SurrogateShield: Beyond Redaction for High-Utility, Privacy-Preserving LLM Interactions
Pith reviewed 2026-06-30 06:55 UTC · model grok-4.3
The pith
SurrogateShield replaces PII in LLM queries with locally generated surrogates to preserve semantic utility while blocking real data transmission.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Surrogate substitution with local generation and restoration yields higher semantic fidelity than redaction for LLM interactions while restricting real PII transmission across query types, as measured by BERTScore gains and adversarial non-recovery.
What carries the argument
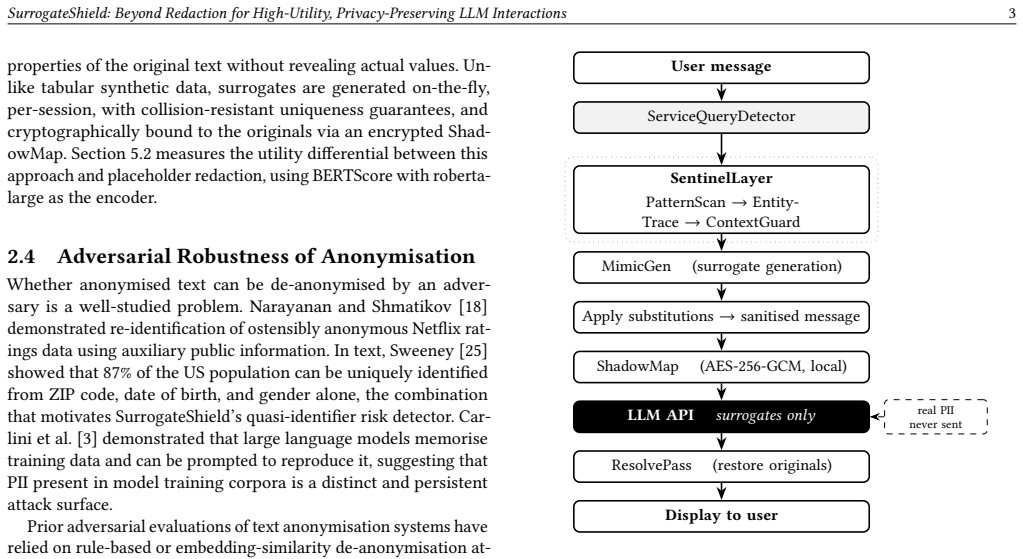
The surrogate substitution mechanism, which detects PII via PatternScan-EntityTrace-ContextGuard cascade, generates type-consistent local surrogates, and uses an AES-256-GCM encrypted ShadowMap for per-conversation original restoration.
If this is right
- LLM queries containing PII can be processed by remote models without the original values ever leaving the local device.
- Response quality remains closer to the unmodified query than with placeholder redaction.
- The local pipeline blocks real PII transmission for all tested query types in the evaluated corpus.
- A prompted LLM adversary recovers none of the original values from surrogate-substituted messages in 100 trials.
Where Pith is reading between the lines
- The same substitution pattern could extend to other API endpoints that receive user text, such as search or analytics services.
- Integration with on-device models might become less necessary if surrogate handling proves reliable at scale.
- Expanding the cascade to additional quasi-identifiers would require re-testing the F1 and adversarial metrics.
Load-bearing premise
The detection cascade finds every instance of the 22 PII types and combinations without missing any that would let real data transmit.
What would settle it
A set of queries containing PII that the cascade misses, followed by successful recovery of the original values from the transmitted message or LLM response.
Figures
read the original abstract
LLM-based assistants transmit user queries verbatim to third-party API endpoints that lie outside the user's audit or control. When those queries contain personally identifiable information (PII), the data persists on remote infrastructure subject to breach, subpoena, or policy change. Placeholder redaction (the prevailing mitigation) suppresses PII at the cost of semantic coherence, producing structurally degraded queries and correspondingly degraded responses. We present SurrogateShield, a client-side proxy that substitutes detected PII with locally generated, type-consistent surrogate values prior to transmission and restores originals in the response. No real PII crosses the network boundary. Detection runs through a three-stage cascade (PatternScan, EntityTrace, and ContextGuard) covering 22 PII types and quasi-identifier combinations grounded in Sweeney's k-anonymity framework. Surrogate-to-original mappings are sealed in an AES-256-GCM encrypted per-conversation ShadowMap that never leaves the device. Evaluations on a 1,124-query corpus demonstrate that the cascade reliably detects PII, achieving an overall F1 score of 98.87%. Surrogate substitution substantially outperforms placeholder redaction in semantic utility, yielding a 13.26 pp improvement in BERTScore (roberta-large), from 81.59% to 94.85%. Within this corpus, the local pipeline restricted real PII transmission across all tested query types; in a 100-query adversarial trial, a prompted LLM adversary recovered no original values from surrogate-substituted messages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SurrogateShield, a client-side proxy that detects PII via a three-stage cascade (PatternScan, EntityTrace, ContextGuard) covering 22 types grounded in k-anonymity, substitutes detected entities with locally generated surrogates before transmission to LLM APIs, and restores originals locally using an encrypted ShadowMap. On a 1,124-query corpus it reports 98.87% F1 for detection, a 13.26 pp BERTScore (roberta-large) gain over placeholder redaction (81.59% to 94.85%), restriction of real PII transmission on all tested queries, and zero recovery by a prompted LLM adversary in a 100-query trial.
