Few-step Generative Models as Lossy Compression
Pith reviewed 2026-06-27 14:10 UTC · model grok-4.3
The pith
Few-step generative models can serve as lossy image compressors without retraining by adapting them to reverse channel coding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
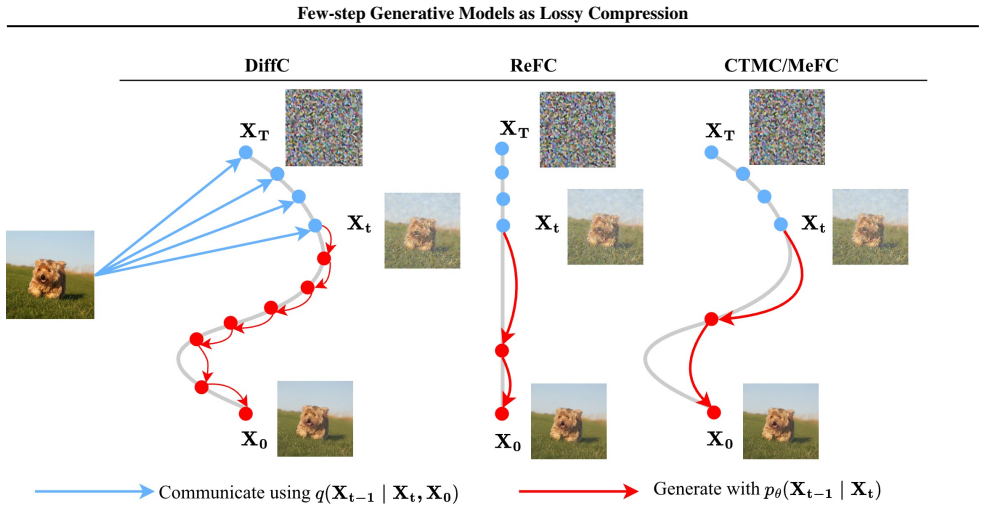
Rectified Flow and MeanFlow supply the quantities demanded by reverse channel coding through the equivalence between velocity parameterization and denoising parameterization; CTM, distilled from EDM, supplies them through the EDM noise parameterization together with local Gaussian approximations of sender and shared distributions at intermediate states. This construction yields a probabilistic codec that reuses any pre-trained few-step model without additional training.
What carries the argument
Reverse channel coding framework supplied with velocity-to-denoising equivalence for flow models and local Gaussian approximations at intermediate states for CTM.
If this is right
- Encoding and decoding each require only a few steps instead of dozens or hundreds.
- No retraining of the generative model is needed to obtain a working compressor.
- Image realism improves relative to multi-step methods in the low-bit-rate regime.
- The same adaptation applies across Rectified Flow, MeanFlow, and CTM.
Where Pith is reading between the lines
- The approach could be tested on higher-resolution images to check whether the local approximations remain accurate.
- Other distilled or few-step models might be plugged into the same reverse channel coding construction.
- The resulting codecs could be combined with conventional entropy coders to reach higher compression ratios.
Load-bearing premise
The velocity equivalence and local Gaussian approximations supply the exact posterior and shared distribution parameters required by reverse channel coding.
What would settle it
Measuring whether the bit rates and reconstruction quality obtained from the derived parameters deviate substantially from those of a full multi-step diffusion codec on the same images.
