From Rashomon Theory to PRAXIS: Efficient Decision Tree Rashomon Sets
Pith reviewed 2026-06-28 23:12 UTC · model grok-4.3
The pith
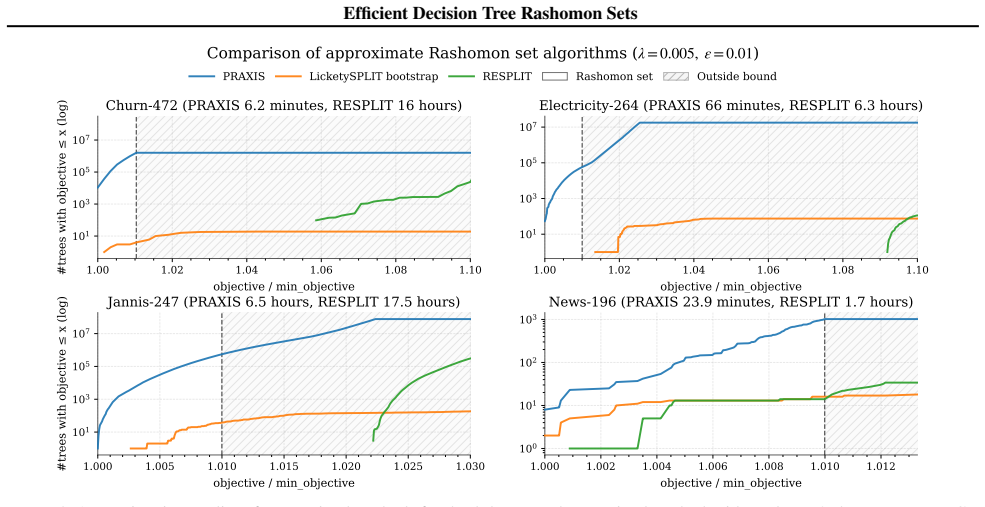
PRAXIS approximates the full Rashomon set of sparse decision trees using orders of magnitude less time and memory.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
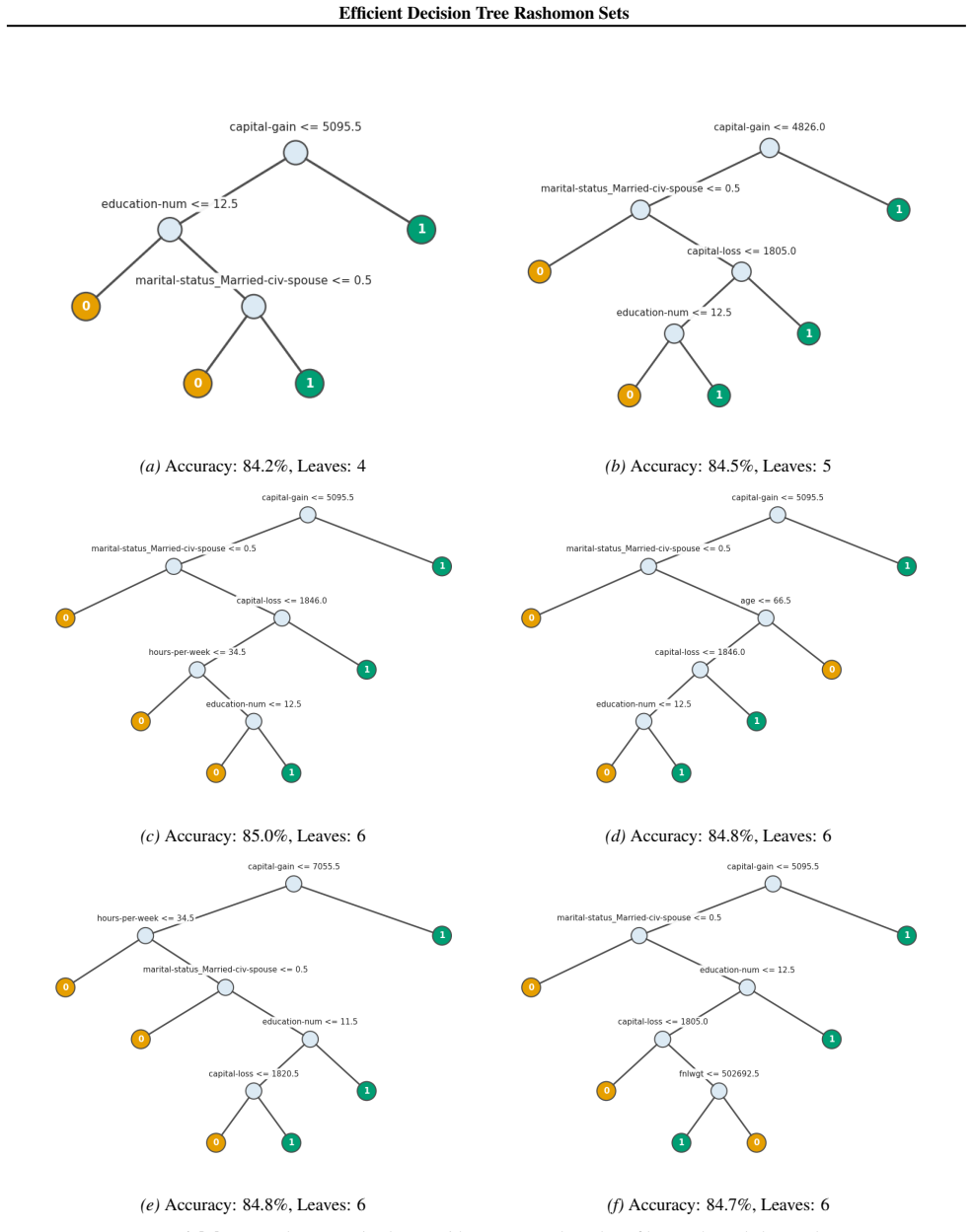
PRAXIS is an algorithm to approximate the Rashomon set of sparse decision trees that achieves orders of magnitude improvement in runtime and memory usage while regularly recovering almost all of the models present in the full Rashomon set, thereby enabling scalable modeling of these sets on real-world datasets.
What carries the argument
The PRAXIS algorithm for approximating Rashomon sets of sparse decision trees by efficient search that avoids exhaustive enumeration.
If this is right
- Researchers can now compute Rashomon sets for larger, real-world datasets instead of only small problems.
- Practitioners gain a practical way to quantify model uncertainty and diversity for a fixed objective.
- Domain knowledge can be incorporated into decisions by selecting among many near-optimal trees rather than one.
- Downstream tasks such as robust prediction or preference-based model choice become feasible at scale.
Where Pith is reading between the lines
- The method may extend naturally to other interpretable model classes once similar search structures are identified.
- Widespread adoption could shift standard practice from single-model selection to set-based analysis in high-stakes domains.
- It opens the possibility of new tools that let users interactively explore and filter large Rashomon sets.
