EviTrack: Selection over Sampling for Delayed Disambiguation
Pith reviewed 2026-05-20 07:05 UTC · model grok-4.3
The pith
EviTrack shows that selecting among trajectory hypotheses outperforms increased sampling for sequential prediction under delayed disambiguation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In regimes where observations are initially ambiguous and multiple latent trajectories remain consistent with the data until sufficient evidence arrives, maintaining competing trajectory hypotheses and applying evidence- and likelihood-ratio-based selection delays premature commitment and produces faster recovery once disambiguation occurs, outperforming sampling-based approaches at matched inference cost.
What carries the argument
EviTrack, a test-time framework that maintains a set of competing latent trajectory hypotheses and performs selection using accumulated evidence and likelihood ratios.
If this is right
- Moderate trajectory-level selection is more effective than increasing sampling coverage for reliable sequential inference.
- Substantial performance gains over sampling baselines occur at matched inference budget.
- Faster post-disambiguation recovery is achieved in the designed synthetic setting with known ground truth.
- Selection over sampling forms a useful principle for inference when evidence arrives gradually.
Where Pith is reading between the lines
- The same selection mechanism could be tested in domains like video tracking or medical event prediction where labels or states are revealed with delay.
- Combining trajectory selection with learned proposal distributions might reduce the number of hypotheses that must be maintained.
- The approach may extend to settings where the number of plausible trajectories grows exponentially until disambiguation.
Load-bearing premise
The controlled synthetic benchmark with known latent ground truth accurately captures the essential challenges and recovery dynamics of delayed disambiguation in real sequential prediction tasks.
What would settle it
Running EviTrack and sampling baselines on a real-world sequential dataset with naturally delayed labels and measuring whether the selection method still shows faster recovery after the delay resolves.
Figures









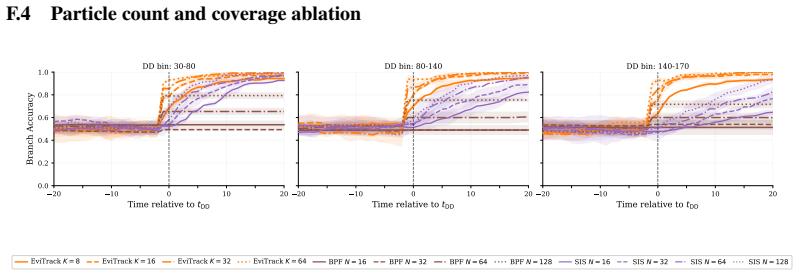

read the original abstract
Sequential prediction is challenging in regimes of delayed disambiguation, where early observations are ambiguous and multiple latent explanations remain plausible until sufficient evidence accumulates. Standard approaches based on marginal inference struggle in this setting, either collapsing uncertainty prematurely or failing to recover once informative evidence arrives. We introduce EviTrack, a test-time inference framework that operates over latent trajectories rather than marginal states. EviTrack maintains a set of competing trajectory hypotheses and applies evidence- and likelihood-ratio-based selection to delay commitment until supported by data, drawing inspiration from hypothesis management in multiple hypothesis tracking and track-before-detect. To evaluate this setting, we construct a controlled synthetic benchmark with known latent ground truth that explicitly exhibits delayed disambiguation. At matched inference budget, EviTrack substantially outperforms sampling-based baselines, achieving faster post-disambiguation recovery. These results show that, in delayed disambiguation regimes, moderate trajectory-level selection is more effective than increasing sampling coverage, highlighting selection over sampling as a key principle for reliable sequential inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EviTrack, a test-time inference framework for sequential prediction under delayed disambiguation. It maintains a set of competing latent trajectory hypotheses and applies evidence- and likelihood-ratio-based selection to delay commitment until supported by data, drawing from multiple hypothesis tracking. The method is evaluated on a controlled synthetic benchmark with known latent ground truth, where it is claimed to substantially outperform sampling-based baselines at matched inference budget by achieving faster post-disambiguation recovery. The authors conclude that moderate trajectory-level selection is more effective than increasing sampling coverage in such regimes.
Significance. If the results hold, the work could highlight a useful principle for inference in ambiguous sequential settings by prioritizing selection mechanisms over pure sampling. The controlled synthetic benchmark with ground truth is a strength for clear evaluation. However, the broader impact hinges on whether the benchmark faithfully reproduces ambiguity patterns and recovery dynamics from real tasks; without stronger validation, the principle may remain testbed-specific.
major comments (2)
- [Abstract] Abstract: the claim that EviTrack 'substantially outperforms sampling-based baselines, achieving faster post-disambiguation recovery' is presented without any quantitative metrics, effect sizes, statistical tests, implementation details, or ablation studies, which directly undermines assessment of the central empirical claim.
