On the Necessity of a Liquid Substrate for Mesh Intelligence
Pith reviewed 2026-06-30 00:34 UTC · model grok-4.3
The pith
A clock-free mesh agent on fixed weights needs a continuous-time liquid substrate to estimate a changing latent from irregular observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
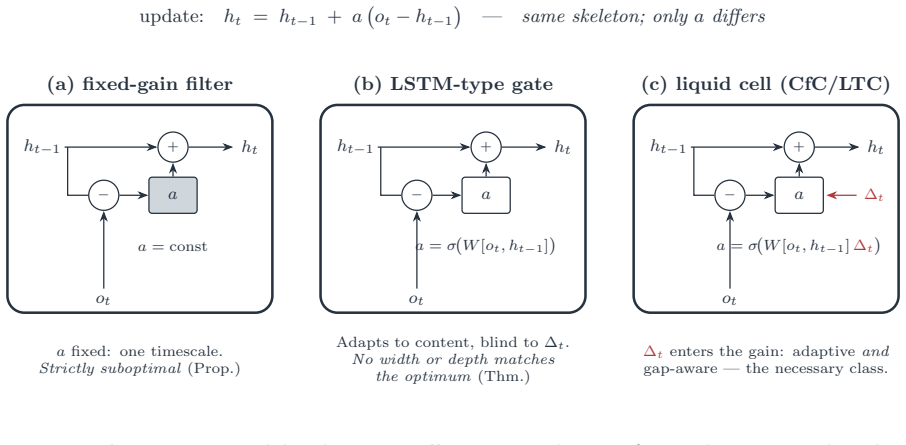
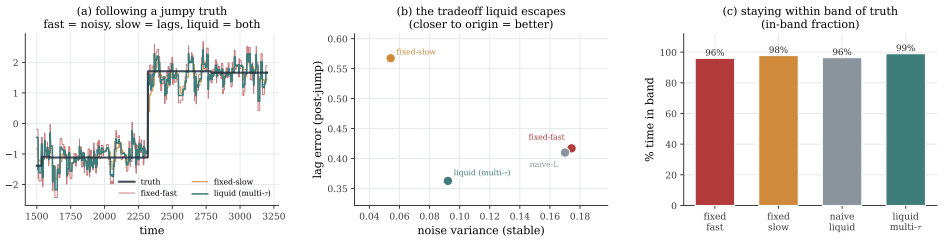
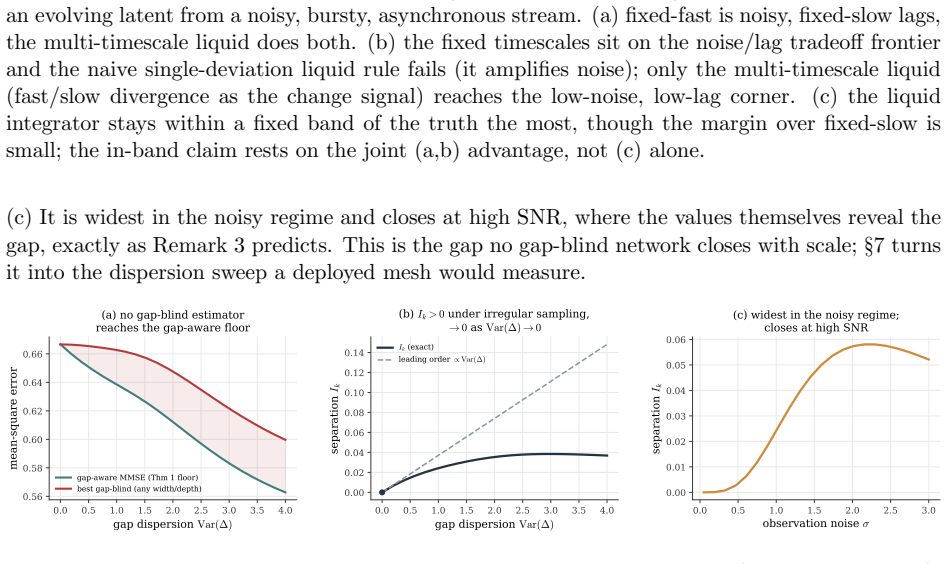
Under a model of a self-evolving latent observed at irregular exogenous times on a fixed-weight substrate, the optimal estimator must be time-varying because the latent changes and must incorporate the elapsed inter-arrival gap because arrivals carry no shared clock; fixed-gain filters fail the first requirement and gap-blind networks fail the second at every scale, with both requirements met precisely by continuous-time liquid networks.
What carries the argument
The intersection of an adaptive-timescale requirement and an explicit inter-arrival-gap dependence, which together define the continuous-time liquid class.
If this is right
- An LSTM satisfies the adaptive-timescale condition but cannot recover gap dependence.
