MedStreamBench: A Time-Aware Benchmark for Streaming and Proactive Medical Video Understanding
Pith reviewed 2026-07-03 16:34 UTC · model grok-4.3
The pith
MedStreamBench shows leading vision-language models drop sharply in performance when medical videos require timed decisions rather than offline answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
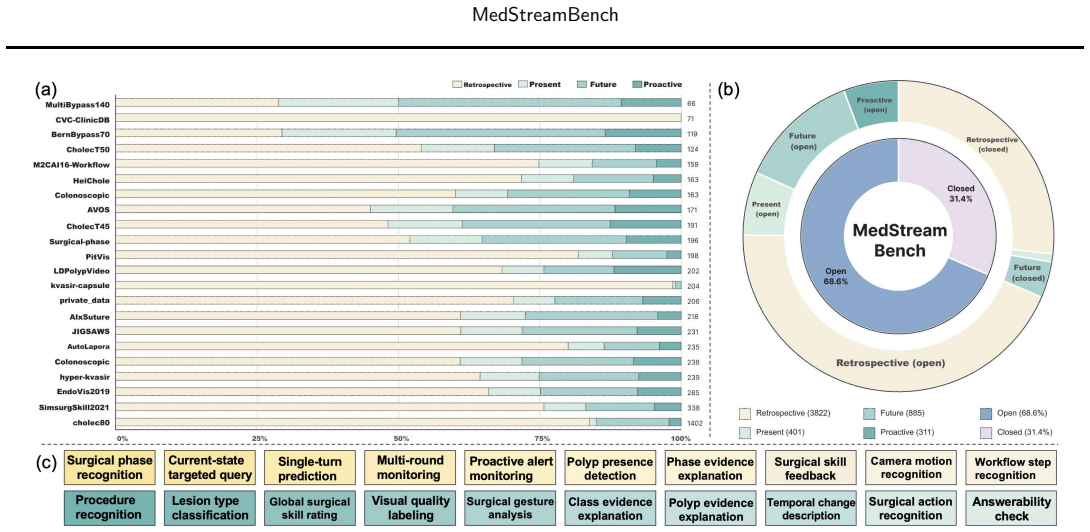
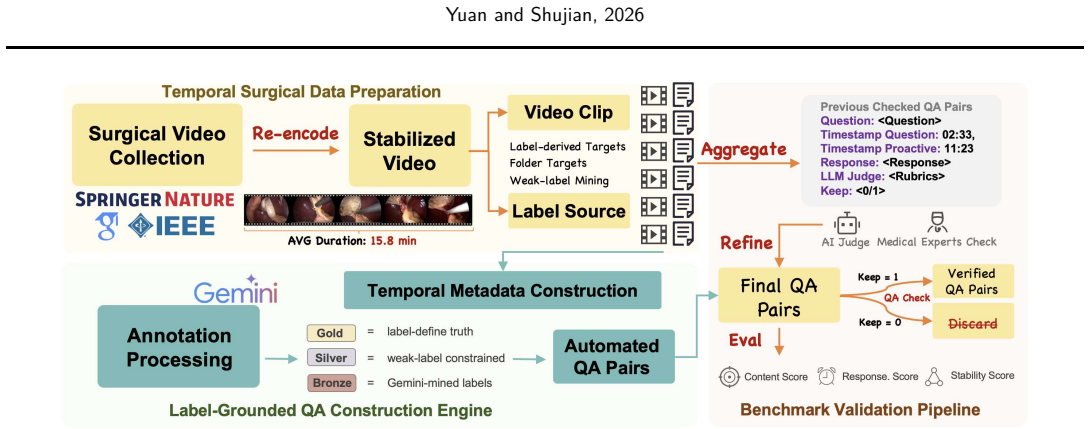
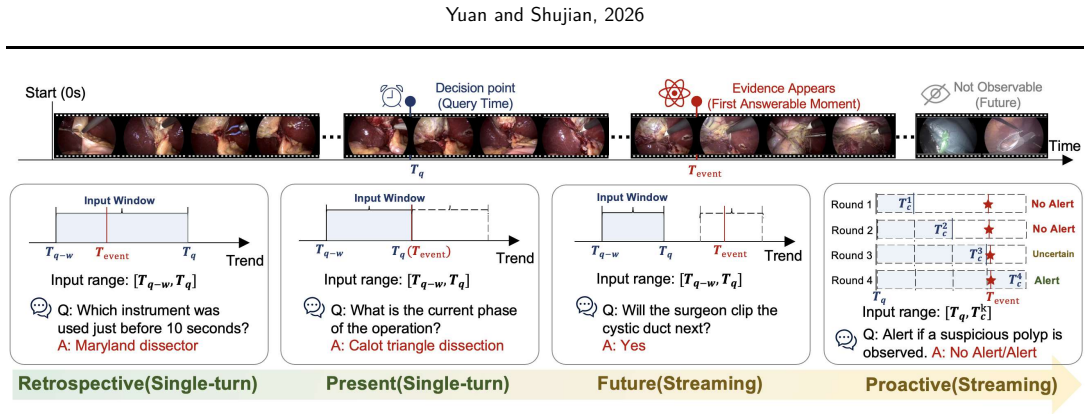
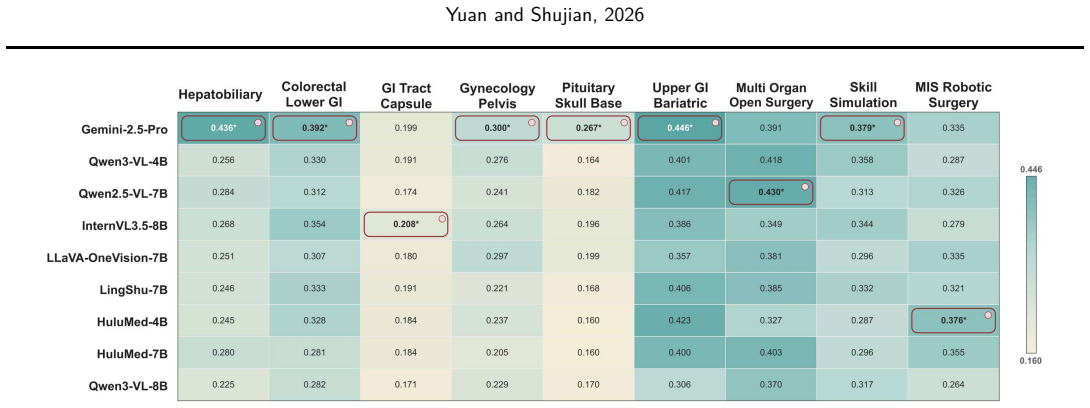
The paper introduces MedStreamBench as a benchmark that integrates 22 medical datasets and 5419 QA instances across retrospective, present, future, and proactive temporal settings. It restricts models to temporally bounded evidence windows, supports single-turn and streaming evaluation, and adds a proactive monitoring task that requires models to decide whether and when to trigger alerts. Beyond answer correctness, the benchmark measures temporal behavior through responsiveness and post-evidence stability. Experiments on leading general-purpose and medical vision-language models reveal a substantial gap between offline recognition and temporally grounded decision-making, with performance dro
What carries the argument
MedStreamBench benchmark, which enforces four temporal settings and bounded evidence windows to test when models answer or alert in medical video streams.
If this is right
- Clinical AI evaluation must include timing of predictions in addition to correctness to match deployment needs.
- Restricting models to bounded evidence windows tests real-time decision making more closely than full-video access.
- Proactive settings require separate assessment of when models should issue alerts without complete video evidence.
- Metrics for responsiveness and post-evidence stability become necessary to judge suitability for streaming medical tasks.
Where Pith is reading between the lines
- Similar time-bounded benchmarks applied to non-medical video tasks could expose parallel gaps in general video models.
- The design may push training approaches that build explicit timing awareness into vision-language models.
- Extending the proactive alert task to additional data types could probe broader real-world decision systems.
Load-bearing premise
