CALIBER: Calibrating Confidence Before and After Reasoning in Language Models
Pith reviewed 2026-06-26 00:17 UTC · model grok-4.3
The pith
Reasoning models achieve better calibrated confidence by supervising pre-thinking estimates with prompt success probability and post-answer estimates with answer correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
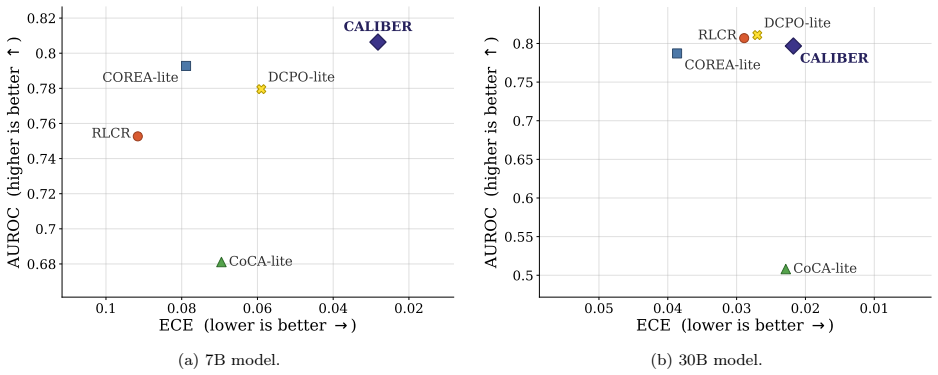
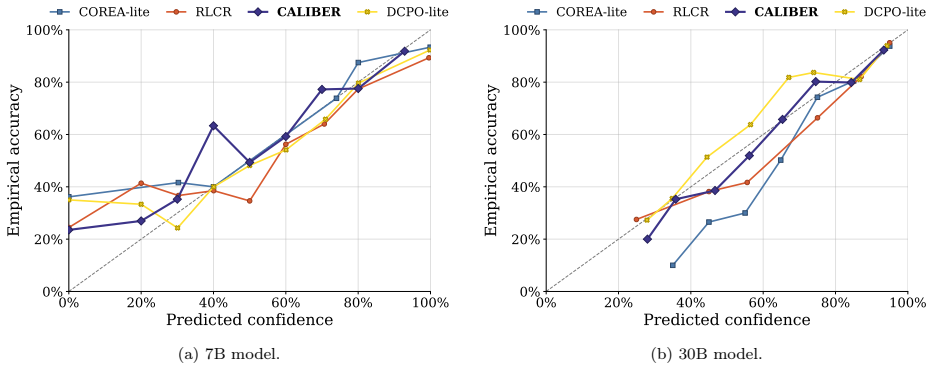
CALIBER elicits both pre-reasoning and post-reasoning confidence estimates in language models. Pre-reasoning estimates are supervised by whether the prompt is solvable, while post-reasoning estimates are supervised by whether the generated answer is correct. This unified protocol reduces Expected Calibration Error by 52.5% over the strongest single-confidence baseline on BigMathDigits for the 7B model and achieves the best Brier score and AUROC.
What carries the argument
The position-target alignment mechanism, which matches the supervision target for each confidence estimate to the information state at the time it is elicited.
If this is right
- Reduces Expected Calibration Error substantially on in-distribution math tasks while staying close to peak accuracy.
