SCI-PRM: A Tool Aware Process Reward Model for Scientific Reasoning Verification
Pith reviewed 2026-06-28 06:35 UTC · model grok-4.3
The pith
Sci-PRM supplies step-level rewards for scientific reasoning by judging tool selection and execution accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
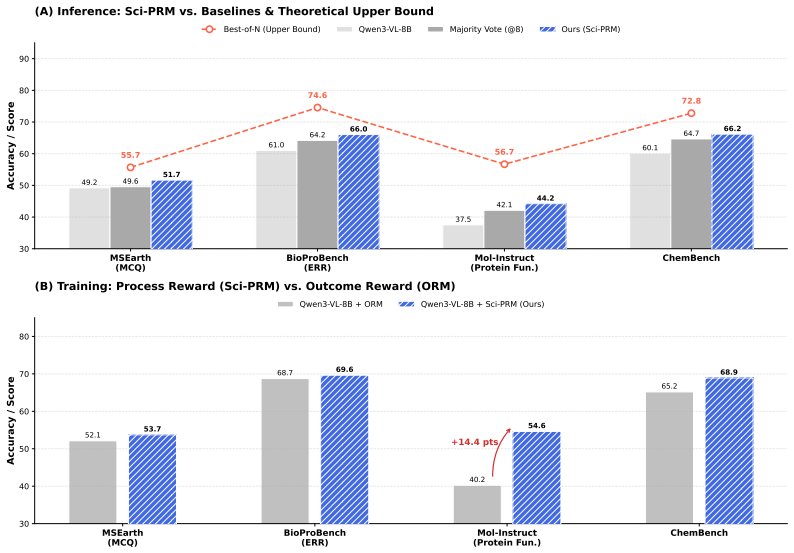
Training Sci-PRM on SCIPRM70K Chain-of-Tool trajectories produces a model that delivers fine-grained process rewards for tool selection, execution accuracy, and result interpretation in a single inference pass, supporting effective Best-of-N test-time scaling and dense reward signals during reinforcement learning that mitigate advantage disappearance.
What carries the argument
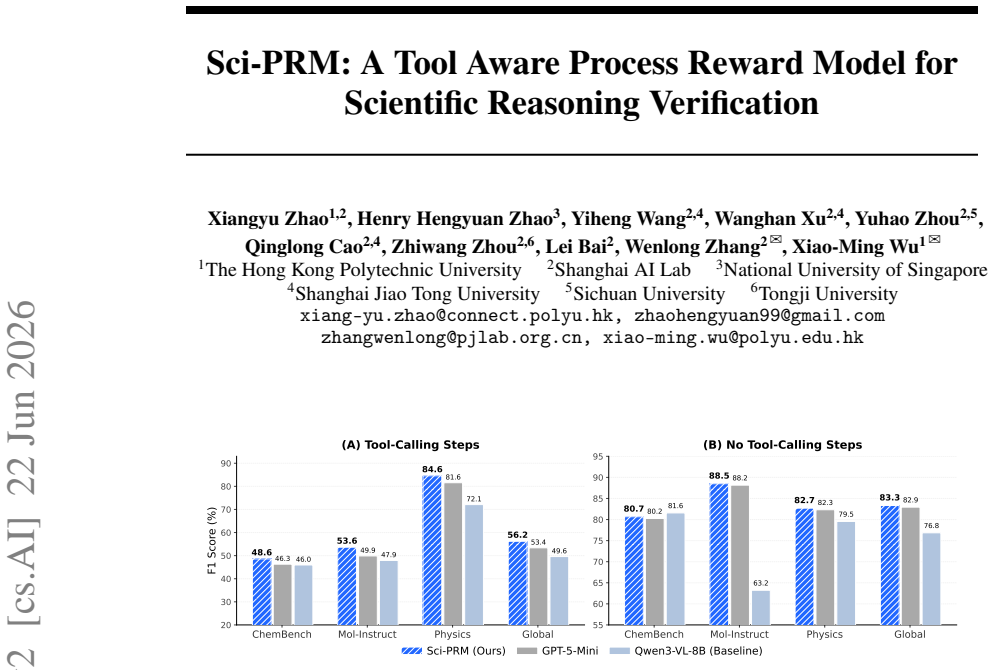
Sci-PRM, the tool-aware process reward model that evaluates each reasoning step including domain-specific tool executions.
