through each expert’s exact marginal probability p_i supplies a tractable and sufficiently accurate surrogate for the true gradient of E[loss | subset]—is load-bearing for all reported results. No derivation or bias bound is supplied showing that the per-expert marginal gradients equal the gradient of the cardinality-constrained expectation; the negative dependence among indicators induced by the exact-k constraint is not addressed.
Authors: We agree that an explicit derivation of the marginal-probability surrogate and its relationship to the cardinality-constrained expectation would improve clarity. In the revised manuscript we will add a dedicated subsection in §3 that (i) derives the exact marginal probabilities under the cardinality constraint, (ii) shows that the per-expert gradient through p_i is the expectation of the indicator gradient conditional on the remaining experts, and (iii) discusses the effect of negative dependence among the indicators. A formal bias bound is not currently derived in the paper; we will include a short discussion of the approximation error together with empirical evidence that the surrogate remains stable across the reported scales. revision: yes
-
Referee: [Abstract] The abstract asserts “strong performance … with improved expert utilization” yet supplies neither quantitative tables, ablation results, nor error bars. Without these data the empirical support for the surrogate’s effectiveness cannot be evaluated.
Authors: Abstracts are intentionally concise and do not contain tables or error bars; the quantitative support for the performance claims, including benchmark tables, ablation studies on Exact-k versus Dynamic-k, expert utilization histograms, routing diversity metrics, and results with standard error bars from multiple random seeds, is provided in §4 and the associated figures. We will verify that every claim in the abstract is directly traceable to a specific result in the experimental section and, if space permits, add one or two representative numbers to the abstract for immediate context. revision: partial
Circularity Check
No circularity: direct probabilistic construction with empirical validation
full rationale
The paper presents ProbMoE as a probabilistic model over cardinality-constrained subsets, with forward sampling of k-subsets and backward use of per-expert marginal probabilities as an explicit surrogate. No equations reduce the surrogate gradient to the true gradient by algebraic identity, no parameters are fitted on a data subset and then relabeled as predictions, and no self-citations are used to justify uniqueness or load-bearing premises. Performance results are reported as empirical outcomes on benchmarks rather than derived from the method's own inputs. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aghdam, M. A., Jin, H., and Wu, Y . Da-moe: Towards dynamic expert allocation for mixture-of-experts models. CoRR, abs/2409.06669,
-
[2]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y ., L´eonard, N., and Courville, A. Estimating or propagating gradients through stochastic neurons for con- ditional computation.arXiv preprint arXiv:1308.3432,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Jang, E., Gu, S., and Poole, B
doi: 10.18653/v1/2024.acl-long.696. Jang, E., Gu, S., and Poole, B. Categorical reparameteriza- tion with gumbel-softmax. InInternational Conference on Learning Representations,
-
[5]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Jin, C., Peng, H., Xiang, M., Zhang, Q., Yuan, X., Hasan, A., Dibua, O., Gong, Y ., Kang, Y ., and Metaxas, D. N. Sparsity-controllable dynamic top-p moe for large founda- tion model pre-training.arXiv preprint arXiv:2512.13996, 2025a. Jin, P., Zhu, B., Yuan, L., and YAN, S. Moe++: Accelerat- ing mixture-of-experts methods with zero-computation experts. I...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Sparse backpropagation for moe training
Liu, L., Gao, J., and Chen, W. Sparse backpropagation for moe training. InWorkshop on Advancing Neural Network Training: Computational Efficiency, Scalability, and Re- source Optimization (WANT@NeurIPS 2023),
2023
-
[8]
Probabilistically rewired message-passing neural networks
Qian, C., Manolache, A., Ahmed, K., Zeng, Z., Van den Broeck, G., Niepert, M., and Morris, C. Probabilistically rewired message-passing neural networks. InInterna- tional Conference on Learning Representations, volume 2024, pp. 32051–32076,
2024
-
[9]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URL https://qwenlm.github.io/blog/qwen1. 5/. Wang, Z., Chen, D., Dai, D., Xu, R., Li, Z., and Wu, Y . Let the expert stick to his last: Expert-specialized fine-tuning for sparse architectural large language mod- els. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processi...
2024
-
[11]
Wang, Z., Zhu, J., and Chen, J
doi: 10.18653/v1/2024.emnlp-main.46. Wang, Z., Zhu, J., and Chen, J. Remoe: Fully differentiable mixture-of-experts with reLU routing. InThe Thirteenth International Conference on Learning Representations,
-
[12]
AdaMoE: Token-adaptive routing with null experts for mixture-of-experts language models
Zeng, Z., Miao, Y ., Gao, H., Zhang, H., and Deng, Z. AdaMoE: Token-adaptive routing with null experts for mixture-of-experts language models. In Al-Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Findings of the Association for Computational Linguistics: EMNLP 2024, pp. 6223–6235, Miami, Florida, USA, November
2024
-
[13]
doi: 10.18653/v1/2024.findings-emnlp.361
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.361. Zuo, S., Liu, X., Jiao, J., Kim, Y . J., Hassan, H., Zhang, R., Gao, J., and Zhao, T. Taming sparsely activated transformer with stochastic experts. InInternational Con- ference on Learning Representations,
-
[14]
Methodological and Implementation Details A.1
12 ProbMoE: Differentiable Probabilistic Routing for Mixture-of-Experts A. Methodological and Implementation Details A.1. DenseMixer: Dense Training-Time Routing DenseMixer addresses the non-differentiability of top-k routing by modifying gradient propagation during training (Yao et al., 2026). Rather than modeling expert subset selection directly, it int...
2026
-
[15]
DenseMixer requires a dense forward pass through all experts for every token in order to compute its straight-through gradient, dramatically increasing forward-pass FLOPs
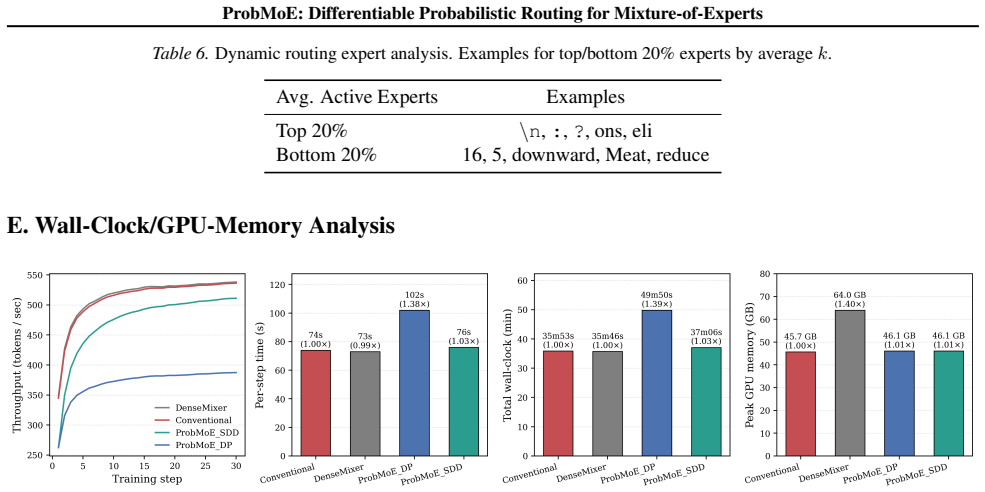
In terms of peak GPU memory, ProbMoE DP and ProbMoE SDD closely match Conventional fine-tuning, whereas DenseMixer requires substantially more memory than any other method. DenseMixer requires a dense forward pass through all experts for every token in order to compute its straight-through gradient, dramatically increasing forward-pass FLOPs. In contrast,...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.