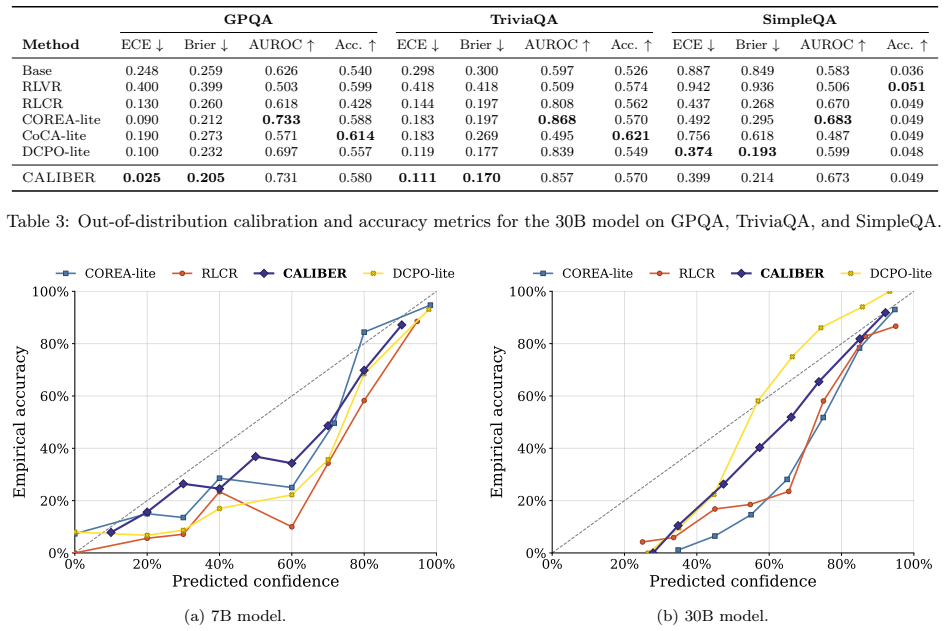
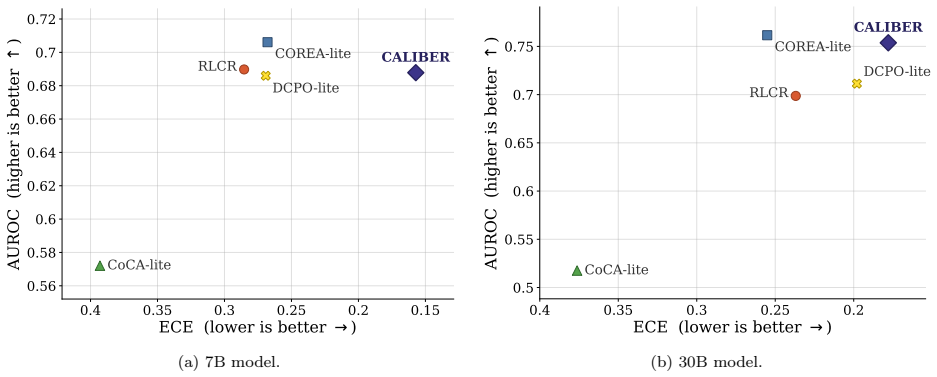
- Achieves best calibration metrics on out-of-distribution benchmarks like GPQA and TriviaQA.
- Shows consistent calibration improvements under distribution shift compared to single-estimate methods.
- Scales to larger models while maintaining competitive performance in Brier score and AUROC.
Where Pith is reading between the lines
- The results suggest that ignoring the change in available information during reasoning limits calibration in standard approaches.
- Models may benefit from always producing two distinct confidence scores rather than one.
- Deployment in settings with shifting data distributions could see reliability gains from this two-stage supervision.
Load-bearing premise
That the appropriate target for supervising confidence is prompt-level success before reasoning and answer-level correctness after reasoning.
What would settle it
Running the same experiments but supervising both estimates with the same target, such as always using answer correctness, and finding no reduction or even an increase in calibration error on BigMathDigits.
