Latent Visual Diffusion Reasoning with Monte Carlo Tree Search
Pith reviewed 2026-06-29 04:54 UTC · model grok-4.3
The pith
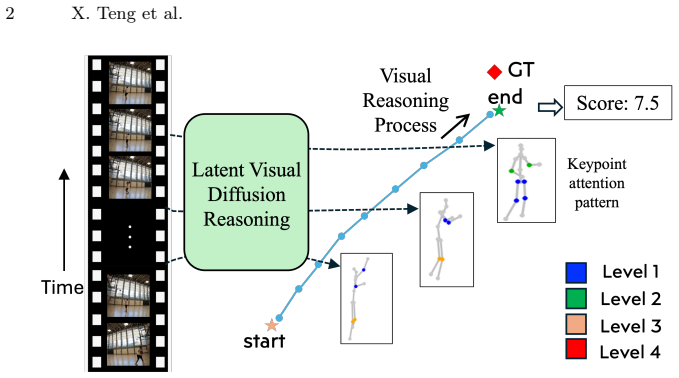
LVDR combines keypoint-guided Monte Carlo Tree Search with latent diffusion to assess skills while generating explicit visual reasoning trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
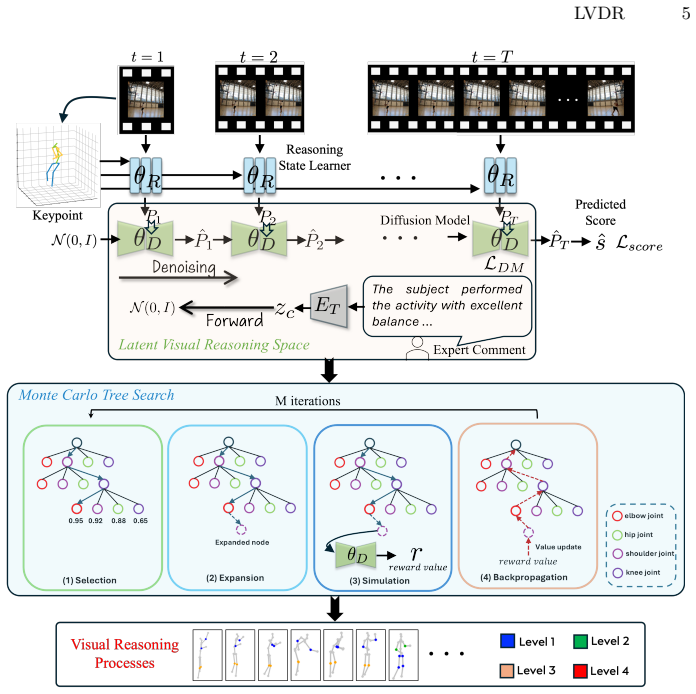
LVDR integrates keypoint-guided Monte Carlo Tree Search to model and visualize the latent visual reasoning process, producing more accurate skill assessments together with the critical visual reasoning sequences that contribute to the final evaluation.
What carries the argument
Keypoint-guided Monte Carlo Tree Search operating in latent diffusion space, which explores and selects reasoning trajectories guided by detected keypoints to simulate progressive visual judgment.
If this is right
- Skill assessment models can output not only a score but also a traceable sequence of visual decisions leading to that score.
- The same framework applies across multiple domains including sports performance and surgical procedure evaluation.
- Interpretability is achieved without sacrificing competitive accuracy on standard quantitative benchmarks.
- Critical reasoning sequences uncovered by the method can highlight which visual elements most influence the final judgment.
Where Pith is reading between the lines
- If the trajectories align with human reasoning, the method could support training tools that show novices exactly where expert judges focus their attention.
- The latent-space search approach might extend to other tasks that require both a decision and an explanation of the visual steps that produced it.
- Replacing or augmenting the keypoint guidance with other forms of structural prior could test how much the current performance depends on that particular cue.