Figures








read the original abstract
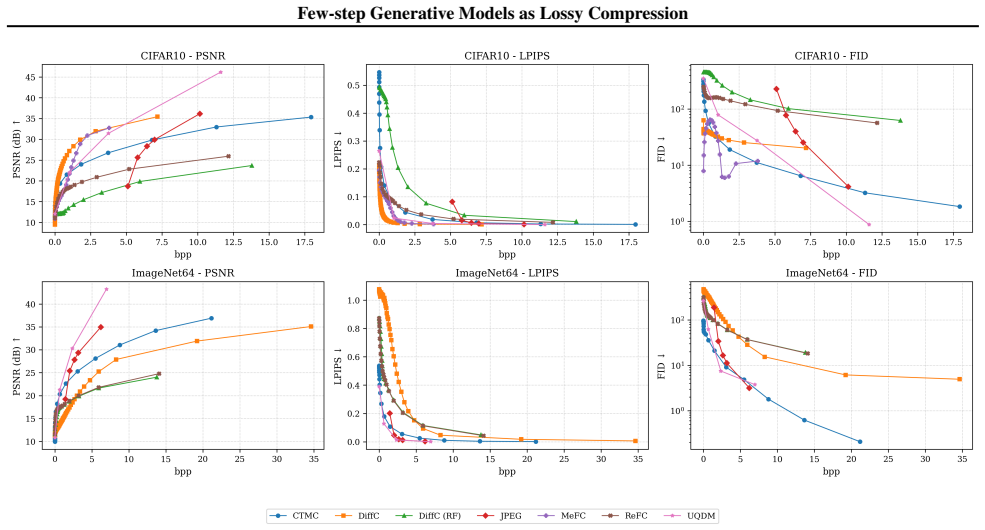
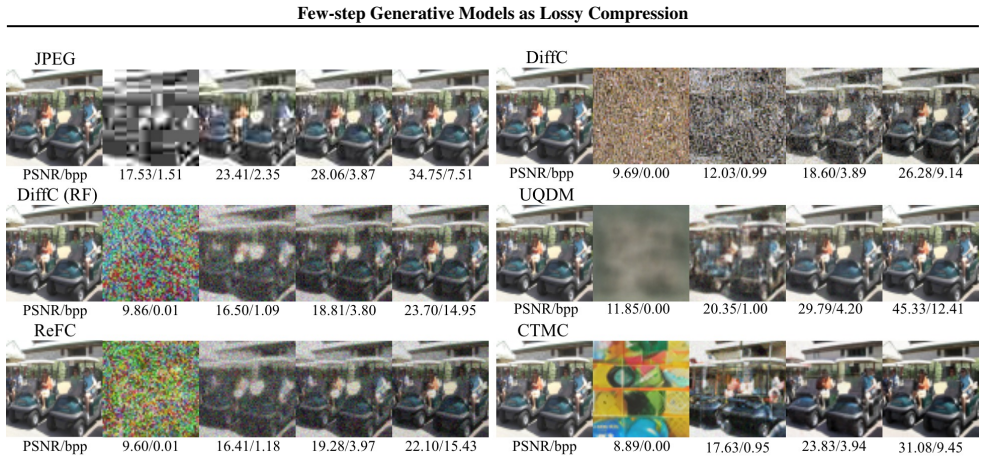
DiffC provides a principled way to reuse pre-trained diffusion models for lossy compression, but its encoding and decoding procedures remain slow because they require many discretized forward and reverse steps. We study whether few-step generative models -- Rectified Flow, Consistency Trajectory Models (CTM), and MeanFlow -- can be cast as codecs within the same reverse channel coding (RCC) framework. The main challenge is that RCC requires posterior and shared distribution parameters, whereas these models do not explicitly parameterize intermediate conditional distributions. For Rectified Flow and MeanFlow, we use the equivalence between velocity parameterization and diffusion-style denoising parameterization to derive the quantities required by RCC. For CTM, which is distilled from EDM, we adopt the EDM noise parameterization together with local Gaussian approximations of the sender and shared distributions at intermediate states. This yields a proof-of-concept probabilistic formulation that enables compression with pre-trained few-step generative models without retraining. On low-resolution benchmarks, the resulting codecs reduce encoding and decoding time and improve realism in the low-bit-rate regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the DiffC reverse channel coding (RCC) framework for lossy compression to few-step generative models (Rectified Flow, Consistency Trajectory Models (CTM), and MeanFlow). It derives the posterior and shared distribution parameters needed by RCC: via velocity-to-denoising reparameterization for Rectified Flow and MeanFlow, and via EDM noise parameterization plus local Gaussian approximations at intermediate states for CTM. The resulting codecs are evaluated on low-resolution benchmarks, where they reduce encoding/decoding time relative to multi-step DiffC and improve perceptual quality in the low-bit-rate regime, all without retraining the base models.
Significance. If the derived distributions satisfy the exact RCC requirements, the work supplies a practical route to fast, training-free compression codecs based on existing few-step models. The proof-of-concept nature and reported speed gains are potentially useful for deployment; however, the absence of explicit error bounds or quantitative checks on the approximations means the rate-distortion guarantees rest on unverified steps rather than on machine-checked derivations or reproducible parameter-free results.
major comments (3)
- [§3.2] §3.2 (CTM derivation): the local Gaussian approximation of sender and shared distributions at intermediate states is introduced without a bound on the approximation error or an empirical verification (e.g., measured KL divergence to the true conditional) that the resulting means and variances coincide with those demanded by the RCC construction; this directly affects whether the encoding/decoding procedure remains correct.
- [§3.1] §3.1 (Rectified Flow / MeanFlow): the velocity-to-denoising equivalence is invoked to obtain the RCC parameters, yet no explicit verification is supplied that the reparameterized conditional distributions are identical to the posterior and shared distributions required by the reverse channel coding theorem; any mismatch would invalidate the claimed probabilistic formulation.