Figures


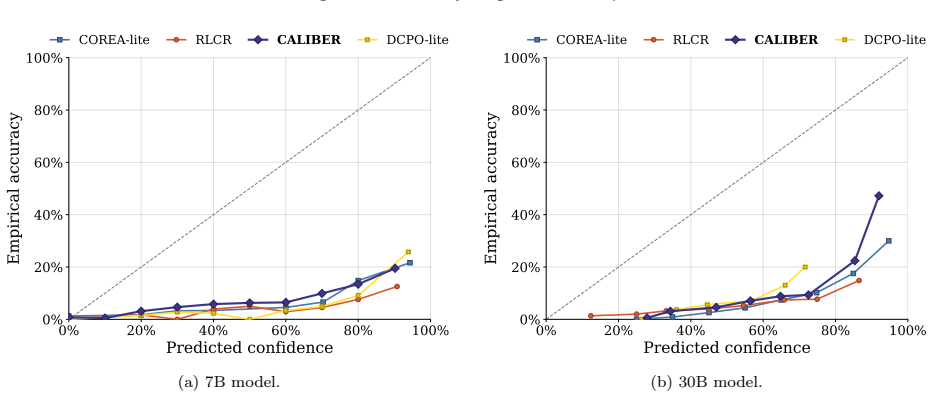
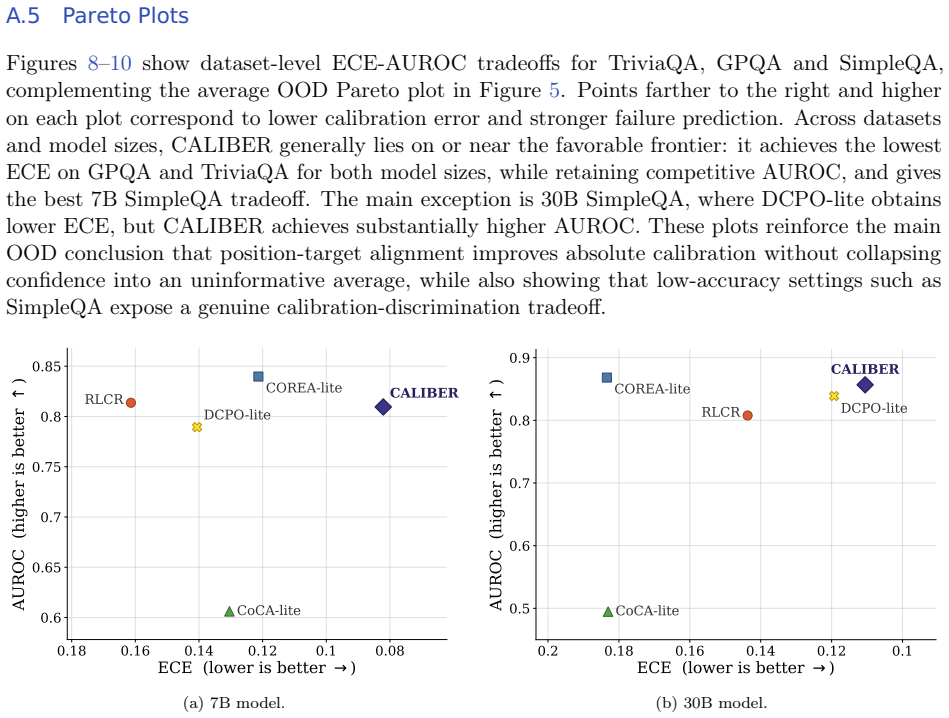

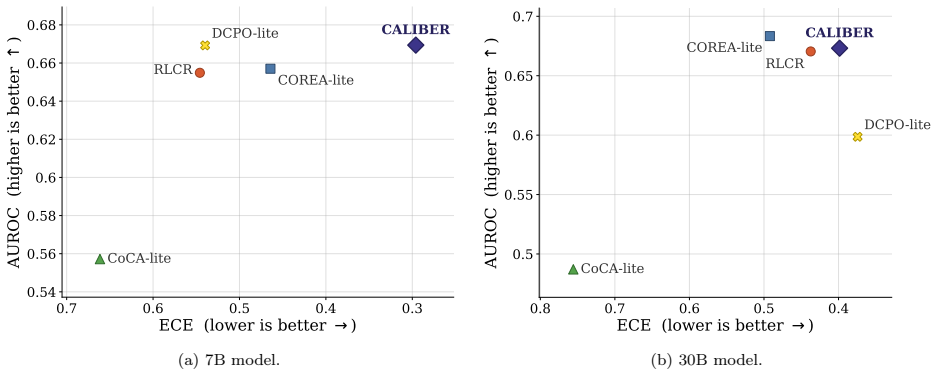
read the original abstract
Reasoning language models are increasingly asked not only to answer difficult questions, but also to estimate their likelihood of success. Existing methods typically elicit confidence only once: either before thinking or after answering. We argue that confidence in reasoning models is state-dependent: before thinking, confidence should estimate the chance of the model correctly solving the prompt, while after thinking it should predict whether the realized answer is likely to be correct. This distinction determines the appropriate supervision target: prompt-level success should supervise confidence estimates made after seeing the prompt, while individual answer-level correctness should supervise confidence estimates made after answering. We introduce CALIBER (Calibration Before and After Reasoning), which elicits both estimates and supervises each with the target matched to its information state. Under this unified protocol, CALIBER reduces Expected Calibration Error (ECE) by 52.5% over the strongest single-confidence baseline on BigMathDigits for the 7B model, while achieving the best Brier score and AUROC, and remains within 2.1 points of the best accuracy. Further, on a larger 30B model, CALIBER achieves the best ECE on BigMathDigits while remaining competitive in Brier score and AUROC. Out of distribution, it achieves the best ECE and Brier score on GPQA and TriviaQA, and remains competitive on SimpleQA. Ablations further show that this position-target alignment