Govern the Repository, Not the Agent: Measuring Ecosystem-Level Risk in AI-Native Software
Pith reviewed 2026-06-29 02:46 UTC · model grok-4.3
The pith
About half the variation in integration friction belongs to the repository after all other factors are accounted for, and agents concentrate it twice as much as humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
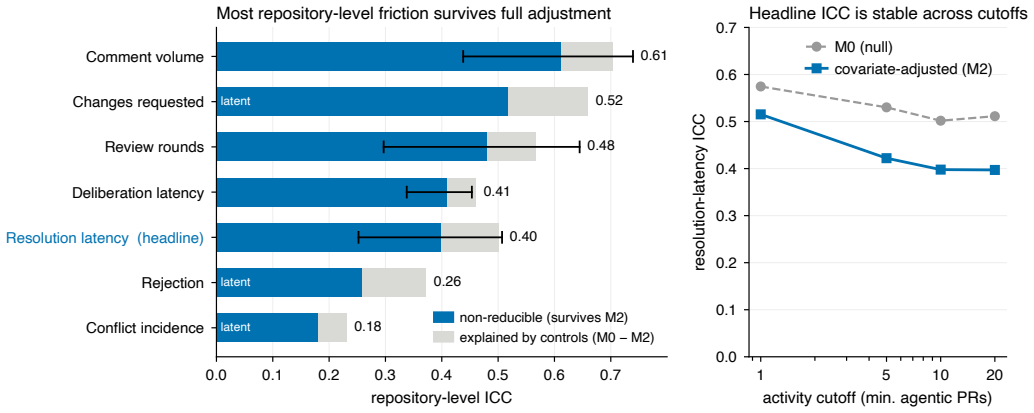
Autonomous coding agents now open and merge pull requests in shared repositories at scale. The authors measure integration friction, the cost of integrating a contribution into a codebase that other contributors are concurrently changing, across more than 930,000 agent-authored pull requests. About half of the variation in friction stays with the repository after the contribution, its author, its size, and its agent are accounted for, and this repository effect survives full controls. In the same repositories, agent-authored contributions concentrate this repository-level friction roughly twice as much as human ones (intraclass correlation 0.30 versus 0.16), a gap that holds after controllin
What carries the argument
Integration friction, quantified by the share of its variation that remains at the repository level via intraclass correlation after contribution, author, size, and agent are removed.
If this is right
- Benchmarks that evaluate agents on isolated tasks will systematically understate the risks that actually appear in shared repositories.
- Governance practices should target repository health and merge processes rather than selecting or improving individual agents.
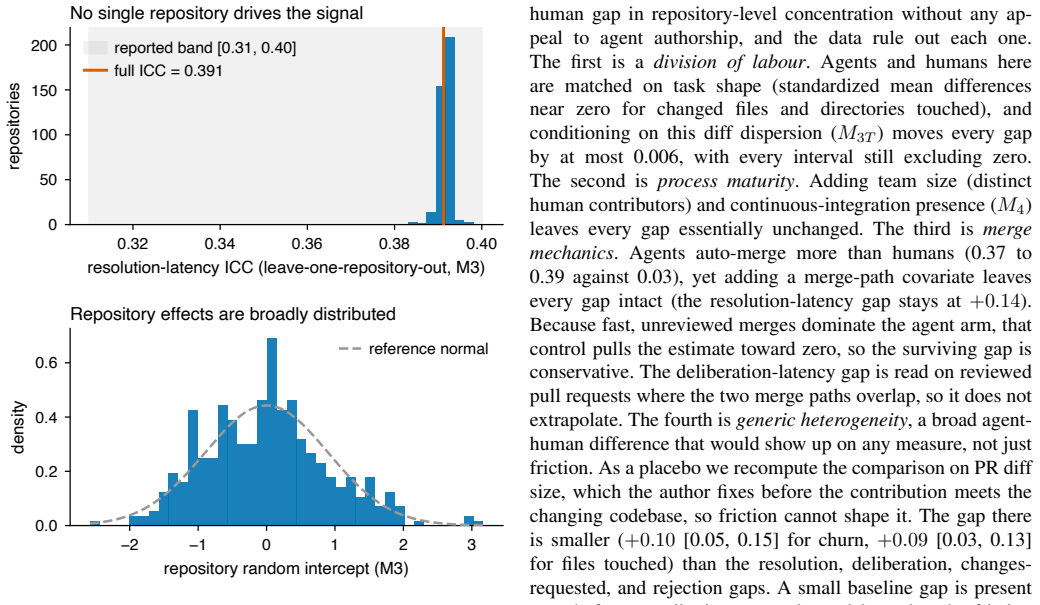
- The doubled concentration of friction from agents versus humans is not explained by differences in codebase size, age, task shape, process maturity, or merge path.