Load-bearing premise
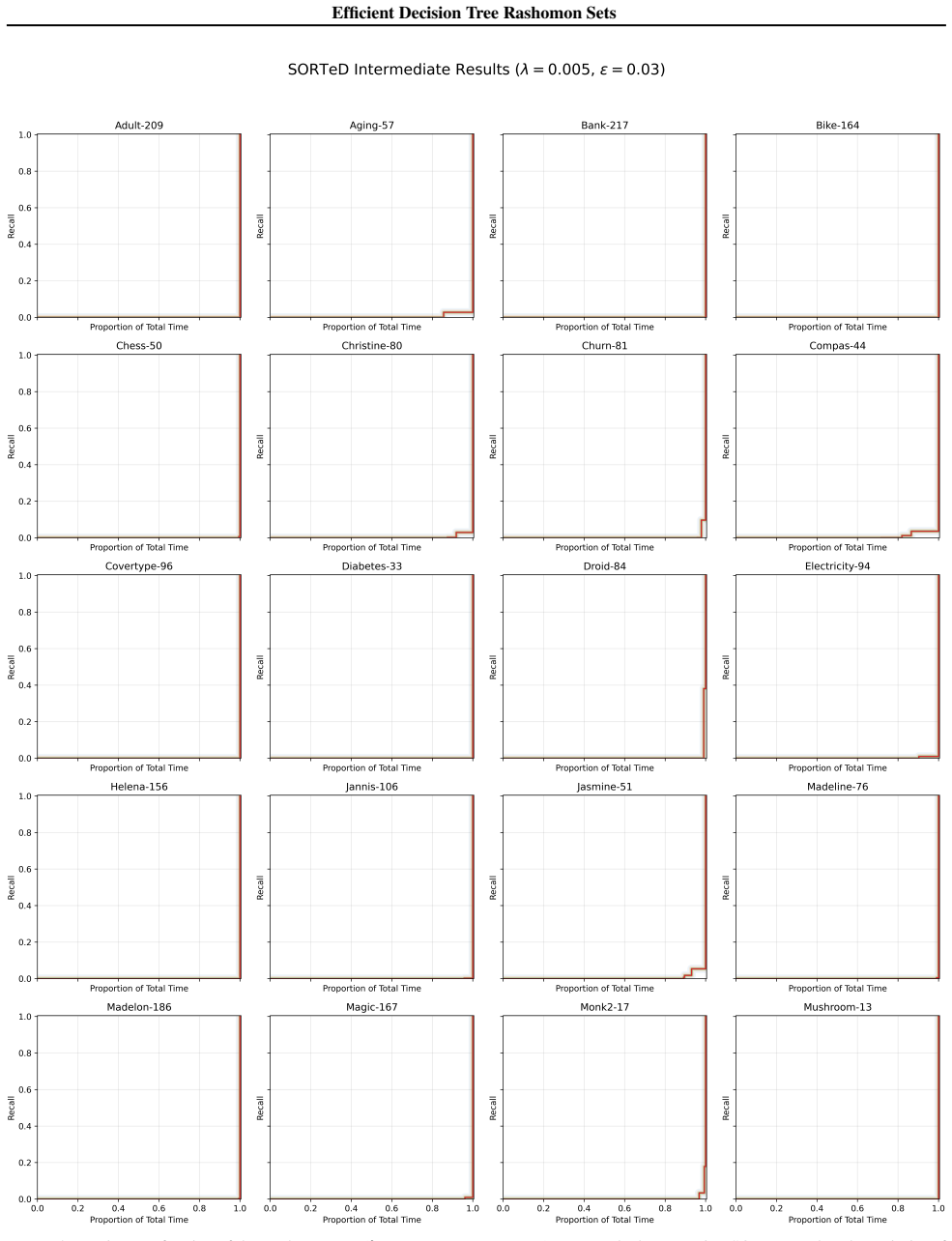
The approximation quality seen on the validation datasets will hold for other real-world data and the recovered models will retain the diversity and uncertainty properties of the exact set.
What would settle it
A new dataset on which PRAXIS recovers substantially fewer than almost all models from the exact Rashomon set or where the approximated set loses key diversity properties.
Figures

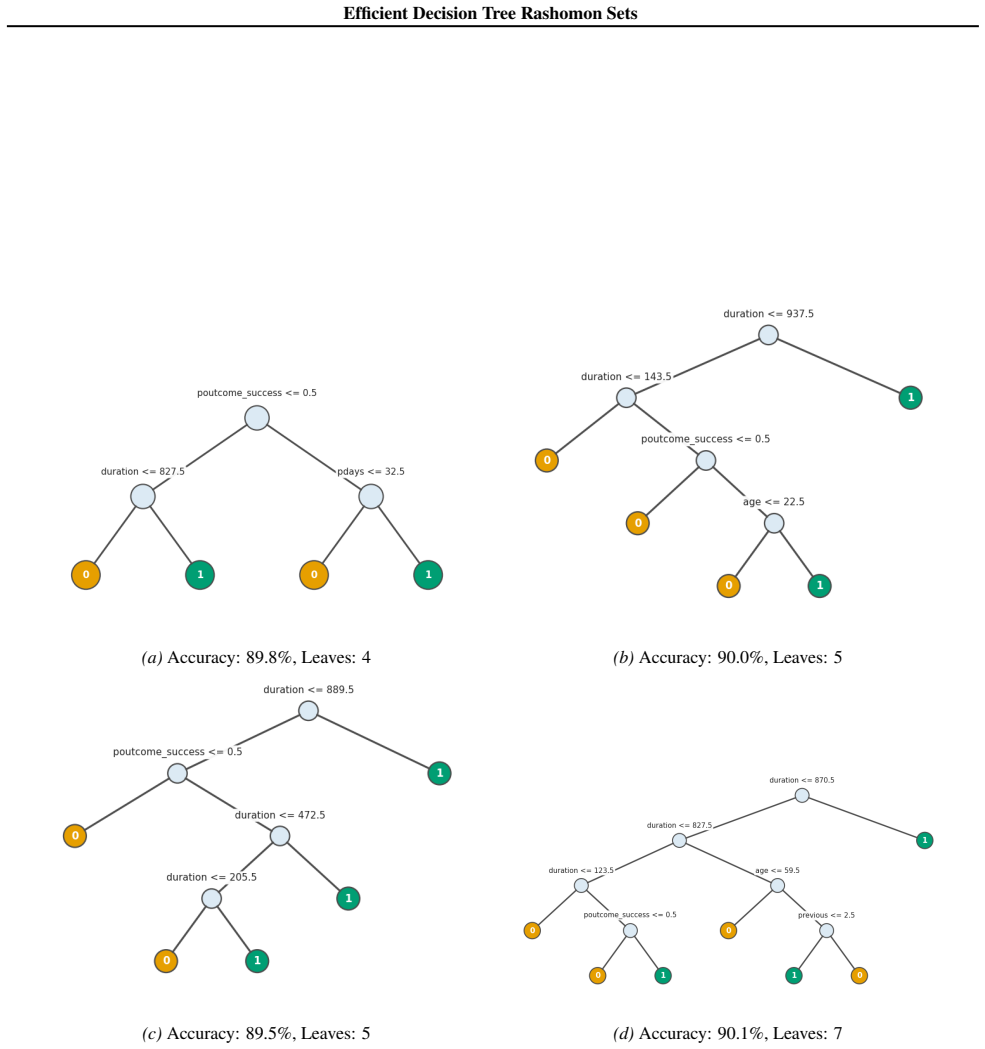
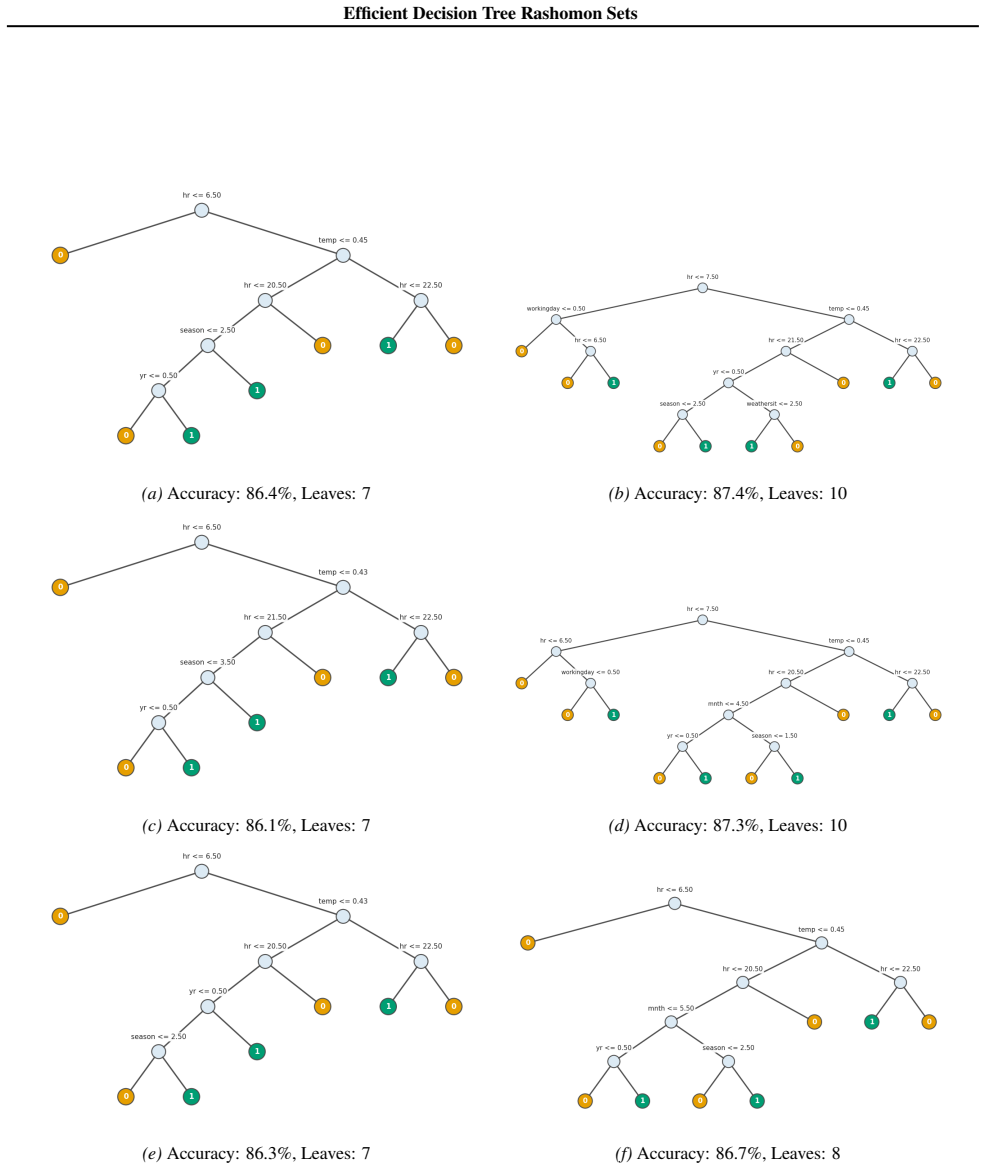
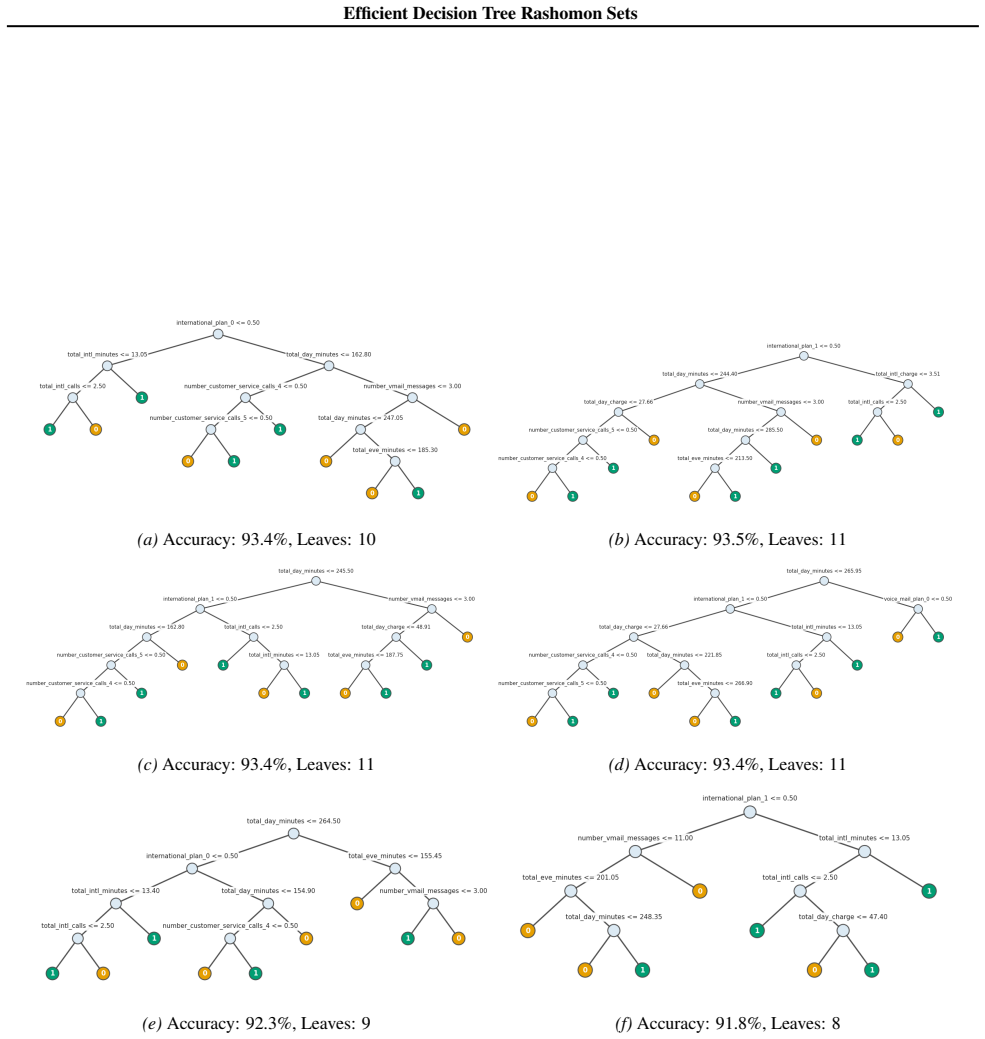
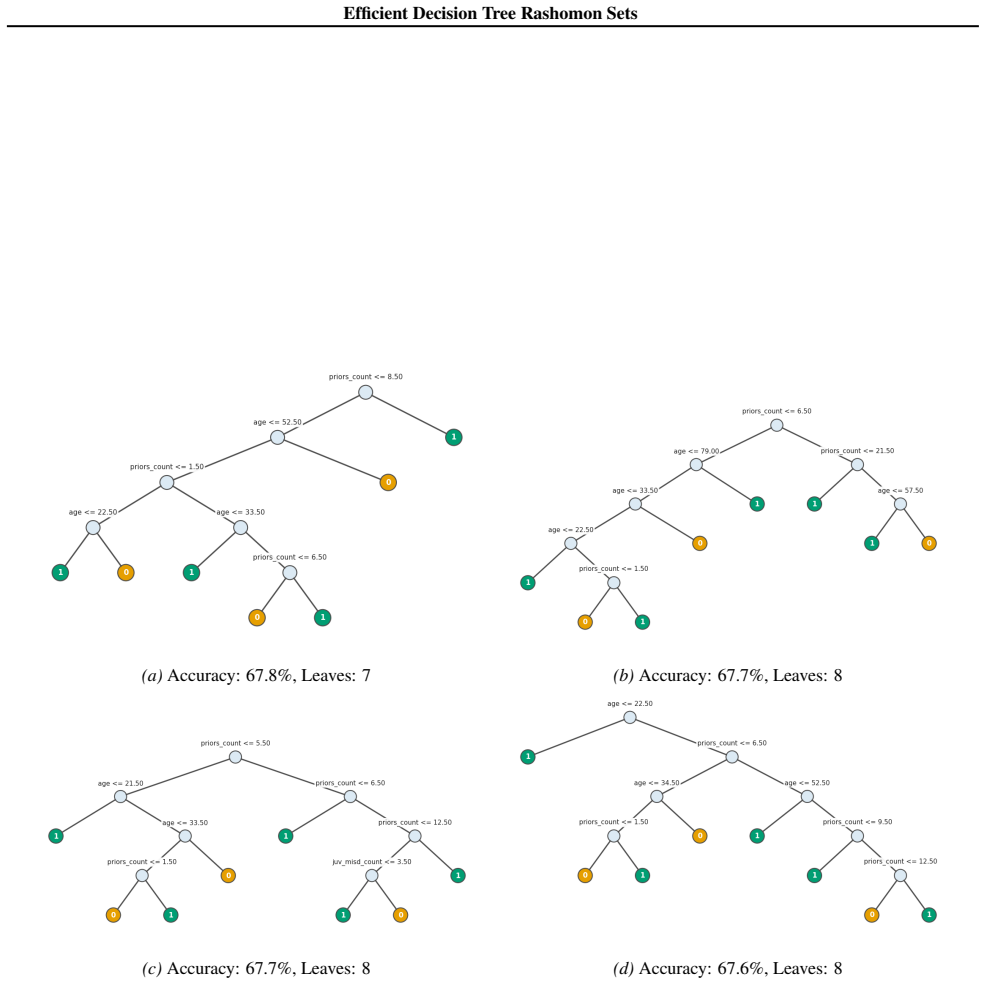
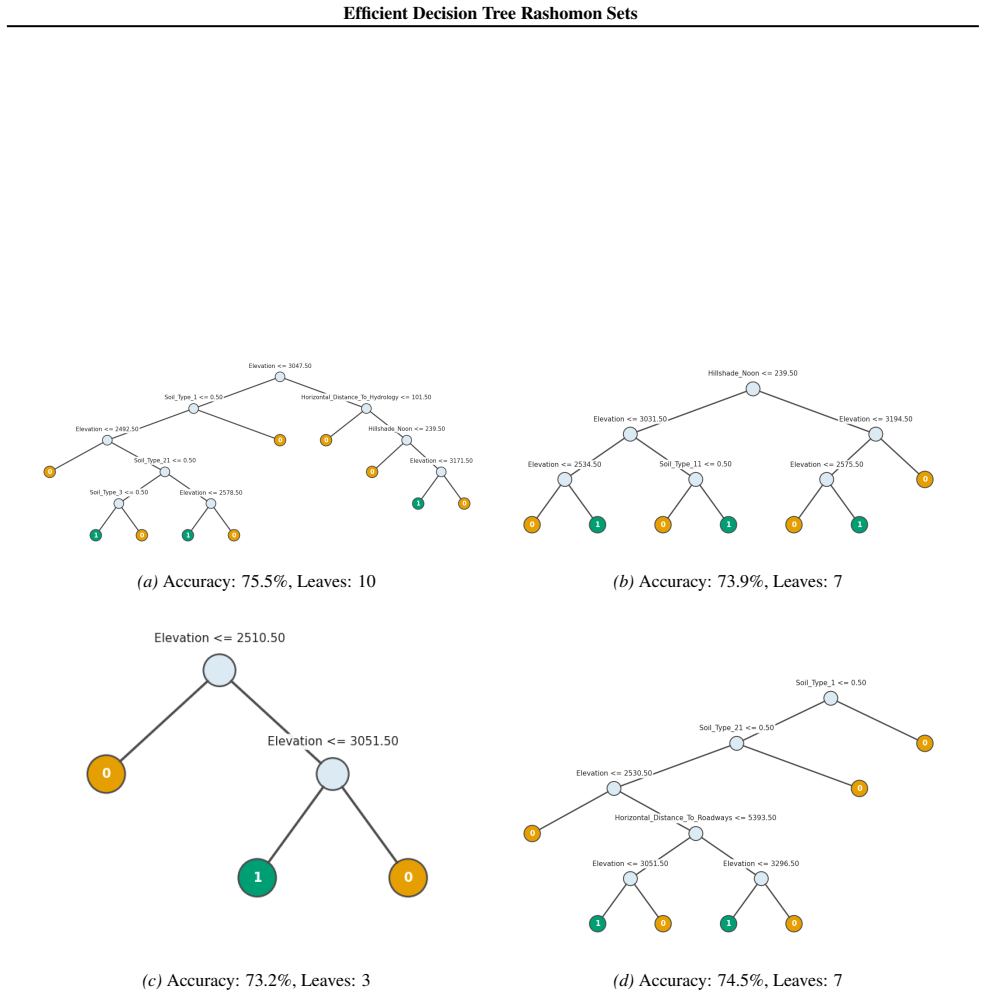
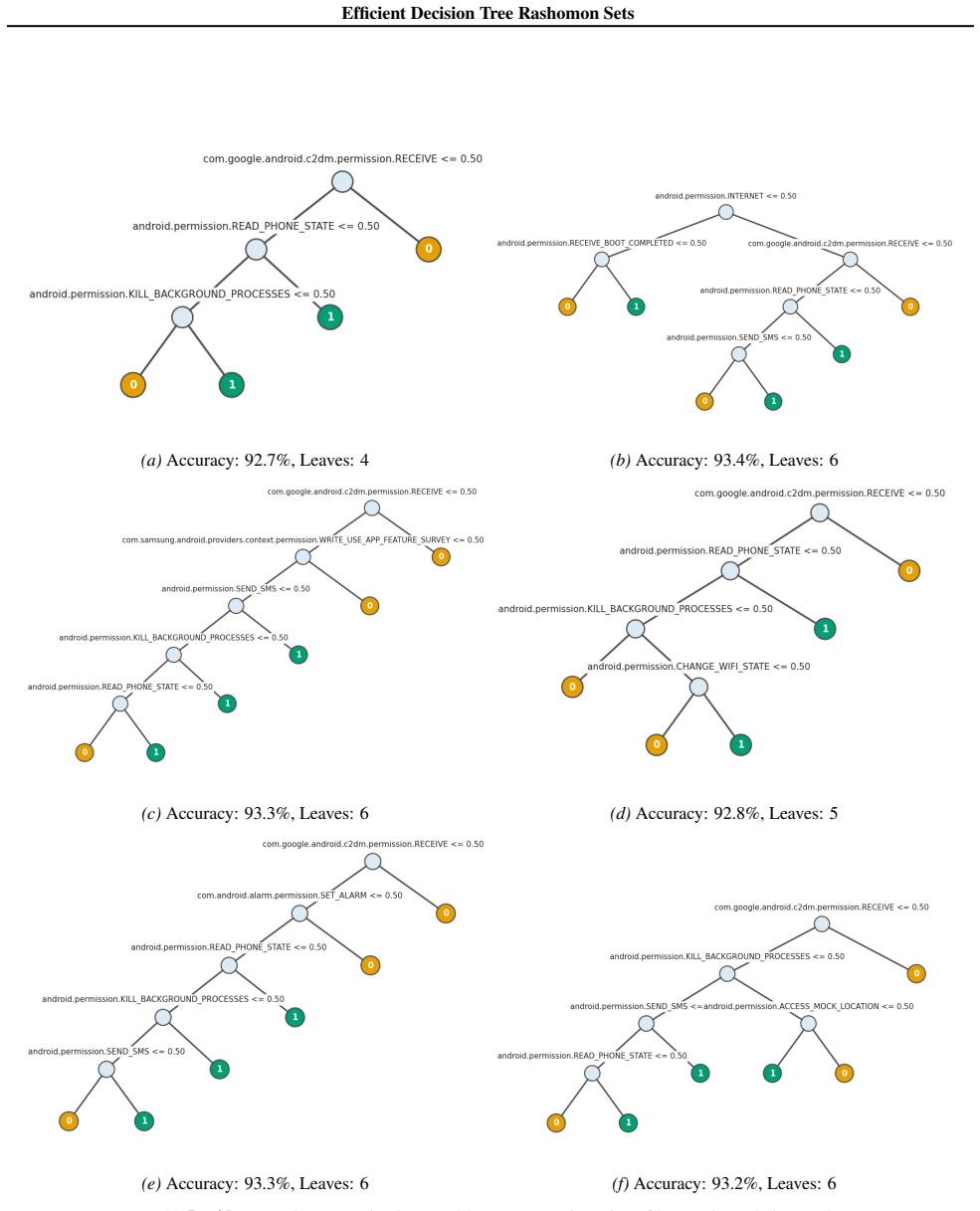
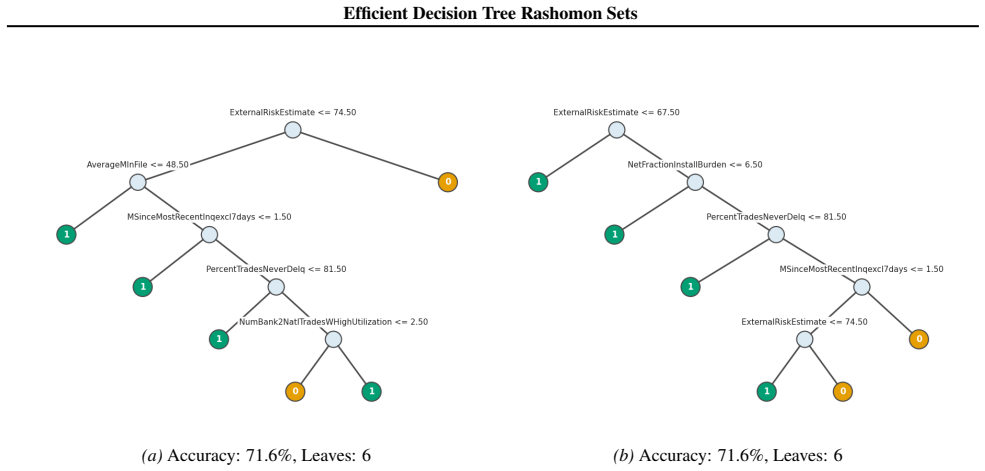
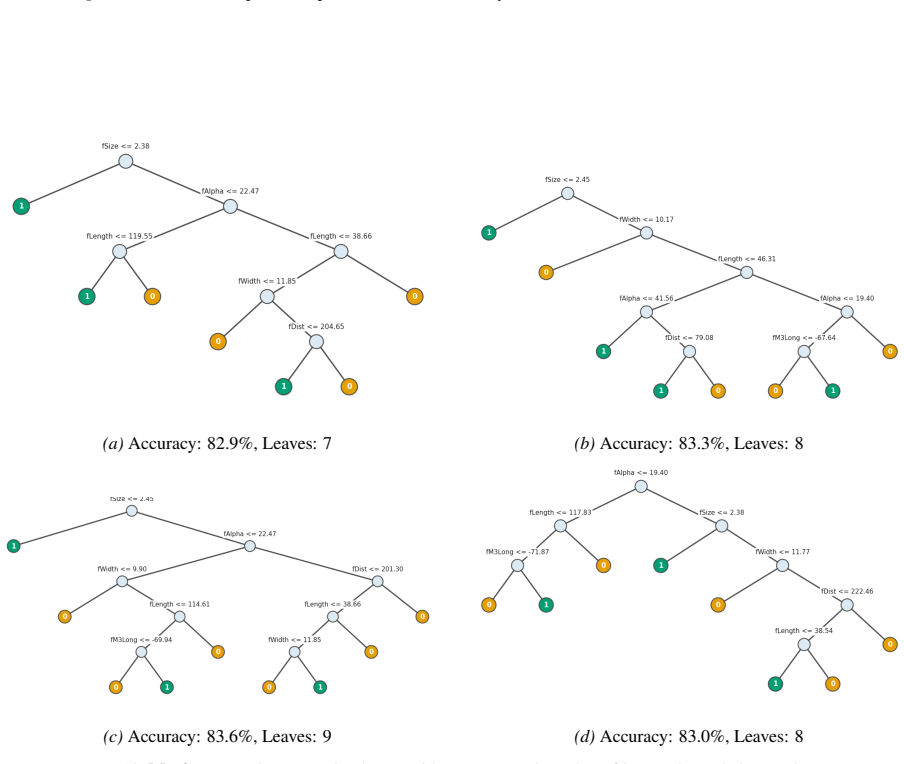
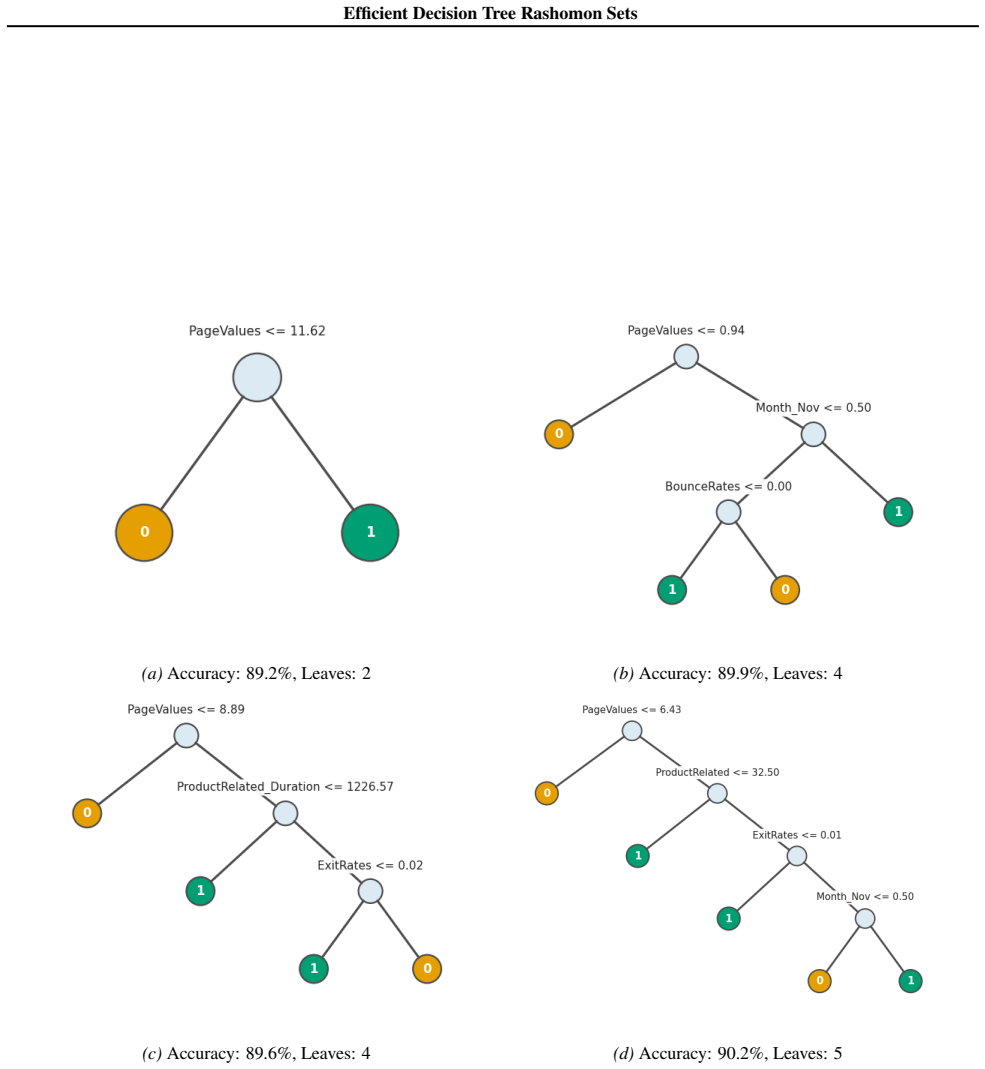
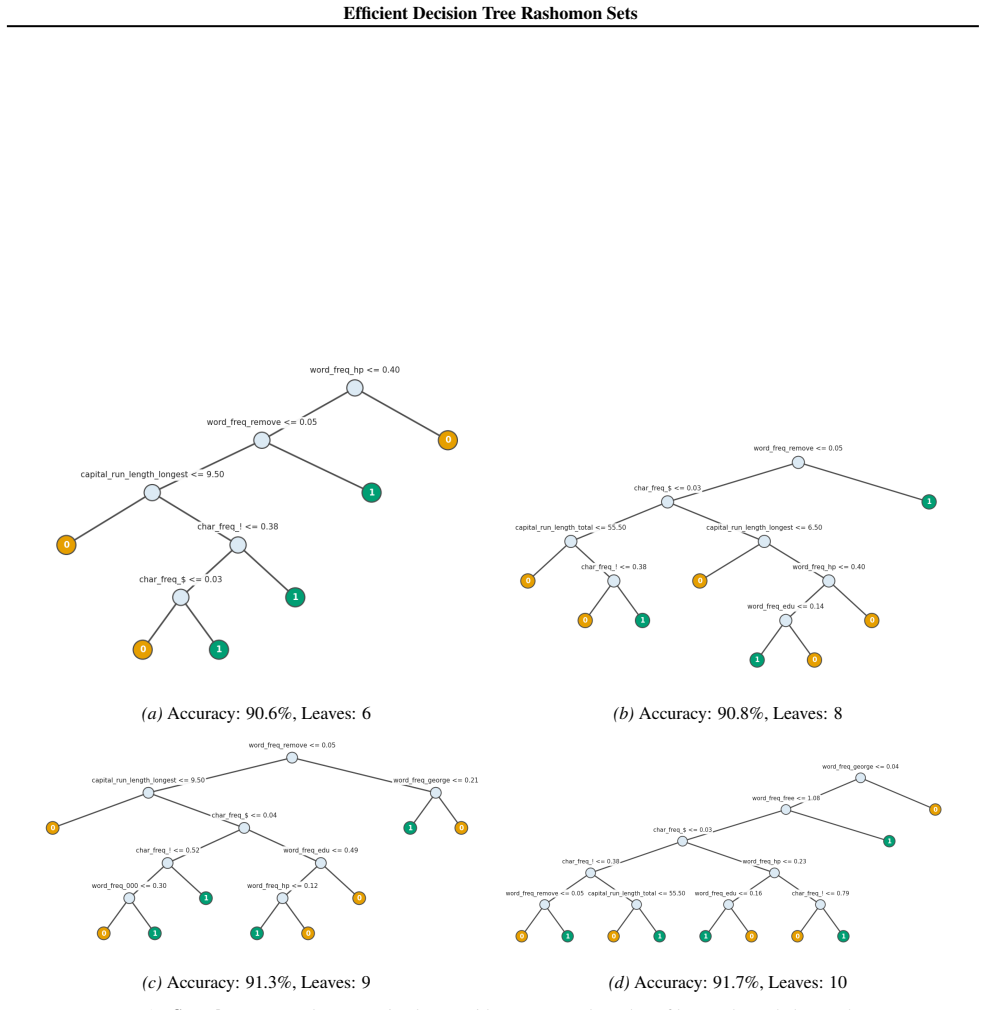
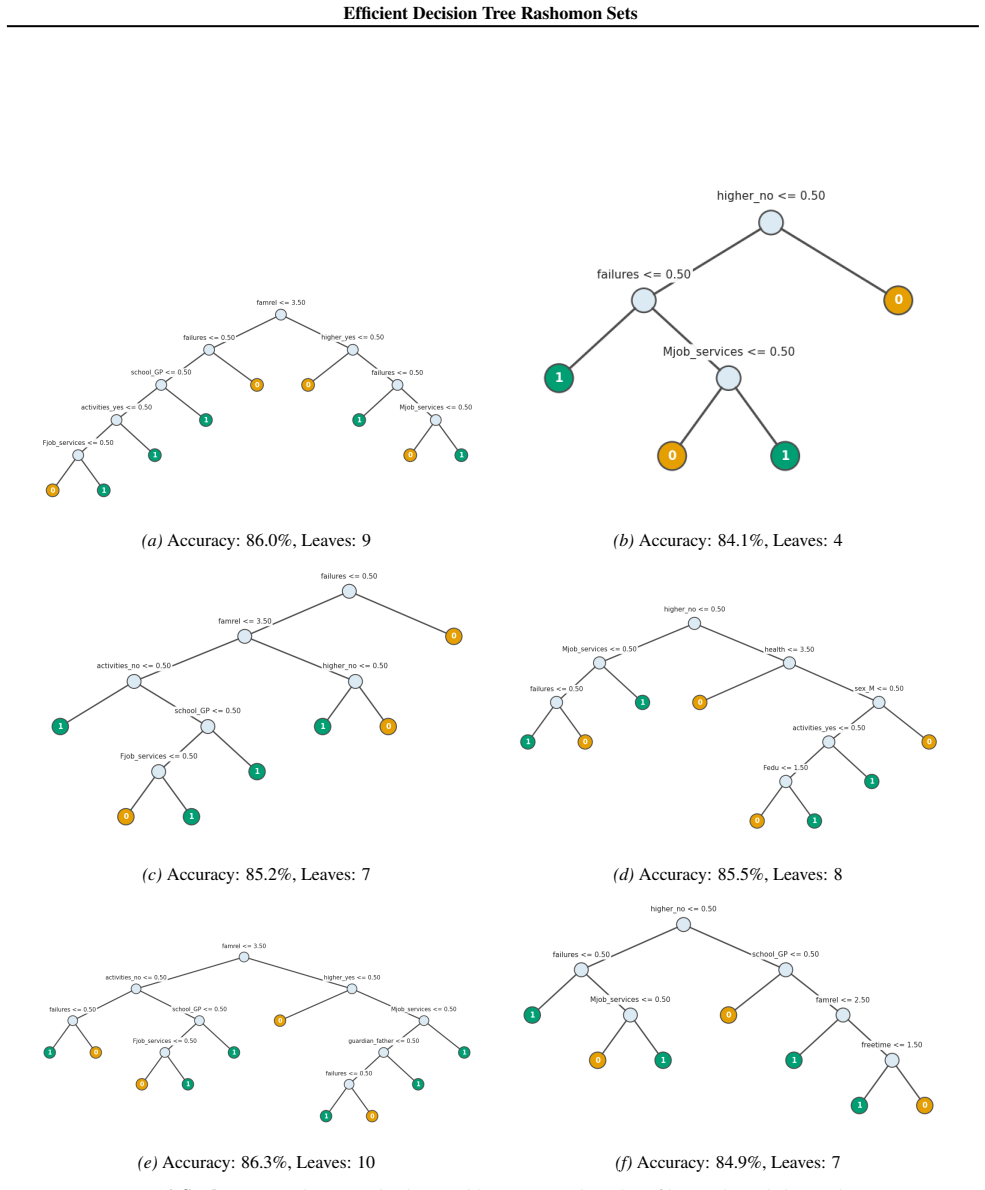
read the original abstract
