Repeated Sequences Reveal Gaps between Large Language Models and Natural Language
Pith reviewed 2026-06-30 12:28 UTC · model grok-4.3
The pith
Large language model outputs show different entropy growth in repeated subsequences than natural language texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
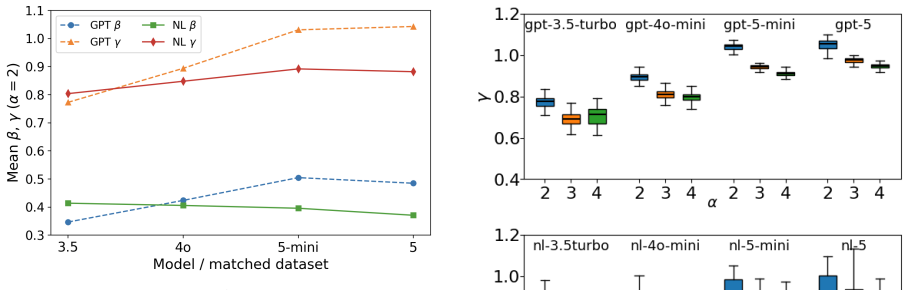
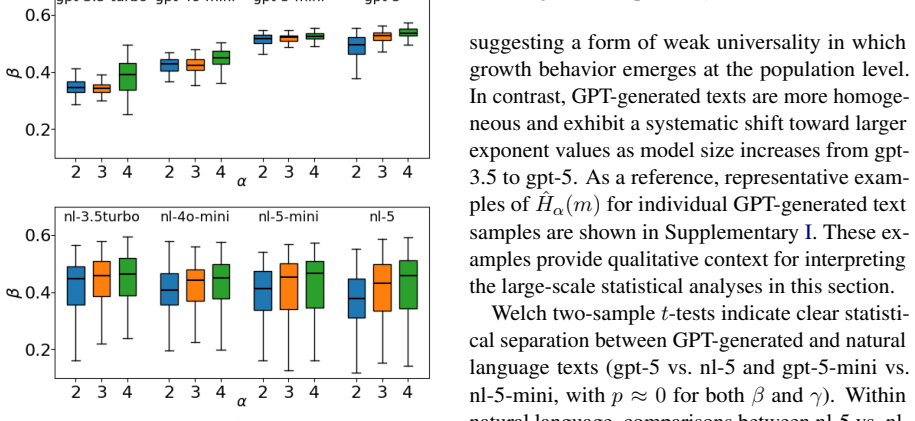
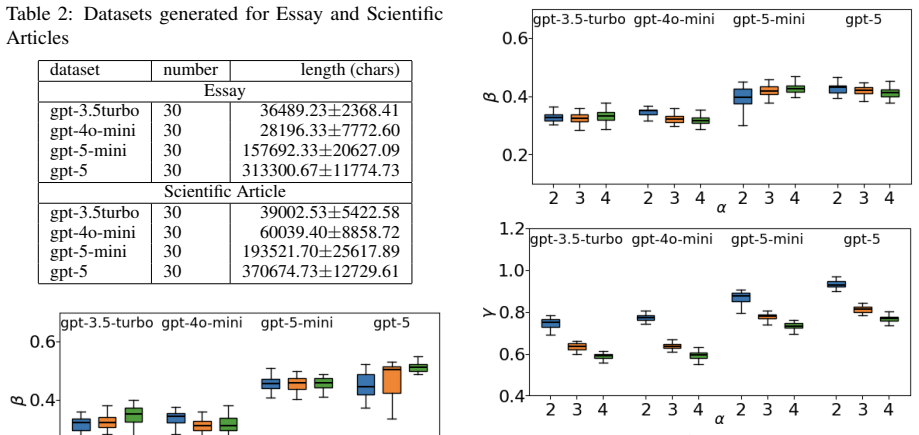
By relating the distribution of repeated subsequences across scales to higher-order Rényi entropies, the analysis reveals that natural language maintains consistent entropy-growth patterns, whereas GPT-generated texts exhibit systematic shifts in estimated exponents with increasing model size. These results demonstrate that repeated-subsequence entropy provides a quantitative structural diagnostic that reveals systematic differences in long-range organization, distinguishing natural language from state-of-the-art LLM outputs beyond surface-level fluency.