Load-bearing premise
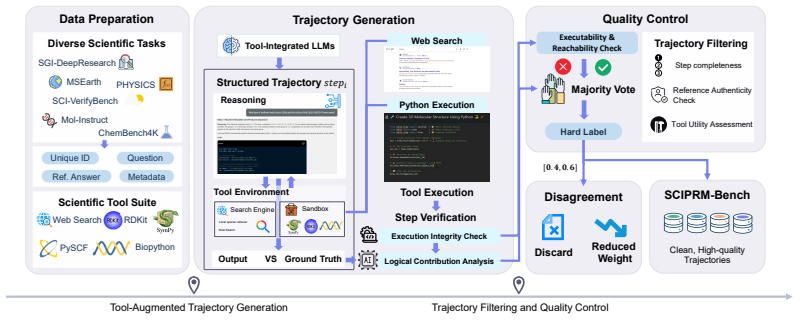
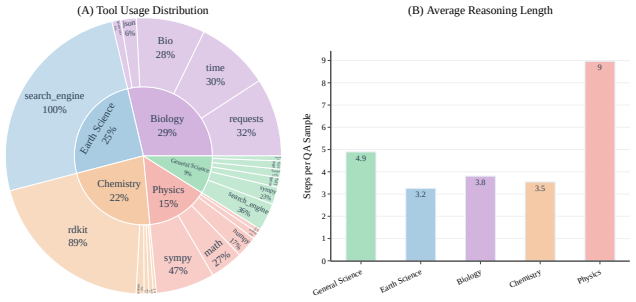
The SCIPRM70K dataset accurately captures the factual and tool-execution requirements of real scientific reasoning, and measured gains stem from the tool-aware process supervision rather than dataset scale or other training factors.
What would settle it
An independent scientific reasoning benchmark where Best-of-N selection or RL training with Sci-PRM shows no accuracy or convergence gain over a standard outcome reward model would falsify the central claim.
Figures

read the original abstract
While Process Reward Models (PRMs) have achieved remarkable success in mathematical reasoning, their application in complex scientific domains-such as biology, chemistry, and physics remains largely unexplored. Scientific problems demand not only logical rigor but also factual consistency and the precise usage of domain-specific tools, areas where current models often suffer from hallucinations and lack of verification. In this paper, we first construct SCIPRM70K, a large-scale dataset featuring Chain-of-Tool trajectories that explicitly interleave reasoning with the execution of scientific tools. Building upon this, we train an efficient reward model called Sci-PRM to provide fine-grained supervision on tool selection, execution accuracy, and result interpretation at each step in one inference. Experiments demonstrate that Sci-PRM significantly enhances foundation models in two key aspects: (1) it enables effective test-time scaling via Best-of-N selection; and (2) when integrated into Reinforcement Learning, it serves as a dense reward signal that mitigates the critical issue of advantage disappearance, allowing the model to break through existing performance ceilings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the construction of the SCIPRM70K dataset, which consists of Chain-of-Tool trajectories interleaving reasoning with scientific tool executions for domains like biology, chemistry, and physics. It then trains Sci-PRM, a process reward model designed to provide fine-grained supervision on tool selection, execution accuracy, and result interpretation in a single inference pass. The paper claims that this approach enables effective test-time scaling through Best-of-N selection and, when integrated into reinforcement learning as a dense reward signal, mitigates advantage disappearance to surpass existing performance ceilings in scientific reasoning tasks.
Significance. If the experimental claims are substantiated with proper controls, this work would extend process reward models from mathematical reasoning to complex scientific domains requiring factual consistency and tool usage. The creation of a large-scale dataset with explicit tool interleaving is a concrete contribution toward addressing hallucinations in tool-augmented reasoning.
major comments (2)
- [Abstract] Abstract: the assertion of significant enhancements from Best-of-N selection and RL integration supplies no quantitative results, baselines, ablation details, or error analysis, making it impossible to determine whether the data support the stated claims.