Standard machine learning pipelines often admit many near-optimal models. These "Rashomon sets" pose a range of challenges and opportunities for uncertainty-aware, robust decision making. They allow users to incorporate domain knowledge and preferences that would otherwise be difficult to specify directly in an objective, and they quantify diversity among valid models for a given training dataset and objective function. However, computation of Rashomon sets, even for simple, interpretable model classes such as sparse decision trees, continues to require immense memory and runtime resources. We present PRAXIS, an algorithm to approximate this Rashomon set with orders of magnitude improvement in runtime and memory usage. We validate that PRAXIS regularly recovers almost all of the full Rashomon set. PRAXIS allows researchers and practitioners to scalably model the Rashomon set for real-world datasets. Code for PRAXIS is available at https://github.com/zakk-h/PRAXIS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRAXIS, an algorithm for efficiently approximating Rashomon sets of sparse decision trees. It claims orders-of-magnitude improvements in runtime and memory over exact enumeration methods while regularly recovering nearly the entire Rashomon set on validation datasets, thereby enabling scalable use of Rashomon sets for real-world data.
Significance. If the approximation quality and preservation of model diversity hold, the work would meaningfully advance practical access to Rashomon sets beyond toy scales, supporting uncertainty-aware and preference-incorporating decision making with interpretable models. The public release of code is a clear strength that aids reproducibility.
major comments (1)
- The abstract and validation claims rest on recovery rates and efficiency gains, yet no explicit definition or section details the precise recovery metric (e.g., exact set overlap, model equivalence under some tolerance) or the diversity/uncertainty preservation tests; without this, it is difficult to assess whether the reported 'almost all' recovery supports the downstream claims about modeling the full Rashomon set.