What carries the argument
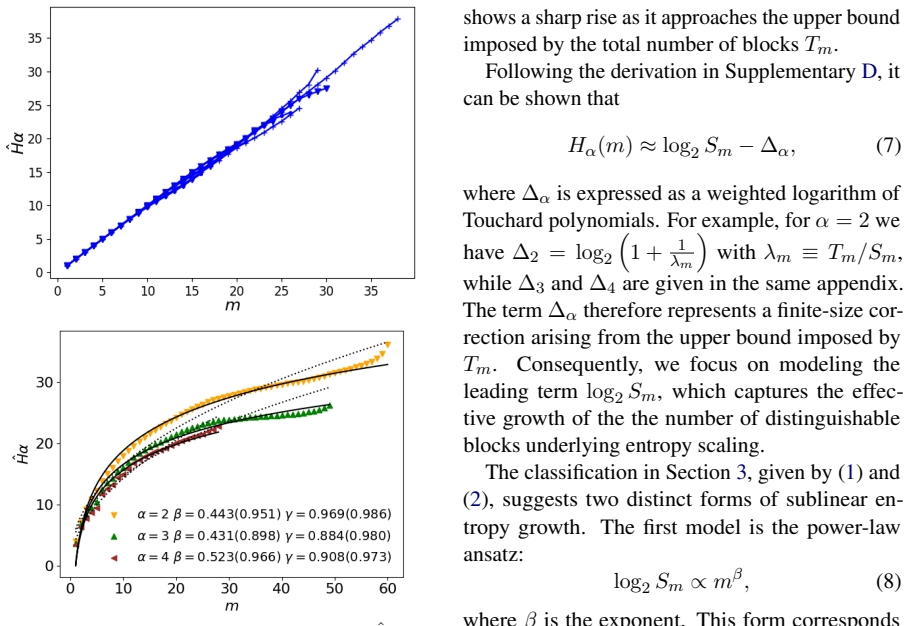
Repeated-subsequence entropy, derived from the distribution of repeated blocks across scales and linked to higher-order Rényi entropies, serving as a diagnostic for long-range statistical organization.
If this is right
- Natural language exhibits stable entropy-growth patterns over accessible ranges with consistent average behavior despite variability across texts.
- GPT-generated texts display systematic and statistically significant shifts in estimated exponents tied to model size.
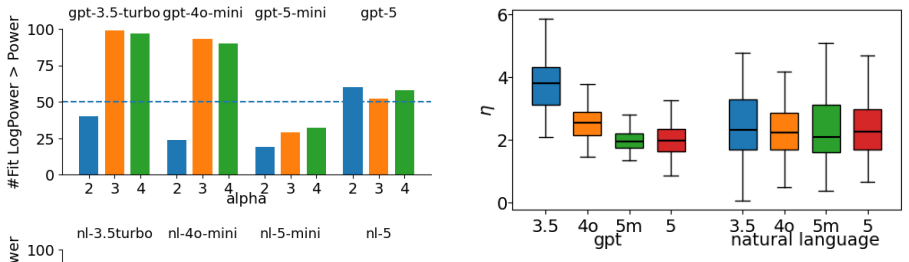
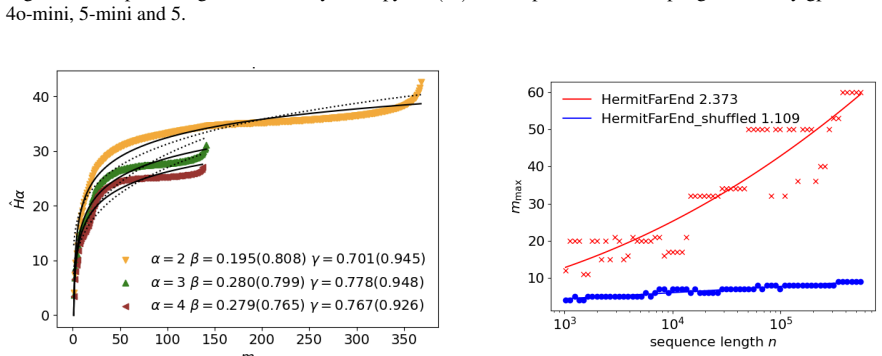
- Power-law models describe only restricted ranges of block length, while logarithmic-power forms often characterize the observed entropy growth equally or better.
