Probabilistic Dating of Historical Manuscripts via Evidential Deep Regression on Visual Script Features
Pith reviewed 2026-05-08 09:43 UTC · model grok-4.3
The pith
Evidential deep regression dates historical manuscripts to within 5 years from visual features
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
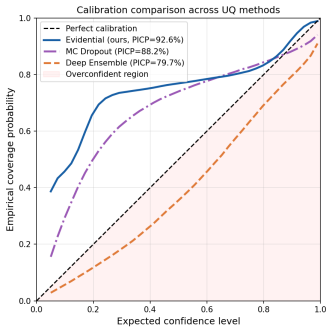
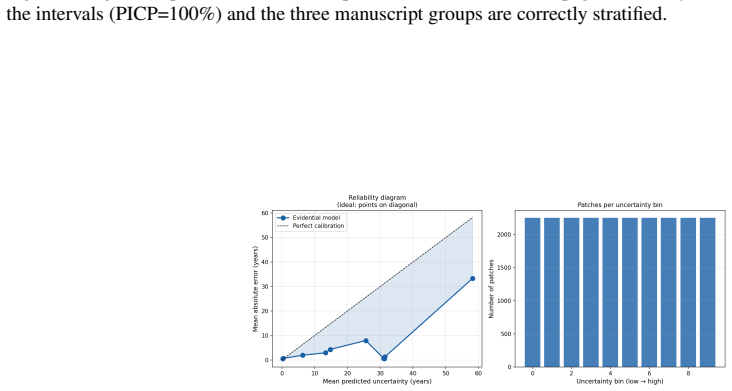
The paper establishes that an evidential deep regression model using a Normal-Inverse-Gamma head on visual script features can predict manuscript dates continuously with 5.4 years mean absolute error and 92.6% prediction interval coverage probability on the DIVA-HisDB benchmark, while decomposing uncertainties and outperforming sampling-based methods in efficiency and calibration.
What carries the argument