- Repository-level measurement will be required to track the cumulative effects of autonomous contributions at scale.
Where Pith is reading between the lines
- Improving merge processes or repository structure could reduce friction for any contributor, agent or human, without needing to change the agents themselves.
- The same repository-level lens could be applied to other shared systems where autonomous agents interact, such as distributed infrastructure or collaborative data sets.
- Teams may achieve more by monitoring and strengthening the repository's integration capacity than by chasing marginal gains in any single agent's performance.
Load-bearing premise
The statistical controls for codebase size, age, task shape, process maturity, and merge path together with the intraclass correlation metric isolate the repository-level effect without significant residual confounding or measurement error in integration friction.
What would settle it
A replication on new pull-request data that finds either zero remaining repository-level variation after the same controls or no difference between agent and human intraclass correlations would falsify the claim.
Figures
read the original abstract
Autonomous coding agents now open and merge pull requests in shared repositories at scale, and the field evaluates them the way it has always evaluated components, one agent at a time, on isolated benchmark tasks. Yet agents that each pass their own tests still leave repositories that accumulate problems no single contribution accounts for. We ask whether this problem belongs to the individual agent or to the repository where it accumulates. We study integration friction, the cost of integrating a contribution into a codebase that other contributors are concurrently changing. Across more than 930,000 agent-authored pull requests, we measure how much of the variation in friction stays with the repository after the contribution, its author, its size, and its agent are accounted for. About half does, and it survives full controls. In the same repositories, agent-authored contributions concentrate this repository-level friction roughly twice as much as human ones (intraclass correlation 0.30 versus 0.16), a gap that holds after controlling for codebase size, age, task shape, process maturity, and merge path. The risk is a property of the ecosystem, not the agent. AI-native software is therefore better measured and governed at the ecosystem level than one agent at a time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that integration friction—the cost of integrating contributions into concurrently changing codebases—is primarily a repository-level property rather than attributable to individual agents. Across >930k agent-authored PRs, roughly half the variation in friction remains with the repository after controlling for the contribution, author, size, and agent; agent-authored PRs concentrate this repo-level friction at roughly twice the rate of human ones (ICC 0.30 vs. 0.16), and the gap persists after further controls for codebase size, age, task shape, process maturity, and merge path. The conclusion is that AI-native software risk should be measured and governed at the ecosystem level.
Significance. If the variance-partitioning results hold under scrutiny, the work supplies the first large-scale empirical demonstration that ecosystem-level factors dominate integration costs in AI-augmented repositories, providing a concrete quantitative basis for shifting evaluation and governance away from isolated agent benchmarks toward repository-level metrics and policies.
major comments (2)
- [Results / Statistical model] The manuscript provides no explicit mixed-effects model equation, variance-component table, or description of how the random-intercept ICCs (0.30 agent vs. 0.16 human) and the ~50 % repository-level share were computed; without these, the central claim that half the friction variance is repository-attributable after the listed controls cannot be verified.