- [§4 / Table 1] Experiments (Table 1 and §4): reported encoding/decoding times and perceptual metrics are given, but no ablation or sensitivity analysis quantifies how deviations from the exact RCC distributions affect achieved rate or distortion; without this, the empirical results do not confirm that the derived quantities satisfy the RCC requirements.
minor comments (2)
- [§3.2] Notation for the approximated variances in the CTM case is introduced without a clear mapping back to the EDM parameterization used in the base model.
- The abstract states that derivations are performed, yet the main text would benefit from a compact summary table listing the exact mean/variance expressions supplied to RCC for each model family.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below. Our work is a proof-of-concept showing that few-step models can be used for compression via the RCC framework; we commit to revisions that add the requested empirical checks and derivations to strengthen the presentation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (CTM derivation): the local Gaussian approximation of sender and shared distributions at intermediate states is introduced without a bound on the approximation error or an empirical verification (e.g., measured KL divergence to the true conditional) that the resulting means and variances coincide with those demanded by the RCC construction; this directly affects whether the encoding/decoding procedure remains correct.
Authors: We acknowledge that the local Gaussian approximation for CTM lacks an explicit error bound or verification in the current manuscript. The approximation is chosen because CTM trajectories are locally near-linear after distillation from EDM. In the revision we will add an empirical verification: we will sample trajectories, estimate the true conditional via Monte Carlo, and report the average KL divergence to the Gaussian approximation at several intermediate states. This will quantify how closely the means and variances match the RCC requirements. revision: yes
-
Referee: [§3.1] §3.1 (Rectified Flow / MeanFlow): the velocity-to-denoising equivalence is invoked to obtain the RCC parameters, yet no explicit verification is supplied that the reparameterized conditional distributions are identical to the posterior and shared distributions required by the reverse channel coding theorem; any mismatch would invalidate the claimed probabilistic formulation.
Authors: The velocity-to-denoising reparameterization for Rectified Flow and MeanFlow is an exact equivalence that preserves the underlying probability path; both describe the same ODE. We will add a short appendix derivation in the revision that explicitly shows the reparameterized conditionals are identical to the posterior and shared distributions required by the RCC theorem, confirming there is no mismatch. revision: yes
-
Referee: [§4 / Table 1] Experiments (Table 1 and §4): reported encoding/decoding times and perceptual metrics are given, but no ablation or sensitivity analysis quantifies how deviations from the exact RCC distributions affect achieved rate or distortion; without this, the empirical results do not confirm that the derived quantities satisfy the RCC requirements.
Authors: We agree that an ablation quantifying sensitivity to deviations from exact RCC parameters would strengthen the empirical claims. In the revised manuscript we will add a sensitivity study that perturbs the derived means/variances by small amounts and reports the resulting changes in rate and perceptual distortion on the same low-resolution benchmarks. revision: yes
Circularity Check
No significant circularity; derivations use external equivalences and explicit assumptions
full rationale
The paper's central step is to cast few-step models into the existing RCC framework by adopting velocity-to-denoising equivalences (for RF/MF) and EDM noise parameterization plus local Gaussian approximations (for CTM). These are presented as adoptions from prior literature and stated assumptions rather than quantities fitted or derived inside this work. No self-definitional reductions, fitted-input-as-prediction, or load-bearing self-citation chains appear; the probabilistic formulation is obtained by direct substitution of these external parameterizations into RCC, which remains falsifiable against the true conditionals.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Equivalence between velocity parameterization and diffusion-style denoising parameterization holds for Rectified Flow and MeanFlow at the intermediate states needed by RCC
- ad hoc to paper Local Gaussian approximations of sender and shared distributions are adequate for CTM at intermediate states
Reference graph
Works this paper leans on
-
[1]