- Repeated-subsequence entropy supplies a quantitative diagnostic for long-range organization that goes beyond task performance or short-context behavior.
Where Pith is reading between the lines
- This diagnostic could be applied to other sequence generators such as code or music to test structural fidelity at scale.
- Training objectives might incorporate subsequence repetition statistics to reduce the observed gaps in long-range organization.
- The method opens a route to compare multiple model families on the same structural metric without relying on downstream tasks.
Load-bearing premise
Differences in estimated entropy-growth exponents between human and GPT texts reflect fundamental gaps in long-range statistical organization rather than generation artifacts, vocabulary differences, or the choice of fitting forms.
What would settle it
A direct comparison of entropy exponents on length-matched texts where GPT generation is constrained to eliminate repetition artifacts and match human vocabulary distributions would falsify the claim if the exponents align with natural language patterns.
Figures




read the original abstract
Evaluating whether large language models (LLMs) capture the structure of natural language beyond local fluency remains an open challenge. Existing evaluation methods, largely based on task performance or short-context behavior, provide limited insight into the long-range statistical organization of generated text. We propose a complementary evaluation framework based on repeated subsequences. By analyzing their distribution across scales and relating it to higher-order R\'enyi entropies, we probe how texts reuse previously established structure under finite-length conditions. Experiments on human-written texts and length-matched GPT-generated texts show that, while power-law models can describe restricted ranges of block length, the observed entropy growth is often equally or better characterized by logarithmic--power forms. Across datasets, natural language exhibits stable entropy-growth patterns over accessible ranges, with consistent average behavior despite variability across individual texts. In contrast, GPT-generated texts show systematic and statistically significant shifts in estimated exponents with model size. These results demonstrate that repeated-subsequence entropy provides a quantitative structural diagnostic that reveals systematic differences in long-range organization, distinguishing natural language from state-of-the-art LLM outputs beyond surface-level fluency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an evaluation framework based on the distribution of repeated subsequences and their connection to higher-order Rényi entropies. It analyzes entropy growth across block lengths in human-written texts versus length-matched GPT outputs, finding that power-law models suffice only in restricted ranges while logarithmic-power forms often characterize the growth better. Natural language shows stable entropy-growth patterns with consistent average behavior, whereas GPT texts exhibit systematic, statistically significant shifts in estimated exponents as model size increases. The central claim is that this repeated-subsequence entropy diagnostic reveals gaps in long-range statistical organization beyond surface fluency.
Significance. If the central empirical distinctions hold under uniform protocols, the work supplies a quantitative, scale-sensitive structural probe that is complementary to task-based or short-context evaluations. It could help identify whether LLMs reproduce the hierarchical reuse statistics of natural language and might guide improvements in long-range coherence modeling.
major comments (2)
- [Abstract / Results] Abstract and results sections: the reported systematic shifts in entropy-growth exponents between human and GPT corpora rest on model selection between power-law and logarithmic-power forms. The manuscript must demonstrate that the distinction survives when an identical fitting protocol (including the same block-length range and model-selection criterion) is applied uniformly to both classes of text; otherwise the exponent differences could be driven by differential preference for the log-power form rather than intrinsic long-range organization.