- [Experiments] Experiments section: no ablations are described that hold data volume, trajectory length, and base model fixed while varying only the presence of explicit tool interleaving, execution accuracy labels, and result interpretation signals; without such controls, gains could arise from increased supervision density or dataset curation effects rather than the claimed tool-aware mechanism.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of significant enhancements from Best-of-N selection and RL integration supplies no quantitative results, baselines, ablation details, or error analysis, making it impossible to determine whether the data support the stated claims.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report specific performance gains from Best-of-N selection and RL integration (with references to the baselines and error analysis already present in the experiments section) so that the claims can be evaluated at a high level. revision: yes
-
Referee: [Experiments] Experiments section: no ablations are described that hold data volume, trajectory length, and base model fixed while varying only the presence of explicit tool interleaving, execution accuracy labels, and result interpretation signals; without such controls, gains could arise from increased supervision density or dataset curation effects rather than the claimed tool-aware mechanism.
Authors: We acknowledge that the suggested controlled ablations are not present in the current experiments section. While our existing comparisons vary supervision type against fixed base models, they do not isolate tool interleaving and label granularity under the exact constraints noted. We will run and report the requested ablations (holding data volume, trajectory length, and base model fixed) and include the results in the revised experiments section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs a new dataset (SCIPRM70K with Chain-of-Tool trajectories) and trains an empirical reward model (Sci-PRM), then reports experimental outcomes on Best-of-N selection and RL integration. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citation chains appear in the abstract or described claims. The central results rest on external evaluation rather than reducing to inputs by construction, making this a standard empirical contribution with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scientific reasoning in biology, chemistry, and physics requires interleaved tool execution and factual verification at each step
Reference graph
Works this paper leans on
-
[1]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Gemini 3, 2025
Google. Gemini 3, 2025
2025
-
[3]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[4]
Bowman, He He, and Shi Feng
Jiaxin Wen, Ruiqi Zhong, Akbir Khan, Ethan Perez, Jacob Steinhardt, Minlie Huang, Samuel R. Bowman, He He, and Shi Feng. Language models learn to mislead humans via RLHF. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[5]
Reward hacking in reinforcement learning.lilianweng.github.io, Nov 2024
Lilian Weng. Reward hacking in reinforcement learning.lilianweng.github.io, Nov 2024
2024
-
[6]
Curing miracle steps in llm mathematical reasoning with rubric rewards, 2025
Youliang Yuan, Qiuyang Mang, Jingbang Chen, Hong Wan, Xiaoyuan Liu, Junjielong Xu, Jen tse Huang, Wenxuan Wang, Wenxiang Jiao, and Pinjia He. Curing miracle steps in llm mathematical reasoning with rubric rewards, 2025
2025
-
[7]
Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering, 2021
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically- labeled knowledge-enhanced dataset for medical visual question answering, 2021
2021
-
[8]
Chemllm: A chemical large language model, 2024
Di Zhang, Wei Liu, Qian Tan, Jingdan Chen, Hang Yan, Yuliang Yan, Jiatong Li, Weiran Huang, Xiangyu Yue, Dongzhan Zhou, Shufei Zhang, Mao Su, Hansen Zhong, Yuqiang Li, and Wanli Ouyang. Chemllm: A chemical large language model, 2024
2024
-
[9]
Physics: Benchmarking foundation models on university-level physics problem solving
Kaiyue Feng, Yilun Zhao, Yixin Liu, Tianyu Yang, Chen Zhao, John Sous, and Arman Cohan. Physics: Benchmarking foundation models on university-level physics problem solving. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 11717–11743, Vienna,...
