MIRROR: Aligning Semantic Relations from Language to Image via Gromov--Wasserstein
Pith reviewed 2026-06-30 07:26 UTC · model grok-4.3
The pith
Semi-Inverse Gromov-Wasserstein alignment transfers relational priors from language to visual representations with a closed-form solution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that this formulation admits a unique closed-form solution that prescribes the ideal visual relational structure implied by language geometry and cross-modal coupling.
What carries the argument
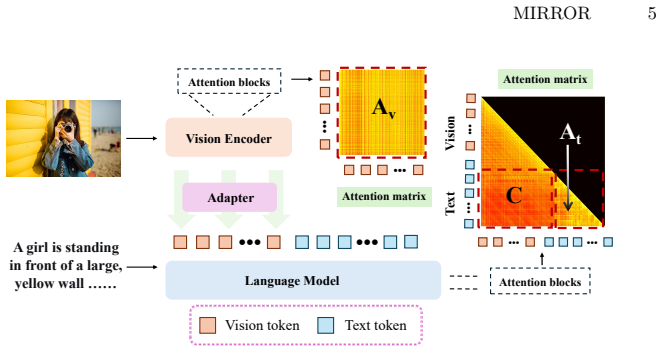
The Semi-Inverse Gromov-Wasserstein (SI-GW) problem, an inverse optimal-transport alignment that matches visual token relations to language-derived relational priors.
If this is right
- Relational consistency improves on tasks that require applying language-learned relations in visual scenes.
- General vision-language performance remains unchanged because the regularization preserves individual token semantics.
- The closed-form solution permits direct application to long token sequences without quadratic scaling issues.
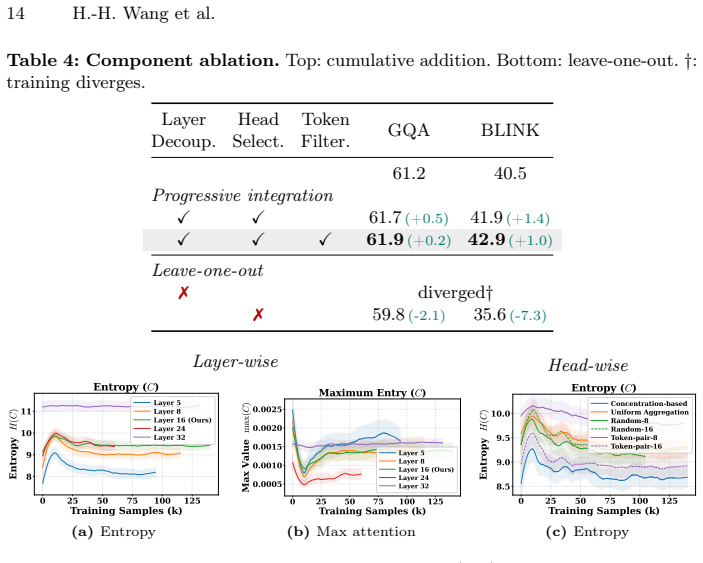
- Integration requires only targeted placement at layer, head, and token levels and adds no parameters or inference overhead.
Where Pith is reading between the lines
- The same closed-form relational transfer could be tested on other modality pairs that share language backbones, such as audio or 3D.
- Because the method needs no task-specific tuning, it may reduce the data required for relational reasoning fine-tuning.
- The geometric view of cross-modal relations opens the possibility of diagnosing which layers already carry strong relational structure before alignment.
Load-bearing premise
Relational priors already present in language representations can be moved into visual representations through SI-GW regularization without distorting the original visual semantics.
What would settle it
An experiment in which models trained with the SI-GW term show no gain on relational consistency benchmarks or exhibit measurable drops on standard vision-language tasks relative to identical baselines without the term.