minor comments (2)
- Notation for the Rashomon set and the approximation parameters should be introduced with a dedicated preliminary section or table for clarity.
- The experimental section would benefit from explicit reporting of dataset characteristics (size, feature types) and hardware used for the runtime comparisons.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity on the recovery metric. We will revise the manuscript to explicitly define this metric and related evaluation details, strengthening the presentation of our validation results.
read point-by-point responses
-
Referee: The abstract and validation claims rest on recovery rates and efficiency gains, yet no explicit definition or section details the precise recovery metric (e.g., exact set overlap, model equivalence under some tolerance) or the diversity/uncertainty preservation tests; without this, it is difficult to assess whether the reported 'almost all' recovery supports the downstream claims about modeling the full Rashomon set.
Authors: We agree that an explicit definition is necessary. In the revised manuscript we will add a new subsection (tentatively 5.2) titled 'Recovery Metric and Evaluation Protocol' that defines recovery rate as the fraction of models in the exact Rashomon set (enumerated via the baseline method) that appear identically in the PRAXIS output, using exact structural equivalence of the decision trees (no tolerance). We will also report the complementary false-positive rate (models returned by PRAXIS but absent from the exact set). Regarding diversity and uncertainty preservation, the current experiments already compare the range of leaf predictions and the coverage of the Pareto front of accuracy-complexity trade-offs between the exact and approximated sets; we will make these comparisons explicit and add a short paragraph explaining why exact-set overlap on the tested data implies that downstream uses (preference incorporation, uncertainty quantification) remain supported. These additions directly address the concern that 'almost all' recovery may not suffice for the modeling claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents PRAXIS as a new algorithmic approximation method for Rashomon sets of decision trees, with claims of runtime/memory gains and empirical recovery rates validated on datasets. No derivation chain, equations, or self-citations appear in the provided abstract or context that reduce a claimed result to a fitted input or self-referential definition by construction. The central contribution is an empirical algorithm whose performance is assessed externally rather than defined tautologically from its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1038/ncomms5308. URL http://dx. doi.org/10.1038/ncomms5308. Bao, M., Zhou, A., Zottola, A. S., Brubach, B., Desmarais, S., Horowitz, S. A., Lum, K., and Venkatasubramanian, S. It’s compaslicated: The messy relationship between rai datasets and algorithmic fairness benchmarks. In Proceedings of the Thirty-Fifth Conference on Neural In- formation Pr...