2025
-
[10]
Msearth: A multimodal scientific dataset and benchmark for phenomena uncovering in earth science, 2025
Xiangyu Zhao, Wanghan Xu, Bo Liu, Yuhao Zhou, Fenghua Ling, Ben Fei, Xiaoyu Yue, Lei Bai, Wenlong Zhang, and Xiao-Ming Wu. Msearth: A multimodal scientific dataset and benchmark for phenomena uncovering in earth science, 2025
2025
-
[11]
Zhiwang Zhou, Yuandong Pu, Xuming He, Yidi Liu, Yixin Chen, Junchao Gong, Xiang Zhuang, Wanghan Xu, Qinglong Cao, Shixiang Tang, et al. Omni-weather: Unified multimodal foundation model for weather generation and understanding.arXiv preprint arXiv:2512.21643, 2025. 13
-
[12]
Peilin Feng, Zhutao Lv, Junyan Ye, Xiaolei Wang, Xinjie Huo, Jinhua Yu, Wanghan Xu, Wenlong Zhang, Lei Bai, Conghui He, et al. Earth-agent: Unlocking the full landscape of earth observation with agents.arXiv preprint arXiv:2509.23141, 2025
-
[13]
Suttle, Mengdi Wang, Amrit Singh Bedi, and Dinesh Manocha
Bhrij Patel, Souradip Chakraborty, Wesley A. Suttle, Mengdi Wang, Amrit Singh Bedi, and Dinesh Manocha. Aime: Ai system optimization via multiple llm evaluators, 2024
2024
-
[14]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[15]
Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, and Zhenru Zhang. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement, 2024
2024
-
[16]
Reasonflux-PRM: Trajectory-aware PRMs for long chain-of-thought reasoning in LLMs
Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. Reasonflux-PRM: Trajectory-aware PRMs for long chain-of-thought reasoning in LLMs. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[17]
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visualprm: An effective process reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291, 2025
-
[18]
The lessons of developing process reward models in mathe- matical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathe- matical reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, p...
2025
-
[19]
R- PRM: Reasoning-driven process reward modeling
Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, and Shujian Huang. R- PRM: Reasoning-driven process reward modeling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13438–13451, Suzhou, China, November 202...
2025
-
[20]
ToolRL: Reward is all tool learning needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru WANG, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. ToolRL: Reward is all tool learning needs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[21]
CodePRM: Execution feedback-enhanced process reward model for code generation
Qingyao Li, Xinyi Dai, Xiangyang Li, Weinan Zhang, Yasheng Wang, Ruiming Tang, and Yong Yu. CodePRM: Execution feedback-enhanced process reward model for code generation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Findings of the Association for Computational Linguistics: ACL 2025, pages 8169–8182, Vienna, Aus...
2025
-
[22]
Agentprm: Process reward models for llm agents via step-wise promise and progress, 2025
Zhiheng Xi, Chenyang Liao, Guanyu Li, Yajie Yang, Wenxiang Chen, Zhihao Zhang, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, Tao Ji, Tao Gui, Qi Zhang, and Xuanjing Huang. Agentprm: Process reward models for llm agents via step-wise promise and progress, 2025
2025
-
[23]
Portool: Tool-use llm training with rewarded tree, 2025
Feijie Wu, Weiwu Zhu, Yuxiang Zhang, Soumya Chatterjee, Jiarong Zhu, Fan Mo, Rodin Luo, and Jing Gao. Portool: Tool-use llm training with rewarded tree, 2025
2025
-
[24]
Sijie Zhao, Feng Liu, Xueliang Zhang, Hao Chen, Xinyu Gu, Zhe Jiang, Fenghua Ling, Ben Fei, Wenlong Zhang, Junjue Wang, et al. Openearth-agent: From tool calling to tool creation for open-environment earth observation.arXiv preprint arXiv:2603.22148, 2026
-
[25]
A self-evolving ai agent system accelerating the understanding of climate change and variability
Fenghua Ling, Zijie Guo, Jiong Wang, Wangxu Wei, Xiaoyu Yue, Zhe Jiang, Wanghan Xu, Jing-Jia Luo, Lijing Cheng, Yoo-Geun Ham, et al. A self-evolving ai agent system accelerating the understanding of climate change and variability. 2026. 14