Load-bearing premise
The generated MCTS trajectories in latent space correspond to the actual visual reasoning humans use when judging skill performance.
What would settle it
A direct comparison in which human experts articulate their own reasoning sequences on the same videos and the LVDR trajectories diverge on the majority of critical steps identified by the experts.
Figures

read the original abstract
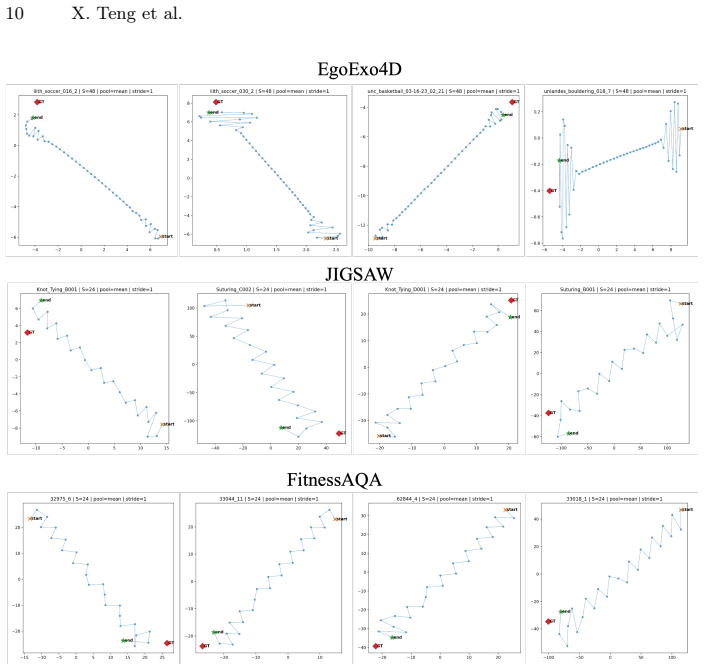
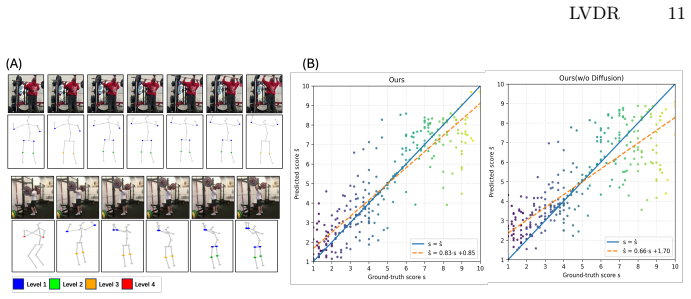
Analyzing fine-grained skill activities (e.g., sports, surgery) requires not only recognizing visual patterns but also performing step-by-step visual reasoning that leads to the final judgment. While recent advances in action quality assessment have achieved remarkable progress in evaluating performance, existing models remain black boxes, where they lack the ability to explicitly reveal the reasoning processes underlying their judgments. To address this limitation, we propose Latent Visual Diffusion Reasoning (LVDR), a novel framework that integrates keypoint-guided Monte Carlo Tree Search (MCTS) to model and visualize the latent visual reasoning process. LVDR not only produces more accurate skill assessments but also uncovers the critical visual reasoning sequences that contribute to the final evaluation. Extensive experiments across four datasets spanning diverse sports and surgical domains demonstrate that LVDR achieves competitive quantitative performance while providing interpretable visual reasoning trajectories leading to the final predictions. Source codes and models can be found through the following link: https://github.com/XiruiTeng/LVDR_Official.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Latent Visual Diffusion Reasoning (LVDR), a framework integrating keypoint-guided Monte Carlo Tree Search (MCTS) into a latent diffusion model to perform step-by-step visual reasoning for fine-grained action quality assessment in sports and surgical domains. It claims that LVDR yields competitive quantitative performance on four datasets while also generating interpretable visual reasoning trajectories that reveal the sequences underlying final skill judgments.