- [Methods] Methods: the relation between repeated-subsequence counts and Rényi entropies is invoked to justify the entropy-growth analysis, but the precise mapping (including any finite-length corrections or subsequence-counting details) is not shown to be robust to the choice of Rényi order or to vocabulary-size differences between human and GPT texts.
minor comments (2)
- [Experimental setup] Clarify the exact procedure for length-matching GPT outputs to human texts and report any sensitivity of the exponent estimates to this matching.
- [Results] Provide the precise statistical test and correction used to establish 'statistically significant shifts' with model size.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped clarify the presentation of our results. We address each major comment below and have revised the manuscript to strengthen the uniformity and robustness of the analyses.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results sections: the reported systematic shifts in entropy-growth exponents between human and GPT corpora rest on model selection between power-law and logarithmic-power forms. The manuscript must demonstrate that the distinction survives when an identical fitting protocol (including the same block-length range and model-selection criterion) is applied uniformly to both classes of text; otherwise the exponent differences could be driven by differential preference for the log-power form rather than intrinsic long-range organization.
Authors: We agree that uniform protocols are required to isolate intrinsic differences. Our original analysis already employed identical block-length ranges for human and GPT texts, but model selection (via information criteria) was performed per corpus. We have now re-executed the full pipeline with a single fixed model-selection criterion and range applied uniformly across all texts. The systematic exponent shifts remain statistically significant under this protocol; we have added explicit statements in the Results section and new supplementary figures documenting the uniform procedure and outcomes. revision: yes
-
Referee: [Methods] Methods: the relation between repeated-subsequence counts and Rényi entropies is invoked to justify the entropy-growth analysis, but the precise mapping (including any finite-length corrections or subsequence-counting details) is not shown to be robust to the choice of Rényi order or to vocabulary-size differences between human and GPT texts.
Authors: We appreciate the call for explicit robustness checks. The mapping follows directly from the Rényi entropy definition applied to subsequence occurrence probabilities, with standard finite-length bias corrections. In the revision we have expanded the Methods section with the exact counting procedure and added analyses varying the Rényi order (q = 2, 3, 4) as well as vocabulary-size normalization; the reported patterns are stable under these variations. These checks appear in a new appendix and are summarized in the main text. revision: yes
Circularity Check
No circularity: empirical comparison of entropy growth forms on distinct corpora
full rationale
The paper proposes an entropy-based diagnostic on repeated subsequences, relates it to Rényi entropies, and reports empirical differences in fitted power-law versus logarithmic-power exponents between human and GPT texts. No equations or steps are shown that reduce the reported distinctions to fitted parameters by construction, nor do self-citations or imported uniqueness theorems carry the central claim. The result is an observational contrast between two classes of text under a uniform analysis protocol, which remains independent of its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- exponents in power-law and logarithmic-power entropy growth models
axioms (1)
- domain assumption The distribution of repeated subsequences across scales can be related to higher-order Rényi entropies to probe long-range statistical organization under finite-length conditions.
Forward citations
Cited by 2 Pith papers
-
Escaping Mode Collapse in LLM Generation via Geometric Regulation
Reinforced Mode Regulation (RMR) uses low-rank damping on the value cache to prevent geometric collapse and mode collapse in autoregressive LLM generation, supporting stable output down to 0.8 nats/step entropy.
-
Escaping Mode Collapse in LLM Generation via Geometric Regulation
Reinforced Mode Regulation (RMR) applies low-rank damping to the Transformer value cache to prevent geometric collapse and enable stable autoregressive generation at entropy rates as low as 0.8 nats/step.