The Normal-Inverse-Gamma evidential output head attached to an EfficientNet-B2 backbone, which models the predictive distribution directly and is trained with a joint negative-log-likelihood and evidence-regularization objective to enable uncertainty decomposition in regression.
If this is right
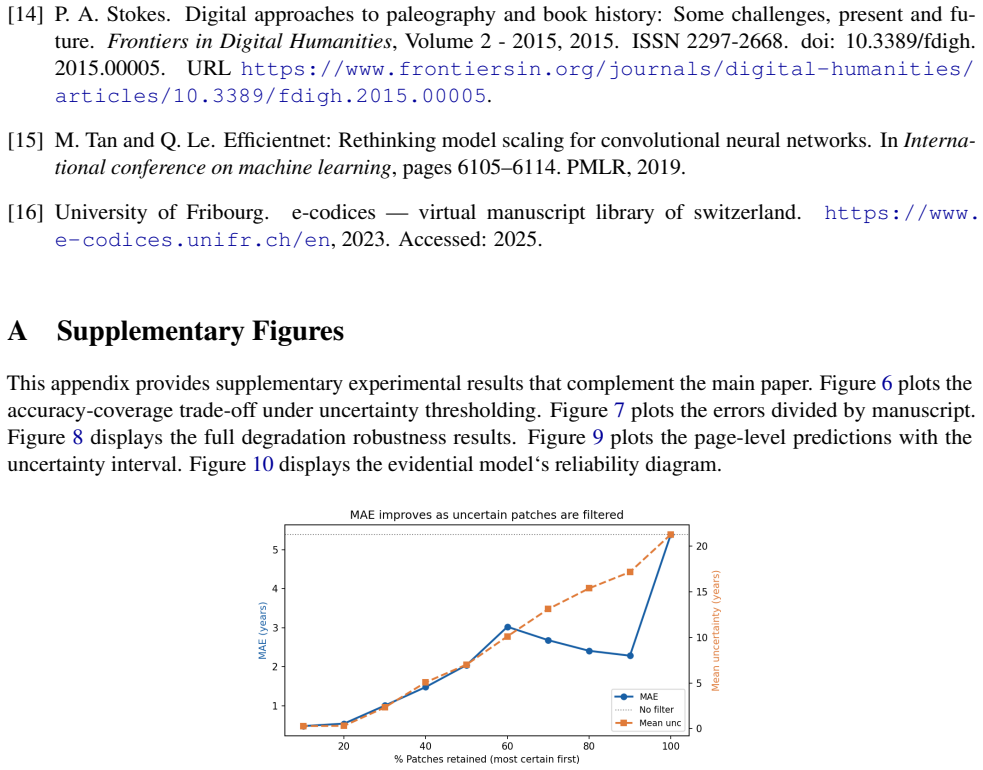
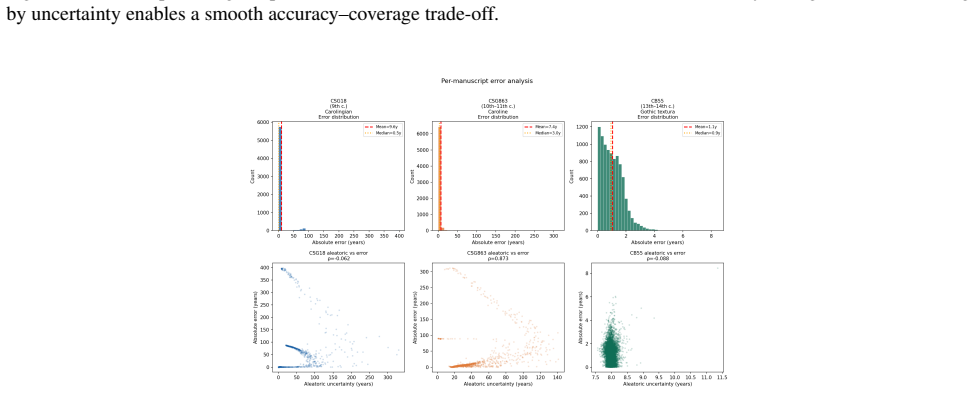
- The 20% of patches with lowest uncertainty achieve 0.5 years MAE.
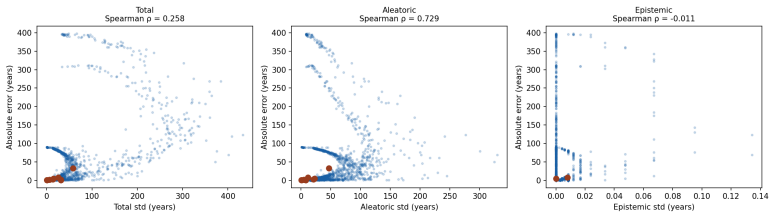
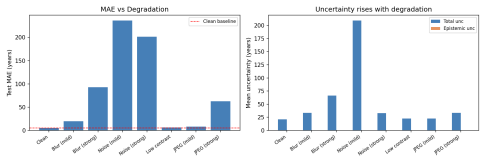
- Aleatoric uncertainty predicts dating error with Spearman correlation 0.729 and rises with worsening image degradation.
- Spatial maps of uncertainty identify script regions responsible for high aleatoric uncertainty.
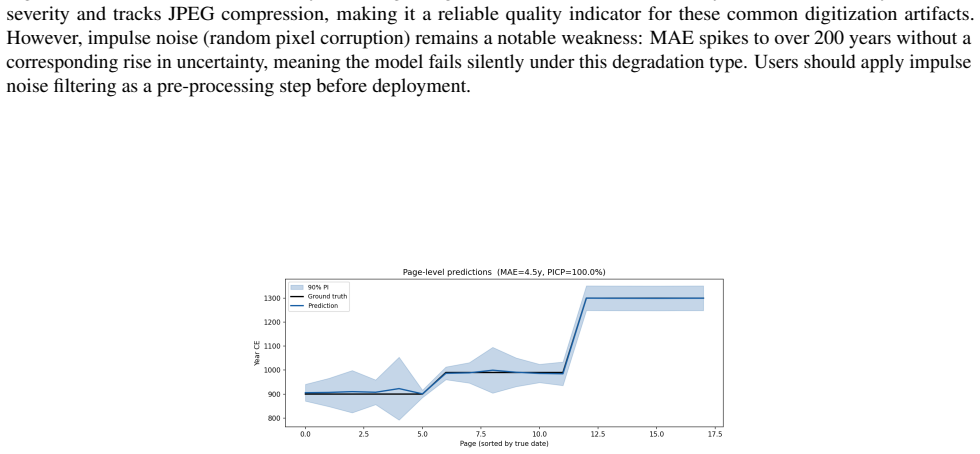
- Aggregating predictions at the page level reduces MAE to 4.5 years.