The four temporal settings and the 22 chosen datasets accurately capture the timing and decision requirements of real clinical video streams.
What would settle it
Finding no marked performance drop for models in the streaming or proactive settings relative to retrospective offline evaluation on MedStreamBench would indicate the claimed gap does not hold.
Figures
read the original abstract
Existing medical video benchmarks primarily evaluate whether a model produces the correct answer, but rarely assess whether it answers at the right time. In real clinical settings, AI systems must decide not only what to predict, but also when to answer, defer judgment, or proactively raise alerts. This creates a critical gap between benchmark evaluation and deployment requirements. We present MedStreamBench, a benchmark for time-aware medical video understanding. MedStreamBench integrates 22 medical datasets and 5,419 QA instances across four temporal settings: retrospective, present, future, and proactive. Unlike conventional benchmarks that assume full-video access, MedStreamBench restricts models to temporally bounded evidence windows and supports both single-turn and streaming evaluation. We further introduce a proactive monitoring setting that requires models to determine whether and when clinically relevant alerts should be triggered. Beyond answer correctness, MedStreamBench evaluates temporal behavior through responsiveness and post-evidence stability. Experiments on leading general-purpose and medical vision-language models reveal a substantial gap between offline recognition and temporally grounded decision-making, with performance dropping markedly in streaming and proactive settings. Our benchmark is available at https://huggingface.co/datasets/Venn2024/MedStreamBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MedStreamBench, a benchmark for time-aware medical video understanding that integrates 22 medical datasets into 5,419 QA instances. It defines four temporal settings—retrospective, present, future, and proactive—and evaluates models on single-turn and streaming modes, with additional metrics for responsiveness and post-evidence stability. Experiments on general-purpose and medical vision-language models demonstrate a substantial performance gap between offline recognition and temporally grounded decision-making in streaming and proactive settings.