Significance. If the generated MCTS trajectories can be shown to align with human expert reasoning, the approach would meaningfully advance explainable models for action quality assessment by addressing the black-box limitation of prior work; the combination of diffusion priors with search-based trajectory modeling in latent space is a plausible technical direction, though its value depends on validation of the interpretability component.
major comments (2)
- [Abstract and Experiments] Abstract and §4 (Experiments): the claim that LVDR 'uncovers the critical visual reasoning sequences' and supplies 'interpretable visual reasoning trajectories' is load-bearing for the paper's contribution, yet the manuscript reports only aggregate accuracy metrics across datasets and provides no human-expert annotations, inter-rater agreement scores, or ablation studies correlating MCTS rollouts with documented human reasoning errors or attention patterns.
- [§3.2] §3.2 (MCTS formulation): the keypoint-guided search heuristic is presented as recovering human-like visual reasoning, but no analysis demonstrates that the latent-space trajectories are not simply artifacts of the diffusion prior and the chosen reward function; without a concrete test (e.g., comparison against eye-tracking or think-aloud protocols), the faithfulness assumption remains untested.
minor comments (2)
- [Abstract] The GitHub link is provided but the manuscript does not specify which quantitative tables or figures correspond to the four datasets, making it difficult to assess the scale of the reported gains.
- [§3] Notation for the latent diffusion process and the MCTS value function could be unified in a single table to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating the interpretability claims. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and §4 (Experiments): the claim that LVDR 'uncovers the critical visual reasoning sequences' and supplies 'interpretable visual reasoning trajectories' is load-bearing for the paper's contribution, yet the manuscript reports only aggregate accuracy metrics across datasets and provides no human-expert annotations, inter-rater agreement scores, or ablation studies correlating MCTS rollouts with documented human reasoning errors or attention patterns.
Authors: We agree that the manuscript lacks direct human validation such as expert annotations or eye-tracking comparisons, which would provide stronger evidence for the trajectories aligning with human reasoning. The current work shows that the MCTS procedure generates explicit step-by-step trajectories in latent space that are visualized and tied to the final skill assessment. To address the concern, we will revise the abstract, §1, and §5 to qualify the language (e.g., 'generates candidate visual reasoning trajectories' rather than 'uncovers the critical visual reasoning sequences') and add a limitations paragraph noting the absence of human-subject validation. We will also include additional qualitative examples of trajectories. We cannot introduce new human annotations or inter-rater studies without further data collection. revision: partial
-
Referee: [§3.2] §3.2 (MCTS formulation): the keypoint-guided search heuristic is presented as recovering human-like visual reasoning, but no analysis demonstrates that the latent-space trajectories are not simply artifacts of the diffusion prior and the chosen reward function; without a concrete test (e.g., comparison against eye-tracking or think-aloud protocols), the faithfulness assumption remains untested.
Authors: The keypoint-guided heuristic restricts node expansion to regions around detected keypoints, and the reward combines diffusion reconstruction consistency with action-quality prediction. This design choice is intended to focus search on task-relevant visual elements rather than arbitrary diffusion artifacts. We will add an ablation in §4 that disables keypoint guidance and reports the resulting change in both accuracy and trajectory coherence. Nevertheless, without external human data we cannot empirically rule out that some trajectories reflect model priors; we will therefore add a short discussion of this assumption in the revised §3.2. revision: partial
- Direct empirical validation that MCTS trajectories match human expert reasoning (via eye-tracking, think-aloud protocols, or annotated reasoning errors), as the submitted study contains no such human-subject data.