- Single-pass inference provides better calibration than MC Dropout or Deep Ensembles at 5 times lower cost.
Where Pith is reading between the lines
- This framework could be applied to other historical image analysis tasks where precise continuous labels are scarce but visual patterns evolve over time.
- The uncertainty maps might assist paleographers in focusing on diagnostic script features for manual verification.
- If scaled to larger collections, it would allow probabilistic timelines of manuscript production across archives.
Load-bearing premise
Visual script features extracted from patches of only three codices contain sufficient information to support accurate continuous year regression that generalizes, and the Normal-Inverse-Gamma evidential framework decomposes uncertainties correctly.
What would settle it
A test on manuscript pages from additional codices not seen during training, measuring if the mean absolute error exceeds 10 years or if the prediction interval coverage probability falls significantly below 90%.
Figures


read the original abstract
We introduce a probabilistic approach for dating historical manuscript pages from visual features alone. Instead of aggregating centuries into classes as is standard in the previous literature, we pose dating as an evidential deep regression problem over a continuous year axis, allowing our neural network to output a full predictive distribution with decomposed aleatoric and epistemic uncertainty in a single forward pass. Our architecture combines an EfficientNet-B2 backbone with a Normal-Inverse-Gamma (NIG) output head trained with a joint negative-log-likelihood and evidence-regularization objective. On the DIVA-HisDB benchmark (150 pages, 3 medieval codices, 151,936 patches), our model scores a test MAE of 5.4 years, well below the 50-year century-label supervision granularity, with 93\% of patches within 5 years and 97\% within 10 years. Our approach achieves \textbf{PICP=92.6\%}, the best calibration among all compared methods, in a single forward pass, outperforming MC Dropout (PICP=88.2\%, 50 passes) and Deep Ensembles (PICP=79.7\%, 5 models) at $5\times$ lower inference cost. Uncertainty decomposition shows aleatoric uncertainty is a strong predictor of dating error (Spearman $\rho=0.729$), and a selective prediction about the most certain 20\% of patches can provide \textbf{0.5 years MAE}. We show that predicted uncertainty increases as image degradation worsens, spatial decomposition maps explain which script regions cause aleatoric uncertainty, and page-level aggregation reduces MAE to 4.5 years with $\rho=0.905$ between uncertainty and page-level error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a probabilistic method for dating historical manuscript pages from visual script features alone by posing the task as evidential deep regression over a continuous year axis. An EfficientNet-B2 backbone is combined with a Normal-Inverse-Gamma (NIG) output head and trained using a joint negative-log-likelihood plus evidence-regularization objective. On the DIVA-HisDB benchmark (150 pages from 3 medieval codices, 151,936 patches), the model reports a test MAE of 5.4 years, 93% of patches within 5 years, 97% within 10 years, and PICP=92.6% (best among compared methods) in a single forward pass, outperforming MC Dropout and Deep Ensembles at lower inference cost. Additional results include uncertainty-error correlation, selective prediction, and spatial uncertainty maps.
Significance. If the reported performance and uncertainty calibration generalize beyond the three codices, the work would advance digital paleography by replacing coarse century classification with continuous, calibrated year estimates and decomposed uncertainties obtainable in one pass. The empirical strengths on a public benchmark, including aleatoric uncertainty as an error predictor and page-level aggregation benefits, are clear. The single-pass efficiency relative to ensembles is a practical advantage.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): The headline metrics (MAE 5.4 years, PICP 92.6%) are obtained on patches drawn from the same three codices in DIVA-HisDB. With only three distinct dating targets and 151k patches, a standard patch- or page-level random split permits the model to exploit codex-specific visual traits (script style, layout, degradation) rather than learning a transferable continuous mapping from script features to year. No leave-one-codex-out results, page-level cross-validation across codices, or evaluation on external manuscripts are reported, directly undermining the central claim that the method dates manuscripts 'from visual features alone' in a generalizable manner.