- [§4] §4 (Experiments/Benchmark): the synthetic benchmark is described only as 'controlled' with 'known latent ground truth' and 'explicitly exhibits delayed disambiguation,' but lacks specifics on generative process details such as latent dimensionality, noise structures, timing of disambiguation events, or how ambiguity patterns match real sequential prediction tasks; this makes it impossible to evaluate whether the selection-over-sampling advantage is general or an artifact of artificially clean disambiguation.
minor comments (1)
- [Abstract] Abstract: consider specifying the exact sampling baselines and inference budget matching procedure for clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that EviTrack 'substantially outperforms sampling-based baselines, achieving faster post-disambiguation recovery' is presented without any quantitative metrics, effect sizes, statistical tests, implementation details, or ablation studies, which directly undermines assessment of the central empirical claim.
Authors: We agree that the abstract would benefit from more specific support for the central claim. In the revised manuscript, we will include key quantitative results, such as the percentage improvement in post-disambiguation recovery time and accuracy metrics from our experiments, along with brief mentions of the inference budget matching and statistical significance where applicable. This will provide readers with a clearer sense of the effect sizes without exceeding abstract length constraints. revision: yes
-
Referee: [§4] §4 (Experiments/Benchmark): the synthetic benchmark is described only as 'controlled' with 'known latent ground truth' and 'explicitly exhibits delayed disambiguation,' but lacks specifics on generative process details such as latent dimensionality, noise structures, timing of disambiguation events, or how ambiguity patterns match real sequential prediction tasks; this makes it impossible to evaluate whether the selection-over-sampling advantage is general or an artifact of artificially clean disambiguation.
Authors: We acknowledge the need for greater transparency in the benchmark description. The current manuscript provides an overview, but we will expand §4 in the revision to detail the generative process, including latent state dimensionality, specific noise models, the timing and nature of disambiguation events, and a discussion of how the ambiguity patterns are designed to reflect challenges in real-world sequential prediction tasks like tracking or language modeling. This will allow better assessment of the generality of our findings. revision: yes
Circularity Check
No circularity: new framework evaluated on external synthetic benchmark
full rationale
The paper presents EviTrack as an original test-time inference construction that maintains competing trajectory hypotheses and applies evidence- and likelihood-ratio-based selection. Evaluation occurs on a separately constructed synthetic benchmark with known latent ground truth, compared against independent sampling baselines at matched budget. No derivation step reduces a claimed result to a fitted parameter or self-defined quantity within the method, nor does any load-bearing premise rest on a self-citation chain. The central claim about selection outperforming sampling is an empirical observation on the benchmark rather than a tautological restatement of the framework's own definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A controlled synthetic benchmark can be constructed that explicitly exhibits delayed disambiguation with known latent ground truth.
invented entities (1)
-
EviTrack
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EviTrack maintains a set of competing trajectory hypotheses and applies evidence- and likelihood-ratio-based selection... scores Jt(z1:t;x1:t)=logp(x1:t,z1:t), Et=logp(x1:t|z1:t)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
local pruning... p⋆C(zt+1|z1:t)=C p(zt+1|z1:t) F(S(zt+1))^{C-1}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of Basic Engineering , volume=
A new approach to linear filtering and prediction problems , author=. Journal of Basic Engineering , volume=
-
[2]
Statistics and Computing , volume=
Sequential Monte Carlo methods in practice , author=. Statistics and Computing , volume=
-
[3]
Advances in Neural Information Processing Systems , year=
A recurrent latent variable model for sequential data , author=. Advances in Neural Information Processing Systems , year=
-
[4]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Structured inference networks for nonlinear state space models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[5]
Tracking and Data Fusion , author=
-
[6]
IEEE Transactions on Aerospace and Electronic Systems , year=
An Overview of Track-Before-Detect Techniques , author=. IEEE Transactions on Aerospace and Electronic Systems , year=
-
[7]
Stochastic Models, Estimation, and Control , author=
-
[8]
Journal of the American Statistical Association , volume=
Sequential Imputations and Bayesian Missing Data Problems , author=. Journal of the American Statistical Association , volume=
-
[9]
Sequential Monte Carlo Methods in Practice , author=
-
[10]
IEE Proceedings F: Radar and Signal Processing , volume=
Novel Approach to Nonlinear/Non-Gaussian Bayesian State Estimation , author=. IEE Proceedings F: Radar and Signal Processing , volume=
-
[11]
Sequence Transduction with Recurrent Neural Networks
Sequence Transduction with Recurrent Neural Networks , author=. arXiv preprint arXiv:1211.3711 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.