Significance. If the detection cascade can be shown to achieve zero false negatives on the claimed PII types and quasi-identifiers, the work supplies a concrete, deployable alternative to redaction that materially improves response quality while keeping real PII off the network; the empirical comparison and adversarial trial are concrete strengths.
major comments (2)
- [Abstract] Abstract: the central privacy claim ('no real PII crosses the network boundary' and 'restricted real PII transmission across all tested query types') rests on the three-stage cascade having zero false negatives for all 22 PII types and quasi-identifier combinations. Only an aggregate F1 of 98.87% is supplied; neither per-type false-negative rates nor any evaluation on out-of-distribution or unseen phrasings are reported.
- [Abstract] Abstract: the reported utility metrics (13.26 pp BERTScore gain, 98.87% F1) are presented without error bars, dataset composition breakdown by PII type or query category, or full per-query results, preventing assessment of whether the gains and the 'across all tested query types' statement are robust.
minor comments (2)
- The manuscript would benefit from an explicit description of how the ShadowMap is initialized, keyed, and garbage-collected per conversation.
- The 100-query adversarial trial description should state the exact prompt template and model used for the adversary.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating planned revisions to improve transparency and robustness of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central privacy claim ('no real PII crosses the network boundary' and 'restricted real PII transmission across all tested query types') rests on the three-stage cascade having zero false negatives for all 22 PII types and quasi-identifier combinations. Only an aggregate F1 of 98.87% is supplied; neither per-type false-negative rates nor any evaluation on out-of-distribution or unseen phrasings are reported.
Authors: We agree that per-type false-negative rates would strengthen the privacy claim. The 1,124-query corpus was designed to cover all 22 PII types and quasi-identifier combinations, and the statement that real PII transmission was restricted on all tested queries indicates zero observed false negatives within this specific corpus. We did not report per-type breakdowns in the original submission. In the revised manuscript we will add a table with detection performance (precision, recall, F1) per PII type. Evaluation on out-of-distribution or unseen phrasings was not performed; we will explicitly note this as a limitation and qualify the generalizability claim accordingly. revision: partial
-
Referee: [Abstract] Abstract: the reported utility metrics (13.26 pp BERTScore gain, 98.87% F1) are presented without error bars, dataset composition breakdown by PII type or query category, or full per-query results, preventing assessment of whether the gains and the 'across all tested query types' statement are robust.
Authors: We acknowledge that error bars, dataset breakdowns, and per-query results would improve assessment of robustness. The reported figures are aggregates over the full 1,124-query corpus. In the revised version we will include (i) standard deviation error bars for the BERTScore and F1 metrics, (ii) a breakdown of corpus composition by PII type and query category, and (iii) a link to the full per-query results as supplementary material. These additions will allow readers to evaluate the consistency of the gains across query types. revision: yes
Circularity Check
No circularity; empirical system description only
full rationale
The paper describes a client-side PII detection and surrogate substitution pipeline with reported F1 scores and utility metrics on a fixed 1,124-query corpus. No equations, fitted parameters, predictions, or derivations appear. The k-anonymity reference is to external prior work (Sweeney). Central privacy claim rests on measured cascade behavior within the tested set rather than any self-referential construction or self-citation chain. This is the expected non-finding for an applied systems paper without mathematical modeling.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math AES-256-GCM encryption provides confidentiality for the per-conversation ShadowMap stored on the device.