Significance. Should the benchmark's temporal settings and dataset choices prove representative of clinical video streams, the work would be significant for identifying critical shortcomings in current models' ability to handle timing, deferral, and proactive alerting in medical contexts. The public release of the dataset on Hugging Face supports reproducibility and community use.
major comments (1)
- [Benchmark Design / Temporal Settings] The section describing the temporal settings and dataset integration states the four settings (retrospective, present, future, proactive) and the selection of 22 datasets but provides no clinician review, deployment-log comparison, or sensitivity analysis on evidence windows and alert triggers. This assumption is load-bearing for the central claim that the observed performance drops reflect genuine clinical shortfalls rather than benchmark-construction artifacts.
minor comments (1)
- [Abstract] The abstract reports 5,419 QA instances but does not break down their distribution across the four temporal settings or 22 source datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the benchmark design. We address the major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Benchmark Design / Temporal Settings] The section describing the temporal settings and dataset integration states the four settings (retrospective, present, future, proactive) and the selection of 22 datasets but provides no clinician review, deployment-log comparison, or sensitivity analysis on evidence windows and alert triggers. This assumption is load-bearing for the central claim that the observed performance drops reflect genuine clinical shortfalls rather than benchmark-construction artifacts.
Authors: We agree that direct clinician review and deployment-log comparisons would strengthen claims of clinical representativeness. The four temporal settings are derived from the native temporal structures and annotation protocols of the 22 source medical datasets (e.g., procedure phases in surgical videos, event timing in endoscopic and ultrasound streams), which themselves stem from clinical data collection. To address the concern about potential construction artifacts, the revised manuscript will include a new sensitivity analysis varying evidence-window lengths and alert-trigger thresholds across a range of clinically plausible values, demonstrating that the reported performance gaps between offline and streaming/proactive modes remain consistent. We will also add an explicit limitations paragraph discussing the absence of new clinician validation. revision: partial
Circularity Check
No circularity: benchmark definition and empirical evaluation are self-contained
full rationale
The paper introduces MedStreamBench by defining four temporal settings (retrospective, present, future, proactive) and aggregating 22 datasets into 5,419 QA instances, then runs standard model evaluations to report performance drops. No equations, fitted parameters, predictions, or first-principles derivations are present. The central claim (performance gap) follows directly from applying existing VLMs to the newly constructed test cases; it does not reduce to any self-citation chain, ansatz, or renaming of prior outputs. The benchmark construction itself is the contribution and is not claimed to be derived from the results it produces.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MedHorizon: Towards Long-context Medical Video Understanding in the Wild
Bodong Du, Bowen Liu, Yang Yu, Xinpeng Ding, Zhiheng Wu, Shuning Wang, Shuo Nie, Naiming Liu, Qifeng Chen, Yangqiu Song, et al. Medhorizon: Towards long-context medical video understanding in the wild. arXiv preprint arXiv:2605.06537, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video- MME : The first-ever comprehensive evaluation benchmark of multi-modal LLM s in video analysis. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SurgOnAir: Hierarchy-Aware Real-Time Surgical Video Commentary
Jingyi He, Yue Zhou, Long Bai, Kun Yuan, Nassir Navab, and Yuan Bi. Surgonair: Hierarchy-aware real-time surgical video commentary. arXiv preprint arXiv:2605.21132, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Runlong He, Mengya Xu, Adrito Das, Danyal Z. Khan, Sophia Bano, Hani J. Marcus, Danail Stoyanov, Matthew J. Clarkson, and Mobarakol Islam. PitVQA : Image-grounded text embedding LLM for visual question answering in pituitary surgery. In Medical Image Computing and Computer Assisted Intervention (MICCAI), pages 488--498. Springer Nature Switzerland, 2024. ...