Reference graph
Works this paper leans on
-
[1]
InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901
Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc. Sébastien Bubeck, Varun Chandrasekaran, Ronen El- dan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Pe- ter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang
1901
-
[2]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general in- telligence: Early experiments with gpt-4.Preprint, arXiv:2303.12712. Thomas M. Cover and Joy A. Thomas. 2006.Ele- ments of Information Theory, 2nd edition. Wiley- Interscience. Łukasz D˛ ebowski
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[3]
strong hilberg conjecture.Entropy, 17(8):5903–5919
Maximal repetitions in written texts: Finite energy hypothesis vs. strong hilberg conjecture.Entropy, 17(8):5903–5919. Łukasz D˛ ebowski. 2020.Information Theory Meets Power Laws : Stochastic processes and Language Models. Wiley. Martin Gerlach and Francesc Font-Clos
2020
-
[4]
Harold S. Heaps. 1978.Information Retrieval: Compu- tational and Theoretical Aspects. Academic Press. Gustav Herdan. 1964.Quantitative Linguistics. Butter- worths. Wolfgang Hilberg
1978
-
[5]
InInternational Conference for Learning Representation (ICLR)
The curious case of neural text de- generation. InInternational Conference for Learning Representation (ICLR). Donald E. Knuth. 1997.The Art of Computer Program- ming, V olume 2: Seminumerical Algorithms, 3rd edi- tion. Addison Wesley Longman, Reading, MA. Andrei N. Kolmogorov
1997
-
[6]
Ming Li and Paul M
Three approaches to the quantitative definition of information.Problems of Information Transmission, 1(1):1–7. Ming Li and Paul M. B. Vitányi. 2008.An Introduction to Kolmogorov Complexity and Its Applications, 3rd edition. Springer. William Merrill, Vivek Ramanujan, Yoav Goldberg, Roy Schwartz, and Noah A. Smith
2008
-
[7]
InProceedings of the 2021 Conference on Empirical Methods in Nat- ural Language Processing, pages 1766–1781, Online and Punta Cana, Dominican Republic
Effects of pa- rameter norm growth during transformer training: Inductive bias from gradient descent. InProceedings of the 2021 Conference on Empirical Methods in Nat- ural Language Processing, pages 1766–1781, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. Rajeev Motwani and Prabhakar Raghavan. 1995.Ran- domized Alg...
2021
-
[8]
1949.Human Behavior and the Principle of Least Effort
George Kingsley Zipf. 1949.Human Behavior and the Principle of Least Effort. Addison-Wesley. Jacob Ziv and Abraham Lempel
1949
-
[9]
SmX i=1 C2 i # = SmX i=1 E[C 2 i ] =S m(λ2 m +λ m). Therefore, E
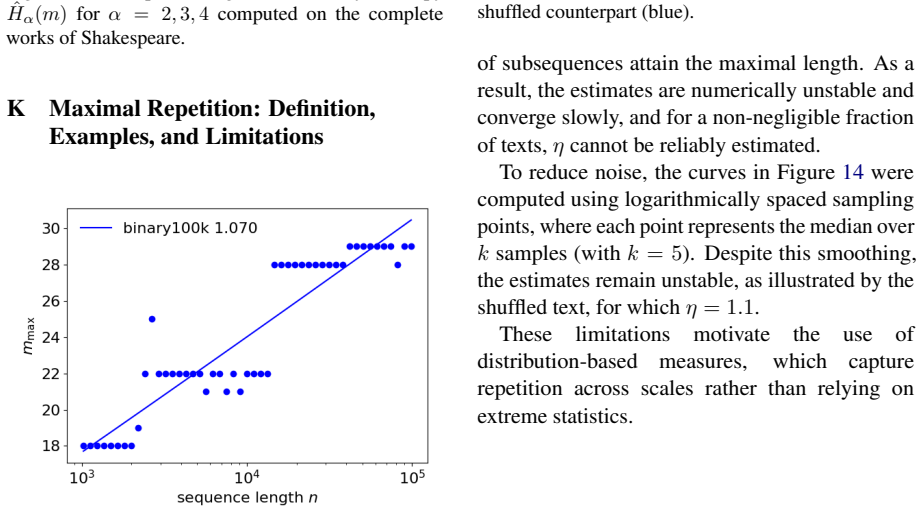
Compression of individual sequences via variable-rate coding.IEEE Transactions on Information Theory, 24(5):530–536. Supplementary Material A Repeated Sequences for a Bernoulli Process (p= 0.5) Figure 8 shows the counts of repeated subse- quences Dm (vertical axis, logarithmic scale) as a function of block length m (horizontal axis) for Bernoulli processe...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.