Circularity Check
No circularity in LVDR framework or claims
full rationale
The paper introduces LVDR as an integration of keypoint-guided MCTS into a latent diffusion model for producing skill assessments and interpretable trajectories. No equations, derivations, fitted parameters, or uniqueness theorems appear in the abstract or description. Claims rest on experimental results across four datasets rather than any self-referential reduction or self-citation chain. The central premise (MCTS trajectories in latent space) is presented as a modeling choice, not derived from or equivalent to its inputs by construction. This matches the default expectation of a non-circular method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
Ashutosh, K., Grauman, K.: Learning skill-attributes for transferable assessment in video. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[2]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ashutosh, K., Nagarajan, T., Pavlakos, G., Kitani, K., Grauman, K.: Expertaf: Expert actionable feedback from video. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 13582–13594 (2025)
2025
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report (2025),https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: European conference on computer vision
Bai, Y., Zhou, D., Zhang, S., Wang, J., Ding, E., Guan, Y., Long, Y., Wang, J.: Action quality assessment with temporal parsing transformer. In: European conference on computer vision. pp. 422–438. Springer (2022) 16 X. Teng et al
2022
-
[5]
In: International conference on computers and games
Coulom, R.: Efficient selectivity and backup operators in monte-carlo tree search. In: International conference on computers and games. pp. 72–83. Springer (2006)
2006
-
[6]
arXiv preprint arXiv:2408.11687 (2024)
Dong, X., Liu, X., Li, W., Adeyemi-Ejeye, A., Gilbert, A.: Interpretable long-term action quality assessment. arXiv preprint arXiv:2408.11687 (2024)
-
[7]
In: MICCAI workshop: M2cai
Gao, Y., Vedula, S.S., Reiley, C.E., Ahmidi, N., Varadarajan, B., Lin, H.C., Tao, L., Zappella, L., Béjar, B., Yuh, D.D., et al.: Jhu-isi gesture and skill assessment working set (jigsaws): A surgical activity dataset for human motion modeling. In: MICCAI workshop: M2cai. vol. 3, p. 3 (2014)
2014
-
[8]
google / technology / google - deepmind/gemini-model-thinking-updates-march-2025(2025)
Google DeepMind: Gemini 2.5.https : / / blog . google / technology / google - deepmind/gemini-model-thinking-updates-march-2025(2025)
2025
-
[9]
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., Byrne, E., Chavis, Z., Chen, J., Cheng, F., Chu, F.J., Crane, S., Dasgupta, A., Dong, J., Escobar, M., Forigua, C., Gebreselasie, A., Haresh, S., Huang, J., Islam, M.M., Jain, S., Khirodkar, R., Kukreja, D., Liang, K.J., Liu, J.W....
-
[10]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Han, R., Zhou, K., Chen, S., Atapour-Abarghouei, A., Shum, H.P.: Caflow: En- hancing long-term action quality assessment with causal counterfactual flow. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 8231–8241 (2026)
2026
-
[11]
In: European con- ference on machine learning
Kocsis, L., Szepesvári, C.: Bandit based monte-carlo planning. In: European con- ference on machine learning. pp. 282–293. Springer (2006)
2006
-
[12]
In: European Conference on Computer Vision
Majeedi, A., Gajjala, V.R., GNVV, S.S.S.N., Li, Y.: Rica^ 2: Rubric-informed, calibrated assessment of actions. In: European Conference on Computer Vision. pp. 143–161. Springer (2024)
2024
-
[13]
In: Proceedings of the 28th International Conference on Intelligent User Interfaces
Matsuyama, H., Kawaguchi, N., Lim, B.Y.: Iris: Interpretable rubric-informed seg- mentation for action quality assessment. In: Proceedings of the 28th International Conference on Intelligent User Interfaces. pp. 368–378 (2023)
2023
-
[14]
In: Proceedings of the IEEE/CVF Con- ference on computer vision and pattern recognition
Okamoto, L., Parmar, P.: Hierarchical neurosymbolic approach for comprehensive and explainable action quality assessment. In: Proceedings of the IEEE/CVF Con- ference on computer vision and pattern recognition. pp. 3204–3213 (2024)