Ball´e, J., Laparra, V ., and Simoncelli, E. P. End-to- 8 Few-step Generative Models as Lossy Compression end optimized image compression.arXiv preprint arXiv:1611.01704,
-
[2]
Ball´e, J., Minnen, D., Singh, S., Hwang, S. J., and Johnston, N. Variational image compression with a scale hyperprior. arXiv preprint arXiv:1802.01436,
-
[3]
ImageNet: A large- scale hierarchical image database
doi: 10.1109/CVPR.2009.5206848. Flamich, G. Greedy poisson rejection sampling.Advances in Neural Information Processing Systems, 36:37089– 37127,
-
[4]
Geng, Z., Deng, M., Bai, X., Kolter, J. Z., and He, K. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
-
[5]
Hoogeboom, E., Agustsson, E., Mentzer, F., Versari, L., Toderici, G., and Theis, L. High-fidelity image compres- sion with score-based generative models.arXiv preprint arXiv:2305.18231,
-
[6]
Kim, D., Lai, C.-H., Liao, W.-H., Murata, N., Takida, Y ., Uesaka, T., He, Y ., Mitsufuji, Y ., and Ermon, S. Consis- tency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279,
-
[7]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
-
[8]
Lai, C.-H., Song, Y ., Kim, D., Mitsufuji, Y ., and Ermon, S
URLhttps://arxiv.org/abs/2506.15742. Lai, C.-H., Song, Y ., Kim, D., Mitsufuji, Y ., and Ermon, S. The principles of diffusion models.arXiv preprint arXiv:2510.21890,
-
[9]
Improving the training of rectified flows.arXiv preprint arXiv:2405.20320,
Lee, S., Lin, Z., and Fanti, G. Improving the training of rectified flows.arXiv preprint arXiv:2405.20320,
-
[10]
T., Ben-Hamu, H., Nickel, M., and Le, M
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
-
[11]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003,
-
[12]
Ohayon, G., Manor, H., Michaeli, T., and Elad, M. Com- pressed image generation with denoising diffusion code- book models.arXiv preprint arXiv:2502.01189,
-
[13]
doi: 10.1109/TIT.1962.1057702. 9 Few-step Generative Models as Lossy Compression Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A. C., and Fei-Fei, L. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 115(3):211–252,
-
[14]
Score-Based Generative Modeling through Stochastic Differential Equations
doi: 10.1007/s11263-015-0816-y. Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Er- mon, S., and Poole, B. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11263-015-0816-y 2011
-
[15]
Lossy image compression with compressive autoencoders
Theis, L., Shi, W., Cunningham, A., and Husz ´ar, F. Lossy image compression with compressive autoencoders. arXiv preprint arXiv:1703.00395,
-
[16]
Theis, L., Salimans, T., Hoffman, M. D., and Mentzer, F. Lossy compression with gaussian diffusion.arXiv preprint arXiv:2206.08889,
-
[17]
V onderfecht, J. and Liu, F. Lossy compression with pretrained diffusion models.arXiv preprint arXiv:2501.09815,
-
[18]
Yang, Y ., Will, J. C., and Mandt, S. Progressive compres- sion with universally quantized diffusion models.arXiv preprint arXiv:2412.10935,
-
[19]
Zhang, R., Isola, P., Efros, A
doi: 10.1109/18.119699. Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595,
-
[20]
Py- Torch implementation of Mean Flows for One-step Gen- erative Modeling. 10 Few-step Generative Models as Lossy Compression Algorithm 3CalcMean Q Require:x t,x 0, αt, σt, αs, σs Ensure:µ t 1:µ t = αs(1−αt) σ2 t x0 + αt αs σ2 s σ2 t xt 2: Returnµ t 3: no operation Algorithm 4CalcMeanStd P Require:x t,ϵ θ, αt, σt, αs, σs Ensure:µ θ, ˜βt 1:µ θ = αs(1−αt) σ...
2020
-
[21]
Notably, µθ can be expressed as a function of˜µt, which motivates the implementations ofCalcMean QandCalcMeanStd Pused in our codec
and pθ(xt−1 |x t)) can be expressed by directly comparing the corresponding means˜µt andµ θ: Lt−1 =E q 1 2σ2 t ∥˜µt(xt,x 0)−µ θ(xt, t)∥2 +C(22) whereCis a constant value.µ θ(xt, t)can be represented with noise-prediction modelϵ θ: µθ(xt, t) =˜µ xt, 1p ¯αDDPM t xt − q 1−¯αDDPM t ϵθ(xt) ! = 1p αDDPM t xt − βtp 1−¯αDDPM t ϵθ(xt, t) ! (23) For a detailed deri...
2020
-
[22]
In DiffC, the noise schedule parameters are αt = p ¯αDDPM t and σt = p 1−¯αDDPM t . B. Velocity–Noise Parameterization Equivalence for Flow Models In the continuous-time setting, the forward process is described by the SDE dxt =f(x t, t)dt+g(t)dw t,(24) where f(x t, t) is the drift coefficient, g(t) is the diffusion coefficient, and wt is a standard Wiene...
2020
-
[23]
Following the velocity–noise parameterization equivalence discussed by Lai et al
proposed the probability flow ODE (PF-ODE): dxt dt =f(x t, t)− 1 2 g(t)2∇x logp t(x).(27) The PF-ODE induces the same marginal distributions pt(x) as the reverse-time SDE, while enabling stable generation with deterministic numerical solvers. Following the velocity–noise parameterization equivalence discussed by Lai et al. (Lai et al., 2025), we summarize...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.