- [§5.2] §5.2 (Uncertainty Calibration): The NIG evidential framework is claimed to produce well-calibrated uncertainties (PICP 92.6%) superior to MC Dropout and Deep Ensembles. However, without explicit verification that the evidence-regularization term prevents the model from fitting codex-specific noise in this closed three-codices setting, the superior calibration may be an artifact of the limited domain rather than a general property of the evidential loss. A concrete test (e.g., out-of-codex PICP) is needed to support the uncertainty decomposition claims.
minor comments (3)
- [Abstract] The abstract states that continuous labels are used 'instead of aggregating centuries into classes' but does not clarify the source or precision of the ground-truth years for the three codices (exact dates vs. approximate ranges).
- [§3.1] §3.1: The joint loss combining NIG negative log-likelihood and evidence regularization is described at a high level; an explicit equation showing the weighting hyperparameter and its effect on the predictive variance would improve reproducibility.
- [Figure 4] Figure 4 (spatial uncertainty maps): The caption and surrounding text should explicitly state the patch size and stride used when generating the maps to allow readers to interpret the highlighted script regions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The concerns about generalizability given the benchmark's limited scope and the need for stronger validation of uncertainty calibration are well-taken. We respond point-by-point below and indicate the changes we will incorporate.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): The headline metrics (MAE 5.4 years, PICP 92.6%) are obtained on patches drawn from the same three codices in DIVA-HisDB. With only three distinct dating targets and 151k patches, a standard patch- or page-level random split permits the model to exploit codex-specific visual traits (script style, layout, degradation) rather than learning a transferable continuous mapping from script features to year. No leave-one-codex-out results, page-level cross-validation across codices, or evaluation on external manuscripts are reported, directly undermining the central claim that the method dates manuscripts 'from visual features alone' in a generalizable manner.
Authors: We agree that the three-codex scope of DIVA-HisDB limits strong claims of broad transferability and that a random page-level split can still permit codex-specific cues to influence results. Our original split was performed at the page level precisely to avoid patch-level leakage from the same physical page, but this does not fully address cross-codex generalization. In the revised manuscript we will add leave-one-codex-out (LOCO) experiments: for each codex we train on the other two and evaluate on the held-out codex, reporting MAE, PICP, and uncertainty-error correlation under this protocol. This directly tests whether the continuous regression mapping transfers across distinct manuscripts. Evaluation on manuscripts completely external to DIVA-HisDB is not possible with currently available public data and is therefore listed as a standing limitation. revision: partial
-
Referee: [§5.2] §5.2 (Uncertainty Calibration): The NIG evidential framework is claimed to produce well-calibrated uncertainties (PICP 92.6%) superior to MC Dropout and Deep Ensembles. However, without explicit verification that the evidence-regularization term prevents the model from fitting codex-specific noise in this closed three-codices setting, the superior calibration may be an artifact of the limited domain rather than a general property of the evidential loss. A concrete test (e.g., out-of-codex PICP) is needed to support the uncertainty decomposition claims.
Authors: We concur that calibration must be verified outside the training codices to substantiate that the evidential loss and regularization produce meaningful uncertainty rather than codex-specific artifacts. We will therefore include LOCO PICP, expected calibration error, and the aleatoric-uncertainty vs. error Spearman correlation in the revised results section. These additional metrics will show whether the Normal-Inverse-Gamma head maintains its reported advantages when the test codex is unseen, thereby strengthening the uncertainty-decomposition claims. revision: yes
- Evaluation on manuscripts external to the DIVA-HisDB benchmark, as no such additional data were available for the original study.