- [Results / Controls and robustness] No robustness analysis is reported that tests whether unmeasured repository traits (review strictness, dependency-graph density, contributor overlap) that jointly influence friction and the decision to adopt agents remain after the listed controls; such omitted variables could produce the observed ICC gap via selection rather than an intrinsic ecosystem effect.
minor comments (1)
- [Abstract] The abstract states the sample size but omits the number of repositories, the human PR comparison sample size, the time window, and the exact operational definition of 'integration friction,' all of which are needed to assess scope and replicability.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the statistical presentation and robustness. We address each point below and will revise the manuscript to improve clarity and address the concerns where data and scope permit.
read point-by-point responses
-
Referee: The manuscript provides no explicit mixed-effects model equation, variance-component table, or description of how the random-intercept ICCs (0.30 agent vs. 0.16 human) and the ~50 % repository-level share were computed; without these, the central claim that half the friction variance is repository-attributable after the listed controls cannot be verified.
Authors: We agree the model specification and variance decomposition were under-documented. The revised manuscript will include the full mixed-effects model equation (with random intercepts for repository, author, contribution, and agent), a variance-component table reporting the ICC calculations, and explicit steps showing how the ~50% repository share and the 0.30 vs. 0.16 ICC gap were obtained after the listed controls. revision: yes
-
Referee: No robustness analysis is reported that tests whether unmeasured repository traits (review strictness, dependency-graph density, contributor overlap) that jointly influence friction and the decision to adopt agents remain after the listed controls; such omitted variables could produce the observed ICC gap via selection rather than an intrinsic ecosystem effect.
Authors: The current controls already include codebase size, age, task shape, process maturity, and merge path. We acknowledge that the specific unmeasured traits listed could still induce selection bias. In revision we will add a dedicated robustness section that incorporates available proxies for review strictness and dependency density (where repository metadata permits) and discuss residual selection concerns as a limitation. revision: partial
Circularity Check
No significant circularity; empirical variance partitioning via standard mixed models.
full rationale
The paper reports an empirical analysis of >930k pull requests using multilevel modeling to compute intraclass correlations for integration friction after fixed effects for contribution/author/size/agent and additional controls. The ~50% repository-level variance and the 0.30 vs 0.16 agent/human gap are direct outputs of the fitted model and ICC formula applied to observed data; they are not obtained by redefining the target quantity in terms of itself or by relabeling a fitted parameter as a prediction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central attribution. The derivation is therefore self-contained against external statistical benchmarks and the dataset.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
H. Li, H. Zhang, and A. E. Hassan, “The rise of AI teammates in software engineering (SE) 3.0: How autonomous coding agents are reshaping software engineering,” arXiv:2507.15003, 2025, aIDev origin study; replication github.com/SAILResearch/AI Teammates in SE3
Pith/arXiv arXiv 2025
-
[2]
AIDev: Studying AI coding agents on GitHub,
——, “AIDev: Studying AI coding agents on GitHub,” arXiv:2602.09185; dataset Hugging Face hao-li/AIDev; MSR 2026 Mining Challenge, 2026
arXiv 2026
-
[3]
SWE-bench: Can language models resolve real-world GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?” inProceedings of the Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
From technical debt to cognitive and intent debt: Re- thinking software health in the age of AI,
M.-A. Storey, “From technical debt to cognitive and intent debt: Re- thinking software health in the age of AI,”ACM Queue, 2026, article id 3807966; preprint arXiv:2603.22106
Pith/arXiv arXiv 2026
-
[5]
More is different,
P. W. Anderson, “More is different,”Science, vol. 177, no. 4047, pp. 393–396, 1972
1972
-
[6]
The WyCash portfolio management system,
W. Cunningham, “The WyCash portfolio management system,” inAd- dendum to the Proceedings of OOPSLA ’92. ACM, 1992, pp. 29–30
1992
-
[7]
Technical debt: From metaphor to theory and practice,
P. Kruchten, R. L. Nord, and I. Ozkaya, “Technical debt: From metaphor to theory and practice,”IEEE Software, vol. 29, no. 6, pp. 18–21, 2012
2012
-
[8]
Social debt in software engineering: Insights from industry,
D. A. Tamburri, P. Kruchten, P. Lago, and H. van Vliet, “Social debt in software engineering: Insights from industry,”Journal of Internet Services and Applications, vol. 6, no. 1, pp. 10:1–10:17, 2015
2015
-
[9]
Programming as theory building,
P. Naur, “Programming as theory building,”Microprocessing and Mi- croprogramming, vol. 15, no. 5, pp. 253–261, 1985
1985
-
[10]
Quantifying and mitigating turnover-induced knowledge loss: Case studies of Chrome and a project at Avaya,
P. C. Rigby, Y . C. Zhu, S. M. Donadelli, and A. Mockus, “Quantifying and mitigating turnover-induced knowledge loss: Case studies of Chrome and a project at Avaya,” inProceedings of the 38th International Conference on Software Engineering (ICSE), 2016, pp. 1006–1016
2016
-
[11]
How AI impacts skill formation,
J. H. Shen and A. Tamkin, “How AI impacts skill formation,” arXiv:2601.20245, 2026, preprint; peer-review status to confirm
arXiv 2026
-
[12]
How do committees invent?