2026
-
[26]
Wanghan Xu, Yuhao Zhou, Yifan Zhou, Qinglong Cao, Shuo Li, Jia Bu, Bo Liu, Yixin Chen, Xuming He, Xiangyu Zhao, et al. Probing scientific general intelligence of llms with scientist- aligned workflows.arXiv preprint arXiv:2512.16969, 2025
-
[27]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
-
[28]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning, 2025
Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, and Ji-Rong Wen. Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning, 2025
2025
-
[29]
CRITIC: Large language models can self-correct with tool-interactive critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. CRITIC: Large language models can self-correct with tool-interactive critiquing. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[30]
Lastras, Yara Rizk, and Pavan Kapanipathi
Mayank Agarwal, Ibrahim Abdelaziz, Kinjal Basu, Merve Unuvar, Luis A. Lastras, Yara Rizk, and Pavan Kapanipathi. Toolrm: Outcome reward models for tool-calling large language models, 2026
2026
-
[31]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022
2022
-
[32]
Solving math word problems with process- and outcome-based feedback, 2022
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback, 2022
2022
-
[33]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[34]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2024
-
[35]
Yiheng Wang, Yixin Chen, Shuo Li, Yifan Zhou, Bo Liu, Hengjian Gao, Jiakang Yuan, Jia Bu, Wanghan Xu, Yuhao Zhou, et al. Scievalkit: An open-source evaluation toolkit for scientific general intelligence.arXiv preprint arXiv:2512.22334, 2025
-
[36]
Hongwei Liu, Junnan Liu, Shudong Liu, Haodong Duan, Yuqiang Li, Mao Su, Xiaohong Liu, Guangtao Zhai, Xinyu Fang, Qianhong Ma, et al. Atlas: A high-difficulty, multidisciplinary benchmark for frontier scientific reasoning.arXiv preprint arXiv:2511.14366, 2025
-
[37]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[38]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning...
2024
-
[39]
Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets.Advances in Neural Information Processing Systems, 37:54463–54482, 2024
Zuxin Liu, Thai Hoang, Jianguo Zhang, Ming Zhu, Tian Lan, Juntao Tan, Weiran Yao, Zhiwei Liu, Yihao Feng, Rithesh RN, et al. Apigen: Automated pipeline for generating verifiable and diverse function-calling datasets.Advances in Neural Information Processing Systems, 37:54463–54482, 2024
2024
-
[40]
Yicheng Zou, Dongsheng Zhu, Lin Zhu, Tong Zhu, Yunhua Zhou, Peiheng Zhou, Xinyu Zhou, Dongzhan Zhou, Zhiwang Zhou, Yuhao Zhou, et al. Intern-s1-pro: Scientific multimodal foundation model at trillion scale.arXiv preprint arXiv:2603.25040, 2026
-
[41]
Jiyong Rao, Yicheng Qiu, Jiahui Zhang, Juntao Deng, Shangquan Sun, Fenghua Ling, Hao Chen, Nanqing Dong, Zhangyang Gao, Siqi Sun, et al. Scidatacopilot: An agentic data preparation framework for agi-driven scientific discovery.arXiv preprint arXiv:2602.09132, 2026
-
[42]
Internagent-1.5: A unified agentic framework for long-horizon autonomous scientific discovery
Shiyang Feng, Runmin Ma, Xiangchao Yan, Yue Fan, Yusong Hu, Songtao Huang, Shuaiyu Zhang, Zongsheng Cao, Tianshuo Peng, Jiakang Yuan, et al. Internagent-1.5: A unified agentic framework for long-horizon autonomous scientific discovery.arXiv preprint arXiv:2602.08990, 2026
-
[43]
Xiangru Tang, Wanghan Xu, Yujie Wang, Zijie Guo, Daniel Shao, Jiapeng Chen, Cixuan Zhang, Ziyi Wang, Lixin Zhang, Guancheng Wan, et al. Eigen-1: Adaptive multi-agent refinement with monitor-based rag for scientific reasoning.arXiv preprint arXiv:2509.21193, 2025
-
[44]
Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
Lei Bai, Zhongrui Cai, Yuhang Cao, Maosong Cao, Weihan Cao, Chiyu Chen, Haojiong Chen, Kai Chen, Pengcheng Chen, Ying Chen, et al. Intern-s1: A scientific multimodal foundation model.arXiv preprint arXiv:2508.15763, 2025
-