2024
-
[15]
OpenAI: Gpt-4o.https://platform.openai.com/docs/models(2024)
2024
-
[16]
In: European Conference on Com- puter Vision
Parmar, P., Gharat, A., Rhodin, H.: Domain knowledge-informed self-supervised representations for workout form assessment. In: European Conference on Com- puter Vision. pp. 105–123. Springer (2022)
2022
-
[17]
In: Proceedings of the 9th ACM multimedia systems conference
Schoeffmann, K., Taschwer, M., Sarny, S., Münzer, B., Primus, M.J., Putzgruber, D.: Cataract-101: video dataset of 101 cataract surgeries. In: Proceedings of the 9th ACM multimedia systems conference. pp. 421–425 (2018)
2018
-
[18]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020) LVDR 17
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[19]
Wang, Y., Li, X., Yan, Z., He, Y., Yu, J., Zeng, X., Wang, C., Ma, C., Huang, H., Gao, J., Dou, M., Chen, K., Wang, W., Qiao, Y., Wang, Y., Wang, L.: Intern- video2.5: Empowering video mllms with long and rich context modeling (2025), https://arxiv.org/abs/2501.12386
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
In: European Conference on Com- puter Vision
Wang, Y., Xi, N., Meng, J., Yuan, J.: Interaction-centric spatio-temporal context reasoning for multi-person video hoi recognition. In: European Conference on Com- puter Vision. pp. 419–435. Springer (2024)
2024
-
[21]
IEEE Transactions on Circuits and Systems for Video Technology32(12), 8550–8561 (2022)
Xi, N., Meng, J., Yuan, J.: Forest graph convolutional network for surgical ac- tion triplet recognition in endoscopic videos. IEEE Transactions on Circuits and Systems for Video Technology32(12), 8550–8561 (2022)
2022
-
[22]
In: Proceedings of the 31st ACM International Conference on Multimedia
Xi, N., Meng, J., Yuan, J.: Chain-of-look prompting for verb-centric surgical triplet recognition in endoscopic videos. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 5007–5016 (2023)
2023
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Xi, N., Meng, J., Yuan, J.: Open set video hoi detection from action-centric chain- of-look prompting. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3079–3089 (2023)
2023
-
[24]
In: European Conference on Computer Vision
Xu, H., Ke, X., Li, Y., Xu, R., Wu, H., Lin, X., Guo, W.: Vision-language action knowledge learning for semantic-aware action quality assessment. In: European Conference on Computer Vision. pp. 423–440. Springer (2024)
2024
-
[25]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xu, J., Rao, Y., Yu, X., Chen, G., Zhou, J., Lu, J.: Finediving: A fine-grained dataset for procedure-aware action quality assessment. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2949–2958 (2022)
2022
- [26]
-
[27]
In: European Conference on Computer Vision
Yun, W., Qi, M., Peng, F., Ma, H.: Semi-supervised teacher-reference-student ar- chitecture for action quality assessment. In: European Conference on Computer Vision. pp. 161–178. Springer (2024)
2024
-
[28]
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data (2025),https://arxiv.org/abs/2410. 02713
2025
-
[29]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Zhao, S., Wang, Z., Luan, T., Jia, J., Zhu, W., Luo, J., Yuan, J., Xi, N.: Pp- motion: Physical-perceptual fidelity evaluation for human motion generation. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 6840– 6849 (2025)
2025
- [30]
-
[31]
IEEE transactions on image processing34, 3718–3732 (2025)
Zhou, K., Shum, H.P., Li, F.W., Zhang, X., Liang, X.: Phi: Bridging domain shift in long-term action quality assessment via progressive hierarchical instruction. IEEE transactions on image processing34, 3718–3732 (2025)
2025
-
[32]
Zhou,K.,Wang,L.,Zhang,X.,Shum,H.P.H.,Li,F.W.B.,Li,J.,Liang,X.:MAGR: Manifold-Aligned Graph Regularization for Continual Action Quality Assessment, p. 375–392. Springer Nature Switzerland (Nov 2024).https://doi.org/10.1007/ 978-3-031-73247-8_22,http://dx.doi.org/10.1007/978-3-031-73247-8_22
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.