- A fixed continuous-time filter satisfies gap dependence but cannot adapt its timescale.
- A multi-timescale liquid network satisfies both conditions simultaneously.
- The necessity applies to every agent in the mesh because the argument is proved per agent.
- A substrate allowed to retrain can reach the required class by other routes, but fixed-weight substrates are bound to the liquid form.
Where Pith is reading between the lines
- Mesh systems may need to embed liquid dynamics at the level of individual agents rather than relying on scale or coordination protocols.
- Asynchronous distributed estimation problems outside meshes could benefit from explicit gap inputs or continuous-time state evolution.
- Hybrid architectures that combine retrainable and fixed-weight components might still require liquid elements for the fixed parts.
Load-bearing premise
The derivation assumes a specific model of a self-evolving latent observed at irregular exogenous times on a substrate whose weights cannot be retrained.
What would settle it
An experiment in which a gap-blind network matches the estimation error of a gap-aware liquid network on irregular observations of a changing latent without any weight retraining.
Figures
read the original abstract
A mesh of sovereign agents has no center: no shared clock, no shared model, and no coordinator to gather data or retrain. Its competence rests on each agent folding the projections its peers emit into a single internal state, online, from observations that arrive at irregular, unscheduled times, on a substrate whose weights it cannot retrain. Any one of these constraints is tractable on its own; folding optimally under all three at once is not. We ask what such a substrate must be, and prove two necessary conditions from one model of a self-evolving latent observed at irregular, exogenous times. Because the latent changes, its optimal estimator is time-varying: an adaptive timescale is necessary, and every fixed-gain filter is strictly suboptimal. And because arrivals are clock-free, the optimal estimate depends on the elapsed gap between them, which no gap-blind network recovers at any width or depth. This second condition is capacity-independent: scale cannot substitute for the missing dependence. The two conditions intersect in the continuous-time liquid class. An LSTM satisfies the first, a fixed continuous-time filter the second, and a multi-timescale liquid network both. Synthetic experiments confirm each: the network attains the timescale, and the separation is computed exactly. The characterization is necessary, not sufficient, and binds fixed-weight substrates: a network free to retrain reaches the class by other means. Proved per agent, the necessity binds every agent of a mesh, a structural condition on mesh intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a mesh of sovereign agents, lacking shared clock, model, or coordinator, requires each agent to process irregular observations on a non-retrainable substrate. From a model of a self-evolving latent observed at irregular exogenous times, it proves two necessary conditions: an adaptive timescale (fixed-gain filters are suboptimal) and dependence on the elapsed gap between arrivals (no gap-blind network can recover it at any capacity). These conditions are satisfied by the continuous-time liquid class. Synthetic experiments confirm the properties. The result is necessary (not sufficient) and applies to fixed-weight substrates, thereby binding every agent in such a mesh.
Significance. If the proofs are correct, this provides a significant structural insight into the requirements for mesh intelligence under asynchronous, decentralized conditions. The capacity-independent result for gap dependence is particularly noteworthy, as it shows scale cannot compensate for missing architectural features. The paper's explicit limitation to fixed-weight substrates and acknowledgment that retraining allows other means is a strength, as it scopes the claim appropriately. The synthetic confirmation adds value. The stress-test concern regarding the model assumptions does not land, as the paper defines the mesh setting to include fixed weights and irregular exogenous observations.
major comments (1)
- [Abstract] Abstract: the claim that 'no gap-blind network recovers the elapsed-gap dependence at any width or depth' and that this is capacity-independent is load-bearing for the central argument that scale cannot substitute for the missing dependence. The derivation of this result (from the specific self-evolving latent model) should be verified to confirm it applies to arbitrary gap-blind architectures rather than a restricted subclass.
minor comments (2)
- The abstract is dense with technical claims; consider splitting the two necessity conditions and their intersection with the liquid class into shorter, more readable sentences.
- The term 'continuous-time liquid class' is used without a brief inline definition or forward reference in the abstract; adding one would improve accessibility for readers outside the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive assessment and recommendation of minor revision. The single major comment is addressed below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'no gap-blind network recovers the elapsed-gap dependence at any width or depth' and that this is capacity-independent is load-bearing for the central argument that scale cannot substitute for the missing dependence. The derivation of this result (from the specific self-evolving latent model) should be verified to confirm it applies to arbitrary gap-blind architectures rather than a restricted subclass.