-
[6]
arXiv preprint arXiv:2510.08668 (2025)
Songtao Jiang, Yuan Wang, Sibo Song, Tianxiang Hu, Chenyi Zhou, Bin Pu, Yan Zhang, Zhibo Yang, Yang Feng, Joey Tianyi Zhou, et al. Hulu-med: A transparent generalist model towards holistic medical vision-language understanding. arXiv preprint arXiv:2510.08668, 2025 a
-
[7]
Omniv-med: Scaling medical vision-language model for universal visual understanding
Songtao Jiang, Yuan Wang, Sibo Song, Yan Zhang, Zijie Meng, Bohan Lei, Jian Wu, Jimeng Sun, and Zuozhu Liu. Omniv-med: Scaling medical vision-language model for universal visual understanding. arXiv preprint arXiv:2504.14692, 2025 b
-
[8]
Llava-surg: towards multimodal surgical assistant via structured surgical video learning
Jiajie Li, Garrett Skinner, Gene Yang, Brian R Quaranto, Steven D Schwaitzberg, Peter CW Kim, and Jinjun Xiong. Llava-surg: towards multimodal surgical assistant via structured surgical video learning. arXiv preprint arXiv:2408.07981, 2024
-
[9]
Surgpub-video: A comprehensive surgical video framework for enhanced surgical intelligence in vision-language model
Yaoqian Li, Xikai Yang, Dunyuan Xu, Yang Yu, Litao Zhao, Xiaowei Hu, Jinpeng Li, and Pheng-Ann Heng. Surgpub-video: A comprehensive surgical video framework for enhanced surgical intelligence in vision-language model. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6628--6635, 2026
2026
-
[10]
Yifei Li, Junbo Niu, Ziyang Miao, Chunjiang Ge, Yuanhang Zhou, Qihao He, Xiaoyi Dong, Haodong Duan, Shuangrui Ding, Rui Qian, Pan Zhang, Yuhang Zang, Yuhang Cao, Jiaqi Wang, and Dahua Lin. OVO -bench: How far is your video- LLM s from real-world online video understanding? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio...
-
[11]
arXiv preprint arXiv:2411.03628 , year=
Junming Lin, Zheng Fang, Chi Chen, Zihao Wan, Fuwen Luo, Peng Li, Yang Liu, and Maosong Sun. StreamingBench : Assessing the gap for MLLM s to achieve streaming video understanding. arXiv preprint arXiv:2411.03628, 2024
-
[12]
CholecTriplet2021 : A benchmark challenge for surgical action triplet recognition
Chinedu Innocent Nwoye, Tong Yu, Saurav Sharma, Aditya Murali, Deepak Alapatt, Armine Vardazaryan, et al. CholecTriplet2021 : A benchmark challenge for surgical action triplet recognition. Medical Image Analysis, 86: 0 102803, 2023. doi:10.1016/j.media.2023.102803
-
[13]
Lalithkumar Seenivasan, Mobarakol Islam, Adithya K. Krishna, and Hongliang Ren. Surgical- VQA : Visual question answering in surgical scenes using transformer. In Medical Image Computing and Computer Assisted Intervention (MICCAI), pages 33--43. Springer Nature Switzerland, 2022. doi:10.1007/978-3-031-16449-1_4
-
[14]
Pia H. Smedsrud, Vajira Thambawita, Steven A. Hicks, Henrik Gjestang, Oda Olsen Nedrejord, Espen N ss, Hanna Borgli, Debesh Jha, Tor Jan Derek Berstad, Sigrun L. Eskeland, Mathias Lux, H vard Espeland, Andreas Petlund, Duc Tien Dang Nguyen, Enrique Garcia-Ceja, Dag Johansen, Peter T. Schmidt, Ervin Toth, Hugo L. Hammer, Thomas de Lange, Michael A. Riegler...
-
[15]
The TUM LapChole dataset for the M2CAI 2016 workflow challenge
Ralf Stauder, Daniel Ostler, Michael Kranzfelder, Sebastian Koller, Hubertus Feu ner, and Nassir Navab. The TUM LapChole dataset for the M2CAI 2016 workflow challenge. Technical report, Technical University of Munich, 2016. arXiv:1610.09278
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
V2t-cot: From vision to text chain-of-thought for medical reasoning and diagnosis
Yuan Wang, Jiaxiang Liu, Shujian Gao, Bin Feng, Zhihang Tang, Xiaotang Gai, Jian Wu, and Zuozhu Liu. V2t-cot: From vision to text chain-of-thought for medical reasoning and diagnosis. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 658--668. Springer, 2025
2025
-
[18]
Beyond n-grams: A hierarchical reward learning framework for clinically-aware medical report generation
Yuan Wang, Shujian Gao, Jiaxiang Liu, Songtao Jiang, Xia Haoxiang, Xiaotian Zhang, Zhaolu Kang, Yemin Wang, and Zuozhu Liu. Beyond n-grams: A hierarchical reward learning framework for clinically-aware medical report generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33719--33727, 2026
2026
-
[19]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. LongVideoBench : A benchmark for long-context interleaved video-language understanding. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024. arXiv:2407.15754
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.