Figures


read the original abstract
Multimodal Large Language Models (MLLMs) inherit rich relational priors from their language backbones, yet often fail when asked to apply these relationships in visual contexts. We trace this failure to a structural blind spot: projection-based alignment trains each visual token to carry the right semantics, but never asks whether the relationships between concepts survive the crossing from language to vision. To address this, we propose MIRROR (Mapping Inter-concept Relations from language to visual Representation via Optimal-transport-based Regularization), a geometric regularization framework that transfers relational priors from language to vision by exploiting the rich relational structure encoded in language representations. Specifically, we derive a surrogate loss from the proposed Semi-Inverse Gromov-Wasserstein (SI-GW) problem, an inverse geometric problem that aligns visual representations with language-derived relational priors. We show that this formulation admits a unique closed-form solution that prescribes the ideal visual relational structure implied by language geometry and cross-modal coupling. The structure of the formulation also enables efficient computation, making it applicable to long token sequences. Applying SI-GW inside decoder-only Transformers requires careful design. We introduce targeted strategies at the layer, head, and token levels to ensure stable extraction without additional parameters or inference cost. MIRROR improves relational consistency while preserving performance on general vision-language tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MIRROR, a geometric regularization framework for multimodal large language models that transfers relational priors from language to vision using a Semi-Inverse Gromov-Wasserstein (SI-GW) alignment. It derives a surrogate loss from the SI-GW problem and claims this admits a unique closed-form solution prescribing the ideal visual relational structure, with efficient computation suitable for long token sequences; targeted integration strategies at layer/head/token levels in decoder-only Transformers are introduced to enable stable extraction without added parameters or inference cost, yielding improved relational consistency while preserving general vision-language performance.
Significance. If the uniqueness and closed-form solution for SI-GW hold under the stated cross-modal assumptions and the method transfers relations without distorting visual semantics, this would supply an efficient, parameter-free regularization approach grounded in optimal transport that directly targets a structural limitation of projection-based alignments in MLLMs. The emphasis on applicability to long sequences and zero-overhead integration represents a practical strength.
minor comments (3)
- The abstract states that SI-GW 'admits a unique closed-form solution' but provides no equation reference or proof outline; adding a brief pointer to the relevant theorem or derivation in the main text would improve accessibility.
- Notation for the language-derived relational priors and the cross-modal coupling term should be defined explicitly on first use to avoid ambiguity when the SI-GW objective is introduced.
- The description of layer/head/token-level strategies would benefit from a short pseudocode or diagram clarifying how the closed-form solution is applied inside the Transformer without altering inference cost.
Simulated Author's Rebuttal
We thank the referee for their constructive summary and positive assessment of the manuscript, including recognition of the closed-form SI-GW solution, computational efficiency for long sequences, and parameter-free integration. The recommendation for minor revision is appreciated.
Circularity Check
No significant circularity detected
full rationale
The abstract frames the SI-GW problem as derived from optimal transport principles and states that the formulation admits a unique closed-form solution, but provides no equations, proofs, or self-citations that reduce this uniqueness or the surrogate loss to fitted inputs, prior self-work, or definitional equivalence. No load-bearing steps matching the enumerated circularity patterns are identifiable from the given text, and the central claim remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties and existence results for Gromov-Wasserstein distances in optimal transport
invented entities (1)
-
Semi-Inverse Gromov-Wasserstein (SI-GW) problem
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Advances in neural information processing systems35, 23716– 23736 (2022)