is most beneficial under distribution shift where it consistently reduces calibration error across all out-of-distribution benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CALIBER, which elicits separate pre-reasoning and post-reasoning confidence estimates in language models and supervises the former with prompt-level success probability and the latter with answer-level correctness. It reports that this matched-supervision protocol yields a 52.5% reduction in Expected Calibration Error over the strongest single-confidence baseline on BigMathDigits (7B model), best-in-class Brier score and AUROC, accuracy within 2.1 points of the best, and strong OOD performance on GPQA, TriviaQA, and SimpleQA, with ablations indicating the alignment is especially helpful under distribution shift.
Significance. If the reported gains prove robust, the work supplies a concrete, state-aware protocol for confidence elicitation that improves calibration without sacrificing accuracy and is particularly effective out-of-distribution. The explicit ablations linking the position-target alignment to OOD gains constitute a reproducible empirical contribution that future reasoning-model calibration studies can directly build upon.
minor comments (3)
- The abstract and §4 should explicitly state the number of random seeds and the precise data-split protocol used for the BigMathDigits, GPQA, TriviaQA, and SimpleQA evaluations so that the 52.5% ECE figure can be reproduced.
- Figure 3 (or the corresponding ablation table) would benefit from error bars or a statistical test comparing the aligned vs. misaligned supervision variants under each OOD shift.