-
[2]
DOI: https://doi.org/10.24432/C50K5N. Blanc, G., Lange, J., Pabbaraju, C., Sullivan, C., Tan, L.- Y ., and Tiwari, M. Harnessing the power of choices in decision tree learning. InAdvances in Neural Information Processing Systems, volume 36, 2024. Bock, R. MAGIC Gamma Telescope. UCI Machine Learning Repository, 2004. DOI: https://doi.org/10.24432/C52C8B. B...
-
[3]
TabArena: A Living Benchmark for Machine Learning on Tabular Data
doi: 10.15585/mmwr.mm6643a2. URL https: //doi.org/10.15585/mmwr.mm6643a2. Cattral, R. and Oppacher, F. Poker Hand. UCI Machine Learning Repository, 2002. DOI: https://doi.org/10.24432/C5KW38. Chaouki, A., Read, J., and Bifet, A. Branches: Efficiently seeking optimal sparse decision trees via ao. InForty- second International Conference on Machine Learning...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15585/mmwr.mm6643a2 2002
-
[4]
10 Beyond Rational Illusion: Behaviorally Realistic Strategic Classification Horowitz, G
URL https://community.fico.com/s/ explainable-machine-learning-challenge . FICO Explainable Machine Learning Challenge. Guyon, I., Sun-Hosoya, L., Boull ´e, M., Escalante, H. J., Escalera, S., Liu, Z., Jajetic, D., Ray, B., Saeed, M., Sebag, M., Statnikov, A., Tu, W., and Viegas, E. Analysis of the AutoML challenge series 2015-2018. InAutoML, Springer ser...
-
[5]
Malani, P
PMLR, 2020. Malani, P. N., Kullgren, J., and Solway, E. National poll on healthy aging (NPHA), United States, april 2017, 2019. URL https://doi.org/10.3886/ ICPSR37305.v1. Available from the Inter-university Consortium for Political and Social Research and UCI Machine Learning Repository. Marcoulides, G. A.Discovering Knowledge in Data: An Introduction to...
2020
-
[6]
Mazumder, R., Meng, X., and Wang, H
Available in UCI Machine Learning Repository. Mazumder, R., Meng, X., and Wang, H. Quant-BnB: A scal- able branch-and-bound method for optimal decision trees with continuous features. InInternational Conference on Machine Learning, volume 162, pp. 15255–15277. PMLR, 17–23 Jul 2022. McTavish, H., Zhong, C., Achermann, R., Karimalis, I., Chen, J., Rudin, C....
-
[7]
org/CorpusID:261516162
URL https://api.semanticscholar. org/CorpusID:261516162. Sullivan, C., Tiwari, M., and Thrun, S. Maptree: Beating “optimal” decision trees with bayesian decision trees. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 38, pp. 9019–9026, 2024. Thrun, S. The MONK’s problems-a performance comparison of different learning algorithms,...
2024
-
[8]
DOI: https://doi.org/10.24432/C5V312. Wnek, J. MONK’s Problems. UCI Ma- chine Learning Repository, 1993. DOI: https://doi.org/10.24432/C5R30R. Xin, R., Zhong, C., Chen, Z., Takagi, T., Seltzer, M., and Rudin, C. Exploring the whole Rashomon set of sparse decision trees. InAdvances in Neural Information Pro- cessing Systems, volume 35, pp. 14071–14084, 202...
-
[9]
A single copy of the original dataset
-
[10]
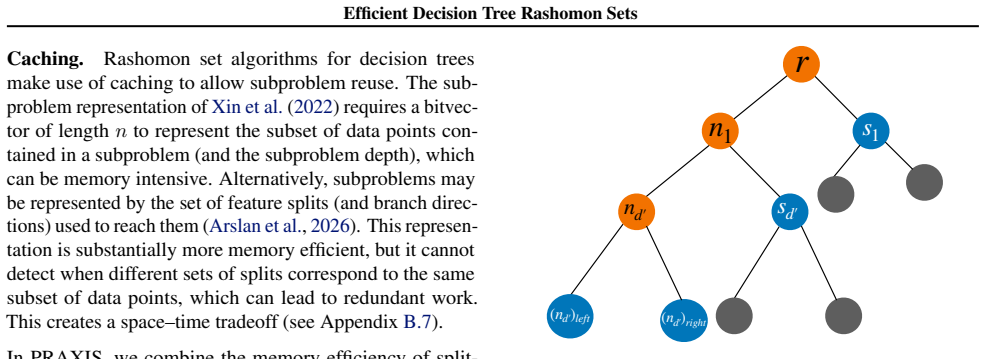
the dependency graph structure, which can be constructed to include only nodes with a constant amount of storage space, where there are no more nodes in the dependency graph than there are nodes (split nodes or leaves) across the whole Rashomon set
-
[11]
Since the number of leaves and internal nodes is bounded by twice the number of leaves, we know object (2) isO(P t∈R |t|)
Row indices for currently active subproblems in the dependency graph. Since the number of leaves and internal nodes is bounded by twice the number of leaves, we know object (2) isO(P t∈R |t|). We know object (1) is O(nk), so combining them we have proven our claimed memory complexity. (Note that (3) is also withinO(nk)so does not affect the complexity). ....
-
[12]
the returned AND/OR graphGcontains (represents) the proxy treef px, (Gis nonempty)
-
[13]
In particular, the root node satisfies G.min objective≤P(D, d)
the minimum objective stored at the root OR-node satisfies G.min objective≤P(D, d). In particular, the root node satisfies G.min objective≤P(D, d). Proof.We argue by induction on the depthd. Base case (d= 0).Thenf px is a leaf predicting some labelb∈ {0,1}, (denote this label wlog asb ′) hence P(D,0) =C b′,(16) 25 Efficient Decision Tree Rashomon Sets one...
-
[14]
A pure greedy (information-gain) depth-dtree achieves accuracy at most 1 2 +δ
-
[15]
Every treeTreturned byP RAXIS(S, d, γ, ε abs)achieves accuracy at least1−δ. Proof. Fix δ >0 and define η:=δ/(1 +ε mult). By Theorem A.7 of Babbar et al. (2025), for this η and depth d there exist D and n such that, with high probability over S∼ D n: (i) LICKETYSPLIT returns a depth- d tree with error at most η, and (ii) pure greedy achieves error at least...
2025
-
[16]
the returned AND/OR graphGcontains the ProxyWrapper treef pw(D, d)
-
[17]
In particular, G.min objective≤Obj(f pw(D, d), D, γ)≤Obj(f px, D, γ). Proof.Claim.If PRAXIS is invoked on(D, d)withε abs ≥P(D, d), then the returned graph containsf pw(D, d). Base case:d= 0. By construction, PROXYWRAPPERreturns a leaf (in fact, the majority leaf). Since εabs ≥P(D,0) and PRAXIS inserts all feasible leaf actions whose objective is ≤ε abs, t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.