M. E. Conway, “How do committees invent?”Datamation, vol. 14, no. 4, pp. 28–31, 1968
1968
-
[13]
Exploring the duality between product and organizational architectures: A test of the mirroring hypothesis,
A. MacCormack, J. Rusnak, and C. Y . Baldwin, “Exploring the duality between product and organizational architectures: A test of the mirroring hypothesis,”Research Policy, vol. 41, no. 8, pp. 1309–1324, 2012
2012
-
[14]
Software ecosystems – a systematic literature review,
K. Manikas and K. M. Hansen, “Software ecosystems – a systematic literature review,”Journal of Systems and Software, vol. 86, no. 5, pp. 1294–1306, 2013
2013
-
[15]
Recovering inter-project depen- dencies in software ecosystems,
M. Lungu, R. Robbes, and M. Lanza, “Recovering inter-project depen- dencies in software ecosystems,” inProceedings of the 25th IEEE/ACM International Conference on Automated Software Engineering (ASE), 2010, pp. 309–312
2010
-
[16]
When and how to make breaking changes: Policies and practices in 18 open source software ecosystems,
C. Bogart, C. K ¨astner, J. Herbsleb, and F. Thung, “When and how to make breaking changes: Policies and practices in 18 open source software ecosystems,”ACM Transactions on Software Engineering and Methodology, vol. 30, no. 4, pp. 42:1–42:56, 2021
2021
-
[17]
An empirical comparison of dependency network evolution in seven software packaging ecosystems,
A. Decan, T. Mens, and P. Grosjean, “An empirical comparison of dependency network evolution in seven software packaging ecosystems,” Empirical Software Engineering, vol. 24, no. 1, pp. 381–416, 2019
2019
-
[18]
Small world with high risks: A study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small world with high risks: A study of security threats in the npm ecosystem,” in 28th USENIX Security Symposium, 2019, pp. 995–1010
2019
-
[19]
A formal framework for measuring technical lag in component repositories – and its application to npm,
A. Zerouali, T. Mens, J. Gonzalez-Barahona, A. Decan, E. Constantinou, and G. Robles, “A formal framework for measuring technical lag in component repositories – and its application to npm,”Journal of Software: Evolution and Process, vol. 31, no. 8, p. e2157, 2019
2019
-
[20]
Socio-technical con- gruence: A framework for assessing the impact of technical and work dependencies on software development productivity,
M. Cataldo, J. D. Herbsleb, and K. M. Carley, “Socio-technical con- gruence: A framework for assessing the impact of technical and work dependencies on software development productivity,” inProceedings of the 2nd ACM-IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2008, pp. 2–11
2008
-
[21]
An empirical study of speed and communication in globally distributed software development,
J. D. Herbsleb and A. Mockus, “An empirical study of speed and communication in globally distributed software development,”IEEE Transactions on Software Engineering, vol. 29, no. 6, pp. 481–494, 2003
2003
-
[22]
Quantifying causal emergence shows that macro can beat micro,
E. P. Hoel, L. Albantakis, and G. Tononi, “Quantifying causal emergence shows that macro can beat micro,”Proceedings of the National Academy of Sciences, vol. 110, no. 49, pp. 19 790–19 795, 2013
2013
-
[23]
Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data,