- Notation for the two supervision targets (prompt-level success probability vs. answer-level correctness) should be introduced once in §3 with a short equation or pseudocode block to avoid repeated prose definitions later.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of CALIBER, the recognition of its empirical contributions on position-target alignment, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; empirical protocol with benchmark results
full rationale
The paper introduces CALIBER as a protocol for eliciting and supervising two state-dependent confidence estimates (pre- and post-reasoning) with matched targets (prompt-level success probability vs. answer-level correctness). All reported gains are empirical performance metrics (ECE reductions, Brier scores, AUROC) measured on fixed external benchmarks such as BigMathDigits, GPQA, TriviaQA and SimpleQA. No equations, fitted parameters, or self-citations are presented that reduce the claimed improvements to a definitional identity or to a quantity computed from the same fitted values. The central claim therefore rests on observable benchmark outcomes rather than on any self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387,
-
[2]
David Bani-Harouni, Chantal Pellegrini, Paul Stangel, Ege Özsoy, Kamilia Zaripova, Nassir Navab, and Matthias Keicher. Rewarding doubt: A reinforcement learning approach to calibrated confidence expression of large language models.arXiv preprint arXiv:2503.02623,
-
[3]
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.arXiv preprint arXiv:2502.11028,
-
[4]
Command a: An enterprise-ready large language model.arXiv preprint arXiv:2504.00698,
Team Cohere, Arash Ahmadian, Marwan Ahmed, Jay Alammar, Milad Alizadeh, Yazeed Alnumay, 15 Sophia Althammer, Arkady Arkhangorodsky, Viraat Aryabumi, Dennis Aumiller, et al. Command a: An enterprise-ready large language model.arXiv preprint arXiv:2504.00698,
-
[5]
Beyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training lms to reason about their uncertainty.arXiv preprint arXiv:2507.16806,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A survey of confidence estimation and calibration in large language models
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 6577–6595,
2024
-
[7]
Sophia Hager, David Mueller, Kevin Duh, and Nicholas Andrews. Uncertainty distillation: Teaching language models to express semantic confidence.arXiv preprint arXiv:2503.14749,
-
[8]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation.arXiv preprint arXiv:2302.09664,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
How do LLMs Compute Verbal Confidence
Dharshan Kumaran, Arthur Conmy, Federico Barbero, Simon Osindero, Viorica Patraucean, and Petar Velickovic. How do llms compute verbal confidence.arXiv preprint arXiv:2603.17839,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. Tulu 3: Pushing frontiers in open language model post-training.arXiv preprint arXiv:2411.15124,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Taming overconfidence in llms: Reward calibration in RLHF
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming overconfidence in llms: Reward calibration in RLHF. InInternational Conference on Learning Representations, volume 2025, pp. 16484–16517,
2025
-
[13]
Confidence Before Answering: A Paradigm Shift for Efficient LLM Uncertainty Estimation
Changcheng Li, Jiancan Wu, Hengheng Zhang, Zhengsu Chen, Guo An, Junxiang Qiu, Xiang Wang, and Qi Tian. Confidence before answering: A paradigm shift for efficient llm uncertainty estimation.arXiv preprint arXiv:2603.05881, 2026a. Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verball...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zhengzhao Ma, Xueru Wen, Boxi Cao, Yaojie Lu, Hongyu Lin, Jinglin Yang, Min He, Xianpei Han, and Le Sun. Decoupling reasoning and confidence: Resurrecting calibration in reinforcement learning from verifiable rewards.arXiv preprint arXiv:2603.09117,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs. In International Conference on Learning Representations, volume 2024, pp. 23650–23678,
2024
-
[19]
Sayself: Teaching LLMs to express confidence with self-reflective rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. Sayself: Teaching LLMs to express confidence with self-reflective rationales. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 5985–5998,
2024
-
[20]
17 A Appendix A.1 Training and Evaluation Details Table 5 summarizes the main training and evaluation settings used for the 7B and 30B experiments. Hyperparameter / setting V alue Shared training settings Calibration RL steps 500 Reward weights Equal Training batch size 2048 Rollouts per prompt during training 32 Max sequence length 16384 Model-specific t...
2048
-
[21]
Okay, let’s tackle this question:
Let me check: C10 = 1 11 20 10 . 20 10 is 184756, so 184756 divided by 11 is 16796.[. . . ]But wait, I should make sure that this applies here. The problem states that the chords do not share endpoints and do not intersect. That’s exactly the condition for Catalan numbers.[. . . ]SoC 10 is indeed 16796.” Q.A person contracted the flu, and after two rounds...
2009
-
[22]
Okay, let’s tackle this question:
Let me start by recalling what I know about this case.[. . . ]So the most likely scenario is that the user has the wrong year, but if I have to answer based on the given information, the correct answer would still be David Lee Roth, even though the year is incorrect. However, since the user specified 2009, maybe there’s a different person. Alternatively, ...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.