[45]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[46]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
2017
-
[47]
Sci-verifier: Scientific verifier with thinking.arXiv preprint arXiv:2509.24285, 2025
Shenghe Zheng, Chenyu Huang, Fangchen Yu, Junchi Yao, Jingqi Ye, Tao Chen, Yun Luo, Ning Ding, Lei Bai, Ganqu Cui, et al. Sci-verifier: Scientific verifier with thinking.arXiv preprint arXiv:2509.24285, 2025
-
[48]
Taolin Zhang, Maosong Cao, Alexander Lam, Songyang Zhang, and Kai Chen. Compassjudger- 2: Towards generalist judge model via verifiable rewards.arXiv preprint arXiv:2507.09104, 2025
-
[49]
Yin Fang, Xiaozhuan Liang, Ningyu Zhang, Kangwei Liu, Rui Huang, Zhuo Chen, Xiaohui Fan, and Huajun Chen. Mol-instructions: A large-scale biomolecular instruction dataset for large language models.arXiv preprint arXiv:2306.08018, 2023
-
[50]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Peng Kuang, Xiangxiang Wang, Wentao Liu, Jian Dong, and Kaidi Xu. Tim-prm: Verifying multimodal reasoning with tool-integrated prm.arXiv preprint arXiv:2511.22998, 2025
-
[52]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[53]
Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025. 16
2025
-
[54]
Bioprobench: Comprehensive dataset and benchmark in biological protocol understanding and reasoning
Yuyang Liu, Liuzhenghao Lv, Xiancheng Zhang, Li Yuan, and Yonghong Tian. Bioprobench: Comprehensive dataset and benchmark in biological protocol understanding and reasoning. arXiv preprint arXiv:2505.07889, 2025
-
[55]
arXiv preprint arXiv:2404.01475 , year=
Adrian Mirza, Nawaf Alampara, Sreekanth Kunchapu, Martiño Ríos-García, Benedict Emoek- abu, Aswanth Krishnan, Tanya Gupta, Mara Schilling-Wilhelmi, Macjonathan Okereke, Anagha Aneesh, et al. Are large language models superhuman chemists?arXiv preprint arXiv:2404.01475, 2024
-
[56]
MSEarth: A Multimodal Benchmark for Earth Science Phenomenon Discovery with MLLMs
Xiangyu Zhao, Wanghan Xu, Bo Liu, Yuhao Zhou, Fenghua Ling, Ben Fei, Xiaoyu Yue, Lei Bai, Wenlong Zhang, and Xiao-Ming Wu. Msearth: A benchmark for multimodal scientific comprehension of earth science.arXiv preprint arXiv:2505.20740, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Basereward: A strong baseline for multimodal reward model, 2025
Yi-Fan Zhang, Haihua Yang, Huanyu Zhang, Yang Shi, Zezhou Chen, Haochen Tian, Chaoyou Fu, Haotian Wang, Kai Wu, Bo Cui, Xu Wang, Jianfei Pan, Haotian Wang, Zhang Zhang, and Liang Wang. Basereward: A strong baseline for multimodal reward model, 2025
2025
-
[58]
Vl-rewardbench: A challenging benchmark for vision-language generative reward models
Lei Li, Yuancheng Wei, Zhihui Xie, Xuqing Yang, Yifan Song, Peiyi Wang, Chenxin An, Tianyu Liu, Sujian Li, Bill Yuchen Lin, Lingpeng Kong, and Qi Liu. Vl-rewardbench: A challenging benchmark for vision-language generative reward models. InCVPR, 2025
2025
-
[59]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models, 2024
LLaMA team. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models, 2024
2024
-
[60]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[62]
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Chris Yuhao Liu, Liang Zeng, Yuzhen Xiao, Jujie He, Jiacai Liu, Chaojie Wang, Rui Yan, Wei Shen, Fuxiang Zhang, Jiacheng Xu, et al. Skywork-reward-v2: Scaling preference data curation via human-ai synergy.arXiv preprint arXiv:2507.01352, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025. 17 Table 6: Statistics of theSci-PRMtraining dataset after filtering. The dataset covers diverse scientific domains.Stepsdenotes tota...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Relevance Check: - If the paper exists, is it helpful for answering the specific Question above? OUTPUT FORMAT (STRICT JSON): { "status": "Authentic" or "Hallucinated", "analysis": "Step-by-step verification logic. First state if the DOI/Title exists. Then state if it is relevant." } NOTES: - Return "Authentic" ONLY if the paper is real AND the metadata (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.