F. E. Rosas, P. A. M. Mediano, H. J. Jensen, A. K. Seth, A. B. Barrett, R. L. Carhart-Harris, and D. Bor, “Reconciling emergences: An information-theoretic approach to identify causal emergence in multivariate data,”PLOS Computational Biology, vol. 16, no. 12, p. e1008289, 2020
2020
-
[24]
Greater than the parts: A review of the information decomposition approach to causal emergence,
P. A. M. Mediano, F. E. Rosas, A. I. Luppi, H. J. Jensen, A. K. Seth, A. B. Barrett, R. L. Carhart-Harris, and D. Bor, “Greater than the parts: A review of the information decomposition approach to causal emergence,”Philosophical Transactions of the Royal Society A, vol. 380, no. 2227, p. 20210246, 2022
2022
-
[25]
Dynamical independence: Discovering emer- gent macroscopic processes in complex dynamical systems,
L. Barnett and A. K. Seth, “Dynamical independence: Discovering emer- gent macroscopic processes in complex dynamical systems,”Physical Review E, vol. 108, p. 014304, 2023
2023
-
[26]
Understanding open source commu- nities as complex adaptive systems: A case of the R project community,
G. J. P. Link and M. Germonprez, “Understanding open source commu- nities as complex adaptive systems: A case of the R project community,” inAmericas Conference on Information Systems (AMCIS), 2016
2016
-
[27]
Software ecosystem evolution: It’s complex!
T. Mens, “Software ecosystem evolution: It’s complex!” inBENEVOL, 2016, non-archival extended abstract
2016
-
[28]
A complex adaptive systems perspective of software reuse in the digital age: An agenda for IS research,
G. Vial, “A complex adaptive systems perspective of software reuse in the digital age: An agenda for IS research,”Information Systems Research, vol. 34, no. 4, pp. 1728–1743, 2023
2023
-
[29]
Studying evolving software ecosystems based on ecological models,
T. Mens, M. Claes, P. Grosjean, and A. Serebrenik, “Studying evolving software ecosystems based on ecological models,” inEvolving Software Systems. Springer, 2014, pp. 297–326
2014
-
[30]
More is different: Toward a theory of emergence in AI-native software ecosystems,
D. Russo, “More is different: Toward a theory of emergence in AI-native software ecosystems,” arXiv:2604.19827, 2026
Pith/arXiv arXiv 2026
-
[31]
Emergent abilities of large language models,
J. Wei, Y . Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,”Transactions on Machine Learning Research, 2022, arXiv:2206.07682
Pith/arXiv arXiv 2022
-
[32]
Are emergent abilities of large language models a mirage?
R. Schaeffer, B. Miranda, and S. Koyejo, “Are emergent abilities of large language models a mirage?” inAdvances in Neural Information Process- ing Systems (NeurIPS), 2023, outstanding Paper; arXiv:2304.15004
arXiv 2023
-
[33]
Emergent social conventions and collective bias in LLM populations,
A. F. Ashery, L. M. Aiello, and A. Baronchelli, “Emergent social conventions and collective bias in LLM populations,”Science Advances, vol. 11, no. 20, p. eadu9368, 2025
2025
-
[34]
MAEBE: Multi- agent emergent behavior framework,
S. Erisken, T. Gothard, M. Leitgab, and R. Potham, “MAEBE: Multi- agent emergent behavior framework,” arXiv:2506.03053, 2025
arXiv 2025
-
[35]
Group size effects and collective misalignment in LLM multi-agent systems,
A. F. Ashery, L. M. Aiello, R. Pastor-Satorras, and A. Baronchelli, “Group size effects and collective misalignment in LLM multi-agent systems,” arXiv:2510.22422, 2025
arXiv 2025
-
[36]
Why do multi-agent LLM systems fail?