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Men- sch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems35, 23716– 23736 (2022)
2022
-
[3]
Advances in neural information processing systems 32(2019)
Altschuler, J., Bach, F., Rudi, A., Niles-Weed, J.: Massively scalable sinkhorn dis- tances via the nyström method. Advances in neural information processing systems 32(2019)
2019
-
[4]
Advances in neural information processing systems30(2017)
Altschuler, J., Niles-Weed, J., Rigollet, P.: Near-linear time approximation algo- rithms for optimal transport via sinkhorn iteration. Advances in neural information processing systems30(2017)
2017
-
[5]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 16 H.-H. Wang et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
SIAM Journal on Scientific Computing37(2), A1111–A1138 (2015)
Benamou, J.D., Carlier, G., Cuturi, M., Nenna, L., Peyré, G.: Iterative bregman projections for regularized transportation problems. SIAM Journal on Scientific Computing37(2), A1111–A1138 (2015)
2015
-
[8]
Advances in Neural Information Processing Systems37, 69814–69839 (2024)
Chen, J., Nguyen, B.T., Koh, S., Soh, Y.S.: Semidefinite relaxations of the gromov- wasserstein distance. Advances in Neural Information Processing Systems37, 69814–69839 (2024)
2024
-
[9]
In: Eu- ropean Conference on Computer Vision
Chen, L., Li, J., Dong, X., Zhang, P., He, C., Wang, J., Zhao, F., Lin, D.: Sharegpt4v: Improving large multi-modal models with better captions. In: Eu- ropean Conference on Computer Vision. pp. 370–387. Springer (2024)
2024
-
[10]
In: Forty-third International Conference on Machine Learning (2026),https://openreview.net/ forum?id=PK0zeaGAJ9
Cheng, K., Huang, J., Song, J., Zhang, W., Han, B., Ding, H.: Achieving struc- turally robust gromov wasserstein distance via adaptive dual-mask. In: Forty-third International Conference on Machine Learning (2026),https://openreview.net/ forum?id=PK0zeaGAJ9
2026
-
[11]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality (March 2023),https://lmsys.org/ blog/2023-03-30-vicuna/
2023
-
[12]
Ad- vances in neural information processing systems26(2013)
Cuturi, M.: Sinkhorn distances: Lightspeed computation of optimal transport. Ad- vances in neural information processing systems26(2013)
2013
-
[13]
Advances in Neural Information Processing Systems36(2024)
Dai, W., Li, J., Li, D., Tiong, A.M.H., Zhao, J., Wang, W., Li, B., Fung, P.N., Hoi, S.: Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in Neural Information Processing Systems36(2024)
2024
-
[14]
SIAM Journal on Imaging Sciences7(3), 1853–1882 (2014)
Ferradans, S., Papadakis, N., Peyré, G., Aujol, J.F.: Regularized discrete optimal transport. SIAM Journal on Imaging Sciences7(3), 1853–1882 (2014)
2014
-
[15]
Journal of Machine Learning Research22(78), 1–8 (2021)
Flamary, R., Courty, N., Gramfort, A., Alaya, M.Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al.: Pot: Python optimal transport. Journal of Machine Learning Research22(78), 1–8 (2021)
2021
-
[16]
In: European Conference on Computer Vision
Fu, X., Hu, Y., Li, B., Feng, Y., Wang, H., Lin, X., Roth, D., Smith, N.A., Ma, W.C., Krishna, R.: Blink: Multimodal large language models can see but not per- ceive. In: European Conference on Computer Vision. pp. 148–166. Springer (2024)
2024
-
[17]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6904–6913 (2017)
2017
-
[18]
Gromov, M., Katz, M., Pansu, P., Semmes, S.: Metric structures for Riemannian and non-Riemannian spaces, vol. 152. Springer (1999)
1999
- [19]
-
[20]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 6700–6709 (2019)
2019
-
[21]
In: Proceedings of the 41st International Conference on Machine Learn- ing
Huh, M., Cheung, B., Wang, T., Isola, P.: Position: the platonic representation hy- pothesis. In: Proceedings of the 41st International Conference on Machine Learn- ing. pp. 20617–20642 (2024)
2024
-
[22]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., Casas, D.d.l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al.: Mistral 7b. arXiv preprint arXiv:2310.06825 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023) MIRROR 17
2023
-
[24]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, L.H., Zhang, P., Zhang, H., Yang, J., Li, C., Zhong, Y., Wang, L., Yuan, L., Zhang, L., Hwang, J.N., et al.: Grounded language-image pre-training. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10965–10975 (2022)
2022
- [25]
-
[26]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Singapore (2023),https://openreview.net/forum? id=xozJw0kZXF
2023