invented entities (1)
-
ShadowMap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aggarwal and Philip S
Charu C. Aggarwal and Philip S. Yu. 2008.Privacy-Preserving Data Mining: Models and Algorithms. Springer
2008
-
[2]
Rohan Anil, Badih Ghazi, Vineet Gupta, Ravi Kumar, and Pasin Manurangsi
-
[3]
InProceedings of EMNLP 2022
Large-scale differentially private BERT. InProceedings of EMNLP 2022. 6481–6491
2022
-
[4]
Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert- Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. 2021. Extracting training data from large language models. InProceedings of the 30th USENIX Security Symposium. 2633–2650
2021
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT 2019. 4171–4186
2019
-
[6]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Cali- brating noise to sensitivity in private data analysis. InTheory of Cryptography Conference. Springer, 265–284
2006
-
[7]
Oluwaseun Feyisetan, Borja Balle, Thomas Drake, and Tom Diethe. 2020. Privacy- and utility-preserving textual analysis via calibrated multivariate perturbations. InProceedings of WSDM 2020. 178–186. doi:10.1145/3336191.3371856
-
[8]
Benjamin C. M. Fung, Ke Wang, Rui Chen, and Philip S. Yu. 2010. Privacy- preserving data publishing: A survey of recent developments.Comput. Surveys 42, 4 (2010), 1–53
2010
-
[9]
2010.HMAC-based Extract-and-Expand Key Derivation Function (HKDF)
Hugo Krawczyk and Pasi Eronen. 2010.HMAC-based Extract-and-Expand Key Derivation Function (HKDF). Technical Report RFC 5869. IETF
2010
-
[10]
John Lafferty, Andrew McCallum, and Fernando Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. InProceedings of ICML 2001. 282–289. doi:10.5555/645530.655813
-
[11]
Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. 2016. Neural architectures for named entity recognition. In Proceedings of NAACL-HLT 2016. 260–270
2016
-
[12]
Ninghui Li, Tiancheng Li, and Suresh Venkatasubramanian. 2007. t-closeness: Privacy beyond k-anonymity and l-diversity. InProceedings of ICDE 2007. 106–115. doi:10.1109/ICDE.2007.367856
-
[13]
Pierre Lison, Ildikó Pilán, David Sánchez, Montserrat Batet, and Lilja Øvrelid
-
[14]
Anonymisation models for text data: State of the art, challenges and future directions. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 4188–4203. doi:10.18653/v1/2021.acl- long.323
-
[15]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.arXiv preprint arXiv:1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[16]
Xuezhe Ma and Eduard Hovy. 2016. End-to-end sequence labeling via bi- directional LSTM-CNNs-CRF. InProceedings of ACL 2016. 1064–1074
2016
-
[17]
Ashwin Machanavajjhala, Daniel Kifer, Johannes Gehrke, and Muthuramakrish- nan Venkitasubramaniam. 2007. l-diversity: Privacy beyond k-anonymity.ACM Transactions on Knowledge Discovery from Data1, 1 (2007), 3
2007
-
[18]
Microsoft. 2020. Presidio — data protection and anonymization API. Microsoft Open Source. https://github.com/microsoft/presidio
2020
-
[19]
Niloofar Mireshghallah, Hyunwoo Kim, Xuhui Zhou, Yulia Tsvetkov, Maarten Sap, Reza Shokri, and Yejin Choi. 2024. Can LLMs keep a secret? Testing privacy implications of language models via contextual integrity theory. InInternational Conference on Learning Representations (ICLR 2024). https://arxiv.org/abs/2310. 17884
2024
-
[20]
Arvind Narayanan and Vitaly Shmatikov. 2008. Robust de-anonymization of large sparse datasets. InProceedings of the 2008 IEEE Symposium on Security and Privacy. 111–125
2008
-
[21]
Douglass, Li-wei H
Ishna Neamatullah, Margaret M. Douglass, Li-wei H. Lehman, Andrew Reisner, Mauricio Villarroel, William J. Long, Peter Szolovits, George B. Moody, Roger G. Mark, and Gari D. Clifford. 2008. Automated de-identification of free-text medical records.BMC Medical Informatics and Decision Making8, 1 (2008), 1–17. doi:10. 1186/1472-6947-8-32
2008
-
[22]
Helen Nissenbaum. 2004. Privacy as contextual integrity.Washington Law Review 79, 1 (2004), 119–158
2004
-
[23]
Chen Qu, Weize Kong, Liu Yang, Mingyang Zhang, Michael Bendersky, and Marc Najork. 2021. Natural language understanding with privacy-preserving BERT. InProceedings of the 30th ACM International Conference on Information and Knowledge Management. 1488–1497. doi:10.1145/3459637.3482281
-
[24]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of EMNLP-IJCNLP 2019. 3982–3992
2019
-
[25]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Dis- tilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[26]
Amber Stubbs and Özlem Uzuner. 2015. Annotating longitudinal clinical narra- tives for de-identification: The 2014 i2b2/UTHealth corpus.Journal of Biomedical Informatics58 (2015), S20–S29
2015
-
[27]
2000.Simple demographics often identify people uniquely
Latanya Sweeney. 2000.Simple demographics often identify people uniquely. Technical Report Data Privacy Working Paper 3. Carnegie Mellon University, Pittsburgh, PA
2000
-
[28]
Latanya Sweeney. 2002. k-anonymity: A model for protecting privacy.Inter- national Journal of Uncertainty, Fuzziness and Knowledge-Based Systems10, 05 (2002), 557–570
2002
-
[29]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Transformers: State-of-t...
2020
-
[30]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[31]
Building
BERTScore: Evaluating text generation with BERT. InProceedings of ICLR 2020. A Surrogate Generation Mechanisms Table 10 documents the surrogate generator used by MimicGen for each PII type detected by SurrogateShield, together with the format guarantee and a representative example value. All surrogates are generated via Faker with a per-session unique- ne...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.