M. Cemri, M. Z. Pan, S. Yang, L. A. Agrawal, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, D. Klein, K. Ramchandran, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Why do multi-agent LLM systems fail?” arXiv:2503.13657, 2025
Pith/arXiv arXiv 2025
-
[37]
Agentic software engineering: Foundational pillars and a research roadmap,
A. E. Hassan, H. Li, D. Lin, B. Adams, T.-H. Chen, Y . Kashiwa, and D. Qiu, “Agentic software engineering: Foundational pillars and a research roadmap,” arXiv:2509.06216, 2025
Pith/arXiv arXiv 2025
-
[38]
Toward agentic software engineering beyond code: Framing vision, values, and vocabulary,
R. Hoda, “Toward agentic software engineering beyond code: Framing vision, values, and vocabulary,” inProceedings of the 48th International Conference on Software Engineering (ICSE-Companion), 2026
2026
-
[39]
Agentic AI software engineers: Programming with trust,
A. Roychoudhury, C. Pasareanu, M. Pradel, and B. Ray, “Agentic AI software engineers: Programming with trust,” arXiv:2502.13767, 2025
arXiv 2025
-
[40]
AgenticFlict: A large-scale dataset of merge conflicts in AI coding agent pull requests on GitHub,
D. Ogenrwot and J. Businge, “AgenticFlict: A large-scale dataset of merge conflicts in AI coding agent pull requests on GitHub,” arXiv:2604.03551, 2026
Pith/arXiv arXiv 2026
-
[41]
AI copilot code quality: 2025 data suggests downward pressure on code quality,
GitClear, “AI copilot code quality: 2025 data suggests downward pressure on code quality,” GitClear technical report, 2025
2025
-
[42]
The power of bots: Characterizing and understanding bots in OSS projects,
M. Wessel, B. M. de Souza, I. Steinmacher, I. S. Wiese, I. Polato, A. P. Chaves, and M. A. Gerosa, “The power of bots: Characterizing and understanding bots in OSS projects,”Proceedings of the ACM on Human-Computer Interaction, vol. 2, no. CSCW, pp. 182:1–182:19, 2018
2018
-
[43]
Don’t disturb me: Challenges of interacting with software bots on open source software projects,
M. Wessel, I. Wiese, I. Steinmacher, and M. A. Gerosa, “Don’t disturb me: Challenges of interacting with software bots on open source software projects,”Proceedings of the ACM on Human-Computer Interaction, vol. 5, no. CSCW2, p. Article 332, 2021
2021
-
[44]
Quality gatekeepers: Investigating the effects of code review bots on pull request activities,
M. Wessel, A. Serebrenik, I. Wiese, I. Steinmacher, and M. A. Gerosa, “Quality gatekeepers: Investigating the effects of code review bots on pull request activities,”Empirical Software Engineering, vol. 27, no. 5, p. 108, 2022
2022
-
[45]
The impact of AI on developer productivity: Evidence from GitHub Copilot,
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer, “The impact of AI on developer productivity: Evidence from GitHub Copilot,” arXiv:2302.06590, 2023
Pith/arXiv arXiv 2023
-
[46]
The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers,
Z. Cui, M. Demirer, S. Jaffe, L. Musolff, S. Peng, and T. Salz, “The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers,”Management Science, 2026
2026
-
[47]
Measuring the impact of early-2025 AI on experienced open-source developer productivity,
J. Becker, N. Rush, B. Barnes, and D. Rein, “Measuring the impact of early-2025 AI on experienced open-source developer productivity,” arXiv:2507.09089, 2025
arXiv 2025
-
[48]
The ABC of software engineering re- search,
K.-J. Stol and B. Fitzgerald, “The ABC of software engineering re- search,”ACM Transactions on Software Engineering and Methodology, vol. 27, no. 3, pp. 11:1–11:51, 2018
2018
-
[49]
Wohlin, P