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lin, J., Yin, H., Ping, W., Molchanov, P., Shoeybi, M., Han, S.: Vila: On pre- training for visual language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26689–26699 (2024)
2024
-
[28]
In: International Conference on Ma- chine Learning
Lin, T., Ho, N., Jordan, M.: On efficient optimal transport: An analysis of greedy and accelerated mirror descent algorithms. In: International Conference on Ma- chine Learning. pp. 3982–3991. PMLR (2019)
2019
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[30]
io/blog/2024-01-30-llava-next/
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (January 2024),https://llava-vl.github. io/blog/2024-01-30-llava-next/
2024
-
[31]
Advances in neural information processing systems36(2024)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36(2024)
2024
-
[32]
In: Second Workshop on Representational Alignment at ICLR 2025 (2025)
Masry, A., Rodriguez, J.A., Zhang, T., Wang, S., Wang, C., Feizi, A., Suresh, A.K., Puri, A., Jian, X., Noël, P.A., et al.: Alignvlm: Bridging vision and language latent spaces for multimodal understanding. In: Second Workshop on Representational Alignment at ICLR 2025 (2025)
2025
-
[33]
Foundations of computational mathematics11, 417–487 (2011)
Mémoli, F.: Gromov–wasserstein distances and the metric approach to object matching. Foundations of computational mathematics11, 417–487 (2011)
2011
-
[34]
Michel, P., Levy, O., Neubig, G.: Are sixteen heads really better than one? Ad- vances in neural information processing systems32(2019)
2019
-
[35]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
2021
-
[36]
In: Ku, L.W., Martins, A., Srikumar, V
Ren, J., Guo, Q., Yan, H., Liu, D., Zhang, Q., Qiu, X., Lin, D.: Identifying semantic induction heads to understand in-context learning. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics: ACL 2024. pp. 6916–6932. Association for Computational Linguistics, Bangkok, Thailand (Aug 2024).https://doi.org/1...
-
[37]
Journal of Machine Learning Research25(363), 1–52 (2024)
Rioux, G., Goldfeld, Z., Kato, K.: Entropic gromov-wasserstein distances: Stability and algorithms. Journal of Machine Learning Research25(363), 1–52 (2024)
2024
-
[38]
Probabil- ity Theory and Related Fields70(1), 117–129 (1985)
Rüschendorf, L.: The wasserstein distance and approximation theorems. Probabil- ity Theory and Related Fields70(1), 117–129 (1985)
1985
-
[39]
Advances in Neural Information Process- ing Systems34, 8766–8779 (2021) 18 H.-H
Séjourné, T., Vialard, F.X., Peyré, G.: The unbalanced gromov wasserstein dis- tance: Conic formulation and relaxation. Advances in Neural Information Process- ing Systems34, 8766–8779 (2021) 18 H.-H. Wang et al
2021
-
[40]
ACM Trans
Solomon, J., Peyré, G., Kim, V.G., Sra, S.: Entropic metric alignment for corre- spondence problems. ACM Trans. Graph.35(4), 72:1–72:13 (2016)
2016
-
[41]
In: Forty-third International Conference on Machine Learning (2026),https://openreview.net/forum?id=dxwRakfEFm
Song, J., Huang, J., Cheng, K., Han, B., Ding, H.: LoBCD-GW: A fast and data- dependentalgorithmforcomputinggromov-wassersteindistancevialocalizedblock coordinate descent. In: Forty-third International Conference on Machine Learning (2026),https://openreview.net/forum?id=dxwRakfEFm
2026
-
[42]
In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)
Tao,M.,Huang,Q.,Xu,K.,Chen,L.,Feng,Y.,Zhao,D.:Probingmultimodallarge language models for global and local semantic representations. In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). pp. 13050–13056 (2024)
2024
-
[43]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bash- lykov, N., Batra, S., Bhargava, P., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
Villani, C., et al.: Optimal transport: old and new, vol. 338. Springer (2009)
2009
- [45]
-
[46]
In: ACL 2019-57th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference
Voita, E., Talbot, D., Moiseev, F., Titov, I., Sennrich, R.: Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: ACL 2019-57th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference. pp. 5797–5808 (2020)
2019
-
[47]
x.ai: Grok-1.5 vision preview.https://x.ai/blog/grok-1.5v(2025)
2025
-
[48]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al.: Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
In: The Twelfth International Conference on Learning Representations (2023)
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision- language understanding with advanced large language models. In: The Twelfth International Conference on Learning Representations (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.