Circularity Check
No circularity: empirical ML evaluation on public benchmark
full rationale
The paper trains an EfficientNet-B2 + NIG regression head on DIVA-HisDB patches (151k from 3 codices) and reports direct test metrics (MAE 5.4, PICP 92.6%). No derivation chain exists that reduces predictions to fitted inputs by construction, nor any self-definitional equations or load-bearing self-citations. The NIG evidential loss and uncertainty decomposition follow standard prior formulations from external literature; results are falsifiable on the held-out patches without tautological re-use of training targets. Generalization limits to three codices are a validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
free parameters (1)
- NIG distribution parameters
axioms (2)
- domain assumption Visual script features contain sufficient information for year-level dating precision beyond century granularity
- domain assumption The evidential deep learning objective with NIG head correctly decomposes aleatoric and epistemic uncertainty
Reference graph
Works this paper leans on
- [1]
-
[2]
A. Ciula. Digital palaeography: using the digital representation of medieval script to support palaeographic analysis. 2005. URLhttps://api.semanticscholar.org/CorpusID:113619742
work page 2005
-
[3]
F. Cloppet, V . Eglin, M. Helias-Baron, C. Kieu, N. Vincent, and D. Stutzmann. Icdar2017 competition on the classification of medieval handwritings in latin script. In2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 01, pages 1371–1376, 2017. doi: 10.1109/ICDAR. 2017.224
-
[4]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
- [5]
-
[6]
S. He and L. Schomaker. Beyond ocr: Multi-faceted understanding of handwritten document char- acteristics.Pattern Recognition, 63:321–333, 2017. ISSN 0031-3203. doi: https://doi.org/10.1016/ j.patcog.2016.09.017. URL https://www.sciencedirect.com/science/article/pii/ S0031320316302783
work page 2017
-
[7]
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in neural information processing systems, 30, 2017
work page 2017
-
[8]
C. Leibig, V . Allken, P. Berens, and S. Wahl. Leveraging uncertainty information from deep neural networks for disease detection.Scientific Reports, 10 2017. doi: https://doi.org/10.1038/s41598-017-17876-z
-
[9]
J. Li, Y . Xu, T. Lv, L. Cui, C. Zhang, and F. Wei. Dit: Self-supervised pre-training for document image transformer. InProceedings of the 30th ACM international conference on multimedia, pages 3530–3539, 2022
work page 2022
-
[10]
G. Louloudis, N. Stamatopoulos, and B. Gatos. Icdar 2011 writer identification contest. InProceedings of the 2011 International Conference on Document Analysis and Recognition, ICDAR ’11, page 1475–1479, USA, 2011. IEEE Computer Society. ISBN 9780769545202. doi: 10.1109/ICDAR.2011.293. URL https://doi.org/10.1109/ICDAR.2011.293
-
[11]
A. G. Roy, S. Conjeti, N. Navab, and C. Wachinger. Inherent brain segmentation quality control from fully convnet monte carlo sampling. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 664–672. Springer, 2018
work page 2018
-
[12]
M. Seuret, A. Nicolaou, D. Rodr´ıguez-Salas, N. Weichselbaumer, D. Stutzmann, M. Mayr, A. Maier, and V . Christlein. Icdar 2021 competition on historical document classification. In J. Llad ´os, D. Lopresti, and S. Uchida, editors,Document Analysis and Recognition – ICDAR 2021, pages 618–634, Cham, 2021. Springer International Publishing. ISBN 978-3-030-86337-1
work page 2021
-
[13]
F. Simistira, M. Seuret, N. Eichenberger, A. Garz, M. Liwicki, and R. Ingold. Diva-hisdb: A precisely annotated large dataset of challenging medieval manuscripts. In2016 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), pages 471–476, 2016. doi: 10.1109/ICFHR.2016.0093. 10
-
[14]
P. A. Stokes. Digital approaches to paleography and book history: Some challenges, present and fu- ture.Frontiers in Digital Humanities, V olume 2 - 2015, 2015. ISSN 2297-2668. doi: 10.3389/fdigh. 2015.00005. URL https://www.frontiersin.org/journals/digital-humanities/ articles/10.3389/fdigh.2015.00005
- [15]
-
[16]
e-codices — virtual manuscript library of switzerland
University of Fribourg. e-codices — virtual manuscript library of switzerland. https://www. e-codices.unifr.ch/en, 2023. Accessed: 2025. A Supplementary Figures This appendix provides supplementary experimental results that complement the main paper. Figure 6 plots the accuracy-coverage trade-off under uncertainty thresholding. Figure 7 plots the errors d...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.