C. Wohlin, P. Runeson, M. H ¨ost, M. C. Ohlsson, B. Regnell, and A. Wessl´en,Experimentation in Software Engineering. Springer, 2012
2012
-
[50]
S. W. Raudenbush and A. S. Bryk,Hierarchical Linear Models: Appli- cations and Data Analysis Methods, 2nd ed. Sage, 2002
2002
-
[51]
Gelman and J
A. Gelman and J. Hill,Data Analysis Using Regression and Multi- level/Hierarchical Models. Cambridge University Press, 2007
2007
-
[52]
T. A. B. Snijders and R. J. Bosker,Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling, 2nd ed. Sage, 2012
2012
-
[53]
Partitioning variation in multilevel models,
H. Goldstein, W. Browne, and J. Rasbash, “Partitioning variation in multilevel models,”Understanding Statistics, vol. 1, no. 4, pp. 223–231, 2002
2002
-
[54]
Pull request latency explained: An empirical overview,
X. Zhang, Y . Yu, T. Wang, A. Rastogi, and H. Wang, “Pull request latency explained: An empirical overview,”Empirical Software Engi- neering, vol. 27, no. 6, p. 126, 2022
2022
-
[55]
Pull request decisions explained: An empirical overview,
X. Zhang, Y . Yu, G. Gousios, and A. Rastogi, “Pull request decisions explained: An empirical overview,”IEEE Transactions on Software Engineering, vol. 49, no. 2, pp. 849–871, 2023
2023
-
[56]
No silver bullets: Why understanding software cycle time is messy, not magic,
J. C. Flournoy, C. S. Lee, M. Wu, and C. M. Hicks, “No silver bullets: Why understanding software cycle time is messy, not magic,”Empirical Software Engineering, vol. 30, no. 6, 2025
2025
-
[57]
The coefficient of determination R2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded,
S. Nakagawa, P. C. D. Johnson, and H. Schielzeth, “The coefficient of determination R2 and intra-class correlation coefficient from generalized linear mixed-effects models revisited and expanded,”Journal of the Royal Society Interface, vol. 14, no. 134, p. 20170213, 2017
2017
-
[58]
Using observation-level random effects to model overdispersion in count data in ecology and evolution,
X. A. Harrison, “Using observation-level random effects to model overdispersion in count data in ecology and evolution,”PeerJ, vol. 2, p. e616, 2014
2014
-
[59]
McCullagh and J
P. McCullagh and J. A. Nelder,Generalized Linear Models, 2nd ed. Chapman and Hall, 1989
1989
-
[60]
A general and simple method for obtaining R2 from generalized linear mixed-effects models,
S. Nakagawa and H. Schielzeth, “A general and simple method for obtaining R2 from generalized linear mixed-effects models,”Methods in Ecology and Evolution, vol. 4, no. 2, pp. 133–142, 2013
2013
-
[61]
Random-effects models for longitudinal data,
N. M. Laird and J. H. Ware, “Random-effects models for longitudinal data,”Biometrics, vol. 38, no. 4, pp. 963–974, 1982
1982
-
[62]
statsmodels: Econometric and statistical modeling with Python,
S. Seabold and J. Perktold, “statsmodels: Econometric and statistical modeling with Python,” inProceedings of the 9th Python in Science Conference (SciPy), 2010, pp. 92–96
2010
-
[63]
Efron and R
B. Efron and R. J. Tibshirani,An Introduction to the Bootstrap. Chap- man and Hall, 1993
1993
-
[64]
The promises and perils of mining GitHub,
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian, “The promises and perils of mining GitHub,”Empirical Software Engineering, vol. 21, no. 5, pp. 2035–2071, 2016
2035
-
[65]
Diversity in software engineering research,
M. Nagappan, T. Zimmermann, and C. Bird, “Diversity in software engineering research,” inProceedings of the 9th Joint Meeting on Foundations of Software Engineering (ESEC/FSE), 2013, pp. 466–476
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.