Authors: The derivation starts from the explicit form of the Bayes-optimal estimator for the self-evolving latent under irregular exogenous arrivals. Because the latent evolves continuously, the posterior mean at the current time is a function of the elapsed gap Δ since the last observation (in addition to the observation values themselves). Any gap-blind network receives no input encoding Δ and therefore cannot produce an output that varies with Δ for fixed observations; this is an input-information limitation, not an expressivity limitation. The argument therefore holds for every architecture that lacks gap information, independent of width, depth, or other internal structure. We will insert one clarifying sentence in the revised Section 3 to emphasize that the result is architecture-agnostic. revision: yes
Circularity Check
No significant circularity; derivation self-contained under stated model assumptions
full rationale
The paper explicitly introduces a model of a self-evolving latent observed at irregular exogenous times on a non-retrainable substrate, then derives the two necessary conditions (adaptive timescale and elapsed-gap dependence) as mathematical consequences within that model. This constitutes a standard necessity proof rather than any of the enumerated circular patterns: no parameter is fitted to data and renamed as a prediction, no result is defined in terms of itself, and no load-bearing step reduces to a self-citation or smuggled ansatz. The text acknowledges that the conditions fail to hold if retraining or scheduled arrivals are permitted, confirming the assumptions are overt rather than hidden. The capacity-independence claim is presented as following from the gap-blind definition of the networks considered, without evidence of tautological reduction. The overall characterization therefore retains independent content as a structural constraint under the given restrictions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A self-evolving latent is observed at irregular exogenous times on a fixed-weight substrate.
Reference graph
Works this paper leans on
-
[1]
H. Xu. Mesh Inference: A Formal Model of Collective Inference Without a Center. arXiv:2606.19537, 2026
Pith/arXiv arXiv 2026
-
[2]
H. Xu. Symbolic-Vector Attention Fusion for Collective Intelligence. arXiv:2604.03955, 2026
Pith/arXiv arXiv 2026
-
[3]
Hasani, M
R. Hasani, M. Lechner, A. Amini, L. Liebenwein, A. Ray, M. Tschaikowski, G. Teschl, D. Rus. Closed-form continuous-time neural networks. Nature Machine Intelligence, 2022. 12
2022
-
[4]
Hasani, M
R. Hasani, M. Lechner, A. Amini, D. Rus, R. Grosu. Liquid time-constant networks. AAAI, 2021
2021
-
[5]
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, D. Duvenaud. Neural ordinary differential equa- tions. NeurIPS, 2018
2018
-
[6]
Maass, T
W. Maass, T. Natschl¨ ager, H. Markram. Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Computation, 14(11):2531– 2560, 2002
2002
-
[7]
Jaeger, H
H. Jaeger, H. Haas. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science, 304(5667):78–80, 2004
2004
-
[8]
Z. Che, S. Purushotham, K. Cho, D. Sontag, Y. Liu. Recurrent neural networks for multivariate time series with missing values. Scientific Reports, 8:6085, 2018
2018
-
[9]
Y. Zhu, H. Li, Y. Liao, B. Wang, Z. Guan, H. Liu, D. Cai. What to do next: modeling user behaviors by Time-LSTM. IJCAI, 2017
2017
-
[10]
Rubanova, R
Y. Rubanova, R. T. Q. Chen, D. Duvenaud. Latent ODEs for irregularly-sampled time series. NeurIPS, 2019
2019
-
[11]
A. Gu, T. Dao, S. Ermon, A. Rudra, C. R´ e. HiPPO: recurrent memory with optimal polynomial projections. NeurIPS, 2020
2020
-
[12]
A. Gu, K. Goel, C. R´ e. Efficiently modeling long sequences with structured state spaces. ICLR, 2022
2022
-
[13]
A. Gu, T. Dao. Mamba: linear-time sequence modeling with selective state spaces. arXiv:2312.00752, 2023
Pith/arXiv arXiv 2023
-
[14]
McMahan, E
B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas. Communication-efficient learning of deep networks from decentralized data. AISTATS, 2017
2017
-
[15]
X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, J. Liu. Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel SGD. NeurIPS, 2017
2017
-
[16]
R. Lowe, Y. Wu, A. Tamar, J. Harb, P. Abbeel, I. Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments. NeurIPS, 2017
2017
-
[17]
R. E. Kalman. A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 82(1):35–45, 1960
1960
-
[18]
S. Haykin. Adaptive Filter Theory. Prentice Hall, 5th ed., 2013
2013
-
[19]
Basseville, I
M. Basseville, I. V. Nikiforov. Detection of Abrupt Changes: Theory and Application. Prentice Hall, 1993
1993
-
[20]
Bar-Shalom, X.-R
Y. Bar-Shalom, X.-R. Li, T. Kirubarajan. Estimation with Applications to Tracking and Nav- igation. Wiley, 2001
2001
-
[21]
R. P. Adams, D. J. C. MacKay. Bayesian online changepoint detection. arXiv:0710.3742, 2007. 13
Pith/arXiv arXiv 2007
-
[22]
A. H. Jazwinski. Stochastic Processes and Filtering Theory. Academic Press, 1970
1970
-
[23]
C. E. Shannon. A mathematical theory of communication. Bell System Technical Journal, 27(3):379–423, 1948. 14
1948
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.